2406.05370_VALL-E2: Neural Codec Language Models are Human Parity Zero-Shot Text to Speech Synthesizers¶
组织: 微软研究院
VALL-E Family: https://www.microsoft.com/en-us/research/project/vall-e-x/
Abstract¶
论文介绍了 VALL-E 2,这是一个最新的神经编码语言模型,在零样本文本转语音合成方面取得了重大突破,首次达到接近人类水平。
相较前一代 VALL-E,有两个关键改进:
重复感知采样(Repetition Aware Sampling):
优化了解码过程中对重复内容的处理,避免模型陷入死循环,并让语音生成更稳定。
分组编码建模(Grouped Code Modeling):
将语音编码分组,缩短了序列长度,提高了生成速度,也更好地处理长语句。
实验证明,VALL-E 2 在语音的稳定性、自然度和说话人相似度方面都优于现有系统,是首个在相关基准测试上达到人类水平的系统。
此外,它对复杂或重复的句子也能保持高质量合成,未来可用于帮助失语症或渐冻症患者发声。
1. Introduction¶
背景介绍¶
文本转语音(TTS):目标是将文本转成清晰自然的语音。传统方法在单一说话人、干净数据上表现接近真人。
零样本TTS:只需一个短语音样本就能模仿新说话人的声音,这仍然是难题。
VALL-E(2023)¶
只需3秒语音样本即可生成保留说话人声音、情绪和环境的语音。
存在两个问题:
稳定性差:随机采样容易导致不稳定或死循环。
效率低:自回归架构速度慢,受限于高帧率。
后续研究¶
为提升稳定性,一些方法引入文字和语音对齐信息,但增加了复杂性和误差。
为提升效率,也有工作采用非自回归模型,但牺牲了语音的韵律和自然度。
VALL-E 2 的创新¶
提出人类同等水平的零样本TTS系统,在以下方面改进了 VALL-E:
重复感知采样:根据是否重复,自适应选择随机或核采样,提升稳定性,避免死循环。
分组编码建模:将语音码划分成组建模,减少序列长度,提高效率和表现。
性能表现¶
使用 LibriHeavy 训练,评估在 LibriSpeech 和 VCTK 数据集上,表现优于以往方法,甚至超越真人语音样本(在鲁棒性、自然度和相似性指标上)。
