2503.20215_Qwen2.5-Omni Technical Report¶
https://huggingface.co/Qwen
https://modelscope.cn/organization/qwen
Abstract¶
Qwen2.5-Omni 能够处理并融合 文本、图像、音频和视频 四种模态的信息输入,同时还能 实时生成文本和自然语音输出(streaming generation),是一个统一的生成式多模态大模型。
为了支持多模态信息输入的流式处理,音频与视觉编码器采用了 分块处理 的方式。这种策略有效地将长序列多模态数据的处理进行了解耦:多模态编码器负责感知任务,而长序列建模则交由大语言模型完成。这种分工通过共享注意力机制加强了不同模态之间的融合。
为了使视频输入的时间戳与音频同步,我们将音频和视频序列交错排列,并提出了一种新的位置编码方法,称为 TMRoPE(Time-aligned Multimodal RoPE)。
为了同时生成文本和语音且避免两种模态之间的干扰,我们提出了 Thinker-Talker 架构。在该框架中,Thinker 作为一个大语言模型负责生成文本,而 Talker 是一个双通道自回归模型,直接利用 Thinker 的隐藏表示生成音频 token 作为输出。Thinker 与 Talker 都支持端到端的训练与推理。
为实现流式音频 token 解码,我们引入了 滑动窗口 DiT(Sliding-window DiT),该机制限制了感受野,以减少初始数据包的延迟。
Qwen2.5-Omni 在性能上与体量相近的 Qwen2.5-VL 相当,并且优于 Qwen2-Audio。此外,Qwen2.5-Omni 在 Omni-Bench 等多模态基准测试上达到了当前最优性能(SOTA)。值得注意的是,在端到端的语音指令跟随任务中,Qwen2.5-Omni 的表现与其在文本输入任务中的表现相当,这一点在 MMLU 和 GSM8K 等评测中得到了验证。
在语音生成方面,Qwen2.5-Omni 的流式 Talker 在鲁棒性和自然度方面超越了大多数现有的流式和非流式模型。
1. Introduction¶
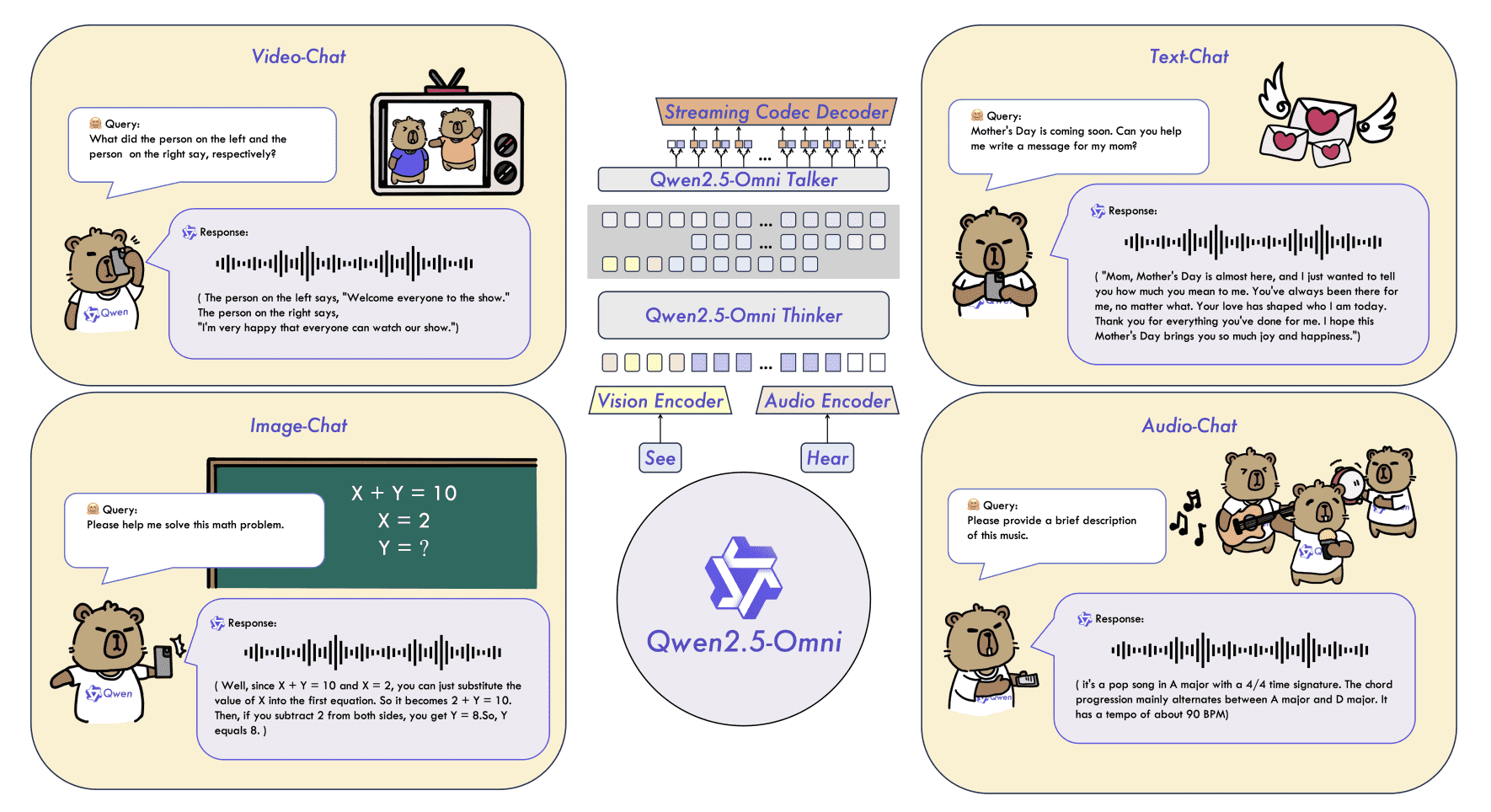
Figure 1: Qwen2.5-Omni is a unified end-to-end model capable of processing multiple modalities, such as text, audio, image and video, and generating real-time text or speech response. Based on these features, Qwen2.5-Omni supports a wide range of tasks, including but not limited to voice dialogue, video dialogue, and video reasoning.
