Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond¶
组织: 阿里
在本文中,我们介绍了Qwen-VL系列,这是一组旨在感知和理解文本和图像的大规模视觉语言模型(LVLM)。以Qwen-LM为基础,通过精心设计的i.视觉感受器、ii.输入输出接口、iii.三级训练流水线和iv.多语种多模态清洗语料库,赋予其视觉能力。除了传统的图像描述和问答之外,我们还通过对齐图像-标题-框元组来实现Qwen-VL的基础和文本阅读能力。由此产生的模型,包括Qwen-VL和Qwen-VL-Chat,在广泛的以视觉为中心的基准测试(例如,图像字幕、问题回答、视觉基础)和不同的设置(例如,zero-shot, few-shot)。 此外,在实际的对话基准测试中,我们的指令调整Qwen-VL-Chat与现有的视觉语言聊天机器人相比也表现出了优越性。
In this work, we introduce the Qwen-VL series, a set of large-scale vision-language models (LVLMs) designed to perceive and understand both texts and images. Starting from the Qwen-LM as a foundation, we endow it with visual capacity by the meticulously designed (i) visual receptor, (ii) input-output interface, (iii) 3-stage training pipeline, and (iv) multilingual multimodal cleaned corpus. Beyond the conventional image description and question-answering, we implement the grounding and text-reading ability of Qwen-VLs by aligning image-caption-box tuples. The resulting models, including Qwen-VL and Qwen-VL-Chat, set new records for generalist models under similar model scales on a broad range of visual-centric benchmarks (e.g., image captioning, question answering, visual grounding) and different settings (e.g., zero-shot, few-shot). Moreover, on real-world dialog benchmarks, our instruction-tuned Qwen-VL-Chat also demonstrates superiority compared to existing vision-language chatbots.

Qwen-VL-Chat支持多种图像输入、多轮对话、多语种对话、文本阅读、本地化、细粒度识别(fine-grained recognition)和理解能力。¶
Qwen-VL是基于Qwen-7 B(Qwen,2023)语言模型的一系列高性能、通用的视觉语言基础模型。
Qwen-VL-Chat是基于Qwen-VL的视觉语言聊天机器人。Qwen-VL-Chat能够与用户进行交互,并按照用户的意图感知输入图像。
Methodology¶
2.1 Model Architecture¶
Qwen-VL的整体网络架构由三部分组成:
1. Large Language Model
2. Visual Encoder
使用视觉Transformer(ViT)体系结构,用来自Openclip的ViT-bigG
在训练和推断期间,输入图像被调整为特定的分辨率
视觉编码器通过将图像分割成步幅为14的小块来处理图像,从而生成一组图像特征
3. Position-aware Vision-Language Adapter
为了缓解长图像特征序列带来的效率问题,Qwen-VL引入了一个压缩图像特征的视觉语言适配器
该适配器包括一个随机初始化的单层交叉注意模块。
该模块使用一组可训练向量(嵌入)作为查询向量,并将来自视觉编码器的图像特征作为交叉注意操作的关键字。
该机制将视觉特征序列压缩为固定长度256。
Table 1:Details of Qwen-VL model parameters:
+----------------+------------+------+-------+
| Vision Encoder | VL Adapter | LLM | Total |
+================+============+======+=======+
| 1.9B | 0.08B | 7.7B | 9.6B |
+----------------+------------+------+-------+
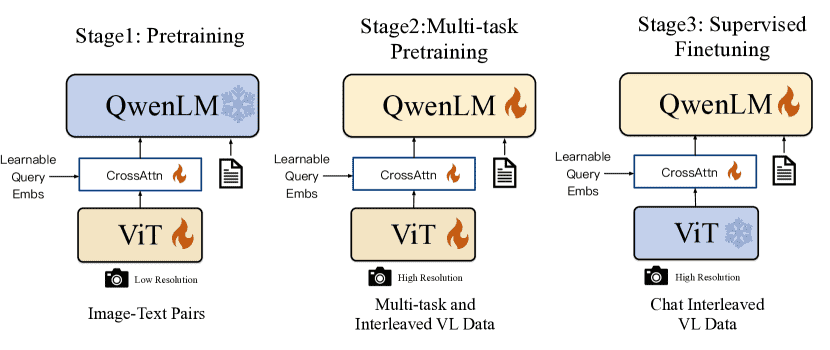
The training pipeline of the Qwen-VL series.¶
2.2 Inputs and Outputs¶
图像输入:图像通过视觉编码器和适配器进行处理,产生固定长度的图像特征序列。为了区分图像特征输入和文本特征输入,图像特征序列的开头和结尾分别附加了两个特殊标记(
< img > 和 < /img >),分别表示图像内容的开头和结尾。边界框输入和输出:为了增强模型的细粒度视觉理解和接地能力,Qwen-VL 的训练涉及区域描述、问题和检测形式的数据。与涉及图像文本描述或问题的传统任务不同,此任务需要模型准确理解并以指定格式生成区域描述。为了区分检测字符串和常规文本字符串,在边界框字符串的开头和结尾添加了两个特殊标记 (
< box > 和 < /box> 。此外,为了将边界框与其相应的描述性单词或句子适当关联,引入了另一组特殊标记(< ref > 和 < /ref >),标记边界框引用的内容。
Training¶
3.1 Pre-training¶
