1806.03377_PipeDream: Fast and Efficient Pipeline Parallel DNN Training¶
组织: Microsoft Research, Carnegie Mellon University, Stanford University
标签: Pipeline_Parallelism
这段内容介绍了一个名为 PipeDream 的深度神经网络(DNN)训练系统,专为在GPU上进行分布式训练而设计。PipeDream通过跨多台机器管道化(pipelining)计算,从而实现了计算的并行化,并能有效解决在大型模型和/或有限的网络带宽下,数据并行训练方式所面临的高通信与计算比率所带来的瓶颈问题。
- 关键技术点
一前一后(1F1B) 调度策略
权重存储(Weight Stashing)
垂直同步(Vertical Sync)
Abstract¶
PipeDream 是一种适用于 GPU 的深度神经网络 (DNN) 训练系统,它通过在多台机器上流水线执行来并行计算。其管道并行计算模型避免了当大型模型和/或有限的网络带宽导致高通信计算比时数据并行训练面临的速度变慢。
相对于数据并行训练,PipeDream 将大型 DNN 的通信减少了高达 95%,并允许通信和计算的完美重叠。
PipeDream 通过系统地划分 DNN 层来平衡工作并最大限度地减少通信,对所有可用的 GPU 进行版本控制以实现向后传递的正确性,并以循环方式安排不同输入的向前和向后传递以优化“达到目标的准确性”,从而保持所有可用 GPU 的生产力。
在两个不同的集群上使用 5 个不同 DNN 进行的实验表明,与数据并行训练相比,PipeDream 的准确率提高了 5 倍。
1. Introduction¶
- 传统数据并行训练:
数据并行是最常用的训练方式,其中每个工作机器(worker)处理一部分训练数据,模型在每个工作机器上复制,经过计算后各个工作机器汇总权重更新。
但是,随着模型规模的增大,通信负担也随之增加,尤其当模型和数据变得非常大时,通信时间可能会超过计算时间,造成训练瓶颈。
- 模型并行训练:
模型并行是将一个模型分割成多个部分,分别由不同的工作机器计算。
优势:模型并行性支持训练非常大的模型。
- 劣势
- 计算资源可能无法充分利用,因为:
- 单一工作节点的使用(if each layer is assigned to a worker)
特点:将模型的每一层分配给一个工作节点(worker)
只有一个节点在进行实际计算,其他节点处于空闲状态,无法高效利用。
- 计算与通信不能重叠(if each layer is partitioned)。
特点:将每一层的计算进一步分割成多个部分
在传统的模型并行性中,数据传输和计算常常是串行进行的,导致时间上的浪费。
- 分割模型的难度
将深度神经网络(DNN)模型合理地分配到多个工作节点是一个非常具有挑战性的任务。
即使是经验丰富的机器学习专家,在这方面也会面临效率低下的问题,因为不合理的分割可能导致性能下降。
- PipeDream的创新: 流水线并行(pipeline-parallel training)
PipeDream结合了管道(pipelining)、模型并行和数据并行,通过优化工作负载分配、减少通信开销、合理安排前向和反向传递等方式来提升效率。
它将训练任务分为多个阶段(每个阶段处理不同的层),并将这些阶段分配给不同的机器。通过多输入处理和层的并行化,管道始终保持满负载,确保所有工作机器都在忙碌,避免空闲。