即便是重复或复杂句子,也能稳定生成高质量语音。
应用与风险¶
潜在用途包括教育、娱乐、辅助沟通、翻译、语音交互等。
存在被滥用的风险(如伪造声音),因此强调需要用户授权,并建议部署检测机制。
当前为研究用途,暂无产品化或公开计划。
3. VALL-E 2¶
3.1 Problem Formulation: Grouped Codec Language Modeling¶
🔧 背景
VALL-E 2 使用现成的神经音频编解码器(audio codec)把语音转换成离散的编码序列(codec codes),
然后把语音合成(TTS)问题变成了一个条件语言建模问题——用文本来预测语音编码。
🧩 分组建模(Grouped Codec Language Modeling)
为了提升效率,VALL-E 2 把原始的 codec code 序列按固定大小分成多个组(每组称为一帧),
这样有几个好处:
减少帧率:可以降低运算频率,提高推理速度。
提升语音质量:因为长上下文不好建模,分组后上下文更短,有利于模型学习。
🧠 训练流程
输入:一段音频
y和对应的文本x编码器把音频转成一个
T × J的编码序列(T 是时间步数,J=8 是每步的编码器层数)。把编码序列按每 G 个时间步切成一组,共有
T/G组。用文本
x作为条件,训练模型预测这些组的概率,使预测越准确越好(最大化似然,或者说最小化负对数似然)。
🗣️ 推理流程(Zero-Shot 推理)
给定一段提示语音和文本:
提示语音来自目标说话人,转成 codec 分组序列
C^P文本包含提示的内容 + 要合成的新内容
模型根据提示的 codec 代码和文本,一步步生成目标语音的 codec 分组,最终还原为语音。
3.2 VALL-E 2 Architecture¶
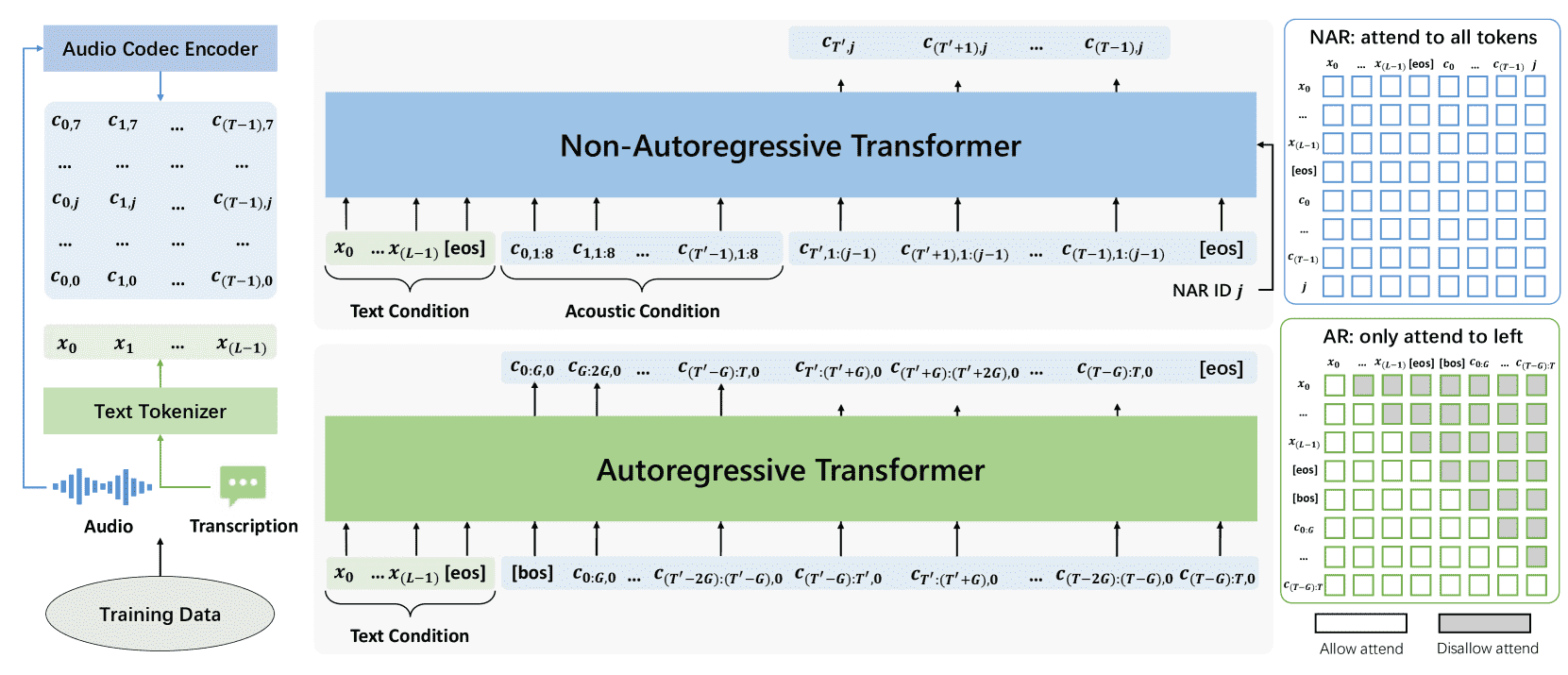
Figure 2: Training overview of VALL-E 2, consisting of an autoregressive and a non-autoregressive Transformer. Note that the autoregressive Transformer is designed to generate grouped codec codes.