多模态方向出现了两类新模型:
LALMs(Language-Audio-Language Models):提升听觉理解能力;
LVLMs(Language-Visual-Language Models):提升视觉理解能力;
但要构建一个能像人一样“实时多模态感知并流式表达”的统一模型,依然是难点。
为了构建一个真正“通用多模态模型(omni-model)”,需要解决以下三个核心问题:
模态联合训练:
要用系统性方法让文本、图像、音频、视频等模态在训练中互相促进;
尤其是视频模态中,音频与画面的时间同步尤为关键。
多模态输出的干扰管理:
模型需要同时输出文字和语音,如何让两个任务互不干扰是个难题。
流式处理能力和低延迟生成:
模型需实时感知多模态信息;
同时要支持流式语音生成,并降低初始响应延迟。
Qwen2.5-Omni 的设计亮点
✅ TMRoPE:时间对齐的位置编码
Time-aligned Multimodal RoPE,一种改进的位置编码机制;
通过交错排列(interleaved)音频与视频帧,保持时间顺序的一致性,强化跨模态对齐。
✅ Thinker-Talker 架构
Thinker:负责文本生成(一个大语言模型);
Talker:一个双轨自回归模型,接收 Thinker 的高层表示,生成语音 token;
灵感来自人类用不同器官同时表达不同信号,依赖同一个神经系统协调;
可以端到端联合训练,保证两个输出路径彼此协同不冲突。
✅ 模态编码器支持流式处理
所有模态输入采用 分块处理(block-wise streaming),方便进行 pre-fill(提前填充上下文)
为实时感知做好准备。
✅ 流式语音生成
Talker 输出语音 token;
DiT(Diffusion Transformer)将语音 token 转换为波形;
实现低延迟的流式语音生成。
总结要点
Qwen2.5-Omni 是一个统一的多模态模型,支持 流式文本 + 语音输出;
提出 TMRoPE 时间对齐编码,强化音视频同步;
采用 Thinker-Talker 架构,同时输出语音与文字,训练时互不干扰;
多模态评测中表现优异,具备强大的语音指令执行与语音生成能力。
2. Archtecture¶
2.1 Overview¶
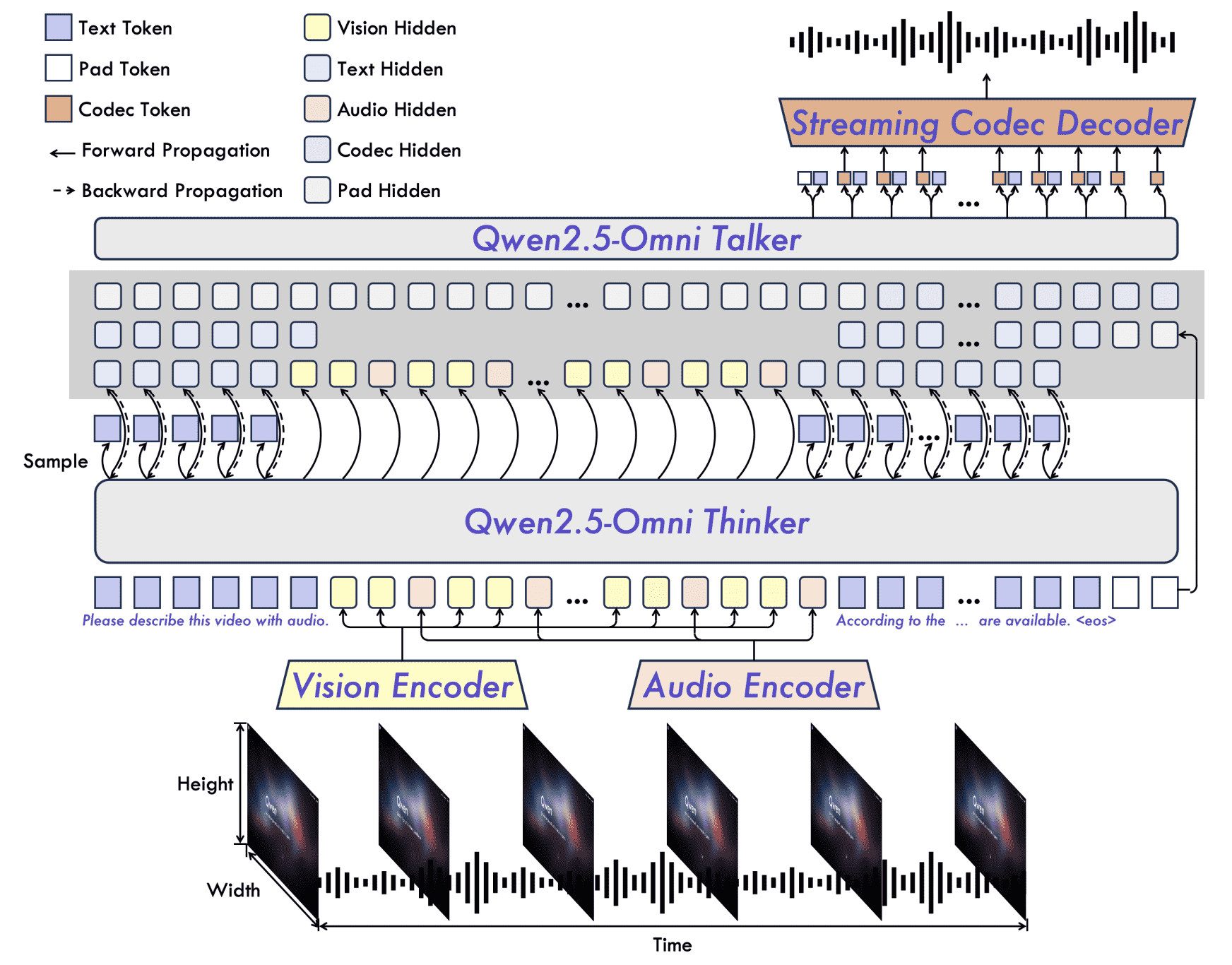
Figure 2: The overview of Qwen2.5-Omni. Qwen2.5-Omni adpots the Thinker-Talker architecture. Thinker is tasked with text generation while Talker focuses on generating streaming speech tokens by receives high-level representations directly from Thinker.