PipeDream还通过调整参数版本,确保在反向传递过程中使用更新后的参数,从而避免计算错误。
- 总结:
PipeDream提出了一种新的训练系统,通过管道化技术结合模型并行和数据并行,有效解决了传统训练方法中的通信瓶颈问题,提升了大规模DNN模型训练的效率。
该系统通过优化任务分配、重叠计算和通信、管理权重版本等技术,显著提升了训练速度,尤其适用于通信负担较重的场景。
2. Background & Related Work¶
这段内容介绍了深度神经网络(DNN)训练中的一些常见方法和挑战,重点讨论了数据并行、模型并行以及它们在分布式训练中的局限性
2.1 DNN Training¶
Data Parallelism¶
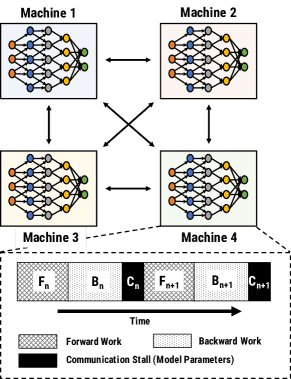
Figure 2: Example data-parallel setup with 4 machines. Timeline at one of the machines shows communication stalls during model parameter exchanges.¶
在数据并行训练中,训练数据被分割到多个GPU上,每个GPU都拥有模型的完整副本,并在自己的数据子集上进行训练。不同GPU之间定期同步权重。
- BSP(Bulk Synchronous Parallel):
同步训练方式,在每个小批量(minibatch)结束后进行权重同步,确保梯度计算时使用的是最新的权重,保证统计效率。
然而,这种方法的缺点是,GPU在等待其他GPU同步梯度时会产生停顿,导致硬件效率降低。
- 异步并行(ASP):
与BSP不同,异步并行让每个GPU不必等待其他GPU的梯度同步,可以减少GPU的空闲时间,从而提高硬件效率。
但这种方式会导致使用过时的权重计算梯度,影响统计效率。
实验结果表明,异步并行方法并没有显著减少训练时间,且对训练的最终效果有一定负面影响。
Model Parallelism¶
在模型并行中,模型被分割到多个GPU上,每个GPU负责模型的一部分。当模型太大无法放入单个GPU时,采用这种方式。
- 然而,模型并行训练有两个主要问题:
GPU资源利用不足:每个GPU只能在某个特定阶段工作,导致GPU有时会空闲。传统的模型并行不支持多小批量的管道化(pipelining),这使得GPU资源无法充分利用。
模型划分的困难:将DNN模型分割到多个GPU上的工作通常由程序员手动完成,这不仅增加了难度,还可能导致效率低下。
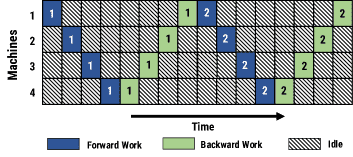
Figure 3: Model parallel training with 4 machines. Numbers indicate minibatch ID. For simplicity, here we assume that forward and backward work in every stage takes one time unit, and communicating activations across machines has no overhead.¶
3. Parallel Training in PipeDream¶
这段内容详细介绍了PipeDream框架中如何结合数据并行性和模型并行性,通过流水线并行(Pipeline Parallelism, PP)来加速深度神经网络(DNN)模型的训练。
