2210.03629_ReAct¶
标题: ReAct: Synergizing Reasoning and Acting in Language Models
作者: Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, Yuan Cao
虽然大型语言模型(LLMs)在语言理解和交互式决策方面在任务中表现出令人印象深刻的能力,但它们的推理能力(例如思维链提示)和行动能力(例如行动计划生成)主要被作为单独的主题进行研究。在本文中,我们探索了使用 LLMs 以交错方式生成推理跟踪和特定于任务的操作,从而在两者之间实现更大的协同作用:推理跟踪帮助模型诱导、跟踪和更新行动计划以及处理异常,而操作允许它与外部源(如知识库或环境)交互, 以收集更多信息。我们将名为 ReAct 的方法应用于各种语言和决策任务,并证明了其在最先进的基线上的有效性,以及在没有推理或行动组件的情况下,提高了人类的可解释性和可信度。具体来说,在问答(HotpotQA)和事实验证(Fever)方面,ReAct通过与简单的维基百科API交互,克服了思维链推理中普遍存在的幻觉和错误传播问题,并生成了类似人类的任务解决轨迹,这些轨迹比没有推理痕迹的基线更具可解释性。在两个交互式决策基准测试(ALFWorld 和 WebShop)上,ReAct 只用一两个上下文示例来提示,但它的绝对成功率分别优于模仿和强化学习方法 34% 和 10%。
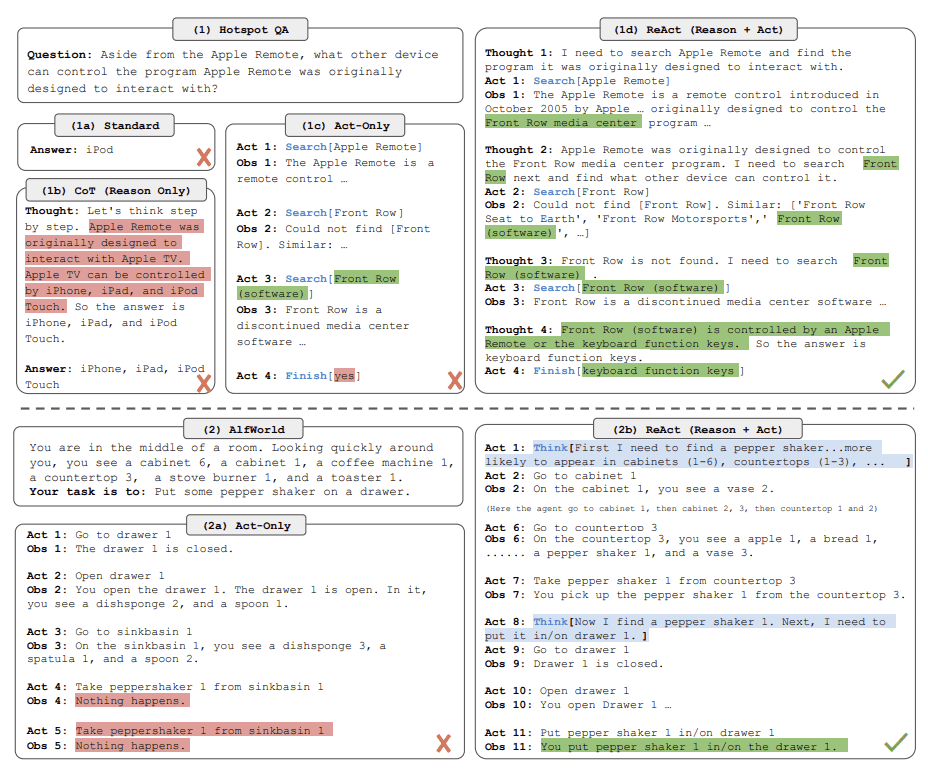
Comparison of 4 prompting methods, (a) Standard, (b) Chain-of-thought (CoT, Reason Only), (c) Act-only, and (d) ReAct (Reason+Act), solving a HotpotQA (Yang et al., 2018) question. (2) Comparison of (a) Act-only and (b) ReAct prompting to solve an AlfWorld (Shridharet al., 2020b) game. In both domains, we omit in-context examples in the prompt, and only show task solving trajectories generated by the model (Act, Thought) and the environment (Obs).¶