2108.03353_ Screen2Words: Automatic Mobile UI Summarization with Multimodal Learning¶
组织: University of Toronto, Google Research
Abstract¶
移动用户界面摘要(Mobile User Interface Summarization)旨在以简洁的语言描述移动端屏幕的关键内容与功能,便于在多种基于语言的应用场景中使用。我们提出了一种新的屏幕摘要方法——Screen2Words,该方法可自动将一个用户界面(UI)屏幕的核心信息浓缩为连贯的语言短语。
由于对移动端UI的摘要需要对包括文本、图像、结构以及UI语义等多模态数据的整体理解,因此我们采用了多模态学习方法。我们收集并分析了一个由人工标注的大规模屏幕摘要数据集,包含超过 112,000 条语言摘要,覆盖大约 22,000 个独特UI屏幕。
我们在一系列不同配置的深度模型上进行了实验,并使用自动准确性指标和人工评分对模型进行评估,结果表明我们的方法能够为移动端屏幕生成高质量的摘要。我们还展示了 Screen2Words 的潜在应用场景,并开源了我们的数据集和模型,以推动语言与用户界面之间更深入的融合发展。
1. Introduction¶
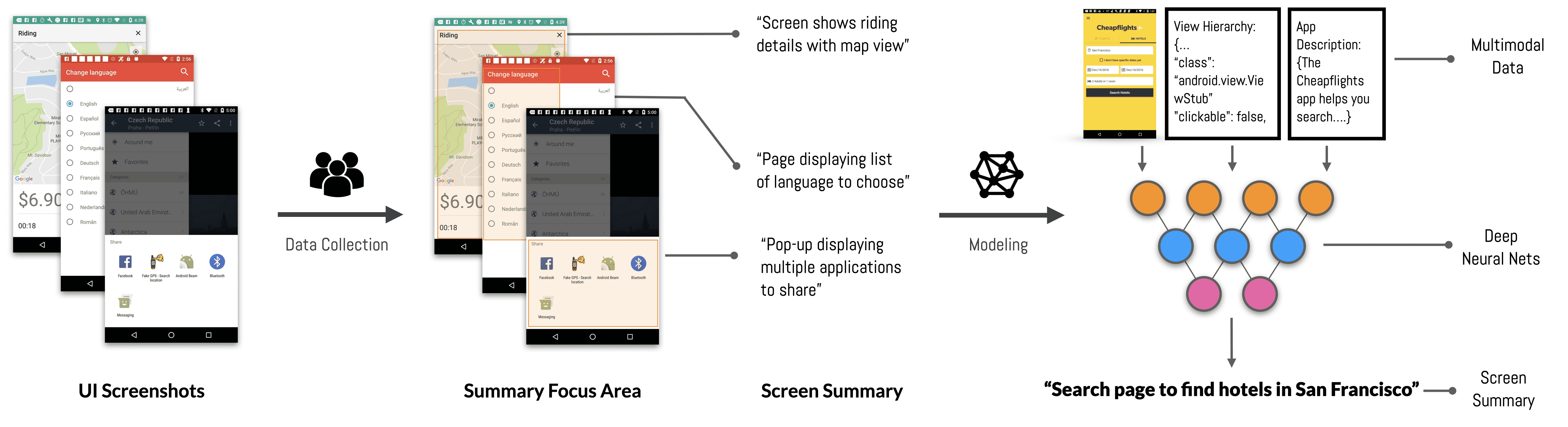
Figure 1.Screen2Words is a novel approach to automatically encapsulates essential information of a UI screen into a coherent language phrase. We collected the first large-scale screen summarization dataset, consisting of human annotations for 22,417 Android UI screens. We developed a set of deep learning models based on the dataset, leveraging the multi-modal data that a mobile screen carries. Our evaluation shows that our approach outperforms the heuristics baseline and is able to generate accurate summaries.