3.1 Pipeline Parallelism¶
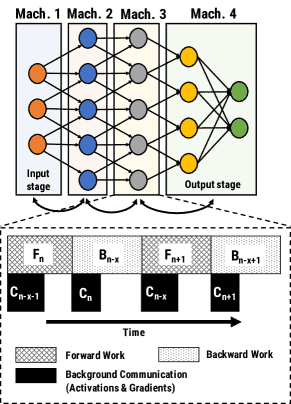
Figure 4: An example pipeline-parallel assignment with four machines and an example timeline at one of the machines, highlighting the temporal overlap of computation and activation / gradient communication.¶
- 流水线并行将神经网络的各层分割成多个阶段
每个阶段包含一个连续的层,并分配到单独的GPU上。
每个阶段执行该层的前向和反向传播过程。
通过将多个minibatch(小批量数据)按顺序注入流水线,并让每个阶段在处理不同minibatch时交替进行前向和反向传播,从而提高了计算和通信的重叠度,使得GPU不会处于空闲状态。
图 4 显示了一个管道并行分配的简单示例,其中 DNN 被拆分到四台机器上
- 说明:
单个minibatch:在最简单的情况下,流水线只处理一个minibatch,每个阶段按照顺序执行前向传播和反向传播。
多个minibatch:多个minibatch会被同时传递通过流水线,从而保证每个GPU的资源被充分利用,并且各阶段的计算和通信能够重叠,提升硬件效率。
- 优点:
减少通信量:相比于BSP,每台机器只需要传输本层的输出,而不需要传输所有参数,减少了大量的通信开销。
计算与通信重叠:由于不同minibatch的前向和反向传播交替进行,计算和通信的重叠使得整体训练时间减少。
- 将流水线模型并行和数据并行相结合
原因:模型并行和数据并行与流水线是正交的,PipeDream 旨在以最小化整体训练时间
- 使用些方案需要解决三个挑战:
自动分配工作:如何在多台机器上分配网络层,确保负载均衡,并减少通信延迟。
计算调度:如何调度计算任务,以最大化吞吐量并保证模型训练的顺利进行。
应对异步问题:流水线并行可能导致参数不同步,PipeDream设计了一些方法来减少这种不一致对训练的影响。
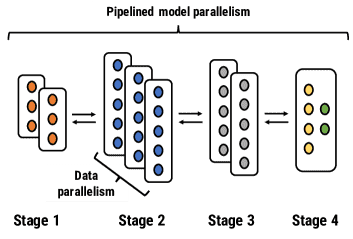
Figure 6: Pipeline Parallel training in PipeDream combines pipelining, model- and data-parallel training.¶
3.2 Partitioning Layers Across Machines¶
为了减少训练时间,PipeDream会自动分析每个层的计算时间和通信成本,并通过算法优化层的分配,使得每个阶段的工作量相当,且尽量减少机器间的通信。
- 具体步骤包括:
模型分析:在单机上运行模型,记录每个层的计算时间、输出大小和参数大小。
分配算法:根据计算和通信成本,确定最优的分配方案,尽量减少负载不平衡和通信开销。
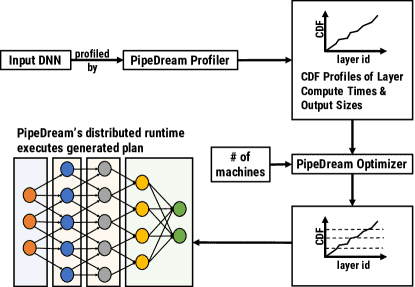
Figure 7: PipeDream’s automated mechanism to partition DNN layers into stages. PipeDream first profiles the input DNN, to get estimates for each layer’s compute time and output size. Using these estimates, PipeDream’s optimizer partitions layers across available machines.¶