VALL-E 2 使用两种 Transformer 模型来生成语音的编码:
自回归模型(AR):
一帧一帧地、按顺序生成每帧的第一个编码序列。
非自回归模型(NAR):
同时生成每帧后续的编码,不用按顺序,提升效率。
这两个模型都用类似的结构:
文本嵌入层(输入文字)
编码嵌入层(处理codec编码)
编码预测层(预测输出)
细节区别包括:
AR 模型多了“组嵌入层”和“组预测层”,用来处理编码分组。
NAR 模型多了“编码 ID 嵌入层”,用来告诉它当前预测哪一组编码。
AR 使用因果注意力(只能看前面),NAR 使用全注意力(可以看全部)。
3.3 VALL-E 2 Training¶
数据要求简单
不需要复杂的对齐信息或多段同一说话人的语音,只需语音和文字一一对应的数据对即可。
训练流程简述
每条训练数据包含一个语音(转为 codec 码)和它的文字(转为 token)。
编码器提取语音的 codec 序列
C = [c0, c1, ..., cT-1],文字变成 token 序列x = [x0, x1, ..., xL-1]。训练两个模型:AR(自回归)模型和NAR(非自回归)模型。这部分先讲 AR。
3.3.1 Autoregressive Model Training¶
目标:根据文字序列,预测第一组 codec 编码(即 c 的第一层)。
方法:
把文字和 codec 分别映射成 embedding 向量。
codec 向量按组(group)拼接(每组大小为 G),形成 group embedding。
把文字、特殊标记
<eos><bos>和 codec group embedding 拼接起来。加上位置编码后送入 Transformer 模型。
每组 codec 的预测,只能参考前面的文字和已预测的 codec(使用因果掩码保证顺序性)。
损失函数是标准的负对数似然(negative log-likelihood)。
3.3.2 Non-Autoregressive Model Training¶