背景:手机界面上通常有很多图形组件,用户可以通过它们完成各种任务。如果能用一句简洁的语言描述这个界面(即“界面摘要”),对语音助手、普通用户和视障用户都很有帮助。但目前大多数应用并没有这样的功能,因为手动编写摘要既困难又不现实。
挑战:这个任务和图像描述、文本摘要类似,但更复杂,因为需要综合理解文本、图像、界面结构等多模态信息。
贡献:
提出了一个新任务:自动生成移动界面摘要(Screen2Words)。
构建了第一个大规模数据集:包含 22,417 个 Android 界面 和 112,085 条人工标注的摘要。
训练并评估了一系列深度学习模型,结合了 Transformer、ResNet 等技术,使用多模态数据,效果优于传统方法。
通过自动评测和人工评审验证了模型质量,证明了方法的有效性。
总结:这项工作提出了用自然语言总结移动界面的新方法,构建了数据集、模型,并展示了其在实际应用中的潜力。
3. Dataset Creation¶
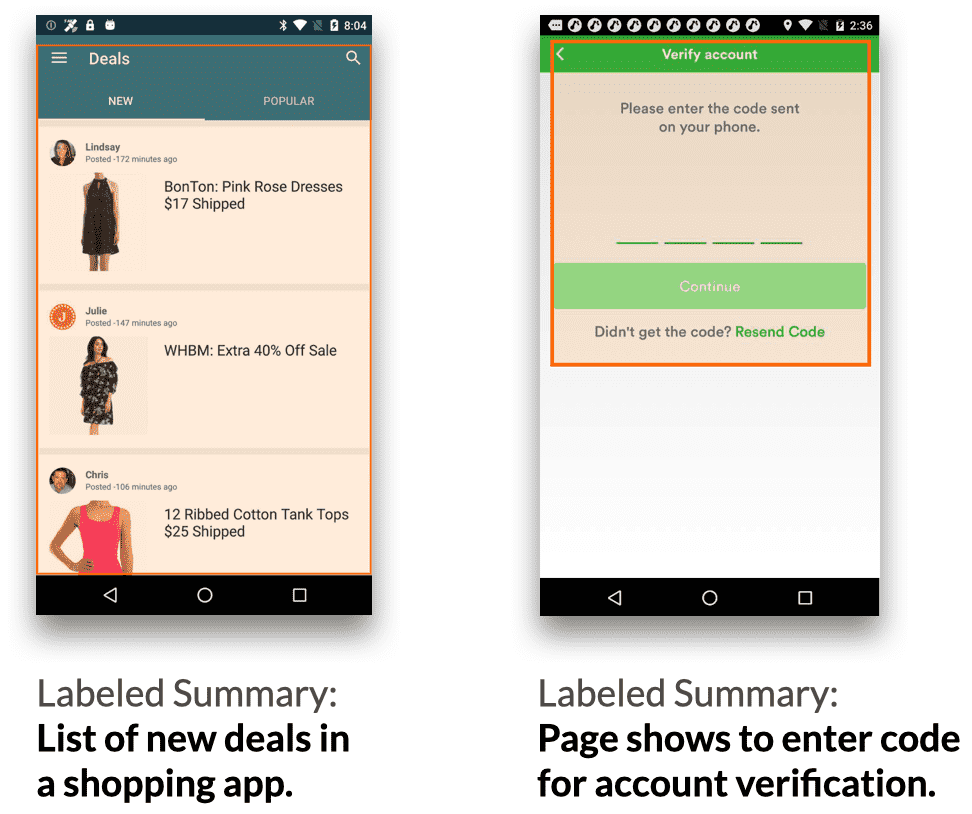
Figure 2.(a) Data annotations examples. Each screen is annotated with a language summary and a Summary Focus Area (visualized with orange rectangles) indicating where the labeler considered is most influential for their summary.
