Mobile-Agent-v2: Mobile Device Operation Assistant with Effective Navigation via Multi-Agent Collaboration¶
组织: 北京交通大学, 阿里巴巴集团
移动设备操作任务日益成为流行的多模态人工智能应用场景。当前的多模态大语言模型(MLLM)受训练数据的限制,缺乏有效充当操作助手的能力。相反,基于MLLM的代理,通过工具调用来增强能力,正在逐渐应用于该场景。然而,移动设备操作任务中的两大导航挑战, 任务进度导航 和 焦点内容导航 ,在现有工作的单代理架构下变得非常复杂。这是由于过长的令牌序列(token sequences)和交错的文本图像数据格式(text-image data format)限制了性能。为了有效地解决这些导航挑战,我们提出了 Mobile-Agent-v2,一种用于移动设备操作辅助的多代理架构。该架构包括三个代理: 规划代理 、 决策代理 和 反思代理 。
规划代理生成任务进度,使历史操作的导航更加高效。为了保留焦点内容,我们设计了一个随任务进度更新的记忆单元。此外,为了纠正错误的操作,反射代理会观察每个操作的结果并相应地处理任何错误。实验结果表明,与 Mobile-Agent 的单代理架构相比,Mobile-Agent-v2 的任务完成率提高了 30% 以上。Mobile device operation tasks are increasingly becoming a popular multi-modal AI application scenario. Current Multi-modal Large Language Models (MLLMs), constrained by their training data, lack the capability to function effectively as operation assistants. Instead, MLLM-based agents, which enhance capabilities through tool invocation, are gradually being applied to this scenario. However, the two major navigation challenges in mobile device operation tasks, task progress navigation and focus content navigation, are significantly complicated under the single-agent architecture of existing work. This is due to the overly long token sequences and the interleaved text-image data format, which limit performance. To address these navigation challenges effectively, we propose Mobile-Agent-v2, a multi-agent architecture for mobile device operation assistance. The architecture comprises three agents: planning agent, decision agent, and reflection agent. The
planning agentgenerates task progress, making the navigation of history operations more efficient. To retain focus content, we design a memory unit that updates with task progress. Additionally, to correct erroneous operations, thereflection agentobserves the outcomes of each operation and handles any mistakes accordingly. Experimental results indicate that Mobile-Agent-v2 achieves over a 30% improvement in task completion compared to the single-agent architecture of Mobile-Agent.
备注
Mobile-Agent是基于GPT-4V端到端屏幕识别的单代理架构;而 Mobile-Agent-v2 包括三个代理: 规划代理 、 决策代理 和 反思代理
AppAgent Zhang 等人,2023a通过从设备 XML 文件中提取可点击位置来解决 MLLM 在本地化方面的局限性。然而,对 UI 文件的依赖限制了该方法对其他平台和设备的适用性。为了消除对底层 UI 文件的依赖,Mobile-Agent Wang 等人 ( 2024 )提出了一种通过视觉感知工具进行本地化的解决方案。它通过MLLM感知屏幕并生成操作,通过视觉感知工具定位它们的位置。
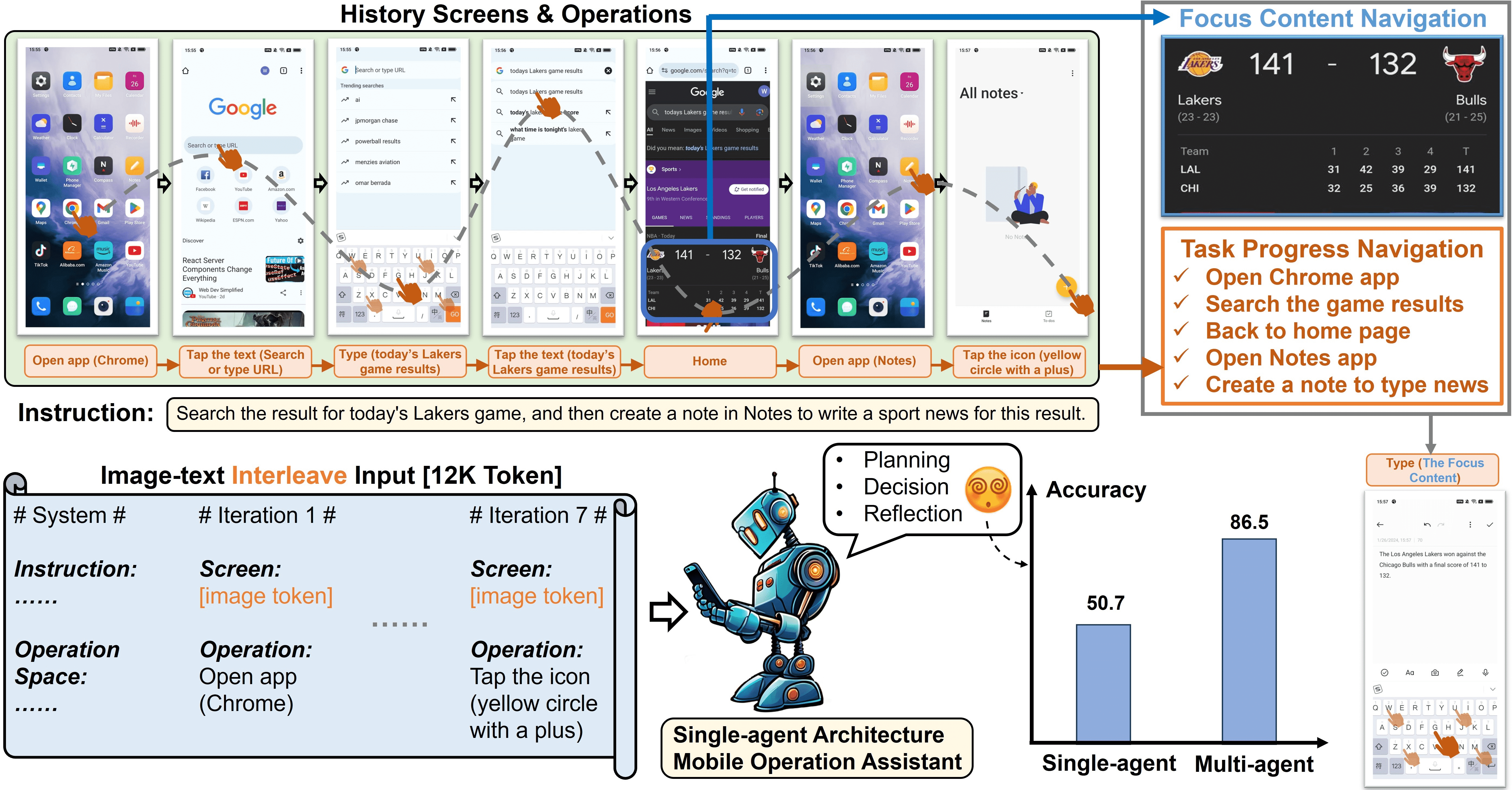
图 1:移动设备操作任务需要从历史操作序列中导航焦点内容(navigating focus content)和任务进度(task progress),其中焦点内容来自之前的屏幕。随着操作数量的增加,输入序列的长度也随之增加,这使得单代理架构有效管理这两种类型的导航变得极具挑战性。¶
移动设备操作任务涉及多步骤顺序处理。操作者需要从初始屏幕开始对设备进行一系列连续的操作,直到指令完全执行。
这个过程有两个主要挑战。
首先,为了规划操作意图,操作员需要从历史操作中导航当前任务进度。
其次,某些操作可能需要历史屏幕中与任务相关的信息