在训练阶段,非自回归模型(NAR)利用自回归模型(AR)生成的首个码序列(code sequence)作为起点,学习并并行预测其余的7个codec层(共8层)对应的码序列。
为增强对说话人信息的建模,训练时将完整的码序列 \(\mathbf{C}\) 划分为:
条件部分(acoustic condition)\(\mathbf{C}_{<T'}\)
目标部分(target codes)\(\mathbf{C}_{\geq T'}\)
其中 \(T'\) 是随机采样的时间步。模型需预测目标码序列 \(\mathbf{c}_{\geq T', j}\),条件包括:
文本序列 \(\mathbf{x}\)
所有条件码序列 \(\mathbf{C}_{<T'}\)
当前codec层 \(j\) 的前置码序列 \(\mathbf{C}_{\geq T', <j}\)
输入嵌入包括:
文本嵌入 \(\mathbf{E}^x\)
条件码与前置目标码的嵌入 \(\mathbf{E}^c\)
codec层ID嵌入 \(\mathbf{e}^j\)
特殊标记
最终输入拼接为:
模型使用全注意力机制,使每个时间步 \(t\) 的预测 \(c_{t,j}\) 能访问全部上下文信息。
训练目标是最小化所有目标码序列 \(\mathbf{c}_{\geq T', j}\) 的负对数似然(NLL)损失。
3.4 VALL-E 2 Inference¶
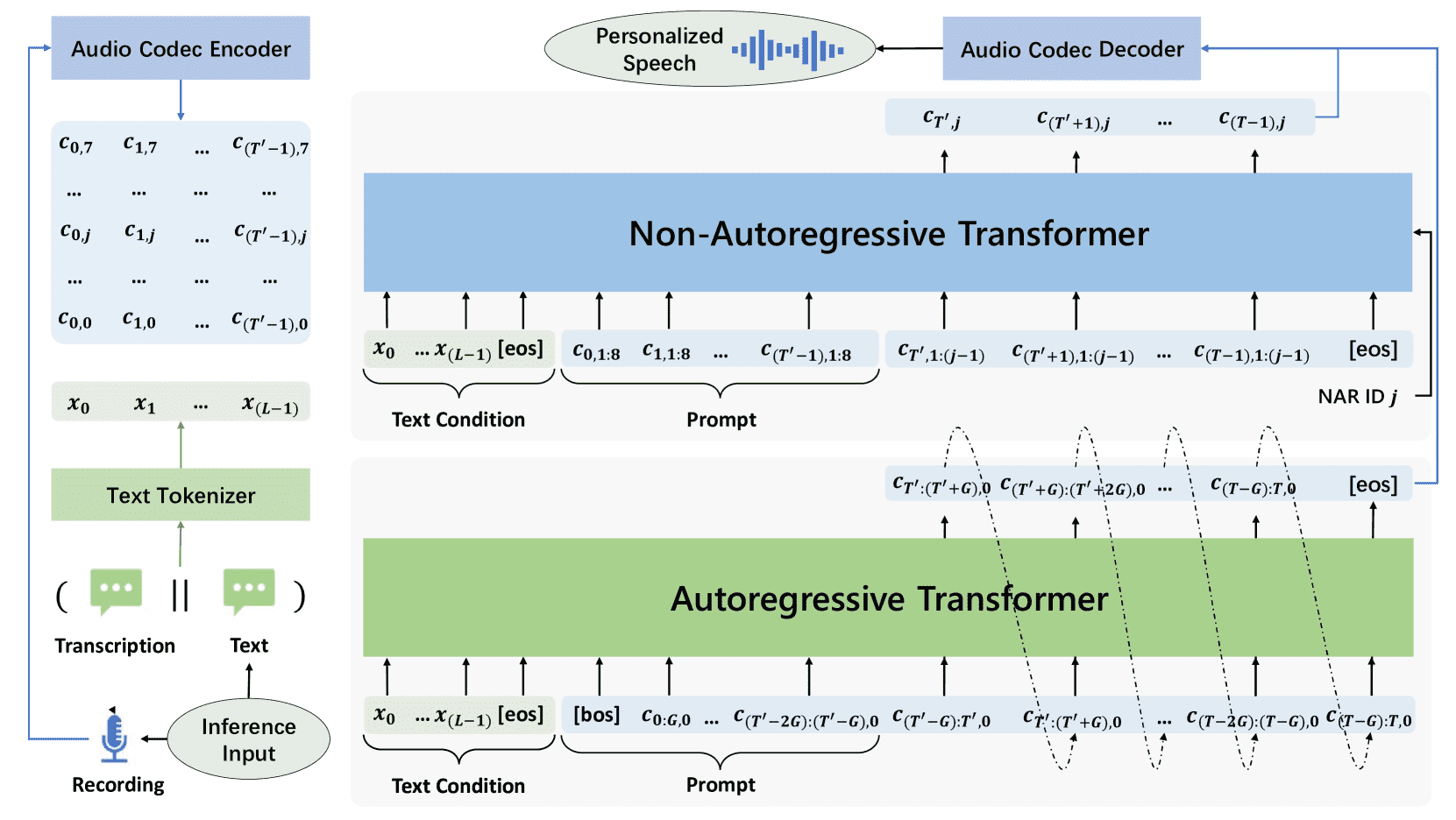
Figure 3:Inference overview of VALL-E 2, which leverages the proposed repetition aware sampling method to predict grouped code sequence during autoregressive model inference.