如图 2 所示,Qwen2.5-Omni 采用 Thinker-Talker 架构。Thinker 类似于人脑,负责处理和理解来自文本、音频和视频模态的输入,生成高层表示及对应文本。Talker 则像人类的嘴巴,以流式方式接收 Thinker 输出的高层表示和文本,流畅地产生离散语音 token。
Thinker 是一个 Transformer 解码器,配有用于音频和图像的编码器,用于信息提取。相比之下,Talker 是一种双通道自回归 Transformer 解码器架构,灵感来自 Mini-Omni(Xie & Wu, 2024)。在训练和推理阶段,Talker 直接接收来自 Thinker 的高维表示,并共享 Thinker 的全部历史上下文信息。因此,整个架构作为一个统一的模型运行,实现端到端的训练与推理。
2.2 感知(Perceivation)¶
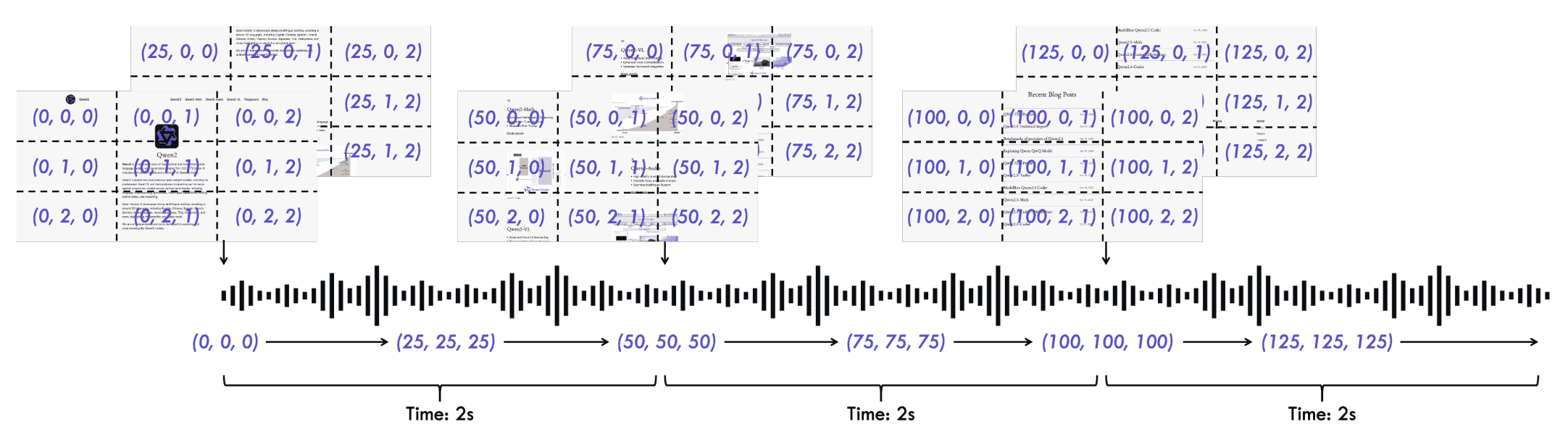
Figure 3: An illustration of Time-aligned Multimodal RoPE (TMRoPE).
文本、音频、图像与视频(无音轨): Thinker 处理文本、音频、图像和无音轨视频,将其转化为一系列隐藏表示作为输入。
文本采用 Qwen 的 tokenizer(Yang et al., 2024a),基于字节级的 BPE 编码,词表包含 151,643 个 token。
音频及视频中的音频部分被重采样为 16kHz 频率,转换为 128 通道的 mel 频谱图,窗口大小为 25ms,步长为 10ms。
采用来自 Qwen2-Audio(Chu et al., 2024b)的音频编码器,使每帧音频表示大致对应原始音频信号的 40ms。
图像与视频输入使用 Qwen2.5-VL(Bai et al., 2025)的视觉编码器,基于参数约为 675 million 的 ViT模型。
视觉编码器在图像和视频数据上混合训练,具备良好的图像理解和视频理解能力。
为了尽可能保留视频信息并适配音频采样率,视频采用动态帧率采样;
图像被当作两个相同帧处理以保持一致性。
视频与 TMRoPE: 我们提出了一种音视频时间交错算法和新的位置编码方法。
如图 3 所示,TMRoPE 结合了 M-RoPE(Multimodal Rotary Position Embedding)与绝对时间位置信息,编码多模态输入的三维位置信息(时间、高度、宽度),
其中:
文本采用统一的位置 ID,相当于 1D-RoPE;
音频同样采用统一位置 ID,并引入绝对时间编码,每个时间 ID 表示 40ms;
图像的时间 ID 保持不变,高度与宽度 ID 依 token 位置分配;
带音轨的视频则将音频每 40ms 分配一个时间 ID,图像帧的时间 ID 按实际时间增量递增,保持一致性;