如上图中,编写体育新闻需要使用之前查询到的比赛结果。我们将这些重要信息称为焦点内容。
在做出决策时,提示决策代理观察当前屏幕页面内是否存在与任务相关的焦点内容。如果观察到此类信息,决策代理会将其更新到内存中,以供后续决策参考。
三种专门的代理角色:规划代理、决策代理和反射代理。 规划代理 需要根据历史操作生成任务进度。为了保存历史屏幕中的焦点内容,我们设计了一个存储单元来记录与任务相关的焦点内容。 决策代理 在生成操作时会观察该单元,同时检查屏幕上是否有焦点内容并将其更新到内存中。由于决策代理无法观察到之前的屏幕进行反映,因此我们设计 反射代理 来观察决策代理操作前后屏幕的变化,并判断操作是否符合预期。如果发现操作不符合预期,则会采取适当措施重新执行操作。¶
Operation Space:
1. Open app
2. Tap (x, y)
3. Swipe (x1, y1), (x2, y2)
4. Type (text)
5. Home
6. Stop
4.1 Model:
Visual Perception Module:
OCR: ConvNextViT-document
icon recognition tool: GroundingDINO
a detection model capable of detecting objects based on natural language prompts
snapshot_download('AI-ModelScope/GroundingDINO', revision='v1.0.0')
icon description tool: Qwen-VL-Int4
MLLM
规划Agent: GPT-4 OpenAI
决策Agent: GPT-4V OpenAI
反思Agent: GPT-4V OpenAI
消融实验结果:
+------------------+------------------+-------------+------+------+------+------+------+------+
| Ablation Setting | Basic | Advanced |
+==================+==================+=============+======+======+======+======+======+======+
| Planning Agent | Reflection Agent | Memory Unit | SR | CR | DA | SR | CR | DA |
+------------------+------------------+-------------+------+------+------+------+------+------+
| x | ✓ | ✓ | 59.1 | 63.7 | 58.9 | 29.5 | 43.8 | 42.6 |
+------------------+------------------+-------------+------+------+------+------+------+------+
| ✓ | ✓ | x | 77.3 | 83.6 | 84.0 | 45.5 | 72.3 | 69.8 |
+------------------+------------------+-------------+------+------+------+------+------+------+
| ✓ | x | ✓ | 86.4 | 89.2 | 85.7 | 54.5 | 75.9 | 72.4 |
+------------------+------------------+-------------+------+------+------+------+------+------+
| ✓ | ✓ | ✓ | 88.6 | 93.9 | 89.4 | 61.4 | 82.1 | 80.3 |
+------------------+------------------+-------------+------+------+------+------+------+------+
成功定义:
• Success Rate (SR):
When all the requirements of a user instruction are fulfilled, the agent is considered to have successfully executed this instruction.
The success rate refers to the proportion of user instructions that are successfully executed.
• Completion Rate (CR):
Although some challenging instructions may not be successfully executed, the correct operations performed by the agent are still noteworthy.
The completion rate refers to the proportion of correct steps out of the ground truth operations.
• Decision Accuracy (DA):
This metric reflects the accuracy of the decision by the decision agent.
It is the proportion of correct decisions out of all decisions.
• Reflection Accuracy (RA):
This metric reflects the accuracy of reflection by the reflection agent.
It is the proportion of correct reflections out of all reflections.