2305.14251_FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation¶
标题:FActScore:长格式文本生成中事实精度的细粒度原子评估
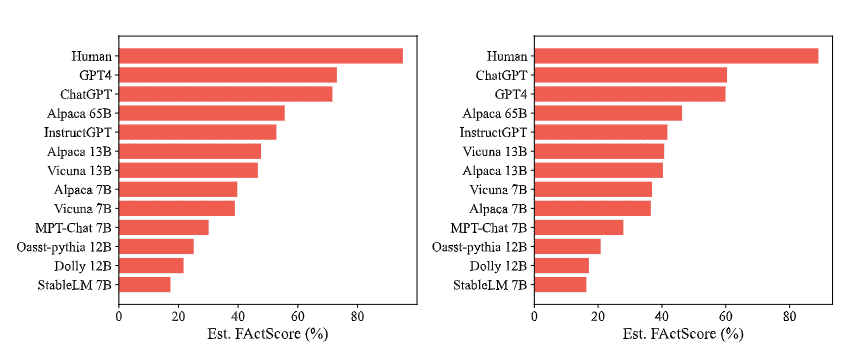
Evaluating the factuality of long-form text generated by large language models (LMs) is non-trivial because (1) generations often contain a mixture of supported and unsupported pieces of information, making binary judgments of quality inadequate, and (2) human evaluation is time-consuming and costly. In this paper, we introduce FACTSCORE, a new evaluation that breaks a generation into a series of atomic facts and computes the percentage of atomic facts supported by a reliable knowledge source. We conduct an extensive human evaluation to obtain FACTSCOREs of people biographies generated by several state-of-the-art commercial LMs – InstructGPT, ChatGPT, and the retrieval-augmented PerplexityAI – and report new analysis demonstrating the need for such a fine-grained score (e.g., ChatGPT only achieves 58%). Since human evaluation is costly, we also introduce an automated model that estimates FACTSCORE using retrieval and a strong language model, with less than a 2% error rate. Finally, we use this automated metric to evaluate 6,500 generations from a new set of 13 recent LMs that would have cost $26K if evaluated by humans, with various findings: GPT-4 and ChatGPT are more factual than public models, and Vicuna and Alpaca are some of the best public models. FACTSCORE is available for public use via pip install factscore.
评估由大型语言模型 (LM) 生成的长格式文本的真实性并非易事,因为 (1)生成通常包含受支持和不支持的信息片段的混合,使得对质量的二元判断不足,以及 (2) 人工评估既耗时又昂贵。在本文中,我们引入了FACTSCORE,这是一种新的评估,它将生成分解为一系列原子事实,并计算由可靠知识来源支持的原子事实的百分比。我们进行了广泛的人工评估,以获得由几个最先进的商业 LM——InstructGPT、ChatGPT 和检索增强的 PerplexityAI ——生成的人物传记的 FACTSCORE,并报告了新的分析,证明需要如此细粒度的分数(例如,ChatGPT 仅达到 58%)。由于人工评估成本高昂,我们还引入了一个自动化模型,该模型使用检索和强大的语言模型来估计 FACTSCORE,错误率低于 2%。最后,我们使用这个自动化指标来评估一组新的 13 个最新 LM 的 6,500 代,如果由人类评估,这些 LM 将花费 26 美元,并有各种发现:GPT-4 和 ChatGPT 比公共模型更真实,而 Vicuna 和 Alpaca 是一些最好的公共模型。FACTSCORE 可通过“pip install factscore”供公众使用。
备注
FactScore是一个用于人类和模型基础评估的度量标准,它将LLM的生成内容分解为“原子事实”,最终得分为每个原子事实的准确性之和。