2412.10117_CosyVoice2: Scalable Streaming Speech Synthesis with Large Language Models¶
组织: Alibaba
引用: 64(2025-06-23)
Abstract¶
在之前的工作中,研究者提出了 CosyVoice,一个多语言语音合成模型,能用上下文学习生成自然、有表现力的语音。
它结合了语言模型和Flow Matching方法。
现在,他们推出了升级版 CosyVoice 2,对语音合成进行了全面优化,特别适用于和大模型的交互使用,支持流式合成(实时生成语音)。
主要改进包括:
使用有限量化方法提高语音token的编码效率;
精简模型架构,可以直接使用大语言模型作为基础;
引入支持分块生成的因果Flow Matching模型,一个模型可同时支持流式和非流式合成;
在大规模多语言数据上训练,CosyVoice 2 在自然度、响应速度和音质上都达到了非常高的水平。
1. Instroduction¶
这段内容介绍了神经网络语音合成(TTS)的发展,特别是零样本语音合成(zero-shot TTS)的最新进展,以及CosyVoice 2的创新点。
📌 背景概述¶
神经TTS模型已经超越传统方法,在音质和自然度上有巨大提升,尤其适用于特定说话人。
零样本TTS模型可以模仿任意说话人的音色、语调和风格,不需要该人的训练数据,表现接近人类语音。
🔧 主流方法¶
零样本TTS模型主要分三类:
Codec语言模型:把语音编码成离散token,通过语言模型生成,再用vocoders还原成音频。
扩散模型(Diffusion):参考图像生成技术,不用逐步预测token,可更自然生成语音,但对时长预测要求高。
混合模型:结合语言模型和扩散模型的优点,先生成token,再用扩散模型生成语音特征,实现更高质量和表现力。
🚫 当前问题¶
现有模型大多是离线处理(非流式),要等整段文本输入完后才生成语音,延迟较高,不适合实时应用,如语音聊天。
✅ CosyVoice 2 的创新点¶
统一流式与非流式生成:一个模型同时支持实时和离线语音合成,质量一致。
架构更简单:去掉文本编码器和说话人嵌入,直接用现成的大语言模型(LLM)理解文本。
更强的量化方式:用标量量化(FSQ)替代向量量化(VQ),信息保留更多。
更强的指令控制能力:支持更多控制项,如情绪、口音、角色风格等,用户可精准控制语音输出。
⭐ 效果¶
在流式模式下也能达到接近人类语音的质量。
一个模型搞定所有需求,部署更简单。
提出的 chunk-aware flow matching 方法也适用于扩散类TTS流式生成,拓展性强。
2. CosyVoice 2¶
2.1 Text Tokenizer¶
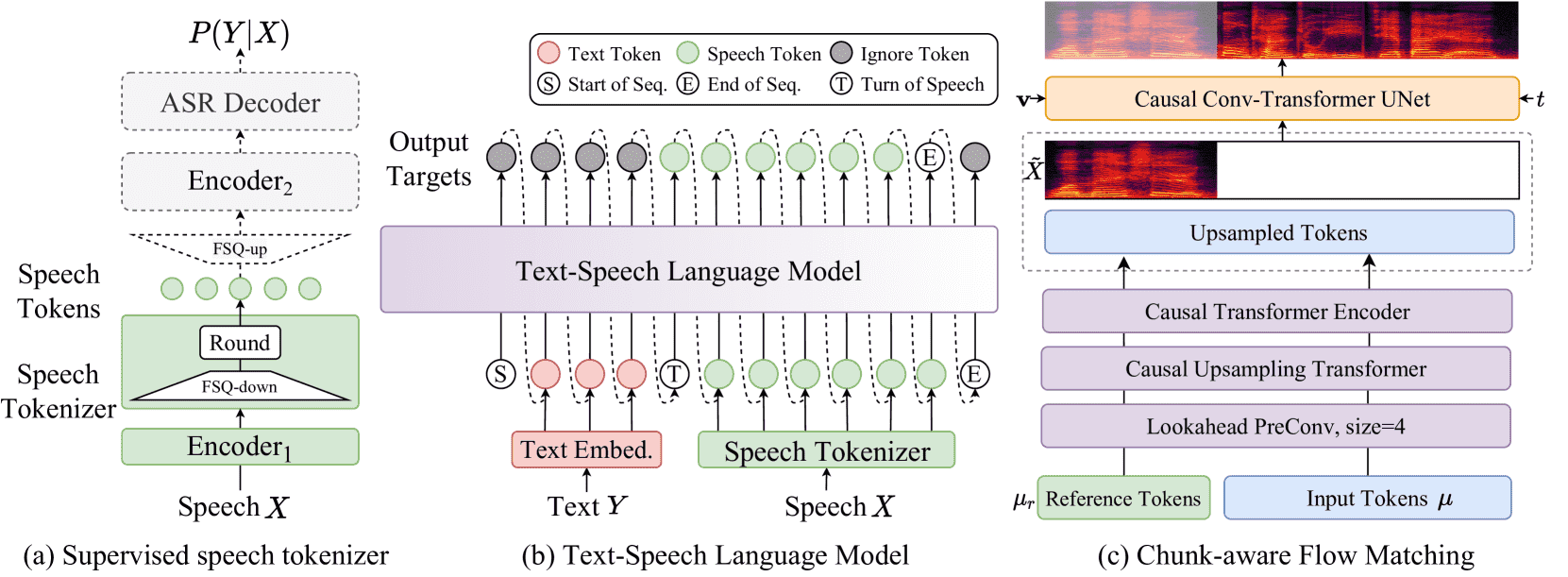
Figure 1:An overview of CosyVoice 2.
