Retrieval-Augmented Generation for Large Language Models: A Survey¶
组织:同济大学上海智能自主系统研究院、复旦大学计算机学院、上海市数据科学重点实验室
LLMs 展示了令人印象深刻的功能,但遇到了幻觉、过时的知识以及不透明、无法追踪的推理过程等挑战。RAG 通过整合来自外部数据库的知识,已成为一种很有前途的解决方案。这提高了生成的准确性和可信度,特别是对于知识密集型任务,并允许持续的知识更新和特定领域信息的集成。RAG 将 LLMs 的内在知识与外部数据库的庞大动态存储库协同融合。这篇全面的综述论文详细研究了 RAG 范式的进展,包括 Naive RAG、Advanced RAG 和 Modular RAG。它仔细审查了 RAG 框架的三方基础,包括检索、生成和增强技术。本白皮书重点介绍了嵌入每个关键组件的最新技术,提供了对 RAG 系统进步的深刻理解。此外,本文还介绍了最新的评估框架和基准。最后,本文描述了目前面临的挑战,并指出了潜在的研发途径。
Large Language Models (LLMs) showcase impressive capabilities but encounter challenges like hallucination, outdated knowledge, and non-transparent, untraceable reasoning processes. Retrieval-Augmented Generation (RAG) has emerged as a promising solution by incorporating knowledge from external databases. This enhances the accuracy and credibility of the generation, particularly for knowledge-intensive tasks, and allows for continuous knowledge updates and integration of domain-specific information. RAG synergistically merges LLMs’ intrinsic knowledge with the vast, dynamic repositories of external databases. This comprehensive review paper offers a detailed examination of the progression of RAG paradigms, encompassing the Naive RAG, the Advanced RAG, and the Modular RAG. It meticulously scrutinizes the tripartite foundation of RAG frameworks, which includes the retrieval, the generation and the augmentation techniques. The paper highlights the state-of-the-art technologies embedded in each of these critical components, providing a profound understanding of the advancements in RAG systems. Furthermore, this paper introduces up-to-date evaluation framework and benchmark. At the end, this article delineates the challenges currently faced and points out prospective avenues for research and development.
备注
这篇论文探讨了RAG如何通过整合外部知识来增强LLMs的能力,解决诸如幻觉(hallucination)和信息过时等挑战。深入研究了不同的RAG范式,包括简单RAG、先进RAG和模块化RAG,并考察了检索、生成和增强技术的基本组成部分。
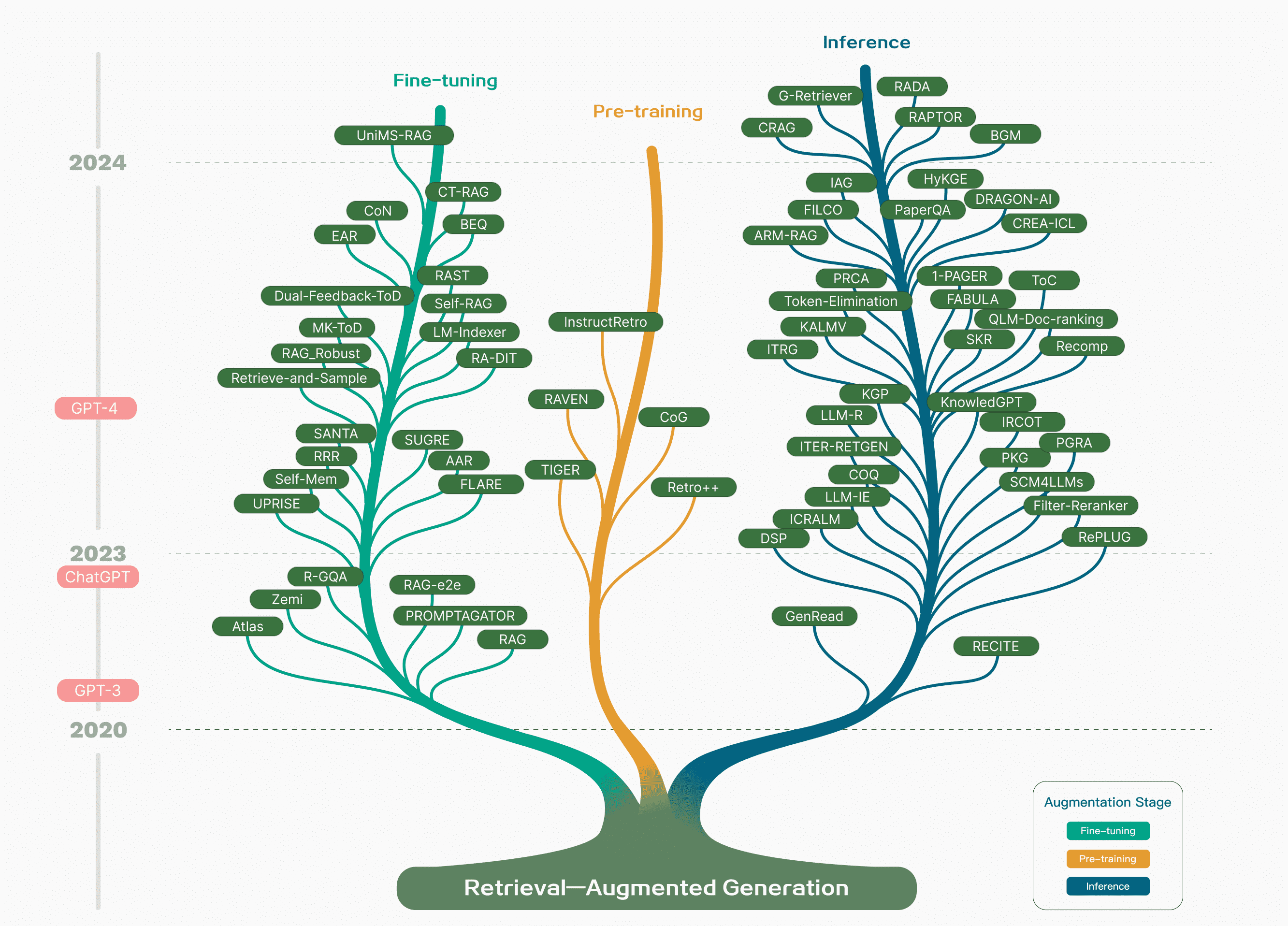