在预训练的第一阶段,我们主要利用了一组大规模的、弱标记的、网络爬虫的图像文本对。我们的预训练数据集由几个可公开访问的来源和一些内部数据组成。我们努力清理某些模式的数据集。原始数据集总共包含 50 亿个图文本对,清理后仍保留 14 亿条数据,其中英文(文本)数据占 77.3%,中文(文本)数据占 22.7%。
冻结了大型语言模型,在这个阶段只优化视觉编码器和 VL 适配器。输入图像的大小将调整为 224×224 。
Table 2:Qwen-VL 预训练数据的详细信息:
+----------+---------------+----------+---------+------------+
| Language | Dataset | Original | Cleaned | Remaining% |
+==========+===============+==========+=========+============+
| English | LAION-en | 2B | 280M | 14% |
+----------+---------------+----------+---------+------------+
| - | LAION-COCO | 600M | 300M | 50% |
+----------+---------------+----------+---------+------------+
| - | DataComp | 1.4B | 300M | 21% |
+----------+---------------+----------+---------+------------+
| - | Coyo | 700M | 200M | 28% |
+----------+---------------+----------+---------+------------+
| - | CC12M | 12M 8M | 66% | |
+----------+---------------+----------+---------+------------+
| - | CC3M | 3M | 3M | 100% |
+----------+---------------+----------+---------+------------+
| - | SBU 1M | 0.8M | 80% | |
+----------+---------------+----------+---------+------------+
| - | COCO Caption | 0.6M | 0.6M | 100% |
+----------+---------------+----------+---------+------------+
| Chinese | LAION-zh | 108M | 105M | 97% |
+----------+---------------+----------+---------+------------+
| - | In-house Data | 220M | 220M | 100% |
+----------+---------------+----------+---------+------------+
| - | Total | 5B | 1.4B | 28% |
+----------+---------------+----------+---------+------------+
3.2 Multi-task Pre-training¶
在多任务预训练的第二阶段,我们引入了具有更大输入分辨率的高质量和细粒度的 VL 标注数据和交错的图文数据
Table 3:Details of Qwen-VL multi-task pre-training data:
+--------------------------+-----------+---------------------------------------------------------------------+
| Task | # Samples | Dataset |
+==========================+===========+=====================================================================+
| Captioning | 19.7M | LAION-en & zh, DataComp, Coyo, CC12M & 3M, SBU, COCO, In-house Data |
+--------------------------+-----------+---------------------------------------------------------------------+
| VQA | 3.6M | GQA, VGQA, VQAv2, DVQA, OCR-VQA, DocVQA,TextVQA, ChartQA, AI2D |
+--------------------------+-----------+---------------------------------------------------------------------+
| Grounding2 | 3.5M | GRIT |
+--------------------------+-----------+---------------------------------------------------------------------+
| Ref Grounding | 8.7M | GRIT, Visual Genome, RefCOCO, RefCOCO+, RefCOCOg |
+--------------------------+-----------+---------------------------------------------------------------------+
| Grounded Cap. | 8.7M | GRIT, Visual Genome, RefCOCO, RefCOCO+, RefCOCOg |
+--------------------------+-----------+---------------------------------------------------------------------+