图片简介 a) demonstrates the supervised speech tokenizer, where dashed modules are only used at the training stage. b) is a unified text-speech language model for streaming and non-streaming synthesis. Dashed lines indicate the autoregressive decoding at the inference stage. c) illustrates the causal flow matching model conditioning on a speaker embedding 𝐯, semantic tokens μ, masked speech features \(\tilde(X)\) and intermediate state \(X_t\) at timestep t on the probabilistic density path.
CosyVoice 2 是一个语音合成系统,分为三个模块:
语音分词器(图1a):把语音转换成语义级别的 token(训练阶段使用)。
统一文本-语音语言模型(图1b):支持流式和非流式合成,把文本 token 转为语音 token。
Flow Matching 模型(图1c):结合说话人信息和语义 token,生成 Mel 频谱,再通过 vocoder 还原为语音。
核心思路是将语音的“语义信息”和“音色等声学细节”分开建模,语音生成过程是一个逐步解码语义的过程,再逐步加入声学信息。
使用 BPE(子词)算法对原始文本分词。
不再需要前端的“拼音-音素”转换(如 G2P),简化了预处理流程。
对于中文:如果一个 BPE token 对应多个汉字,会被“屏蔽”,转而对每个汉字单独编码,避免发音过长或稀有情况。
英语、日语、韩语无特殊处理。
2.2 Supervised Semantic Speech Tokenizer¶
使用一个语音识别模型(SenseVoice-Large),在其中插入一个 FSQ(有限标量量化)模块,将语音编码为语义 token。
处理流程: 1. 语音 → 编码器 Encoder1(6层 Transformer) → 中间表示。 2. 中间表示 → FSQ 模块,投影到低维空间 → 量化。 3. 量化结果 → 投影回高维 → 后续编码器和 ASR 解码器 → 预测对应的文本 token。
FSQ 模块细节: * 每一维数据被量化到一个有限整数范围(例如 [-K, K])。 * 最后通过一个公式把这些离散数值编码成语义 token 的索引。
语音 token 的生成速率是 25Hz(每秒25个 token)。
2.3 Unified Text-Speech Language Model¶
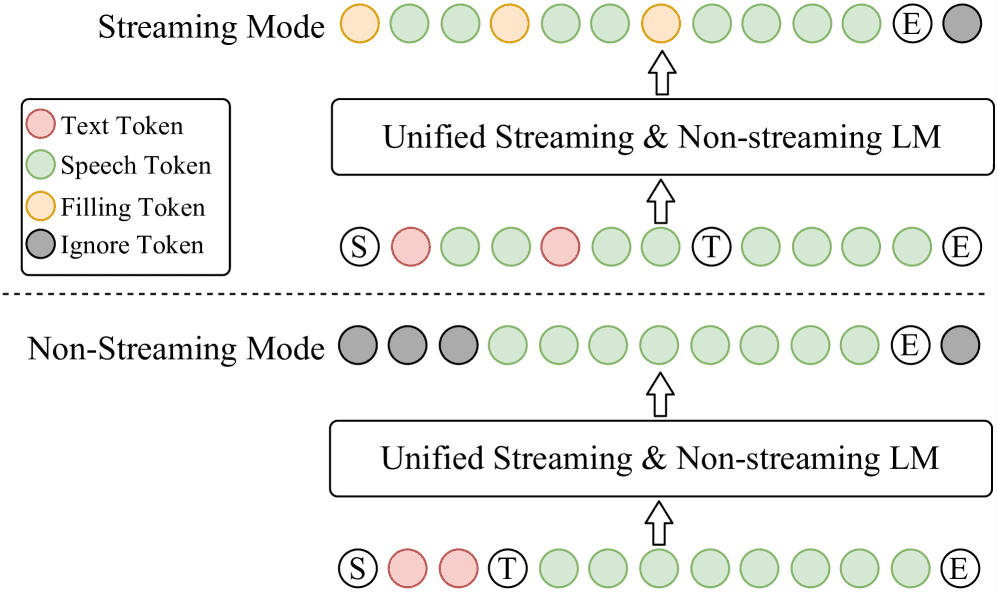
Figure 2: A diagram of the unified text-speech language model for streaming and non-streaming synthesis in CosyVoice 2.