Figure 1:Technology tree of RAG research. The stages of involving RAG mainly include pre-training, fine-tuning, and inference. With the emergence of LLMs, research on RAG initially focused on leveraging the powerful in context learning abilities of LLMs, primarily concentrating on the inference stage. Subsequent research has delved deeper, gradually integrating more with the fine-tuning of LLMs. Researchers have also been exploring ways to enhance language models in the pre-training stage through retrieval-augmented techniques.图 1:RAG 研究的技术树。涉及 RAG 的阶段主要包括预训练、微调和推理。随着LLM的出现,对 RAG 的研究首先集中在利用 LLMs的能力,即主要集中在推理阶段。随后的研究更加深入,逐渐更多地与LLMs的微调结合起来。研究人员还一直在探索通过检索增强技术在预训练阶段增强语言模型的方法。¶
大模型时代RAG的发展轨迹呈现出几个鲜明的阶段特征。
最初,RAG 的诞生恰逢 Transformer 架构的兴起,专注于通过预训练模型 (PTM) 融入额外知识来增强语言模型。这个早期阶段的特点是旨在完善预训练技术的基础工作。
ChatGPT 的随后到来标志着一个关键时刻, LLM展示了强大的上下文学习(ICL)能力。 RAG研究转向为LLMs提供更好的信息,以在推理阶段回答更复杂和知识密集型的任务,从而导致RAG研究的快速发展。
随着研究的进展,RAG的增强不再局限于推理阶段,而是开始更多地与LLM微调技术相结合。
备注
第二部分介绍了RAG的主要概念和当前的范式。以下三个部分分别探讨核心组件——“检索”、“生成”和“增强”。第三节重点介绍检索中的优化方法,包括索引、查询和嵌入优化。第四部分集中于检索后过程和生成中的LLM微调。第五节分析了三个增强过程。第六节重点介绍RAG的下游任务和评估体系。第七节主要讨论RAG当前面临的挑战以及未来的发展方向。最后,第八节对本文进行了总结。
II. Overview of RAG¶
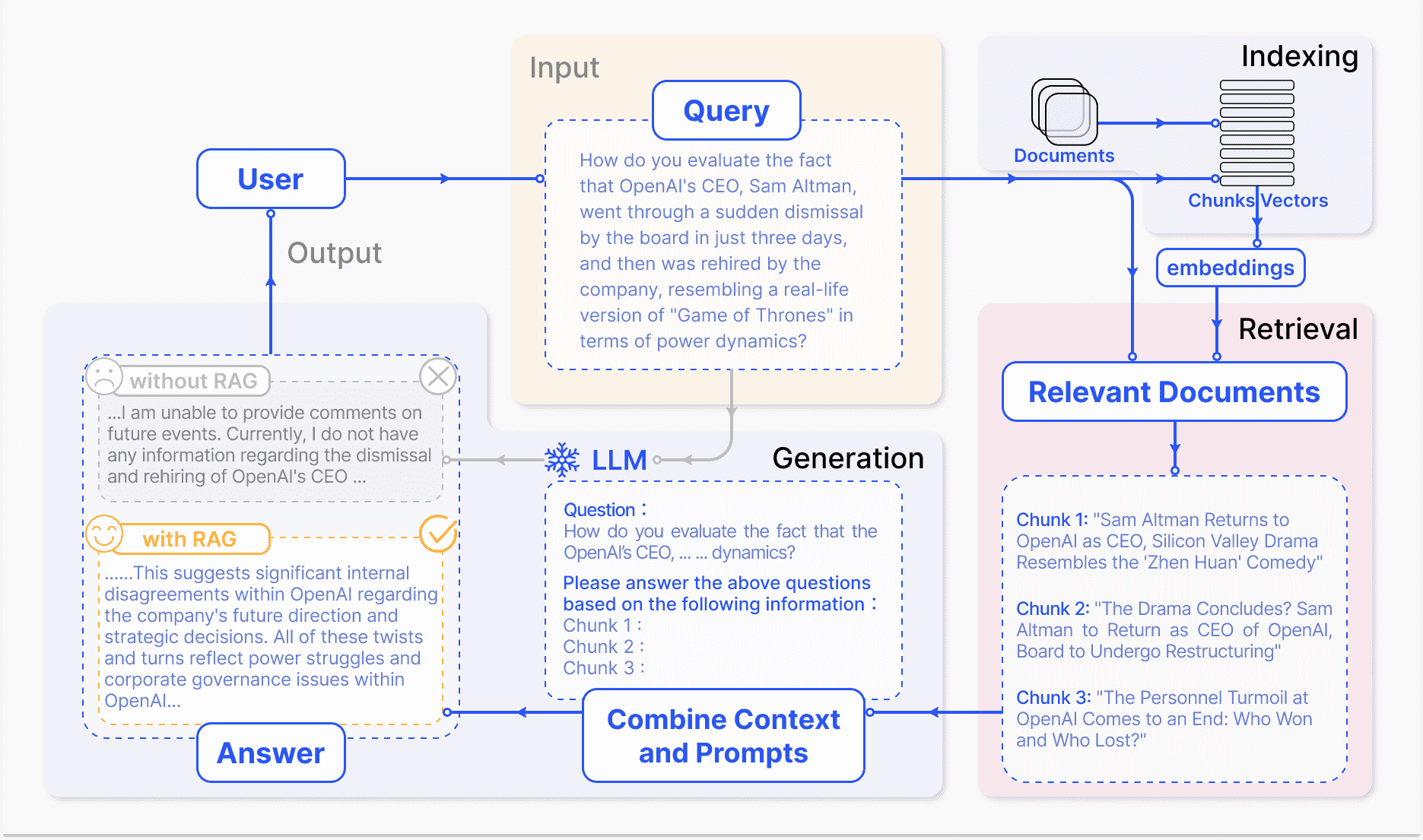
Figure 2: A representative instance of the RAG process applied to question answering. It mainly consists of 3 steps. 1) Indexing. Documents are split into chunks, encoded into vectors, and stored in a vector database. 2) Retrieval. Retrieve the Top k chunks most relevant to the question based on semantic similarity. 3) Generation. Input the original question and the retrieved chunks together into LLM to generate the final answer.¶
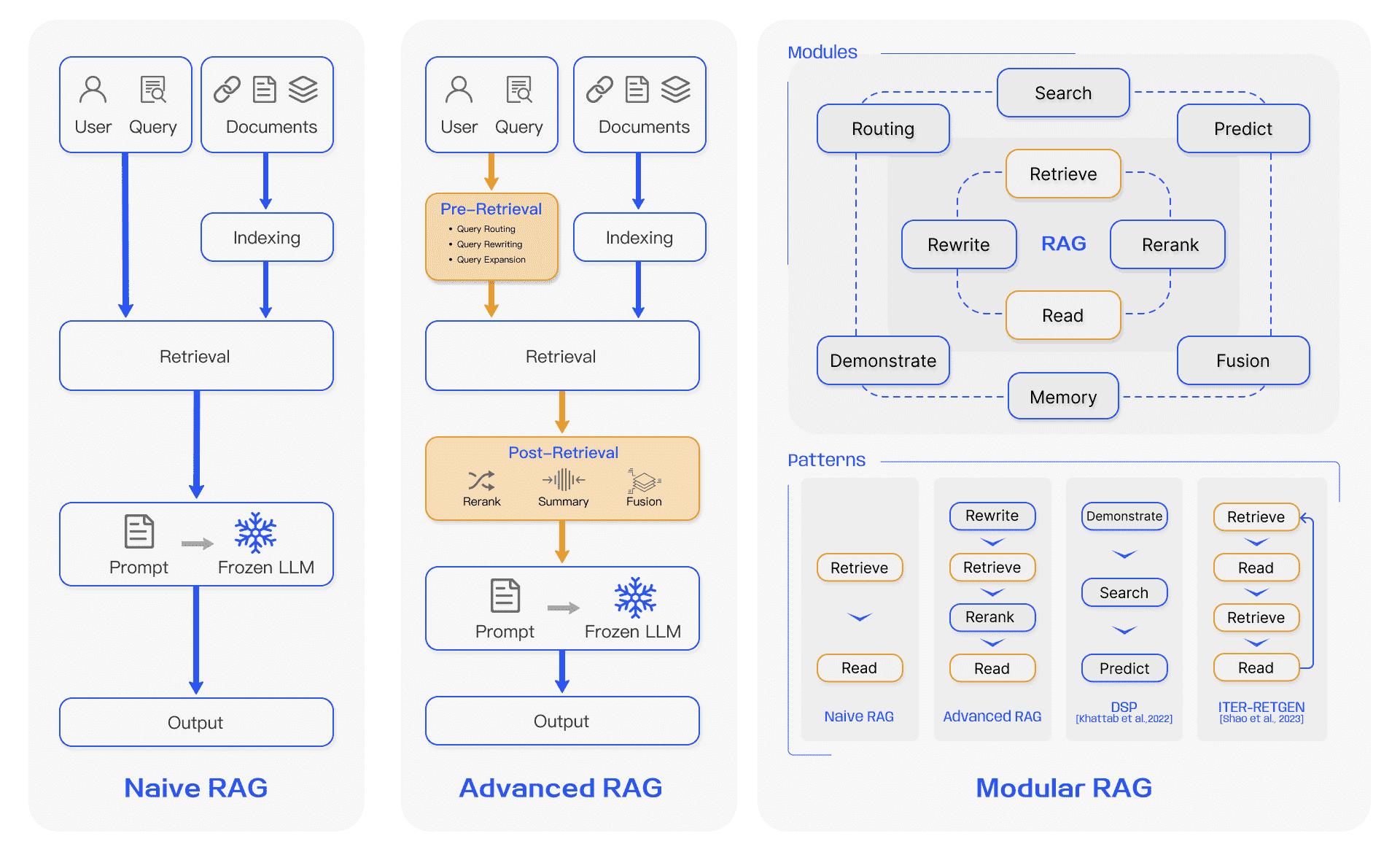