- 知识-所有通信都分三个步骤进行:
1.将数据从 GPU 移动到发送方的 CPU,
2.通过网络将数据从发送方发送到接收方
3.将数据从 CPU 移动到接收方的 GPU
3.3 Work Scheduling¶
- PipeDream的调度机制需要在前向传播和反向传播之间进行选择。
由于每个阶段都可能同时处理前向传播和反向传播的minibatch,简单的调度策略可能导致某些GPU空闲。
PipeDream提出了 一前一后(1F1B) 调度策略,使得每个GPU交替进行前向和反向传播,从而避免空闲,并确保训练进度。
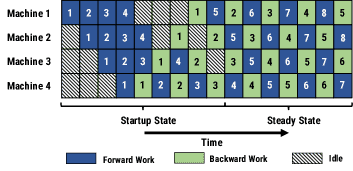
Figure 8: An example pipeline with 4 machines, showing startup and steady states.¶
- 说明
图 8 显示了一个管道的相应计算时间线,该管道有 4 个阶段,每个阶段在一台机器上运行。
此配置的 NOAM 为 4。
在启动阶段,input 阶段只允许四个小批量传播到输出阶段。
输出阶段完成第一个小批量的正向传播后,它会对同一小批量执行反向传播,然后开始为后续小批量交替执行正向和反向传播。
随着向后传播开始传播到管道中的早期阶段,每个阶段都开始在不同小批量的正向和向后传递之间交替。
如图所示,在稳定状态下,每台机器都忙于对小批量进行前向传递或向后传递。
对 1F1B 来说,不要求前向传播和反向传播一样长。事实上,我们观察到,在实践中,反向传播总是大于向前传递,但 1F1B 仍然是一种有效的调度机制。
在管道中的每一阶段的 1F1B 调度策略和跨复制阶段进行负载平衡的循环调度策略都是静态策略。因此,它们可以由每台机器独立执行,而无需昂贵的分布式协调。
3.4 Effective Learning¶
问题:由于流水线并行中,每个minibatch的前向和反向传播使用的参数版本可能不同,导致梯度更新可能不一致,这会影响模型的收敛。
- 为了避免这种问题,PipeDream使用了两种方法:
- 权重存储(Weight Stashing):
通过在每个 minibatch 中保留多个版本的权重,确保前向传播和反向传播都使用相同版本的权重。
核心思想:存储每个 minibatch 在每个阶段使用的权重。
- 具体步骤:
前向传播:每个阶段在处理一个 minibatch 时,使用的是当前最新的权重进行前向计算。
权重存储:在完成前向传播后,存储当前阶段使用的权重版本。这些权重被称为“存储的权重”。
反向传播:当进行反向传播时,使用存储的权重进行梯度计算,而不是使用当前的最新权重。这确保了前向传播和反向传播都使用相同的权重版本。
- 垂直同步(Vertical Sync):解决了跨不同阶段的权重不一致问题
核心思想:保持管道中每个阶段(stages)的权重版本一致,确保每个 minibatch 使用相同版本的权重进行前向传播和反向传播。
在每个阶段中,权重更新是异步的,但为了保持一致性,垂直同步强制确保:
- 具体步骤:
初始化:在管道的第一个阶段,当 minibatch 进入时,它会带上输入阶段最新的权重版本。这意味着每个 minibatch 都会根据输入阶段的权重版本来进行计算。
