2110.02861_bitsandbytes: 8-bit Optimizers via Block-wise Quantization¶
组织: Facebook AI Research, University of Washington
Abstract¶
传统的状态优化器会保存过去梯度的统计信息(比如动量或平方和),用来加速训练,但这需要占用大量内存,限制了模型最大规模。本文提出了首个使用8位(而非32位)统计信息的优化器,保持性能不变。为解决计算和量化的难题,采用了“分块动态量化”技术,把张量分成小块独立量化,提升速度和精度。同时结合非线性动态量化和稳定的嵌入层,降低梯度波动,保证训练稳定。结果是在多种任务上,8位优化器用极少内存实现了与32位相当的性能,而且只需简单改动代码即可替换使用。
为了让大模型在有限显存中也能训练,大家通常会想办法减少内存占用。
虽然已有很多方法优化了模型参数的内存需求,
但**优化器(如 Adam)**里保存的梯度统计信息(比如一阶和二阶动量)占据了 33%-75% 的显存,却很少被优化。
比如 GPT-2 和 T5 的 Adam 状态就分别占了 11GB 和 41GB。
有效使用这个非常有限的范围具有挑战性,原因有三:
量化精度、计算效率和大规模稳定性。
为了保持准确性,引入某种形式的非线性量化以减少常见的小幅度值和罕见的大幅度值的误差至关重要。
为了实用,8 位优化器需要足够快,以免减慢训练速度,这对于需要更复杂的数据结构来维护量化桶的非线性方法来说尤其困难。
为了保持超过 1B 参数的大型模型的稳定性,量化方法不仅需要具有良好的平均误差,还需要具有出色的较差情况性能,因为单个较大的量化误差会导致整个训练运行发散。
为了解决这个问题,本文提出了一种新的方法,叫做块状动态量化(block-wise dynamic quantization),
把优化器的 32-bit 状态压缩成 8-bit,大大减少内存占用,同时还能保持精度和训练稳定性,不需要改超参数。
这方法有三大技术点:
块状量化:把张量切成多个小块分别处理,能隔离极端值,提升稳定性,还能并行加速。
动态量化:非线性方法,能在只用 8-bit 情况下更好保留小数值和大数值,降低误差。
稳定嵌入层:让词嵌入的输入更平稳,避免梯度变化剧烈,方便更激进的量化。
实验证明,这种 8-bit 优化器在多种任务上都能以极低的显存代价达到和 32-bit 优化器相当的效果,并且可以直接替代,不用调超参。
1. Background¶
一、Stateful Optimizers(有状态优化器)¶
优化器用梯度来更新神经网络的参数。
Momentum 和 Adam 是常用的有状态优化器,会记录梯度的历史信息来加速收敛。
Momentum 用一个动量变量 \(m_t\) 表示累计的梯度趋势;
Adam 除了动量 \(m_t\),还记录平方梯度 \(r_t\) 来自适应调整每个参数的学习率。
32位精度下,Momentum 每个参数占用 4 字节,Adam 占 8 字节,一个 10 亿参数的模型需要 4GB 或 8GB 内存。
为了节省显存,作者提出用 8bit 非线性量化把它们压缩到 1GB 和 2GB。
二、Non-linear Quantization(非线性量化)¶
量化就是把原本高精度的数字压缩成低位宽(如8位)的整数,以节省存储空间。
过程包括:
归一化:将原始数据缩放到目标范围;
映射:找到最接近的量化值;
存储索引:保存量化值的索引。
解码时用存的索引 + 反归一化,恢复近似的原始值。
动态量化方法会将张量值范围归一化到 [-1, 1],再用搜索方式找出最合适的量化值。
三、Dynamic Tree Quantization(动态树量化)¶
这是一个适用于 [-1, 1] 范围的新型量化方法,比传统线性量化精度更高。
它的编码结构:
第1位表示正负号;
接下来的0表示指数大小;
首个为1的位之后是线性部分,用于精细表示。
这种方法可以同时表示非常小或非常大的值,适合非均匀分布的数据。
2. 8-bit Optimizers¶
这段内容讲的是一种8-bit优化器的设计,重点是如何在保证训练效果的同时节省显存、提高速度。
🌟 8-bit优化器的核心组成:¶
分块量化(Block-wise Quantization):
把大张量按块切分,每块独立量化,可以避免极端值(outliers)对整体精度的影响,同时提升效率。
动态量化(Dynamic Quantization):