多模态输入的位置信息会依序递增,避免 ID 冲突。
TMRoPE 增强了位置建模能力,实现多模态信息的深度融合,使模型能同时理解和分析多种模态的信息。
融合位置信息后,我们对各模态表示进行排序。
对于带音轨的视频,我们特别设计了时间交错方法:以每 2 秒为一段,将视频表示置前,音频表示置后,进行交错排列,如图 3 所示。
2.3 生成(Generation)¶
文本生成
文本由 Thinker 直接生成。
其生成逻辑与主流 LLM 类似,基于词表上的概率分布进行自回归采样。
生成过程中可能使用重复惩罚(repetition penalty)、Top-p 采样等策略提升多样性。
语音生成
Talker 接收 Thinker 生成的高层表示和文本 token 的嵌入。
结合高维表示和离散 token 对语音生成至关重要。
作为流式算法,语音生成必须在文本完全生成之前就预测语气和语调,高维表示能隐式表达这些信息,提升流畅性。
Thinker 的表示更偏向语义相似性,而非语音相似性,因此即便发音不同的词,其表示可能相似,需要离散 token 消除这种不确定性。
我们设计了高效的语音编码器 qwen-tts-tokenizer
可将语音关键信息压缩为 token,并通过因果音频解码器流式解码为语音。
Talker 在接收信息后开始自回归生成音频 token 和文本 token。
生成过程无需与文本在词级或时间戳级对齐,从而简化了训练与推理。
2.4 面向流式的设计¶
在流式音视频交互中,首包延迟是衡量系统性能的关键指标,其来源包括:
多模态输入处理引发的延迟;
从收到首个文本输入到输出首个语音 token 的延迟;
首段语音转为音频的延迟;
模型架构自身的延迟,如模型规模、计算量(FLOPs)等。
本文将从算法与架构两个维度说明我们在这四方面的优化设计。
支持 Prefilling
Chunked-prefills 是现代推理框架中常用机制。
为支持模态间的预填充,我们对音频与视觉编码器进行修改,使其支持时间维度上的分块注意力。
音频编码器从全局注意力改为每 2 秒一块的分块注意力;
视觉编码器采用 Flash Attention,加上简单的 MLP 层将相邻 2×2 patch 合并为一个 token,patch 大小为 14,可支持不同分辨率图像拼接为序列。
流式 Codec 生成
为实现长语音序列的流式生成,我们提出滑动窗口的分块注意力机制,限制当前 token 可访问的上下文范围。
采用基于 Flow-Matching(Lipman 等)模型的 DiT,将输入码转为 mel 频谱图,再用改进的 BigVGAN(Lee 等)将 mel 频谱还原为音频波形。

Figure 4: An illustration of sliding window block attention mechanism in DiT for codec to wav generation.