前向传播:在管道中的每个阶段,前向传播都使用存储的权重版本进行计算,而不是使用当前的最新权重。这个“存储的权重版本”是由输入阶段决定的,因此所有阶段的前向传播都使用相同的权重。
反向传播:一旦每个阶段完成前向传播,它们会进行反向传播,并使用相同的存储权重版本来计算梯度。
权重更新:完成反向传播后,权重更新被应用到各个阶段,更新后的权重成为“最新的权重”。
同步:在 Vertical Sync 中,每个 minibatch 在经过管道时,都保持使用相同版本的权重。这是通过同步所有阶段的权重版本来实现的。
- 过时性(Staleness)
在 Weight Stashing 中,每个阶段都使用“存储的”版本(即更新前的权重),这可能导致一些阶段的权重较为陈旧(即过时性),但这样可以保证前向和反向传播的一致性。
在 Vertical Sync 中,每个 minibatch 在进入管道时会使用最新的权重版本,从而减少了不同阶段之间的权重版本不一致性,保持了更高的同步性。
- 区别:
Weight Stashing 主要是通过存储每个 minibatch 使用的权重,确保前向和反向传播使用相同的权重版本,防止梯度计算的不一致。
Vertical Sync 更加注重跨阶段的同步,确保每个 minibatch 在整个管道中使用相同版本的权重进行前向和反向传播,从而消除跨阶段的不一致性。
- 关注的范围不同:
Weight Stashing:关注单个阶段内的前向和反向传播权重一致性,确保同一个 minibatch 在前后传播时使用相同的权重。
Vertical Sync:关注不同阶段之间的权重一致性,确保同一个 minibatch在跨阶段传递时使用相同版本的权重。
- 目标相同,但切入点不同:
Weight Stashing 解决的是前后传播的时间不一致带来的权重差异。
Vertical Sync 解决的是跨阶段的空间不一致带来的权重差异。
3.5 GPU Memory Management¶
在流水线并行中,由于需要同时处理多个minibatch,每个阶段的GPU内存需求会有所不同。PipeDream通过预先计算每个阶段所需的内存并统一分配,避免了动态内存分配带来的性能瓶颈。
总结¶
这段内容介绍了如何通过结合流水线并行、模型并行和数据并行,设计出一个高效的训练系统,PipeDream框架通过优化层分配、调度策略、权重一致性维护和内存管理,显著提高了训练效率,减少了通信开销,并解决了因异步更新造成的不一致问题。
4. Implementation¶
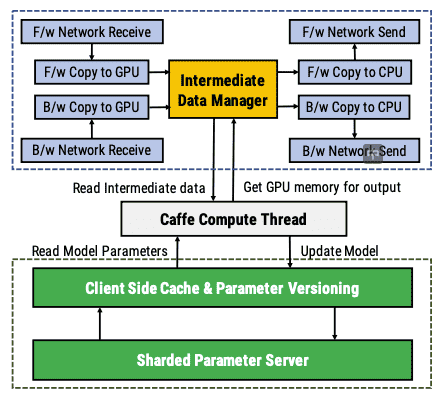
Figure 9: Architecture of the stage runtime and integration with Caffe. PipeDream provides the ML worker thread (Caffe) pointers to GPU memory containing layer input data, parameters, and buffers for recording layer outputs and parameter updates. PipeDream manages buffer pools, and handles all intra- and inter-machine communication.¶
PipeDream 是一种用于训练深度神经网络(DNN)的大规模分布式训练框架,利用 GPU 并行处理和多机器的资源优化训练过程。
系统输入和初始化¶