Figure 3:Comparison between the three paradigms of RAG. (Left) Naive RAG mainly consists of three parts: indexing, retrieval and generation. (Middle) Advanced RAG proposes multiple optimization strategies around pre-retrieval and post-retrieval, with a process similar to the Naive RAG, still following a chain-like structure. (Right) Modular RAG inherits and develops from the previous paradigm, showcasing greater flexibility overall. This is evident in the introduction of multiple specific functional modules and the replacement of existing modules. The overall process is not limited to sequential retrieval and generation; it includes methods such as iterative and adaptive retrieval.¶
II-A Naive RAG¶
Naive RAG 研究范式代表了最早的方法论,在 ChatGPT 广泛采用后不久就得到了重视。 Naive RAG 遵循传统的过程,包括索引、检索和生成,也被称为“检索-读取”框架(“Retrieve-Read” framework)
notable drawbacks(缺点):
检索挑战。检索阶段经常在精确度和召回率方面遇到困难,导致选择错位或不相关的块,并丢失关键信息。
生成困难。在生成响应时,模型可能会面临幻觉问题,即生成检索到的上下文不支持的内容。此阶段还可能会受到输出的不相关性、毒性或偏差的影响,从而降低响应的质量和可靠性。
增强障碍。将检索到的信息与不同的任务集成可能具有挑战性,有时会导致输出脱节或不连贯。当从多个来源检索类似信息时,该过程还可能遇到冗余,从而导致重复响应。确定各个段落的重要性和相关性并确保风格和语气的一致性进一步增加了复杂性。面对复杂的问题,基于原始查询的单一检索可能不足以获取足够的上下文信息。
II-B Advanced RAG¶
Advanced RAG 引入了特定的改进来克服 Naive RAG 的局限性。它着眼于提高检索质量,采用检索前和检索后策略。
预检索过程。这一阶段的主要重点是优化索引结构和原始查询。优化索引的目标是提高索引内容的质量。这涉及到策略:增强数据粒度、优化索引结构、添加元数据、对齐优化、混合检索。
检索后过程。一旦检索到相关上下文,将其与查询有效集成就至关重要。检索后过程中的主要方法包括重新排序块和上下文压缩。重新排列检索到的信息以将最相关的内容重新定位到提示的边缘是一个关键策略。
备注
Advanced RAG 不仅依赖于检索到的信息,还结合了更复杂的生成策略,以处理更知识密集的任务
II-C Modular RAG¶
模块化 RAG 架构超越了前两种 RAG 范例,提供了增强的适应性和多功能性。它结合了多种策略来改进其组件,例如添加用于相似性搜索的搜索模块以及通过微调来改进检索器。
模块化 RAG 仍建立在高级 RAG 和朴素 RAG 的基本原则之上,展示了 RAG 系列的进步和完善。
备注
模块化RAG允许将不同的功能组件(如检索、生成和增强模块)分开设计和实现。这种设计使得每个模块可以独立优化和替换,从而更好地满足特定任务的需求。
II-C1 New Modules¶
模块化 RAG 框架引入了额外的专用组件来增强检索和处理能力。
作用:本部分强调了在模块化RAG框架中引入的新功能模块,以增强RAG系统的能力和灵活性。
II-C2 New Patterns¶
模块化 RAG 通过允许模块替换或重新配置来解决特定挑战,从而提供卓越的适应性。
作用:本部分探讨了新模式的出现,强调了系统在处理任务时的灵活性和适应性。
II-D RAG vs Fine-tuning¶
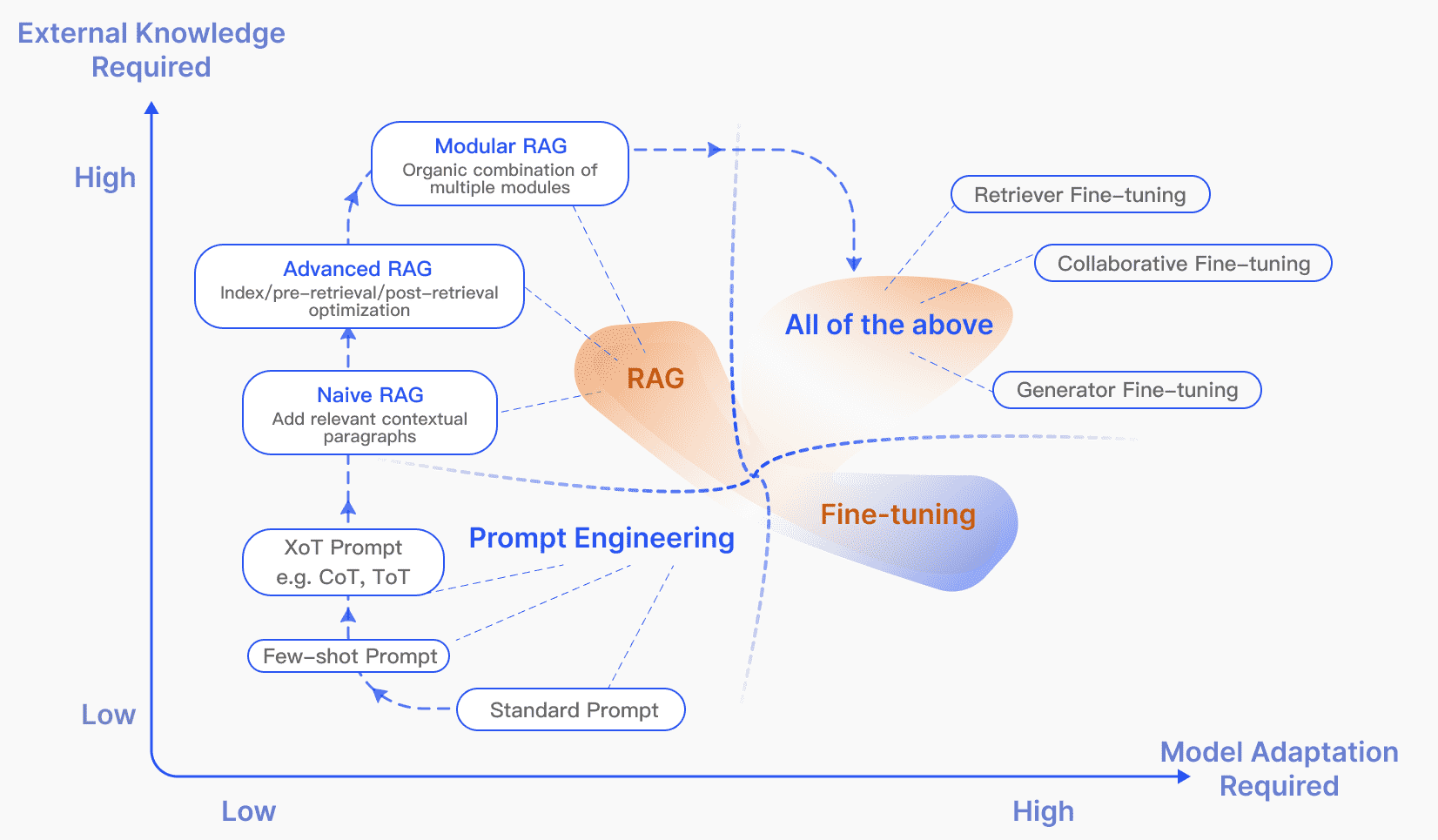
Figure 4: RAG compared with other model optimization methods in the aspects of “External Knowledge Required” and “Model Adaption Required”. Prompt Engineering requires low modifications to the model and external knowledge, focusing on harnessing the capabilities of LLMs themselves. Fine-tuning, on the other hand, involves further training the model. In the early stages of RAG (Naive RAG), there is a low demand for model modifications. As research progresses, Modular RAG has become more integrated with fine-tuning techniques.¶