如图 4 所示,为从编码生成波形,我们将相邻的编码分组为块,并构建注意力 mask。DiT 的感受野被限制为 4 个块(回看 2 块,前瞻 1 块)。解码过程中,Flow-Matching 按块生成 mel 频谱,每个代码块能访问所需上下文,增强流式输出质量。BigVGAN 同样采用逐块方式以适应其固定感受野,从而实现语音的流式生成。
3 预训练¶
Qwen2.5-Omni 的训练分为三个阶段。
在第一阶段中,我们冻结大语言模型(LLM)的参数,专注于视觉编码器和音频编码器的训练,利用大量的音频-文本和图像-文本数据对来增强 LLM 的语义理解能力。
第二阶段中,我们解冻所有参数,使用更广泛的多模态数据进行训练,以实现更全面的学习。
在最后阶段,我们使用长度为 32k 的数据,提升模型对复杂长序列数据的理解能力。
该模型在一个多样化的数据集上进行预训练
数据类型包括图文、视频-文本、视频-音频、音频-文本以及纯文本语料。
我们遵循 Qwen2-Audio(Chu 等人,2024a)的方法,用自然语言提示替换了分层标签,这能显著提升模型的泛化能力和指令跟随能力。
在初始预训练阶段
Qwen2.5-Omni 的 LLM 组件使用 Qwen2.5(Yang 等人,2024b)中的参数初始化,
视觉编码器与 Qwen2.5-VL 相同,
音频编码器则使用 Whisper-large-v3(Radford 等人,2023)初始化。
这两个编码器在固定的 LLM 上分别训练,初期训练各自的 adapter(适配器),然后再训练编码器本体。
这个基础训练阶段对于建立模型对视觉-文本与音频-文本之间核心关联关系的理解至关重要。
预训练的第二阶段是一个重要的进步,
它引入了额外的
800 billion 图像和视频相关 token、
300 billion 音频相关 token
100 billion 视频与音频联合数据 token
该阶段引入了更大规模的混合多模态数据和更丰富的任务类型,进一步增强了模型对听觉、视觉和文本信息之间的交互理解能力。
多模态、多任务的数据集对于培养模型同时处理多种模态和任务的能力至关重要,这对于应对复杂的真实世界数据尤为重要。
此外,纯文本数据在维持和提升语言能力方面也起着关键作用。
引入长音频和长视频数据
为了提升训练效率,前两个阶段我们将最大 token 长度限制为 8192。
之后,将原始文本、音频、图像和视频数据扩展到 32,768 个 token 进行训练。
4 后训练(Post-training)¶
4.1 数据格式¶
ChatML 数据集格式示例如下:
<|im_start|>user
<|vision_start|>Video.mp4 [视频中有两个人在交谈]<|vision_end|>视频中的人都在说什么?<|im_end|>
<|im_start|>assistant
两个画面都展示的是海绵宝宝。穿红色衣服的人说:“你好,今天天气怎么样?”穿黑色衣服的人回答:“你好,今天天气很好。”<|im_end|>
<|im_start|>user
<|vision_start|>Video.mp4 [视频中有人说:“请描述你面前的那个人。”]<|vision_end|><|im_end|>
<|im_start|>assistant
你面前的人戴着眼镜,穿着棕色夹克,里面是蓝色衬衫。他看起来正在说话或做出反应,嘴巴张开,显得很专注。背景中可以看到一个挂在墙上的空调、一排挂着各种衣物的衣架,以及一个显示夜间城市景观的大屏幕。房间的灯光温暖而舒适。<|im_end|>
4.2 Thinker¶
在后训练阶段,我们采用 ChatML(OpenAI,2022)格式的指令跟随数据进行 instruction-finetuning(指令微调)。我们的数据集包含纯文本对话、视觉模态对话、音频模态对话,以及混合模态对话。
4.3 Talker¶