基本流程(零样本TTS):
输入:一句文本 + 一个未见过说话人的语音样本及对应文本。
文本处理:把语音样本的文本和要生成的文本拼接,用文本编码器编码成条件
x。语音处理:把语音样本输入音频编码器,转成一段语音码(code)作为“提示”。
模型生成:使用这段“提示”和条件文本
x,通过自回归模型(AR) 和 非自回归模型(NAR),预测剩余的语音码。解码输出:将预测出的语音码输入音频解码器,生成目标语音。
3.4.1 Autoregressive Model Inference¶
生成方式:
使用自回归语言模型(AR model),基于文本输入(x)和之前的代码提示(c),逐步生成目标的语音编码(code sequence)。
采用分组生成,一次生成一组编码(每组大小为 G),按时间顺序逐组生成后续编码。
目标函数:
目标是最大化整体生成序列的概率,通过对每一组、每个时间步的概率取对数并求和(log-likelihood 最大化)。
采样方式优化:
与原始 VALL-E 使用的随机采样不同,这里引入了**“重复感知采样”(Repetition Aware Sampling)**机制。
在每一步采样前,先计算该 token 在最近 K 个 token 中出现的频率。
如果重复率太高(超过阈值
tr),就不按常规的 nucleus sampling 选最可能的,而是随机从概率分布中重新采样,避免重复。
📘 重采样机制:Repetition-Aware Sampling(防止重复) 1. 输入:文本条件 x、自回归模型 θ、组大小 G、当前时间步 t、之前生成的编码、top-p 值、重复阈值 tr、重复窗口大小 K。 2. 用模型生成当前 step 的概率分布。 3. 使用 nucleus sampling(基于 top-p)选择当前 token。 4. 检查该 token 是否在最近 K 个 token 中出现次数太多。 5. 如果重复太多,就重新随机采样一个新 token。 6. 输出最终 token。
✅ 目的
防止生成过程中出现“口吃”或“重复词”的现象,提升语音合成的自然性和稳定性。
3.4.2 Non-Autoregressive Model Inference¶
NAR 推理过程(非自回归模型)
给定前一段音频的编码(前缀)和对应的文本,非自回归模型(NAR)用于生成目标音频剩下部分的编码。
初始时,我们已有第一个 code(由自回归模型生成),然后用 NAR 模型逐个生成接下来的 2~8 个编码。
推理公式简化解释:
我们的目标是找到最可能的一组编码,使得在已知文本、前缀音频编码和已生成的编码的基础上,生成的音频尽可能自然。
使用贪婪解码(greedy decoding)逐步生成这 7 个 code(第2到第8个)。
最终生成语音:
将这些 code(从第1个到第8个)输入到音频解码器中,生成最终的个性化语音波形。
VALL-E 2 的能力:
语音克隆: 用一个从未见过的说话人的语音样本做提示(prompt),就能模仿其声音生成语音。
零样本语音续读(zero-shot continuation): 给出完整文本 + 前3秒音频,VALL-E 2 可以自然续读生成后续语音。
4. Experiments¶
4.1 Setups¶
4.1.1 Model Training¶
数据集:用 Libriheavy(带标签的 Librilight)大约 5 万小时英文语音,含 7000 名说话人。
语音处理:文本用 BPE 分词;语音编码用预训练 EnCodec(6Kbit、24kHz);解码用 Vocos。
模型结构:使用和 VALL-E 2 相同的 Transformer 架构;4 个 AR 模型(分组大小为 1/2/4/8),共用一个 NAR 模型。
训练配置:用 16 张 V100 GPU,AdamW 优化器,32k 次 warmup;NAR 模型输入语音长度为当前语音的一半或 3~30 秒间的最大值。
4.1.2 Evaluation Metrics¶
主观指标:
SMOS:评估合成音频与原声的说话人相似度(1-5 分)。
CMOS:评估合成音频相较参考音频的自然程度(-3 至 +3)。
客观指标:
SIM:用 WavLM-TDNN 评估说话人相似度(-1 到 1)。
WER:用 Conformer-Transducer 计算语音识别错误率,衡量鲁棒性。
DNSMOS:用微软的预训练模型评估语音整体质量(1-5 分)。
4.1.3 Evaluation Settings¶
评估数据:
LibriSpeech test-clean:16kHz 英语语音,40 个说话人。