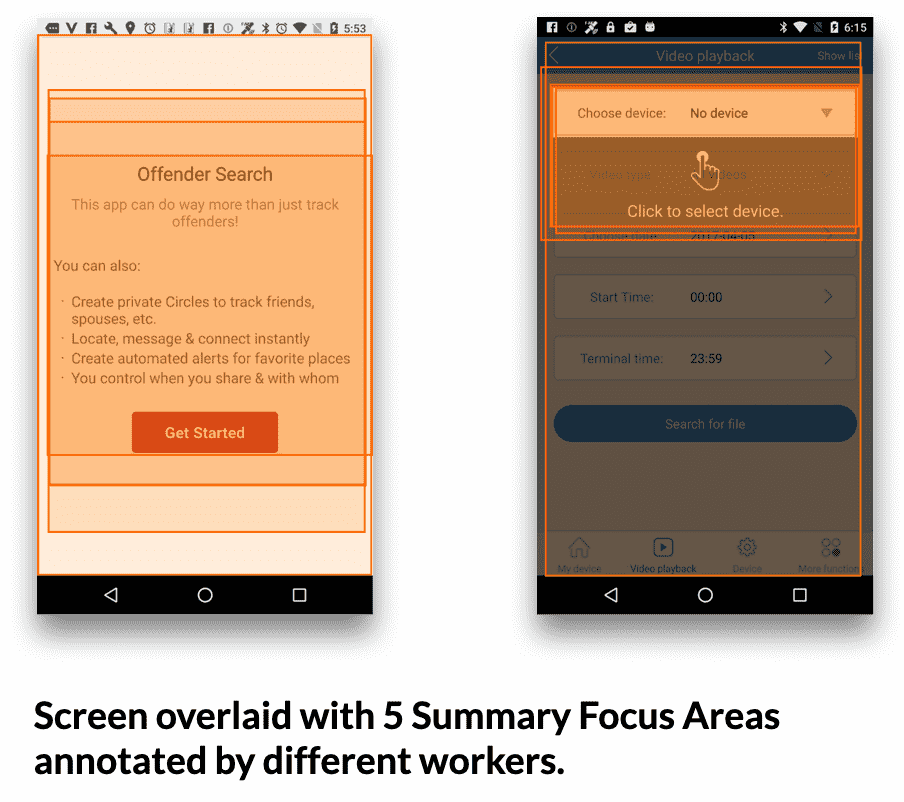
Figure 2.(b) Overlay of 5 labelers’ Summary Focus Area. Areas with the deepest colors represent the places where most labelers consider important when summarizing the screen.
数据集构建:用于移动UI自动摘要
✅ 数据来源
基于 Rico-SCA 数据集构建,筛选后包含 22,417 个移动UI屏幕
每个屏幕含截图 + 结构化视图树(View Hierarchy)
✍️ 标注流程
85位标注员,每屏幕写 5条英文摘要
总计生成 112,085 条摘要
摘要规则:
5-10词,突出功能,参考屏幕文本
避免描述图标/颜色/主观感受
🔍 摘要关注区域(SFA)
标注员用拖拽框选出最关键区域
平均SFA覆盖屏幕 66.1%
标注员之间区域一致性(IoU)高达 74.1%
4. Model Design¶
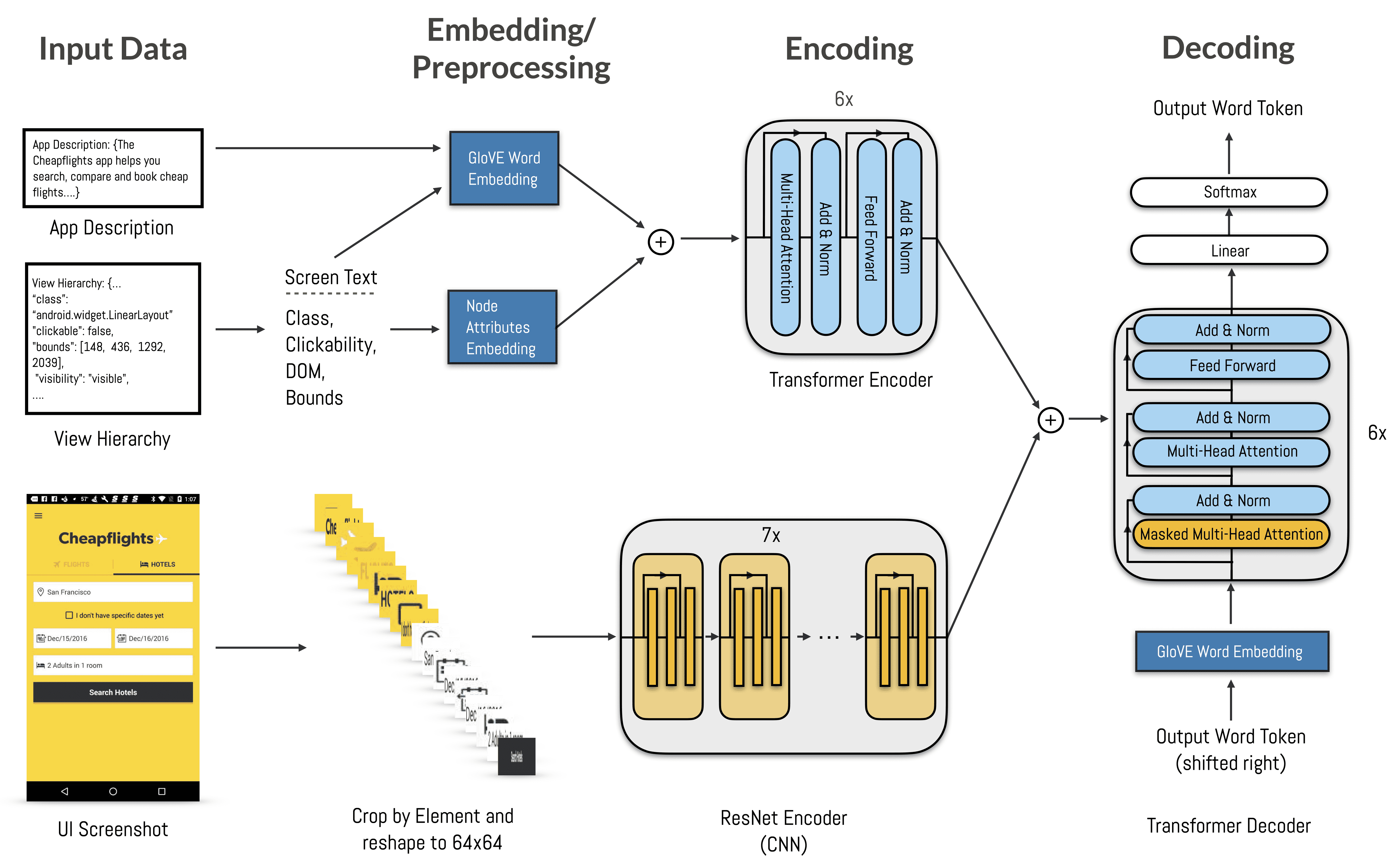
Figure 4.The Screen2Words deep model is designed based on the Transformer Encoder-Decoder architecture (Vaswani et al., 2017). It leverages three input modalities, including the UI screenshot, the view hierarchy structure, and the screen text and app description. Each modality is encoded and then fused to participate in the decoding for summary generation.
这个模型叫 Screen2Words,用于给手机界面生成简洁的自然语言描述。它使用了一种标准的 Transformer 编码-解码架构,可以处理多模态信息(即不同类型的输入):
输入有三种:
界面截图(图片)
界面结构信息(比如控件的类型、层级、位置)
应用描述文本(比如 App 的介绍文字)
编码部分:
结构+文本信息:用 Transformer 编码器处理,输入包括每个 UI 元素的文本、位置、类型等。
图片信息:对每个界面元素从截图中裁剪出小图,转成灰度图,用 ResNet 网络编码图像信息。
融合方式:把这两种编码拼接(late fusion),形成每个元素的多模态表示。
此外,还把 App 描述也当成一个特殊的“元素”放入 Transformer 编码器里,让其他元素可以通过自注意力机制访问它。
解码部分:
用 Transformer 解码器生成自然语言总结(一句话描述这个屏幕)。
解码时逐词生成,使用 自注意力 和 编码器-解码器注意力。
模型端到端训练,用交叉熵损失(对每个词进行监督学习)。
其它¶
todo