III. Retrieval¶
III-A Retrieval Source¶
Data Structure:
1. Unstructured Data
2. Semi-structured data
3. Structured data
4. LLMs-Generated Content
Retrieval Granularity:
检索粒度从细到粗,包括:
Token、Phrase、Sentence、Proposition、Chunks、Document
III-B Indexing Optimization¶
Chunking Strategy:
1. 最常见的方法是将文档分割成固定数量的token(例如,100、256、512)
较大的块可以捕获更多的上下文,但它们也会产生更多的噪音,需要更长的处理时间和更高的成本
较小的块可能无法完全传达必要的上下文,但它们确实具有较少的噪音。
2. 很难在 `语义完整性` 和 `上下文长度` 之间取得平衡
3. Small2Big
sentences (small) are used as the retrieval unit,
preceding and following sentences are provided as (big) context to LLMs
Metadata Attachments:
1. 可以使用页码、文件名、作者、类别时间戳等元数据信息来丰富块
2. 随后,可以基于该元数据来过滤检索,从而限制检索的范围
3. 在检索过程中为文档时间戳分配不同的权重可以实现时间感知的RAG,保证知识的新鲜度并避免信息过时
4. 除了从原始文档中提取元数据外,还可以人工构建元数据
添加段落摘要,以及引入假设性问题
反向 HyDE:利用LLM生成文档可以回答的问题,然后在检索时计算原始问题与假设问题的相似度,以减少问题与答案之间的语义差距
Reverse HyDE: LLMs生成可以通过文档回答问题的过程。通过将这些假设问题与用户的原始查询进行比较,系统可以更好地理解并从文档中检索最相关的信息。这种方法通过在问题和答案之间建立更直接的联系来增强检索过程,从而提高信息检索的准确性。
HyDE 和反向 HyDE 是旨在通过利用LLMs的能力来生成和分析原始文档中可能未明确说明但与其密切相关的内容来提高语义搜索有效性的技术。
Structural Index:
增强信息检索(enhancing information retrieval)的一种有效方法是建立文档的层次结构。
1. Hierarchical index structure.
File are arranged in parent-child relationships, with chunks linked to them.
数据摘要存储在每个节点上,有助于快速遍历数据并协助 RAG 系统确定要提取的chunk。
这种方法还可以减轻由块提取问题引起的幻觉。
2. Knowledge Graph index.
利用KG构建文档的层次结构有助于保持一致性。
它描绘了不同概念和实体之间的联系,显着减少了产生幻觉的可能性。
另一个优点是将信息检索过程转化为LLM可以理解的指令,从而提高知识检索的准确性,
并使LLM能够生成上下文连贯的响应,从而提高RAG系统的整体效率。
III-C Query Optimization¶
III-C1 Query Expansion:
Expanding a single query into multiple queries enriches the content of the query,
providing further context to address any lack of specific nuances,
thereby ensuring the optimal relevance of the generated answers.