VCTK:48kHz,多口音,108 说话人。
两者都不含训练集说话人,用于零样本语音合成(Zero-shot TTS)。
推理流程:
AR 模型先用重复感知采样生成首段编码(K=10,tr=0.1,top-p ∈ [0, 0.8])。
NAR 模型接着用贪婪解码生成剩余 7 段编码。
每条语音合成采样一次与五次,并评估不同策略下的最佳结果。
评估策略:
排序法:按 SIM > 0.3 时优先比较 WER,否则按 SIM 排序,选出表现最优样本。
指标最大化:分别选出每个指标下得分最高的样本(SIM、WER、DNSMOS)。
4.2 LibriSpeech Evaluation¶
4.2.1 Objective Evaluation¶
核心结论:
VALL-E 2 比 VALL-E 在所有测试中表现更好,尤其在只有一次采样(Single Sampling)时更稳定。
它在 WER(字错误率)和 DNSMOS(语音质量)评分上甚至优于真实语音(Ground Truth)。
技术关键:
引入了重复感知采样(Repetition Aware Sampling),提升了解码稳定性。
使用**分组编码(Group Size)**优化推理效率,同时保持甚至提升性能,特别是在 Group Size 为 2 时效果最好。
小 top-p 采样策略(甚至为 0)帮助生成更稳定、低错误率的语音。
4.2.2 Subjective Evaluation¶
核心结论:在人工评分中,VALL-E 2 的语音相似度和质量评分都超过 VALL-E,甚至超过真实语音。
评估指标:
SMOS:语音与目标说话人相似度。
CMOS:语音质量评分。
技术关键:
VALL-E 2 使用分组编码后,在 SMOS 和 CMOS 上表现优于 VALL-E。
4.2.3 Ablation Study¶
输入消融(Model Input)
移除 prompt 会严重降低语音相似度,说明 prompt(例如参考语音)在保持说话人身份中至关重要。
无论是 AR 模型还是 NAR 模型,prompt 都能显著提升稳定性与相似度。
NAR 模型中,显式分离声学条件训练效果更好。
训练数据量消融
使用 10k 条数据训练已能达到接近 50k 数据的效果。
小于 10k 数据时性能明显下降,尤其在使用参考语音作为 prompt 的设定下。
4.3 VCTK Evaluation¶
4.3.1 Objective Evaluation¶
整体效果:VALL-E 2 在无训练样本(zero-shot)语音合成任务上表现优于旧版 VALL-E,尤其是在 语音鲁棒性(用 WER 字错误率衡量)上更好。
重复感知采样法(Repetition-aware Sampling):
能稳定生成过程,特别是面对多种口音的 VCTK 数据。
单次采样下可将 WER 减半。
五次采样能筛选出最优样本,大幅提升语音质量和稳定性。
分组编码建模(Grouped Code Modeling):
对长提示词(prompt)尤其有效,能减短序列长度,缓解 Transformer 模型对长序列的建模困难,进一步降低 WER。
4.3.2 Subjective Evaluation¶
对 60 个说话人做主观听感评分。
VALL-E 2 在说话人相似度和音质上都超过 VALL-E,使用仅 3 秒的提示语音时就可达到或超过真实语音的水平。
使用 10 秒提示语音时,表现进一步提升,尤其在说话人相似度上。
4.3.3 Ablation Study¶
模型输入的消融:
不输入提示语音(prompt)时,说话人相似度大幅下降,说明 prompt 是建模说话人信息的关键。
即便在非自回归模型(NAR)中,文本输入也依然是必要的。
训练数据量的影响:
训练数据越多,说话人相似度(SIM)越高。
3 秒提示语音下,需要更多数据来降低 WER。
但感知质量评分(DNSMOS)并非训练数据越多越好,模型容量有限时会有平衡。
5. Conclusion¶
我们提出了 VALL-E 2,它是一种语言建模方法,首次实现了在人类水平上的零样本文本转语音(TTS)合成。相比前代,VALL-E 2 引入了两个简单有效的新技术:一种是让合成更稳定的“重复感知采样”,另一种是提高效率的“分组编码建模”。它能稳定合成包括复杂和重复性强的句子。
潜在影响方面:因为 VALL-E 2 能合成保持说话人身份的语音,存在被滥用的风险,比如伪造身份或模仿他人声音。我们的实验假设用户同意让模型合成他们的声音。若推广到未见过的说话人,必须建立获得说话人授权的机制,并配套语音合成检测技术。同时,后续开发会遵循微软 AI 责任原则。