这段内容主要介绍了 CosyVoice 2 如何通过一个统一的模型来进行文本到语音的生成,支持流式(streaming)和非流式(non-streaming)两种方式。
核心思想:统一的文本-语音大模型
使用 Qwen2.5-0.5B 作为统一的语言模型来预测语音 token,不再单独使用 speaker embedding 和 text encoder,减少信息泄露,提高跨语言能力和韵律自然度。
流式 vs 非流式:
非流式(Non-Streaming):
整句话一次性输入,模型从
[S, text, T, speech, E]的序列中学习预测。
流式(Streaming):
文本和语音 token 按固定比例混合,比如每 5 个 text token 后跟 15 个 speech token,形成
[S, text1, ..., speech1, ..., T, speech2, ...]的结构,适合边听边说。
统一训练方式:
将这两种模式的训练样本同时用于训练一个模型,实现“一模两用”。
在两种实际应用场景中的应用方式:
🔸In-Context Learning(ICL):
非流式:带参考语音模仿风格,序列结构是
[S, prompt_text, text, T, prompt_speech]。流式:也是带参考语音,但生成部分按 N:M 比例流式输出,遇到不足会用填充 token。
🔸Speaker Fine-Tuning(SFT):
非流式:已针对特定说话人训练,不需要提示语音,结构是
[S, text, T]。流式:从
[S, first_N_text]开始,每轮生成 M 个语音 token,然后手动补下一个 N 个 text token,直到完成,延迟极低。
2.4 Chunk-aware Flow Matching¶
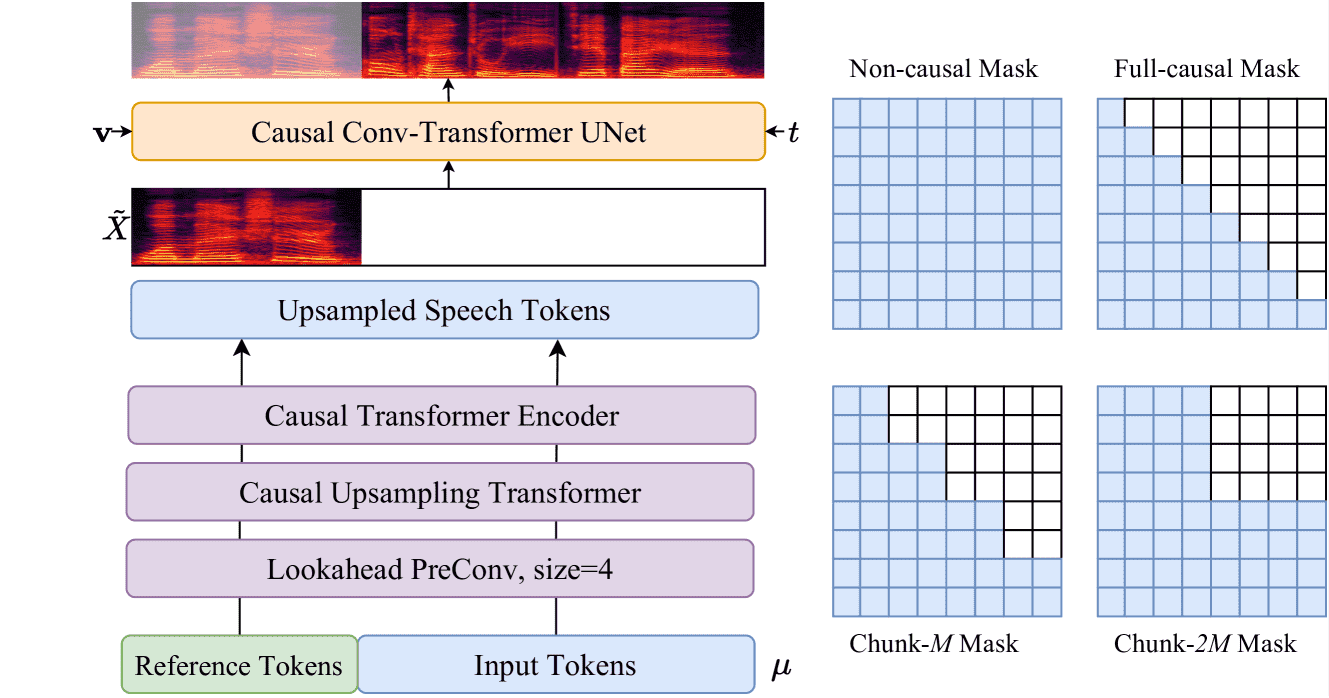
Figure 3:A diagram of the unified chunk-aware flow matching model for streaming and non-streaming synthesis in CosyVoice 2.