输入:PipeDream 的输入包括:模型架构、训练数据集以及将用于训练的 GPU 数量。
初始化:PipeDream 会在单个机器上使用训练数据的子集对模型进行分析(profiling)。它首先对模型进行分段(partition),将 DNN 模型划分为多个阶段(stage),并将每个阶段分配到特定的 GPU 上执行。
阶段分配:每个阶段负责模型的不同部分,且部分阶段可以进行复制以提高计算效率。
Stage Runtime 架构¶
C++库接口:PipeDream 的接口是通过一个 C++ 库来实现的,负责管理模型参数和中间数据,并将其传递给在 GPU 上运行的机器学习(ML)工作线程。这个线程使用的是 Caffe,但也可以扩展支持 TensorFlow、MXNet 和 CNTK 等其他 ML 框架。
内存管理:每个机器初始化时会为其分配的阶段初始化 GPU 数据结构,分配内存存储输入激活值、权重、梯度等。
机器通信¶
ZeroMQ 通信:不同机器之间的通信使用 ZeroMQ 和自定义高效的序列化方案,以保证数据的快速传输和低延迟。
检查点与容错¶
检查点机制:PipeDream 定期保存模型参数的检查点,以确保在出现故障时能够恢复。每个阶段在处理完一个 epoch 的最后一个 minibatch 后,都会本地保存检查点。若某个阶段失败,可以从上一个成功保存的 epoch 重新开始训练,而不需要全局同步。
总结¶
【总结】:PipeDream 是一种优化大规模神经网络训练的框架,通过将训练过程分解为多个阶段,结合 GPU 资源和分布式参数服务器,提升了训练效率。其通过创新的调度算法和内存管理策略,使得多机器、多 GPU 环境下的深度学习训练更加高效和容错。
5. Evaluation¶
主要是对比 PipeDream 和传统的 数据并行训练(Data-parallel training)以及 模型并行训练(Model-parallel training)的效果。
核心结论¶
结合流水线并行、模型并行和数据并行的方式比单独使用模型并行或数据并行效果更好。这表明,单独使用其中一种并行方式并不能充分利用计算资源,结合多种方式能更高效地训练模型。
PipeDream大大减少了与数据并行训练相比的通信开销。数据并行训练通常会面临较大的通信开销,而PipeDream通过优化通信策略,减少了这一开销。
对于计算和通信比率较低的配置,PipeDream的性能提升更为显著。当通信开销较高时,PipeDream的优势更加明显。
5.1 Experimental Setup¶
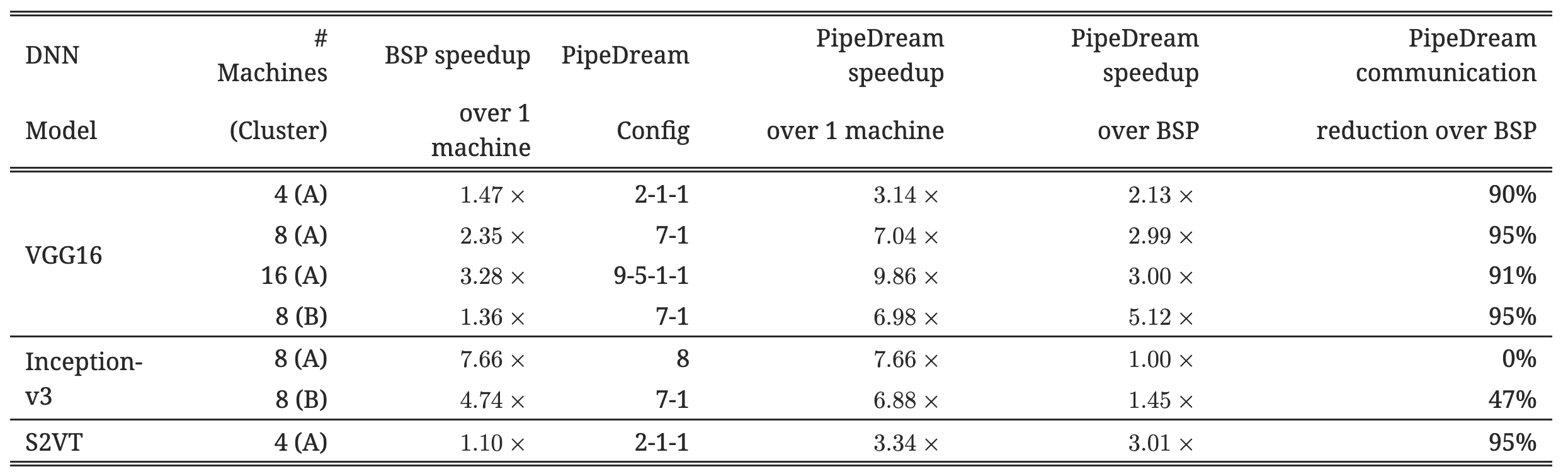
Table 1:Summary of results comparing PipeDream with data-parallel configurations (BSP) when training models to their advertised final accuracy. “PipeDream config” represents the configuration generated by our partinioning algorithm—e.g., “2-1-1” is a configuration in which the model is split into three stages with the first stage replicated across 2 machines.¶
- 数据集:
ImageNet 1K:大规模视觉识别挑战赛的数据集,包括约130万张训练图像,分为1000个类别。
Microsoft Video Description (MSVD):包含1970个YouTube视频,用于视频转录任务。
- 集群:
Cluster-A:NVIDIA Titan X GPU,连接带宽为25 Gbps,以此集群进行训练实验。
Cluster-B:AWS上的NVIDIA V100 GPU,连接带宽为10 Gbps。Cluster-B的GPU更强,但网络速度较慢。
- 模型和训练方法:
实验使用了三种DNN模型:VGG16、Inception-v3和S2VT。
其中,VGG16和Inception-v3使用ImageNet数据集,S2VT使用MSVD数据集。
使用了 SGD 或 RMSProp 优化算法来训练模型,学习率和动量参数根据模型进行调整。
- PipeDream的实现与对比:
为了评估PipeDream的效果,实验中与数据并行(BSP)和单机训练进行对比。
PipeDream与开源的 GeePS(一个高效的数据并行训练系统)进行了比较,结果表明PipeDream的性能至少与GeePS持平,甚至在某些情况下更优。
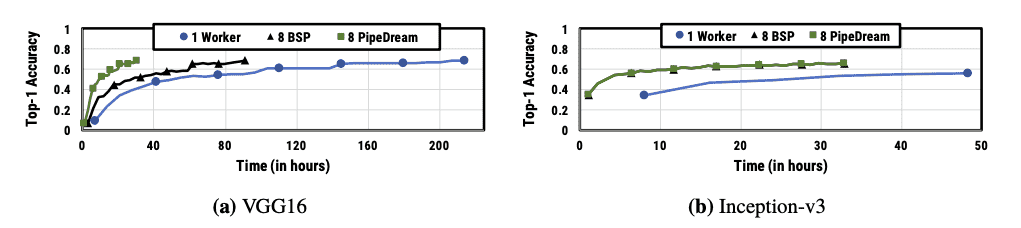
Figure 10: Accuracy vs. time for VGG16 and Inception-v3 with 8 machines on Cluster-A¶
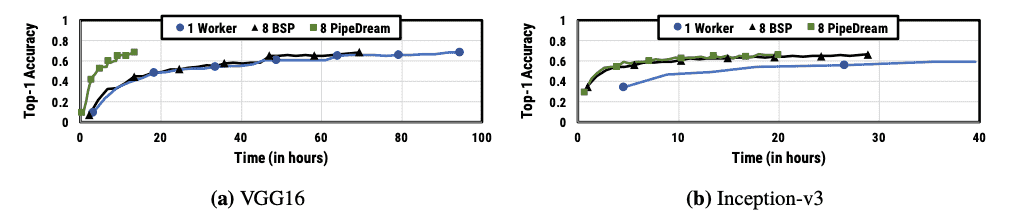
Figure 11: Accuracy vs. time for VGG16 and Inception-v3 with 8 machines on Cluster-B¶
- 实验结果
- VGG16和Inception-v3在Cluster-A和Cluster-B上的训练时间对比:
对比 BSP(基本同步并行)和 PipeDream,VGG16的训练时间缩短了7倍以上,而Inception-v3在Cluster-A上的表现接近BSP,主要是因为其通信开销较小,BSP可以接近完美扩展。
在Cluster-B,由于V100 GPU的计算能力较强,通信开销对PipeDream的影响较小,使得PipeDream相较于BSP的提升更为显著。
- 使用更多机器的效果:
随着机器数量的增加,BSP的通信开销会显著增加,导致性能提升较为有限。
相比之下,PipeDream的性能提升显著,随着机器数量的增加,PipeDream的加速比比BSP更高。
- 与异步并行(ASP)的对比:
ASP没有同步机制,计算速度较快,但由于其统计效率差,导致训练效果不佳。 PipeDream相对于ASP在同样机器配置下的训练时间要短得多。
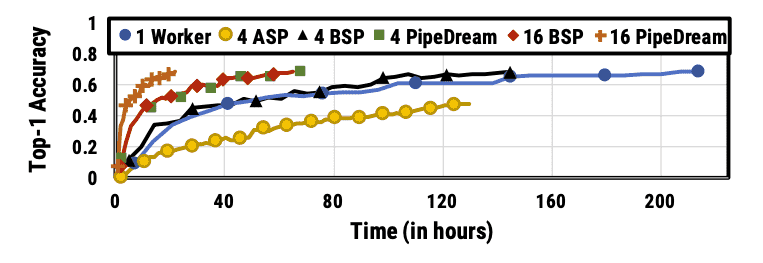
Figure 12: Accuracy vs. time for different configurations for VGG16 on Cluster-A with 4 and 16 workers.¶
- 不同并行方式的比较
模型并行(没有流水线或数据并行):最慢。
流水线并行(没有数据并行的情况下的模型并行):较快,但仍逊色于数据并行训练。
PipeDream:结合了模型并行、流水线并行和数据并行,是训练速度最快的方式。
实验表明,PipeDream结合多种并行方式显著降低了训练时间,尤其是在机器数增加时,优势尤为明显。