我们为 Talker 模块引入了三阶段的训练流程,使 Qwen2.5-Omni 能同时生成文本和语音响应。
第一阶段训练 Talker 学习上下文衔接;
第二阶段使用 DPO(Rafailov 等人,2023)方法增强语音生成的稳定性;
第三阶段进行多说话人指令微调,以提升语音响应的自然度和可控性。
在 In-Context Learning(ICL)训练中
除了类似 Thinker 的文本监督外,我们还引入语音续写任务,
通过 next-token 预测方式进行训练,数据集包括多模态上下文和语音响应对话。
Talker 学会从语义表示到语音的单调映射,并具备表达语调、情绪、口音等多样语音特征的能力。
同时我们引入 timbre disentanglement(音色解耦)技术,以防模型将特定声音错误地关联到罕见文本模式上。
DPO 损失函数如下:
为了扩展说话人和场景的覆盖范围,预训练数据不可避免地存在标签噪声和发音错误,可能导致模型产生幻觉(hallucination)。
为缓解这一问题,我们引入了强化学习阶段以提升语音生成的稳定性。
具体做法是:
对于每条请求和对应的文本响应及参考语音,我们构建一个包含三元组 (x, y_w, y_l) 的数据集,
其中 x 是输入文本序列,y_w 和 y_l 分别是好的和差的语音生成结果。
我们根据字错误率(WER)和标点停顿错误率打分并进行样本排序。
最后,我们对上述基础模型进行说话人微调,使 Talker 能采用特定声音,并提升语音生成的自然度。
5. Evaluation¶
5.1 Evaluation of X→Text¶
Text→Text
任务类型:
通用能力评估:MMLU-Pro, MMLU-redux, LiveBench0803
数学与科学:GPQA, GSM8K, MATH
编程能力:HumanEval, MBPP, MultiPL-E, LiveCodeBench
优于 Qwen2-7B,接近或略低于 Qwen2.5-7B
Audio→Text
涉及任务:
音频理解:ASR(自动语音识别)、S2TT(语音翻译)、SER(语音实体识别)、VSC(声音分类)、音乐理解
音频推理:MMAU(包括语音、音乐、环境音)
语音对话:VoiceBench、语音指令聊天评估(使用自构建语音指令数据集)
主要发现:
ASR 在多个标准集上表现强劲(如 LibriSpeech、CommonVoice、Fleurs、Wenetspeech),优于 Whisper-v3、MinMo、Qwen2-Audio 等。
语音翻译(S2TT) 任务中表现领先,尤其是中英互译上超过 MinMo。
语音情感识别(SER) 得分为 0.570,优于 MiniCPM-o 和 Qwen2-Audio。
语音交互能力 在 VoiceBench 上得分 74.12,表明强大的语音理解与生成能力。
Image→Text
涉及任务:
大学水平推理与数学题:MMMU、MMMU-Pro、MathVista、MathVision
通用视觉问答:MMBench、MMVet、MMStar、MME、MuirBench、RealWorldQA 等
OCR / 文本图理解:AI2D、TextVQA、DocVQA、ChartQA、OCRBench_v2
视觉定位与指代:RefCOCO、RefCOCO+、RefCOCOg、object detection in the wild、自构建点定位任务
Video (w/o Audio) →Text
我们在多个具有代表性的视频理解任务上评估了模型的表现,如
Video-MME(Fu 等,2024a)、MVBench(Li 等,2024a)和 EgoSchema(Mangalam 等,2023)。
Multimodality →Text
在 OmniBench(Li 等,2024b)上展示了模型对于混合模态(图像、音频和文本)提示的处理能力。