1. Multi-Query
使用 prompt engineering 通过 LLMs 扩展查询
2. Sub-Query
sub-question planning: 将一个复杂问题拆分成多个简单子问题
3. Chain-of-Verification(CoVe)
III-C2 Query Transformation:
The core concept is to retrieve chunks based on a transformed query instead of the user’s original query.
核心概念是基于转换后的查询而不是用户的原始查询来检索块。
1. Query Rewrite.
使用LLM重写查询
或使用专门的小模型,如RRR(Rewrite-retrieve-read),来重写查询
2. 让LLM根据原始查询生成查询以供后续检索
III-C3 Query Routing:
Based on varying queries, routing to distinct RAG pipeline,which is suitable for a versatile RAG system designed to accommodate diverse scenarios.
基于不同的查询,路由到不同的RAG管道,适用于旨在适应不同场景的多功能RAG系统。
1. Metadata Router/ Filter.
从查询中提取关键字(实体),然后根据块中的关键字和元数据进行过滤以缩小搜索范围。
2. Semantic Router
参见: https://github.com/aurelio-labs/semantic-router
III-D Embedding¶
在RAG中,检索是通过计算问题和文档块的嵌入之间的相似度(例如余弦相似度)来实现的,其中嵌入模型的语义表示能力起着关键作用。
这主要包括稀疏编码器(BM25)和密集检索器(BERT架构预训练语言模型)。最近的研究引入了著名的嵌入模型,如 AngIE、Voyage、BGE 等
III-D1 Mix/hybrid Retrieval:
稀疏和密集嵌入方法捕获不同的相关性特征,并且可以通过利用互补的相关性信息来相互受益。
例如,稀疏检索模型可用于为训练密集检索模型提供初始搜索结果。
III-D2 Fine-tuning Embedding Model:
微调的另一个目的是对齐检索器和生成器
III-E Adapter¶
微调模型可能会带来挑战,例如通过 API 集成功能或解决因有限的本地计算资源而产生的约束。因此,一些方法选择结合外部 Adapter 来帮助对齐。
IV. Generation¶
检索后,将所有检索到的信息直接输入到LLM来回答问题并不是一个好的做法。下面将从调整检索内容和调整LLM两个角度介绍调整。
IV-A Context Curation¶
IV-A1 Reranking:
Reranking 从根本上对文档块进行重新排序,以首先突出显示最相关的结果,
有效地减少总体文档池,实现信息检索的双重目的,充当增强器和过滤器,为更精确的语言模型处理提供精致的输入
可以使用:
1. 基于规则的方法(取决于多样性、相关性和 MRR 等预定义指标)
2. 基于模型的方法(例如
BERT 系列的编码器-解码器模型(例如 SpanBERT)
专门的重排序模型(例如 Cohere rerank 或bge-raranker-large
通用大型语言模型,如 GPT
IV-A2 Context Selection/Compression:
RAG 过程中的一个常见误解是认为检索尽可能多的相关文档并将它们连接起来形成冗长的检索提示是有益的。
然而,过多的上下文可能会引入更多噪音,从而削弱LLM对关键信息的感知。
LLMLingua 利用小型语言模型(SLM)(例如 GPT-2 Small 或 LLaMA-7B)来检测和删除不重要的标记,将其转换为人类难以理解但易于LLMs理解的形式
这种方法提供了一种直接且实用的即时压缩方法,无需对LLMs进行额外培训,同时平衡语言完整性和压缩率
除了压缩上下文之外,减少文档数量还有助于提高模型答案的准确性
IV-B LLM Fine-tuning¶
LLMs缺乏特定领域的数据时,可以通过微调为LLM提供额外的知识。
微调的另一个好处是能够调整模型的输入和输出。
通过强化学习将LLM输出与人类或检索器的偏好保持一致是一种潜在的方法。
V. Augmentation process in RAG¶
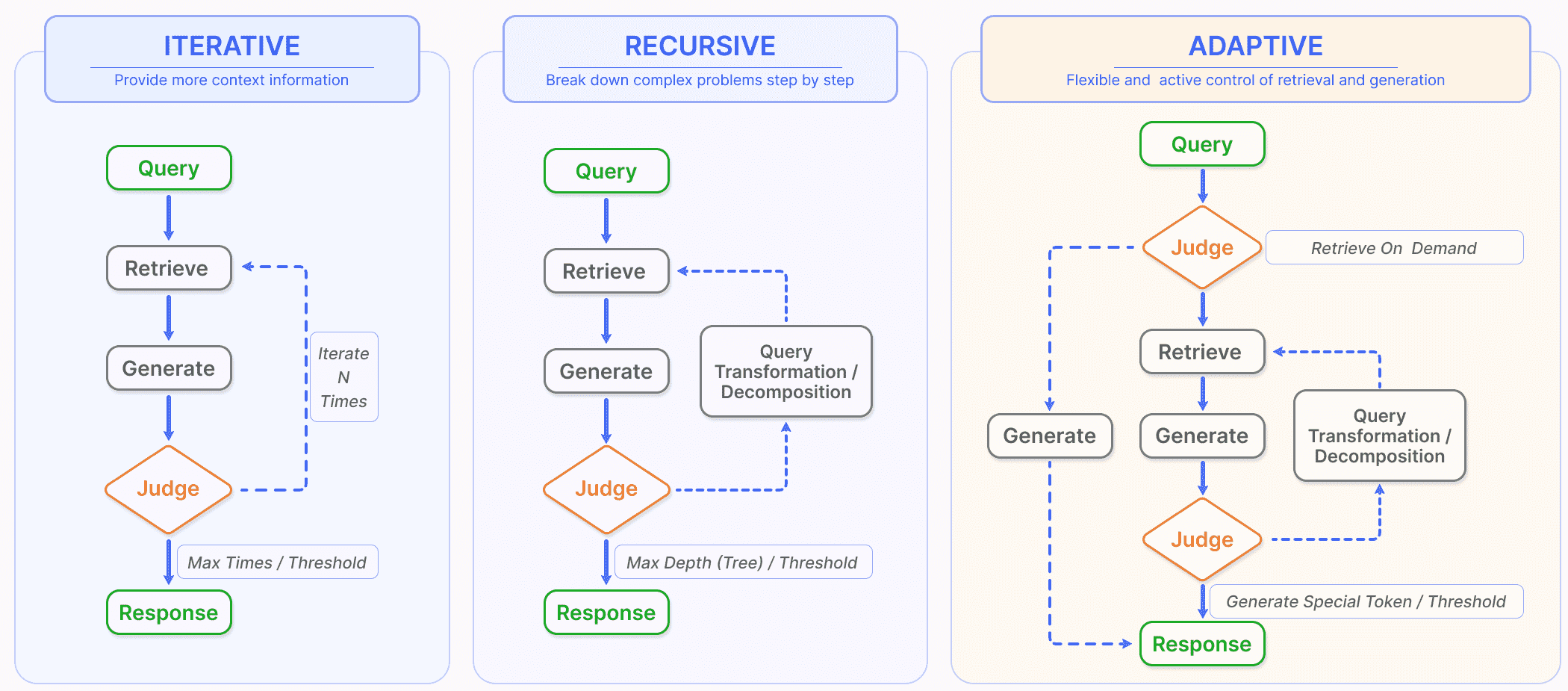
Figure 5:In addition to the most common once retrieval, RAG also includes three types of retrieval augmentation processes. (left) Iterative retrieval involves alternating between retrieval and generation, allowing for richer and more targeted context from the knowledge base at each step. (Middle) Recursive retrieval involves gradually refining the user query