19xx_GPT2: Language Models are Unsupervised Multitask Learners¶
The Illustrated GPT-2¶

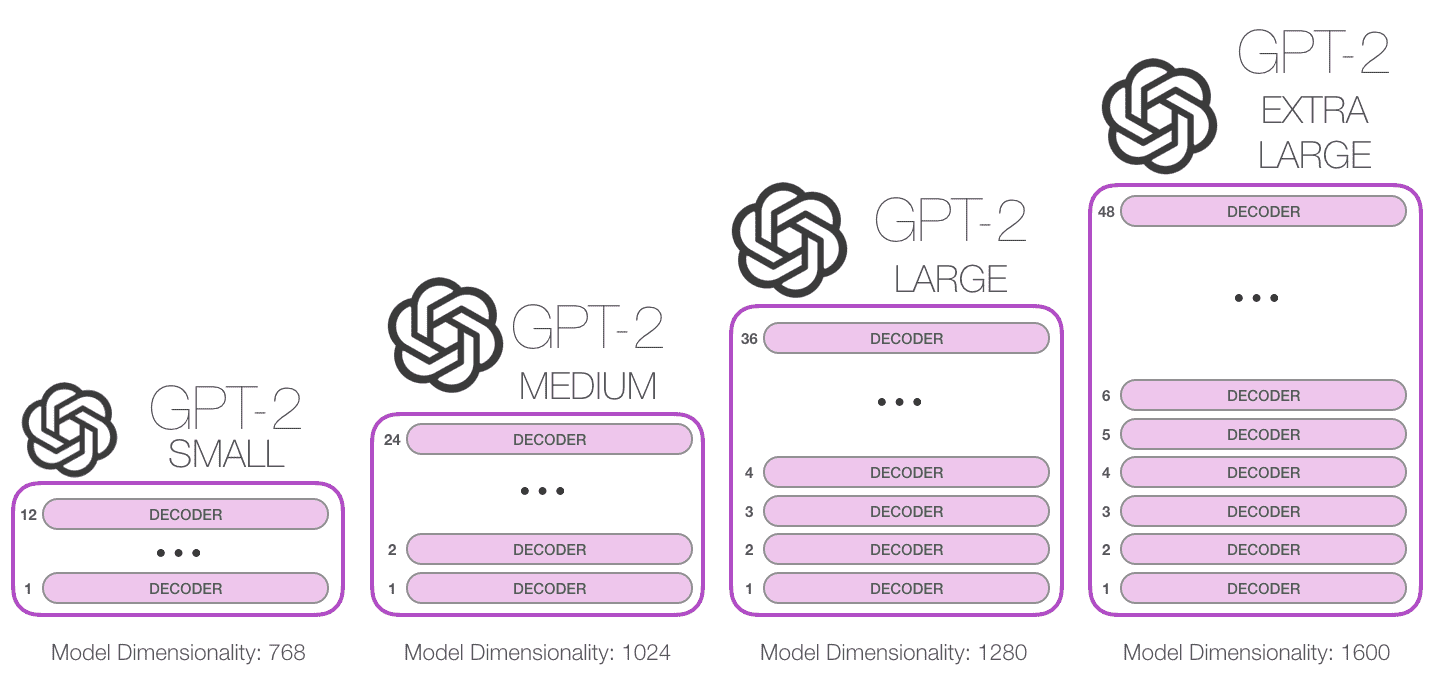
不同 GPT2 模型大小¶
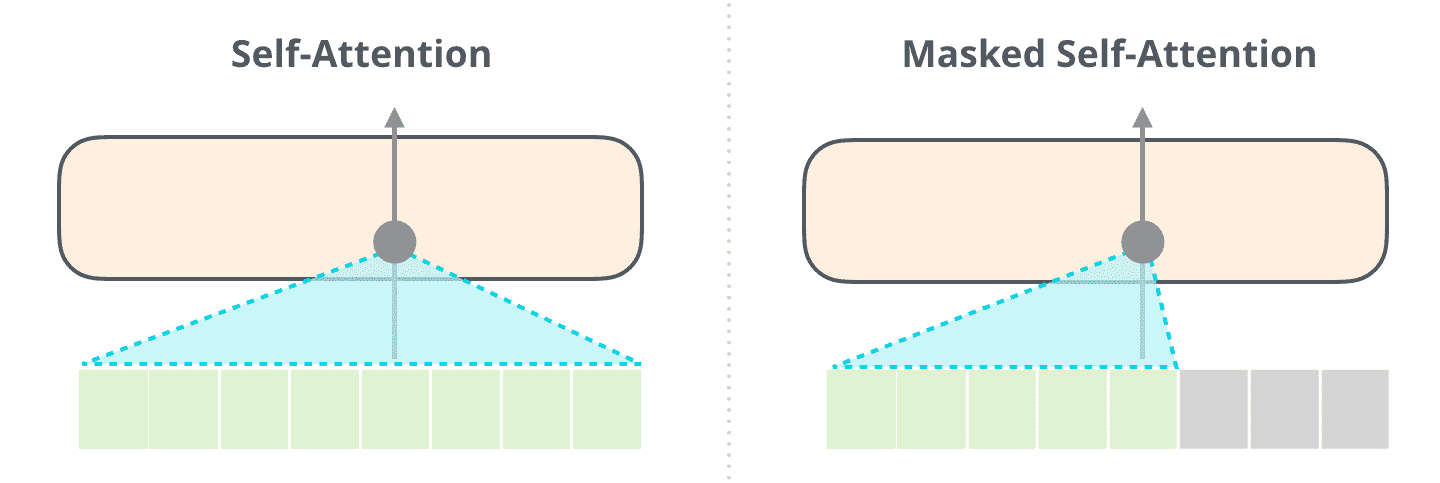
It’s important that the distinction between self-attention (what BERT uses) and masked self-attention (what GPT-2 uses) is clear. A normal self-attention block allows a position to peak at tokens to its right, Masked self-attention prevents that from happening. 自注意力(BERT)和屏蔽自注意力(GPT-2)¶
参考¶
The Illustrated GPT-2 (Visualizing Transformer Language Models): https://jalammar.github.io/illustrated-gpt2/