| OCR | 24.8M | SynthDoG-en & zh, Common Crawl pdf & HTML |
+--------------------------+-----------+---------------------------------------------------------------------+
| Pure-text Autoregression | 7.8M | In-house Data |
+--------------------------+-----------+---------------------------------------------------------------------+
Captioning:
生成描述图像内容的自然语言句子 应用场景:自动为图片生成标题,辅助视障人士理解图片内容,图像搜索引擎等。 技术:通常使用编码器-解码器架构,其中编码器(如卷积神经网络 CNN)提取图像特征,解码器(如递归神经网络 RNN 或 Transformer)生成描述文本。
VQA:
回答基于图像的自然语言问题 应用场景:智能助手、教育工具、医疗诊断等。 技术:结合图像特征和问题文本特征,使用多模态模型(如注意力机制、Transformer)来生成答案。
Grounding2:
将自然语言描述与图像中的特定区域对齐 应用场景:图像标注、目标检测、机器人导航等。 技术:通常使用多模态模型,通过联合训练图像特征和文本特征来学习对齐关系。 主要用于将语言中的特定对象映射到图像中的对应实体,帮助机器理解并定位自然语言描述的物体。 这项技术常应用于增强人机交互系统,让系统能准确识别语言中的指代并找到与之匹配的视觉目标。
Ref Grounding(Referring Expression Grounding):
给定一个自然语言描述和一张图像,定位图像中被描述的对象 应用场景:人机交互、图像标注、机器人视觉等。 技术:结合图像特征和描述文本特征,使用注意力机制或区域提议网络(RPN)来精确定位目标对象。 旨在通过解析自然语言中的指代表达,定位图像中的具体对象。 例如,如果用户说“图像中穿红衣服的女人”,模型需要识别并定位该描述对象。
Grounded Cap:
生成描述图像内容的句子,并同时指出句子中提到的对象在图像中的位置 应用场景:增强现实、图像标注、智能助手等。 技术:结合图像描述生成和对象检测技术,生成带有位置信息的描述句子。 结合视觉内容生成相关的文字描述,但不同于一般的图像描述,它强调生成的文字必须与特定的视觉区域或对象密切相关。 通过该技术,生成的描述不仅仅是全局性的,而是针对特定的对象或场景。
OCR:
从图像中提取文本内容 应用场景:文档数字化、表单处理、车牌识别等。 技术:使用卷积神经网络(CNN)和循环神经网络(RNN)或 Transformer 模型来识别和提取图像中的文本。
Pure-text Autoregression:
生成自然语言文本,通常用于语言模型训练 应用场景:文本生成、机器翻译、对话系统等。 技术:使用自回归模型(如 Transformer、LSTM)生成文本,模型逐词生成下一个词的概率分布
3.3 Supervised Fine-tuning¶
通过指令微调对 Qwen-VL 预训练模型进行了微调,增强了其指令跟随和对话能力,从而产生了交互式 Qwen-VL-Chat 模型。
多模态指令调优数据主要来自字幕数据或通过 LLM,通常只涉及单图像对话和推理,仅限于图像内容理解。
我们通过手动注释、模型生成和策略连接构建了一组额外的对话数据,以将定位和多图像理解能力整合到 Qwen-VL 模型中。
在这个阶段,我们冻结了可视编码器,并优化了语言模型和适配器模块。
Evaluation¶
4.1 Image Caption and General Visual Question Answering¶
图像字幕 (Image caption) 和一般视觉问答 (General Visual Question Answering, VQA) 是视觉语言模型的两项常规任务。
具体来说,图像字幕要求模型为给定图像生成描述,而一般 VQA 要求模型为给定的图像-问题对生成答案。
4.2 Text-oriented Visual Question Answering¶
面向文本的视觉理解(Text-oriented visual understanding)在实际场景中具有广阔的应用前景。
4.3 Refer Expression Comprehension¶
引用表达式理解(Refer Expression Comprehension)任务要求模型在描述的指导下定位目标对象。
B. Data Format Details of Training¶
B.1 Data Format of Multi-Task Pre-training¶

B.2 Data Format of Supervised Fine-tuning¶
To better accommodate multi-image dialogue and multiple image inputs, we add the string “
Picture id:” before different images, where the id corresponds to the order of image input dialogue.In terms of dialogue format, we construct our instruction tuning dataset using the ChatML (Openai) format, where each interaction’s statement is marked with two special tokens (<im_start> and <im_end>) to facilitate dialogue termination.

During training, we ensure the consistency between prediction and training distributions by only supervising answers and special tokens (blue in the example), and not supervising role names or question prompts.