and breaking down the problem into sub-problems, then continuously solving complex problems through retrieval and generation. (Right) Adaptive retrieval focuses on enabling the RAG system to autonomously determine whether external knowledge retrieval is necessary and when to stop retrieval and generation, often utilizing LLM-generated special tokens for control.图 5:除了最常见的一次检索之外,RAG 还包括三种类型的检索增强过程。 (左)迭代检索涉及检索和生成之间的交替,允许在每一步从知识库中获得更丰富、更有针对性的上下文。 (中)递归检索涉及逐步细化用户查询并将问题分解为子问题,然后通过检索和生成不断解决复杂问题。 (右)自适应检索侧重于使 RAG 系统能够自主确定是否需要外部知识检索以及何时停止检索和生成,通常利用LLM生成的特殊令牌进行控制。¶
V-A Iterative Retrieval¶
迭代检索是根据初始查询和迄今为止生成的文本重复搜索知识库的过程,为LLMs提供更全面的知识库。
这种方法已被证明可以通过多次检索迭代提供额外的上下文参考来增强后续答案生成的稳健性。
然而,它可能会受到语义不连续性和不相关信息积累的影响。
V-B Recursive Retrieval¶
递归检索常用于信息检索和自然语言处理中,以提高搜索结果的深度和相关性。
该过程涉及根据先前搜索获得的结果迭代地细化搜索查询。递归检索旨在通过反馈循环逐渐收敛最相关的信息来增强搜索体验。
V-C Adaptive Retrieval¶
以 Flare 和 Self-RAG 为代表的自适应检索方法通过使LLMs能够主动确定检索的最佳时刻和内容来完善 RAG 框架,从而提高所获取信息的效率和相关性。
此方法是更广泛趋势的一部分,其中LLMs在其操作中采用主动判断,如 AutoGPT、Toolformer 和 Graph-Toolformer 等模型代理。例如,Graph-Toolformer 将其检索过程分为不同的步骤,其中LLMs主动使用检索器,应用自我询问技术(Self-Ask techniques),并采用少量提示来启动搜索查询。这种主动的能力使LLMs能够决定何时搜索必要的信息,类似于代理人如何使用工具。
WebGPT [ 110 ]集成了强化学习框架来训练GPT-3模型在文本生成过程中自主使用搜索引擎。它使用特殊令牌来导航此过程,这些令牌有助于搜索引擎查询、浏览结果和引用参考文献等操作,从而通过使用外部搜索引擎扩展 GPT-3 的功能。 * Flare 通过监控生成过程的置信度来使时序检索自动化。当概率低于某个阈值时就会激活检索系统来收集相关信息,从而优化检索周期。 * Self-RAG 引入了“reflection tokens”,允许模型反思(introspect)其输出。
这些 token 有两种类型:“retrieve”和“critic”。
模型自主决定何时激活检索,或者,预定义的阈值可以触发该过程。
在检索过程中,生成器在多个段落中进行片段级波束搜索(fragment-level beam search),以得出最连贯(coherent)的序列。
批评分数(Critic scores)用于更新细分(subdivision)分数,可以在推理过程中灵活调整这些权重,从而定制(tailoring)模型的行为。
Self-RAG 的设计不需要额外的分类器和对自然语言推理 (NLI) 模型的依赖,从而简化了何时使用检索机制的决策过程,并提高了模型生成准确响应的自主判断能力。
VI. Task and Evaluation¶
RAG 在 NLP 领域的快速发展和日益广泛的采用,将 RAG 模型的评估推向了LLMs社区研究的前沿。
本次评估的主要目的是了解和优化 RAG 模型在不同应用场景下的性能。本章将主要介绍 RAG 的主要下游任务、数据集以及如何评估 RAG 系统。
VI-A Downstream Task¶
RAG的核心任务仍然是问答(QA),包括传统的单跳/多跳QA、多选、特定领域的QA以及适合RAG的长格式场景。
除了QA之外,RAG还不断扩展到多个下游任务,例如信息提取(IE)、对话生成、代码搜索等。
TABLE II:Downstream tasks and datasets of RAG:
Task Sub Task DataSet
---- ---------- -------------
QA Single-hop Natural Qustion(NQ)
TriviaQA(TQA)
SQuAD
Web Questions(WebQ)
PopQA
MS MARCO
Multi-hop HotpotQA
2WikiMultiHopQA
MuSiQue
Long-form QA ELI5
NarrativeQA(NQA)
ASQA
QMSum(QM)
Domain QA Qasper
COVID-QA
CMB
MMCU_Medical
Multi-Choice QA QuALITY
ARC
CommonsenseQA
Graph QA GraphQA