5.1.1 Performance of Text→Text¶
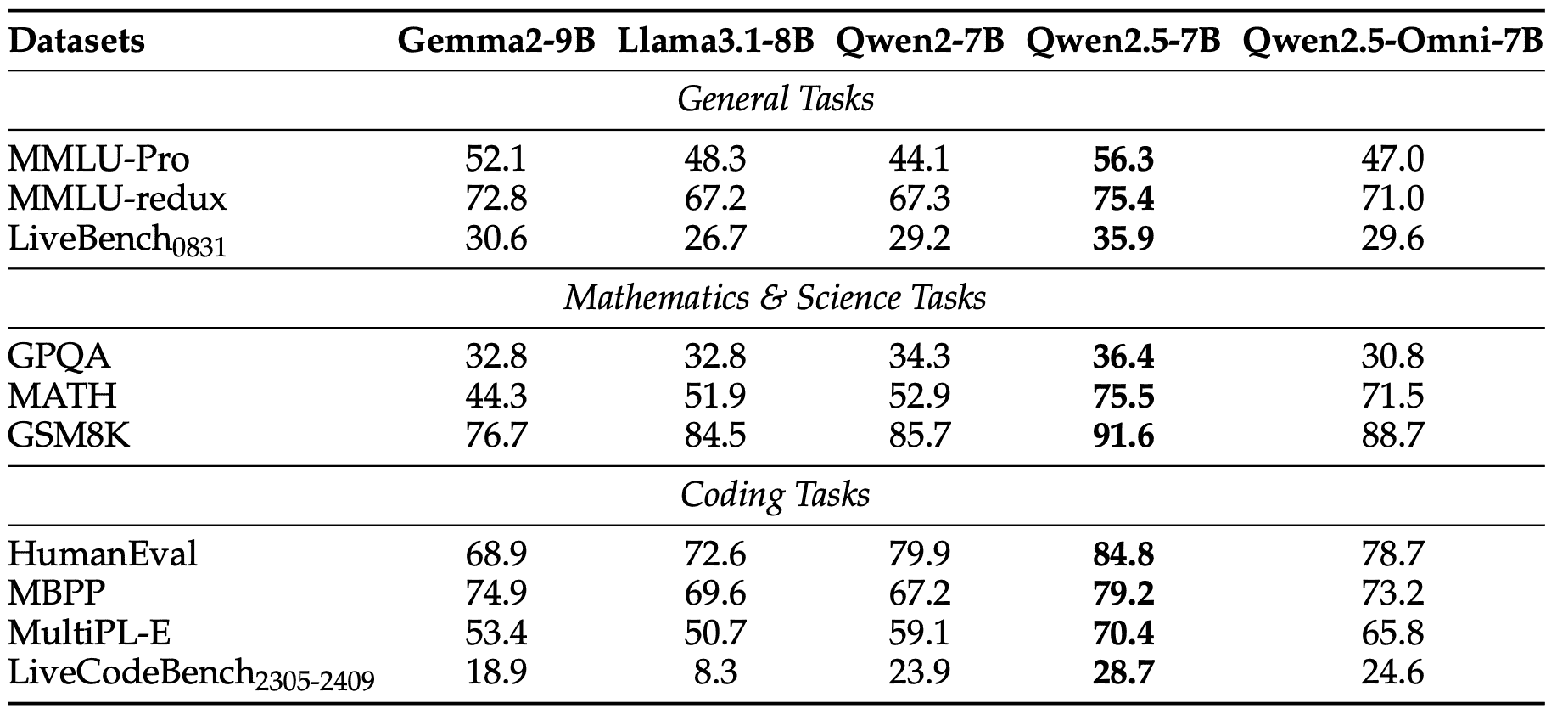
Table 1: Text → Text performance of 7B+ pure text models and Qwen2.5-Omni
5.1.2 Performance of Audio→Text¶
以下是 Qwen2.5-Omni 在 Audio → Text 任务中使用和评测的数据集,按照任务类别整理如下:
ASR(Automatic Speech Recognition)
LibriSpeech
子集:
dev-clean,dev-other,test-clean,test-other
Common Voice 15
语言子集:
en,zh,yue,fr
Fleurs
语言子集:
zh,en
Wenetspeech
子集:
test-net,test-meeting
Voxpopuli-V1.0-en
S2TT(Speech-to-Text Translation)
CoVoST2
子集:
en-de,de-en,en-zh,zh-en
SER(Speech Emotion Recognition)
MELD
用于评估情感识别表现
VSC(Vocal Sound Classification)
VocalSound
MUSIC(Music Understanding)音乐理解任务
GiantSteps Tempo
音乐节奏识别
MusicCaps
多项指标
音频推理(Audio Reasoning)
MMAU Benchmark
子任务:
Sound,Music,Speech
语音对话 / 多轮问答(Voice Chatting)
VoiceBench(两个子表) a. 多项语音问答和对话评估: *
AlpacaEval*CommonEval*SD-QA*MMSUb. 多个推理/知识测试集语音化后的语音输入评测: *OpenBookQA*IFEval*AdvBench
语音指令交互任务(Text Benchmark → Speech)
MMLU
CEval
IFEval
GSM8K
Math23K
Math401
5.1.3 Performance of Image → Text¶
图像转文本任务(Image → Text)相关数据集
大学水平问题理解(College-level Problems)
MMMU val
MMMU-Pro overall
数学视觉问答(Mathematical VQA)
MathVista testmini
MathVision full
通用视觉问答(General Visual Question Answering)
MMBench-V1.1-EN test
MMVet turbo
MMStar
MME sum
MuirBench
CRPE relation
RealWorldQA avg
MME-RealWorld en
MM-MT-Bench
OCR 与图文理解任务(OCR-related Tasks)
AI2D
TextVQA val
DocVQA test
ChartQA test Avg
OCRBench_V2 en
视觉指代与定位任务(Visual Grounding)相关数据集
Referring Expression Comprehension
RefCOCO val
RefCOCO textA
RefCOCO textB
RefCOCO+ val
RefCOCO+ textA
RefCOCO+ textB
RefCOCOg val
RefCOCOg test
Open Vocabulary Detection / 指定点定位
ODinW (Open-vocabulary Detection in the Wild)
PointGrounding