采用高动态范围的量化方式,能同时保留大数和小数的精度,尤其适合Adam中变化范围很大的状态变量。
稳定的嵌入层(Stable Embedding Layer):
为了让word embedding在训练中更稳定,使用了特殊的初始化方式和层归一化
同时该层保留32-bit优化器状态,避免精度损失导致训练不稳定。
🔧 使用方式:¶
每次更新时,将8-bit状态反量化成32-bit → 更新 → 再量化回8-bit存储。
所有操作都在GPU寄存器中完成,无需复制到显存,也不需要额外的内存。
🚀 优势:¶
更快:相比传统32-bit优化器,速度更快。
更省显存:优化器状态从32-bit缩减到8-bit,节省大量显存。
更稳定:通过特殊处理embedding层和分块量化,避免训练崩溃或精度下降。
3. 8-bit vs 32-bit Optimizer Performance for common Benchmarks¶
这段内容主要讲了 8-bit优化器 相比于传统的 32-bit优化器,在多个常见任务中表现如何。
📌 实验目的¶
对比8-bit和32-bit优化器在各种NLP和CV任务中的性能。
⚙️ 实验设置¶
仅替换优化器位宽(8-bit vs 32-bit),其他设置如超参数、权重精度、输入输出等都不变。
大多数实验在16-bit混合精度下训练。
涉及任务包括机器翻译、语言建模、RoBERTa预训练和微调、图像分类等。
✅ 结论¶
8-bit优化器在不改动其他设置的前提下,能保持性能、加速训练,并节省显存,非常适合资源有限的用户。
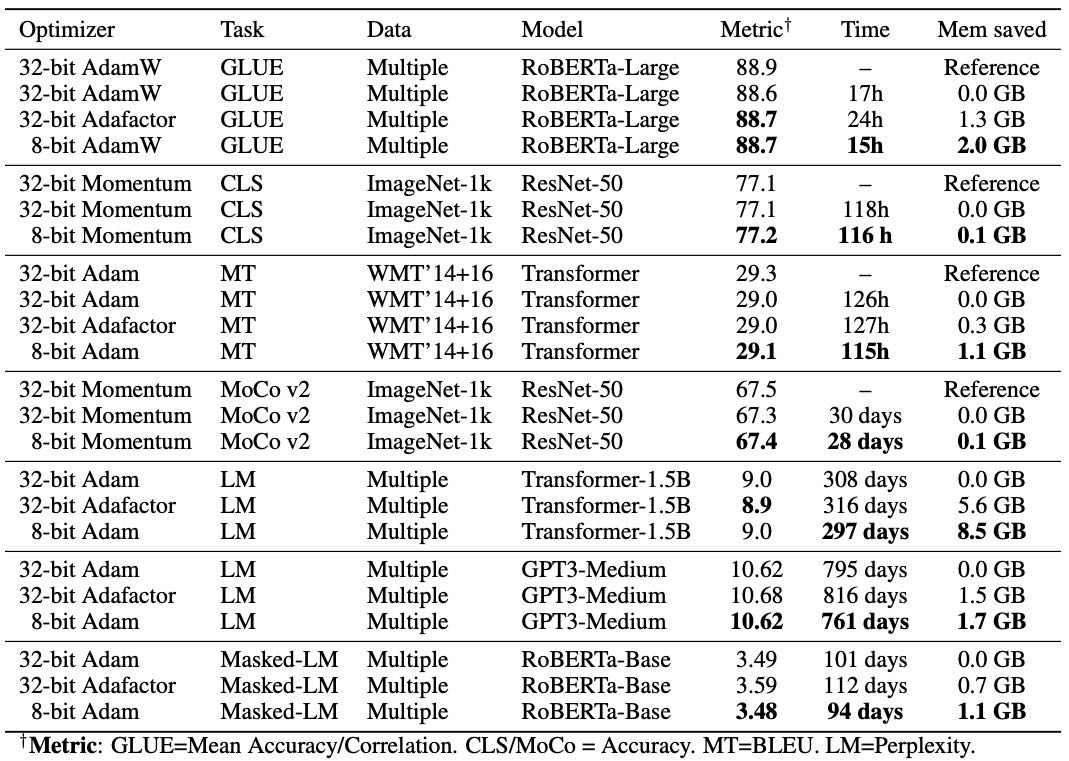
Table 1: Median performance on diverse NLP and computer vision tasks: GLUE, object classification with (Moco v2) and without pretraining (CLS), machine translation (MT), and large-scale language modeling (LM). While 32-bit Adafactor is competitive with 8-bit Adam, it uses almost twice as much memory and trains slower. 8-bit Optimizers match or exceed replicated 32-bit performance on all tasks. We observe no instabilities for 8-bit optimizers. Time is total GPU time on V100 GPUs, except for RoBERTa and GPT3 pretraining, which were done on A100 GPUs.
4. Analysis¶
研究目的:¶
作者提出了一种 8-bit Adam 优化器,希望替代传统的 32-bit Adam,以减少显存和计算资源消耗。
分析方法:¶
消融实验(Ablation):分别移除/加入关键组件,验证哪些部分对性能和稳定性是必要的。
超参敏感性分析:测试 8-bit 和 32-bit Adam 对学习率、beta、epsilon 等超参数的敏感度。
实验设置:¶
任务:Transformer 语言建模。
数据集:RoBERTa 英文子集(Books、Stories、OpenWebText、Wikipedia、CC-News)。
模型:10层 Transformer,209M 参数,训练资源高达 440 GPU 天找到最佳基线。
消融实验主要发现:¶
动态量化(Dynamic Quantization):对于训练稳定性非常关键。
块级量化(Block-wise Quantization):对大模型(10亿以上参数)的稳定性必不可少。
稳定 Embedding 层:对 8-bit 和 32-bit 都有帮助。
如果这些组件缺失,会导致模型训练失败(如梯度爆炸、损失发散)。
超参敏感性分析结果:¶
无论怎样调整超参数,8-bit Adam 的表现变化和 32-bit Adam 很接近。
说明 8-bit Adam 可以 直接替代 32-bit Adam,不需要额外调参。
结论:¶
通过动态量化、块级量化和稳定 embedding 层,8-bit Adam 能在保持性能的同时,大幅降低资源开销,并且可以直接替代 32-bit Adam。