这段内容介绍了 CosyVoice 2 在语音生成中的“Chunk-aware Flow Matching”方法
🔧 核心流程:¶
输入和预处理:
使用 Mel 频谱图作为语音特征(50Hz 帧率、24kHz 采样率)。
因 Mel 与语音 token 的帧率不一致,先将语音 token 上采样(倍数为 2)来对齐。
为了因果性建模,引入了一个“向未来看的卷积”层(右填充的 1D 卷积)。
Token 到 Mel 的转换:
使用 Conditional Flow Matching (CFM) 模型,将语音 token 转换为 Mel 频谱图。
CFM 模型将预测 Mel 频谱图视为从高斯分布到真实数据分布的“概率路径”,通过 ODE(常微分方程)描述。
用 UNet 来学习这个 ODE,条件包括语音 token、说话人信息、参考 Mel。
训练方式:
对目标 Mel 做遮蔽(mask),然后训练模型预测被遮蔽部分。
损失函数是预测的 ODE 与真实路径之间的 L1 距离。
时间步 t 在训练时是均匀采样,推理时采用余弦调度(前期多推理步骤)。
推理增强技巧:
使用 Classifier-Free Guidance (CFG) 技术来增强有条件生成能力,具体方式是:
ν̃ = (1 + β) * ν(conditioned) - β * ν(unconditioned)
这里 β=0.7,推理时重复 UNet 10 次(NFE=10)。
📦 流式生成支持(重点):¶
传统 Flow Matching 模型只能离线工作,无法流式生成。
CosyVoice 2 通过**“chunk-aware 模式”** 解决此问题:
CosyVoice 2
将 10 步流动估计看成一个 堆叠 UNet 网络,变成可展开的、可因果的网络。
定义了 4 种 mask(掩码),支持不同应用需求:
Mask 类型
特点
场景
Non-causal
可看所有帧,性能最佳
离线生成,延迟不敏感
Full-causal
只能看过去帧,延迟最低
实时生成
Chunk-M
过去 + M 帧未来,兼顾延迟与质量
第一块生成
Chunk-2M
看更多未来帧,接近离线性能
后续块生成,追求质量
训练时,每条样本随机用其中一种 mask,从而训练出一个统一模型,兼容多种推理场景,并实现自蒸馏(context 多的掩码教 context 少的)。
✅ 总结一句话:¶
CosyVoice 2 利用 chunk-aware flow matching + UNet ODE 来实现高效、统一、可流式的语音生成模型,兼顾性能、实时性和灵活性。
2.5 Latency Analysis for Streaming Mode¶
在语音对话系统中,“首包延迟”(First-package latency)是用户最先听到语音的时间延迟,非常关键。
TTS(文本转语音)模型的延迟来源包括三个部分:
语言模型生成语音 token 的时间
Mel谱图(中间声学特征)的生成时间
vocoder 合成语音波形的时间
所以总延迟 \(L_{TTS} = M \cdot d_{lm} + M \cdot d_{fm} + M \cdot d_{voc}\),M为语音token数量。
若结合LLM进行语音聊天,还要加上文本生成时间 \(L_{Chat} \leq N \cdot d_{llm} + L_{TTS}\)
2.6 Instructed Generation¶
为了更好控制语音风格,CosyVoice 2 加入了带“指令”的训练数据(共1500小时)。
指令包括自然语言指令和细粒度控制:
自然语言指令如:“用愤怒语气说”、“说得慢一点”、“模仿粤语”
细粒度控制如插入
[laughter]、<strong>词>,标记笑声、强调等
使用
<|endofprompt|>作为提示结尾,帮助模型区分“指令”和“要说的内容”

Table 1: Examples of natural language instructions and fine-grained instructions.