Dialog Dialog Generation Wizard of Wikipedia (WoW)
Personal Dialog KBP
DuleMon
Task-oriented Dialog CamRest
Recommendation Amazon(Toys,Sport,Beauty)
IE Event Argument Extraction WikiEvent
RAMS
Relation Extraction T-REx
ZsRE
Reasoning Commonsense Reasoning HellaSwag
CoT Reasoning CoT Reasoning
Complex Reasoning CSQA
Others Language Understanding MMLU
Language Modeling WikiText-103
StrategyQA
Fact Checking/Verification FEVER
PubHealth
Text Generation Biography
Text Summarization WikiASP
XSum
Text Classification VioLens
TREC
Sentiment SST-2
Code Search CodeSearchNet
Robustness Evaluation NoMIRACL
Math GSM8K
Machine Translation JRC-Acquis
VI-B Evaluation Target¶
RAG 模型评估主要集中在特定下游任务中的执行情况
问答评估可能依赖于 EM 和 F1分数
事实检查任务通常依赖于准确性作为主要指标
BLEU 和 ROUGE 指标也常用于评估答案质量
RALLE 等工具专为自动评估 RAG 应用程序而设计,同样基于这些特定于任务的指标进行评估
主要评估目标包括:
Retrieval Quality.评估检索质量对于确定检索器组件所提供的上下文的有效性至关重要。采用搜索引擎、推荐系统和信息检索系统领域的标准指标来衡量 RAG 检索模块的性能。命中率、MRR 和 NDCG 等指标通常用于此目的
Generation Quality.生成质量的评估集中于生成器从检索到的上下文中合成连贯且相关的答案的能力。该评估可以根据内容的目标进行分类:未标记的内容和标记的内容。对于未标记的内容,评估包括生成答案的真实性、相关性和无害性。相反,对于标记内容,重点是模型产生的信息的准确性。
VI-C Evaluation Aspects¶
RAG 模型的当代评估实践强调三个主要质量分数(quality scores)和四个基本能力(essential abilities),它们共同指导 RAG 模型的两个主要目标的评估:检索和生成。
VI-C1 Quality Scores:
包括: 上下文相关性、答案忠实度和答案相关性
从不同角度评估了RAG模型在信息检索和生成过程中的效率
1. 上下文相关性: 评估检索到的上下文的精度(precision)和特征(specificity),确保相关性并最大限度地减少与无关内容相关的处理成本。
2. 答案忠实性: 确保生成的答案与检索到的上下文保持一致,保持一致性并避免矛盾。
3. 答案相关性: 要求生成的答案与提出的问题直接相关,有效解决核心问题。
VI-C2 Required Abilities:
RAG评估还包括表明其适应性和效率的四种能力:
1. 噪声鲁棒性(noise robustness)
2. 负拒绝(negative rejection)
3. 信息集成(information integration)
4. 反事实鲁棒性(counterfactual robustness)
1. 噪声鲁棒性评估模型管理与问题相关但缺乏实质性信息的噪声文档的能力。
2. 否定拒绝评估模型在检索到的文档不包含回答问题所需的知识时避免做出响应的辨别能力。
3. 信息集成评估模型从多个文档合成信息以解决复杂问题的能力。
4. 反事实稳健性测试模型识别和忽略文档中已知不准确之处的能力,即使在被指示有关潜在错误信息的情况下也是如此。
备注
上下文相关性和噪声鲁棒性对于评估检索质量很重要,而答案忠实度、答案相关性、否定拒绝、信息集成和反事实鲁棒性对于评估生成质量很重要。

TABLE III: Summary of metrics applicable for evaluation aspects of RAG¶
VI-D Evaluation Benchmarks and Tools¶
人们提出了一系列基准测试和工具来促进 RAG 的评估。
这些工具提供的定量指标不仅可以衡量 RAG 模型的性能,还可以增强对模型在各个评估方面的能力的理解。
RGB、RECALL 和 CRUD 等著名基准侧重于评估 RAG 模型的基本能力。同时,最先进的自动化工具如 RAGAS 、ARES 和 TruLens8 使用LLMs来裁决质量分数
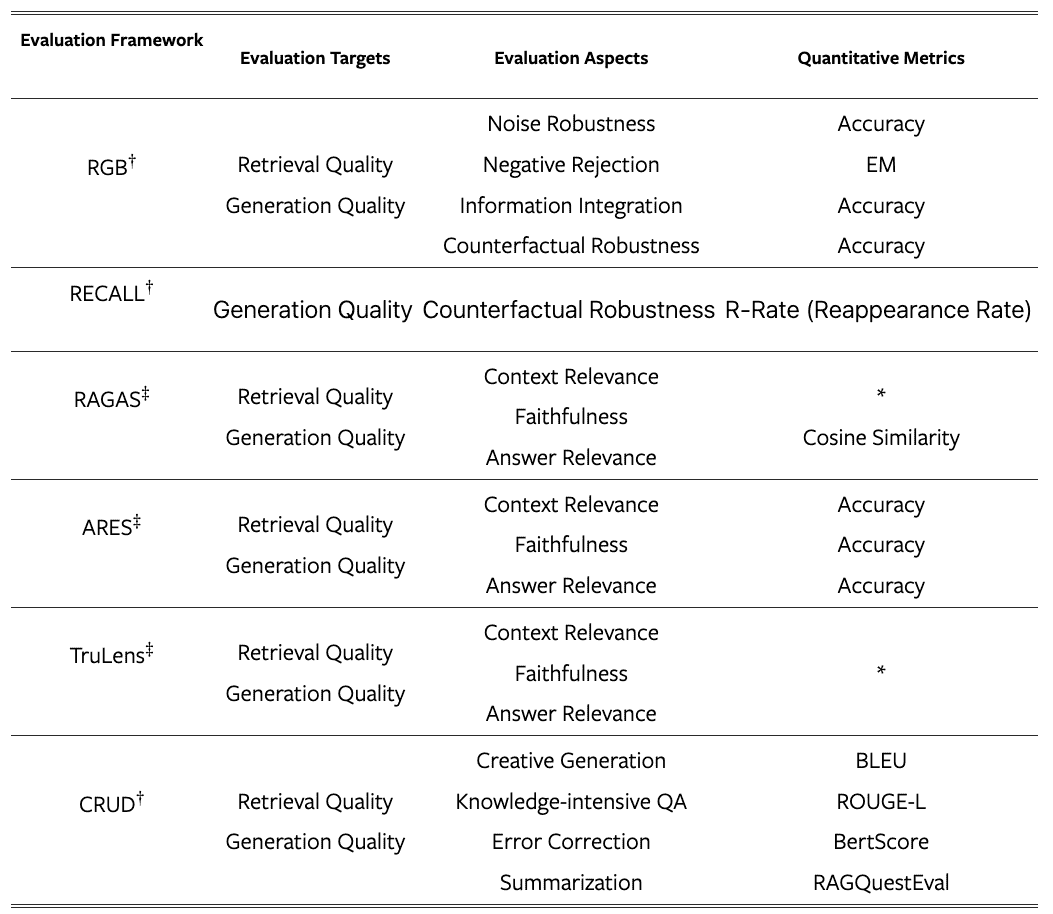
TABLE IV:Summary of evaluation frameworks¶
说明:
† represents a benchmark. ‡ represents a tool. * denotes customized quantitative metrics, which deviate from traditional metrics.