5.1.4 Performance of Video → Text¶
Qwen2.5-Omni 在多个视频理解数据集上的表现优于目前所有主流开源多模态模型,包括 GPT-4o-Mini,整体接近或超过 Qwen2.5-VL-7B,说明其视频理解能力非常强。
数据集名称 |
简介 |
|---|---|
Video-MME w/o sub |
视频多模态评测集,不含字幕 |
Video-MME w sub |
视频多模态评测集,包含字幕信息 |
MVBench |
视频理解评测集,评估多模态推理和理解 |
EgoSchema (test) |
主观视角视频理解任务,评估模型对自我视角事件的理解能力 |
5.1.5 Performance of Multimodality→Text¶
在多模态评测基准 OmniBench 上,Qwen2.5-Omni 远超其他模型,显示出它在多模态理解上的显著优势(图像、语音、音乐等多种信息融合处理能力很强)。
数据集名称 |
模态内容 |
简介 |
|---|---|---|
OmniBench |
语音(Speech)、声音事件(Sound Event)、音乐(Music) |
多模态统一评测基准,覆盖声音类多模态理解任务,评估指标包括分类准确率和平均分(Avg) |
5.2 Evaluation of X→Speech¶
评估了 Qwen2.5-Omni 的语音生成能力。由于相关评估体系尚不完善,我们主要从文本转语音(TTS)的角度,聚焦于零样本与单说话人语音生成两方面
零样本语音生成
我们在 SEED 数据集(Anastassiou 等,2024)上评估了模型在零样本语音生成任务中的内容一致性(WER)与说话人相似度(SIM)。
单说话人语音生成
我们评估了经过说话人微调后的模型在 SEED 数据集上的稳定性,并在自建数据集上评估了生成语音的主观自然度(NMOS)。
使用的数据集列表:
SEED(Anastassiou et al., 2024)
包含多个子集
test-zh:用于测试中文语音生成的一致性与相似性test-en:用于测试英文语音生成的一致性与相似性test-hard:更具挑战性的数据子集,用于评估模型在复杂或极端输入下的鲁棒性
此数据集用于以下两种评估任务:
Zero-Shot Speech Generation(零样本语音生成):
评估内容一致性(Content Consistency / WER)
说话人相似度(Speaker Similarity / SIM)
Single-Speaker Speech Generation(单说话人语音生成)
评估经过特定说话人微调后的语音稳定性与自然度
自建数据集(用于主观自然度评估)
用于评估单说话人语音生成的 主观自然度指标(NMOS)
6. Conclusion¶
Qwen2.5-Omni 是一个统一模型,旨在理解和生成多种模态内容,包括文本和实时语音。为了增强视频集成能力,我们引入了一种新的位置编码方法——TMRoPE,用于对齐音频与视频的时间轴。此外,我们提出了 Thinker-Talker 框架,以支持实时语音生成,同时尽量减少不同模态之间的干扰。我们还采用了诸如块级音频/视觉编码和滑动窗口的代码转音频(code-to-wav)机制等技术。该创新模型在复杂的视听交互和语音对话中的情感理解方面表现出色。
全面评估结果表明,Qwen2.5-Omni 在多模态任务中优于同等规模的单模态模型,尤其是在语音指令理解方面表现突出,达到了当前多模态任务的最先进水平。
在模型开发过程中,我们识别出多个在以往学术研究中常被忽视的重要问题,例如视频文字识别(video OCR)和音视频协同理解。解决这些挑战需要学术界与工业界的共同协作,特别是在构建完善的评估基准和研究数据集方面。我们相信,Qwen2.5-Omni 是朝向通用人工智能(AGI)迈出的重要一步。