2.7 Multi-Speaker Fine-tuning¶
传统微调是只用一个人的数据,现在采用“多说话人微调”(mSFT):
一次性用多个说话人数据训练,有助于提高音色多样性、避免遗忘旧知识
每条训练样本前加说话人标签,如 “Speaker A<|endofprompt|>”,无标签则用“unknown”
学习率设为 1e-5
2.8 Reinforcement Learning for SFT¶
为了让语音生成更符合人类喜好,CosyVoice 2 使用强化学习方式微调:
奖励函数用两个指标:
SS:与目标音色的相似度
WER:语音识别错误率(越低越好)
使用 DPO(直接偏好优化)算法,把“好的样本”和“不好的样本”差距放大
由于实际合成音频再评分效率低,优化时用量化的语音 token(如μ)做近似:
将语音 token 恢复为低秩特征,再送入 ASR(语音识别器)来估算得分
用 Gumbel Softmax 技巧解决采样不可导问题,从而可优化整个 TTS 模型
3. Experimental Settings¶
3.1 Training Data for Speech Tokenizer¶
用了 20万小时语音数据训练分词器(用文本标注)。
数据来自三类来源:开源ASR数据、工业内部数据、TTS生成数据。
虽只用中英文训练,但实验表明该分词器对日语、韩语也有零样本泛化能力。
中英文时长分别为:中文 110,884 小时,英文 99,918 小时。
3.2 Training Data for CosyVoice 2¶
与旧版使用相同数据,语音来自内部工具采集。
使用 Paraformer(中文)和 SenseVoice(其他语种)生成伪文本标注。
再用对齐模型筛除低质量数据,优化标点。
多语言数据时长如下:
中文:130,000 小时
英文:30,000 小时
日语:4,600 小时
韩语:2,200 小时
3.3 Evaluation Settings¶
用两个测试集评估模型性能:
test-clean(英文):
用于小领域英文评估。
用 Whisper-large V3 评估文本一致性,ERes2Net 算说话人相似度。
SEED(多语言):
包括中文(test-zh)、英文(test-en)和困难样例(test-hard),用 Paraformer 和 Whisper 评估内容一致性和说话人相似度。
3.4 日语与韩语测试基准¶
准备了两个测试集:
test-ja(日语):从 CommonVoice 中选取 1000 个样本,覆盖 WER、SS、MOS 等指标。
test-ko(韩语):选取 1000 个 WER<5% 的样本作为参考语音,另一部分文本作为输入。
所有样本和文本都已开放,以便复现。
同样使用 Whisper-large V3 作为 ASR 模型进行评估。
4. Experimental Results¶
4.1 Evaluations on Speech Tokenizer¶
FSQ 优于传统 VQ:FSQ(Finite State Quantization)分词器完全利用了编码字典(codebook),在语音识别错误率(ASR)上表现更好,说明能保留更多语义信息。
说话人信息去除效果好:通过 t-SNE 可视化和说话人识别实验(SID),发现 FSQ 能有效消除不同说话人之间的差异,实现“说话人无关性”。
说话人识别训练不收敛:用量化后的 token 训练说话人识别模型不收敛,进一步验证说话人信息已被成功剥离。
4.2 Comparison Results with Baselines¶
全面领先对比模型:CosyVoice 2 在文本一致性(WER/CER)、说话人相似度(SS)和语音质量(NMOS)方面都超过了包括 ChatTTS、OpenVoice 在内的多个开源模型。
接近甚至超过真人表现:在多项指标上,CosyVoice 2 的表现甚至优于真人录音(尤其是说话人相似度 SS)。
流式版本(CosyVoice 2-S)性能几乎无损:CosyVoice 2-S 在大部分场景下表现接近离线模式,仅在复杂任务中略有下降。
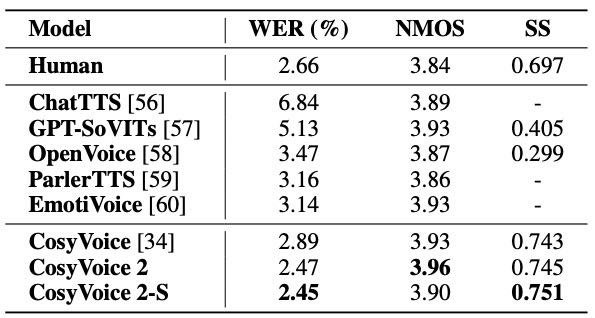
Table 5: Content consistency (WER), speaker similarity (SS) and speech quality (NMOS) results on LibriSpeech test-clean subset of baselines and CosyVoice 2. Whisper-Large V3 is employed as the ASR model and punctuations are excluded before WER calculation.