VII. Discussion and Future Prospects¶
VII-A RAG vs Long Context¶
当LLMs不受上下文限制时是否仍然需要RAG
事实上,RAG仍然发挥着不可替代的作用。
一方面,一次性为LLMs提供大量上下文将显着影响其推理速度,而分块检索和按需输入可以显着提高运营效率。
另一方面,基于RAG的生成可以快速定位LLMs的原始参考文献,帮助用户验证生成的答案。整个检索和推理过程是可观察的,而仅依赖长上下文的生成仍然是一个黑匣子。
相反,语境的扩展为RAG的发展提供了新的机遇,使其能够解决更复杂的问题以及需要阅读大量材料才能回答的综合或总结性问题。
在超长背景下开发新的RAG方法是未来的研究趋势之一。
VII-B RAG Robustness¶
检索过程中存在的噪声或矛盾信息可能会对 RAG 的输出质量产生不利影响。这种情况被形象地称为“错误信息可能比没有信息更糟糕”。
提高 RAG 对此类对抗性或反事实输入的抵抗力正在获得研究动力,并已成为关键绩效指标。
VII-C Hybrid Approaches¶
将 RAG 与微调相结合正在成为一种领先策略。
确定 RAG 的最佳集成和微调(无论是顺序、交替还是通过端到端联合训练)以及如何利用参数化和非参数化优势是值得探索的领域。
另一个趋势是将具有特定功能的SLM引入RAG中,并根据RAG系统的结果进行微调。例如, CRAG 训练一个轻量级检索评估器来评估查询检索到的文档的整体质量,并根据置信度触发不同的知识检索动作。
VII-D Scaling laws of RAG¶
端到端的RAG模型和基于RAG的预训练模型仍然是当前研究人员关注的焦点之一。这些模型的参数是关键因素之一。
当LLMs的参数已经找到确定的标度律时,对 RAG 的适用性仍然不确定。
像 RETRO++ 这样的初步研究已经开始解决这个问题,但 RAG 模型中的参数计数仍然落后于LLMs 。
RAG模型可能适用逆标度律(较小的模型优于较大的模型),这一点特别有趣,值得进一步研究。
VII-E Production-Ready RAG¶
In the development of RAG technology, there is a clear trend towards different specialization directions, such as:
1) Customization - tailoring RAG to meet specific requirements.
2) Simplification - making RAG easier to use to reduce the initial learning curve.
3) Specialization - optimizing RAG to better serve production environments.
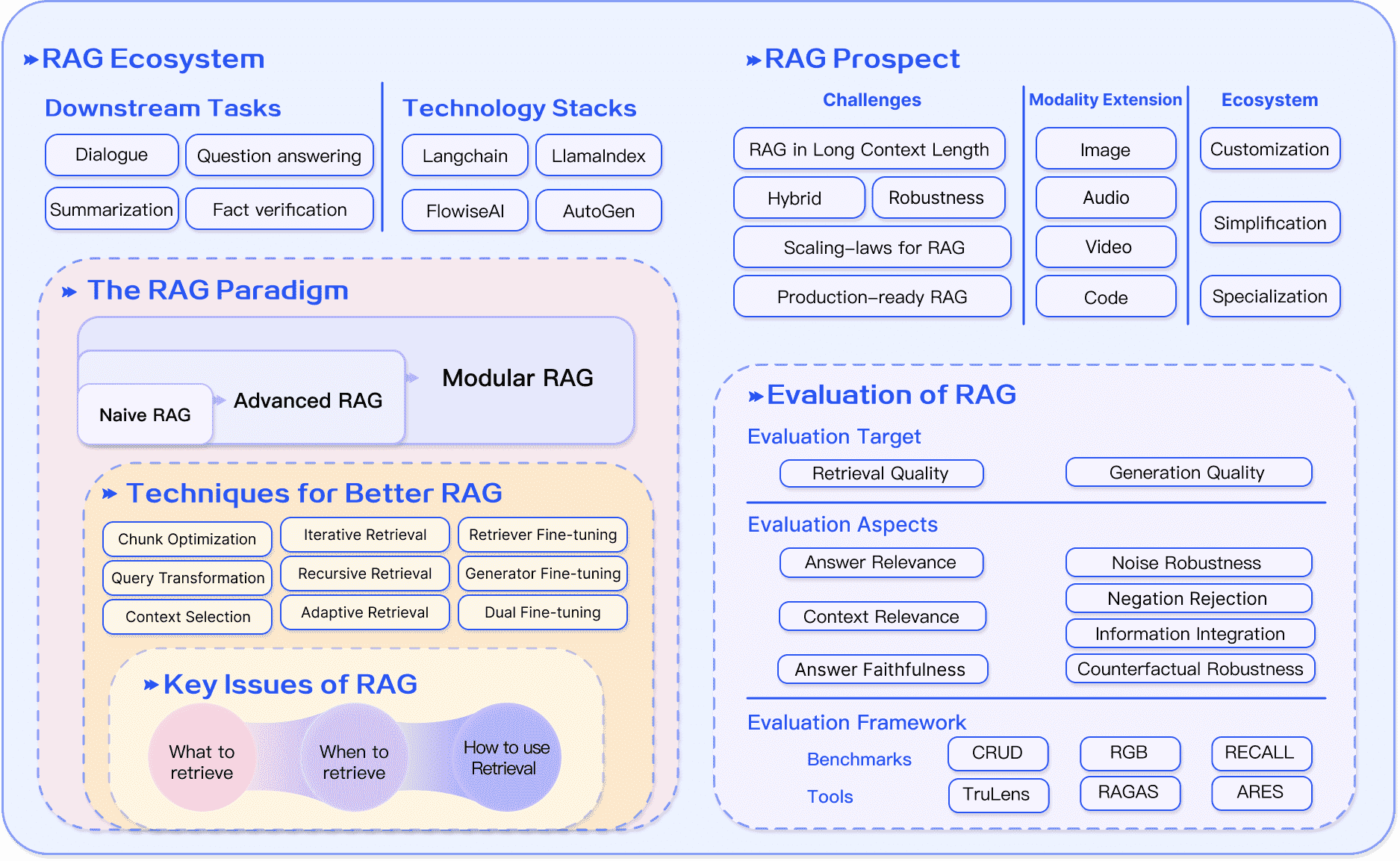
Figure 6: Summary of RAG ecosystem¶
VII-F Multi-modal RAG¶
Image:
1. RA-CM3 是检索和生成文本和图像的开创性多模态模型 2. BLIP-2 利用冻结图像编码器和LLMs进行高效的视觉语言预训练,实现零样本图像到文本的转换 3. “Visualize Before You Write” 方法使用图像生成来引导 LM 的文本生成,在开放式文本生成任务中显示出前景
Audio and Video:
1. GSS 方法检索音频剪辑并将其拼接在一起,将机器翻译的数据转换为语音翻译的数据 2. UEOP 通过结合外部离线语音到文本转换策略,标志着端到端自动语音识别的重大进步 3. 基于 KNN 的注意力融合利用音频嵌入和语义相关的文本嵌入来完善 ASR,从而加速领域适应。 4. Vid2Seq 使用专门的时间标记增强了语言模型,有助于在统一的输出序列中预测事件边界和文本描述
Code:
1. RBPS 通过编码和频率分析,检索与开发人员目标一致的代码示例,在小规模学习任务中表现出色。这种方法已在测试断言生成和程序修复等任务中证明了有效性 2. 对于结构化知识,CoK方法首先从知识图谱中提取与输入查询相关的事实,然后将这些事实作为提示集成到输入中,从而提高知识图谱问答任务的性能