4.3 Modular Ablation Study¶
预训练 LLM 提升显著:用预训练大模型替换原始语言模型后,文本一致性大幅提升。
去除说话人 embedding 更稳定:避免“信息泄露”,对模型结构更简洁,保持说话人相似度。
替换为 FSQ 更强大:FSQ 带来更好的一致性和上下文理解能力,未损害说话人还原。
加入音高损失更优:进一步提升 TTS 下游任务效果。
流式模块影响有限:LM 模块对困难任务影响大,但 Flow Matching(FM)模块几乎不受影响,甚至在某些场景下说话人还原更好。
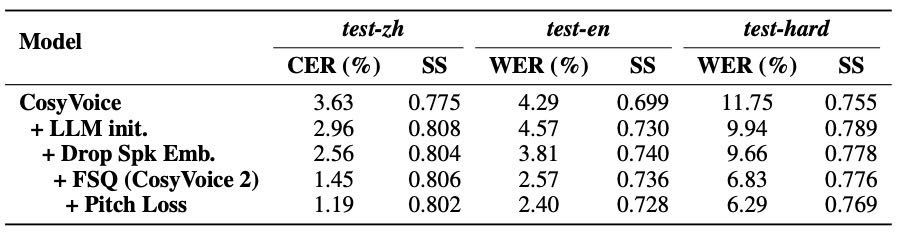
Table 7: Modular analysis on the modifications of text-speech language model.
4.4 Results on Japanese and Korean Benchmarks¶
CosyVoice 2 支持日语和韩语。
测试发现:在内容一致性、说话人相似度和语音质量三个指标上,韩语表现明显优于日语。
原因:日语与中文字符有重叠,容易被系统错误发音为中文;韩语字符独立,所以表现更好。
数据不平衡也是原因之一,更多的训练数据能进一步提升效果。
4.5 Results on Instructed Generation¶
使用中文测试集评估 CosyVoice 2 在“按指令生成语音”的能力。
测试内容包括情绪、语速、方言、角色扮演等细节。
加入“指令”后,CosyVoice 2 在内容一致性、说话人相似度、指令准确性(MOS-I)上表现最好。
移除指令后,MOS-I 明显下降,说明模型难以从文本中自动学到指令控制能力。
4.6 Results on Speaker Fine-tuned Models¶
用无监督聚类保持说话人音色稳定。
仅用 400 条语音数据就能达到不错的合成效果。
微调后的模型仍保留原始大模型的上下文理解和情感表达能力。
4.7 LM Fine-tuning with Reinforcement Learning¶
对“Spk E”说话人(声音复杂且语速快)使用强化学习优化。
用两种方式:
ASR可微奖励(L_ASR):直接根据识别后结果优化发音准确性。
DPO偏好学习(L_DPO):用成对语音样本调整模型偏好。
在目标说话人数据集上,强化学习显著降低了识别错误率(WER),且不影响其它指标。
在跨领域/复杂测试集(SEED)上,ASR 奖励泛化性更好;DPO 对重复内容不友好。
两种方法结合使用效果最佳。
5. Conclusion¶
CosyVoice 2 是在 CosyVoice 基础上升级的语音合成模型,支持流式和非流式两种模式,能做到接近人类的自然语音、响应快、质量高。
它的主要创新包括:
更高效的量化方法,充分利用语音编码;
简化的语音模型架构,融合了大语言模型(LLM);
支持多场景的“块感知”流式合成技术;
能精细控制情感、口音、角色风格等语音细节。
这些改进让 CosyVoice 2 合成效果更好、使用门槛更低,适合广泛应用,是高质量语音合成的一大进步。