2412.04468_NVILA: Efficient Frontier Visual Language Models¶
GitHub: https://github.com/NVlabs/VILA
组织: 1NVIDIA 2MIT 3UC Berkeley 4UC San Diego 5University of Washington 6Tsinghua University
Demo演示: https://vila.hanlab.ai/
Abstract¶
摘要: 近年来,视觉语言模型 (VLM) 在准确性方面取得了重大进展。然而,他们的效率受到的关注要少得多。本文介绍了 NVILA,这是一个旨在优化效率和准确性的开放式自动立体货柜系列。在 VILA 的基础上,我们改进了其模型架构,首先提高了空间和时间分辨率,然后压缩了视觉标记。这种“ 先缩放后压缩 ”的方法使 NVILA 能够高效处理高分辨率图像和长视频。我们还进行系统调查,以提高 NVILA 从训练到部署的整个生命周期的效率。NVILA 在各种图像和视频基准测试中达到或超过许多领先的开放式和专有 VLM 的准确性。同时,训练成本降低 1.9-5.1× ,预填充延迟降低 1.6-2.2× ,解码延迟降低 1.2-2.8× 。我们提供代码和模型以促进可重复性。
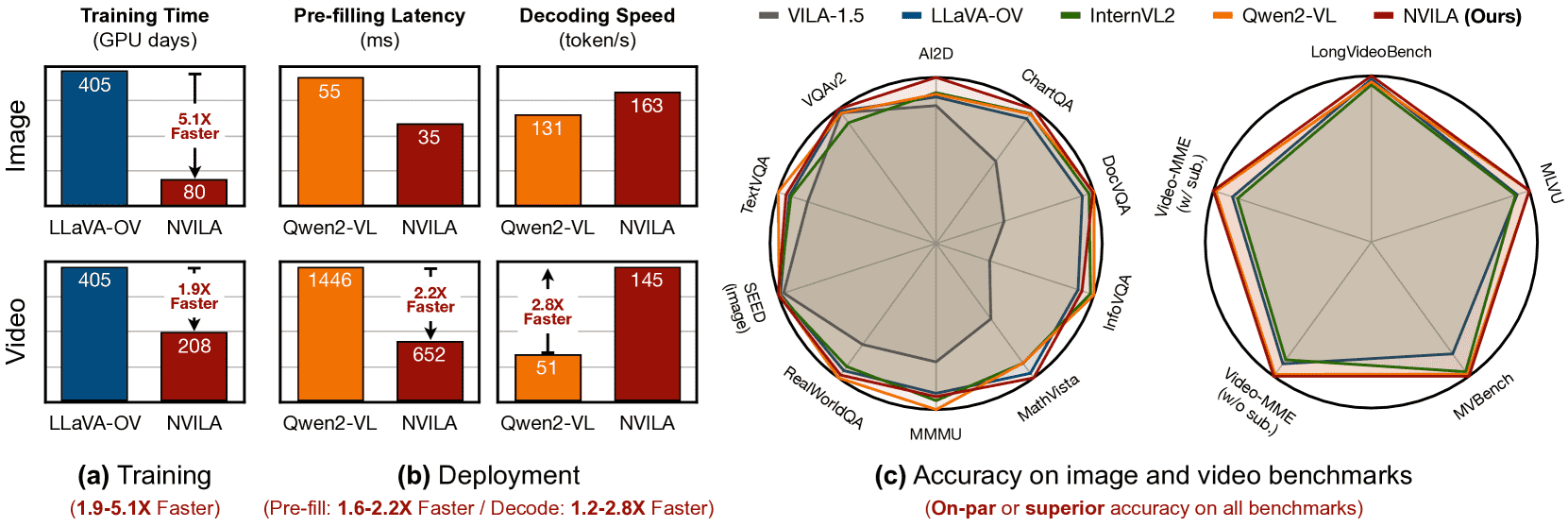
Figure 1: NVILA – Efficient Frontier VLMs.
(a) NVILA trains image and video models 5.1× and 1.9× faster, respectively, than LLaVA-OneVision (OV), which is the only baseline model with publicly disclosed training costs.
(b) Against Qwen2-VL, NVILA achieves a 1.6–2.2× measured speedup in the pre-filling stage and a 1.2–2.8× speedup during the decoding stage.
(c) NVILA’s efficiency is achieved without compromising accuracy; in fact, it delivers comparable or even superior accuracy across image and video benchmarks.
All models in this table have 8B parameters.
Training time in (a) is measured using NVIDIA H100 GPUs, while inference speed in (b) is measured using a single NVIDIA GeForce RTX 4090 GPU. Accuracy numbers in (c) are normalized relative to the highest score for each benchmark.
1. Introduction¶
视觉语言模型(VLMs)能同时理解图像和文字,应用越来越广,比如在机器人、自动驾驶、医疗等领域表现很好,但效率方面进展较少。
目前的问题是:
训练成本高:训练一个先进的7B模型需要400个GPU天。
微调难:在特定领域(如医疗图像)使用时,微调会消耗大量内存,比如需要64GB GPU显存。
部署受限:在边缘设备(如笔记本、机器人)上运行受限于算力。
为了解决这些问题,作者提出了一个新模型家族 NVILA,目标是兼顾效率和准确率。
做法是:
提高图像/视频输入的分辨率(保留更多细节);
然后对视觉信息进行压缩(减少计算量);
这种“先放大再压缩”的策略让模型既能处理高分辨率数据,又节省资源。
改进了模型架构:
首先提升空间和时间分辨率,然后压缩视觉 token。
“放大(Scaling)”可以保留更多视觉输入的细节,从而提高模型的准确性上限;
“压缩(Compression)”则能将视觉信息压缩到更少的 token 中,从而提升计算效率。
这种“先放大,再压缩”的策略,使 NVILA 能够高效处理高分辨率图像和长视频。
此外,我们还对 NVILA 在整个生命周期(训练、微调、部署)的效率进行了系统优化研究。
结果:
训练成本最多降低5.1倍;
推理速度提升1.2–2.8倍;
精度与最好的开源或商用模型持平甚至更好;
支持新功能,比如视频中定位、机器人导航、医学图像分析。
2. Approach¶
2.1 Efficient Model Architecture¶
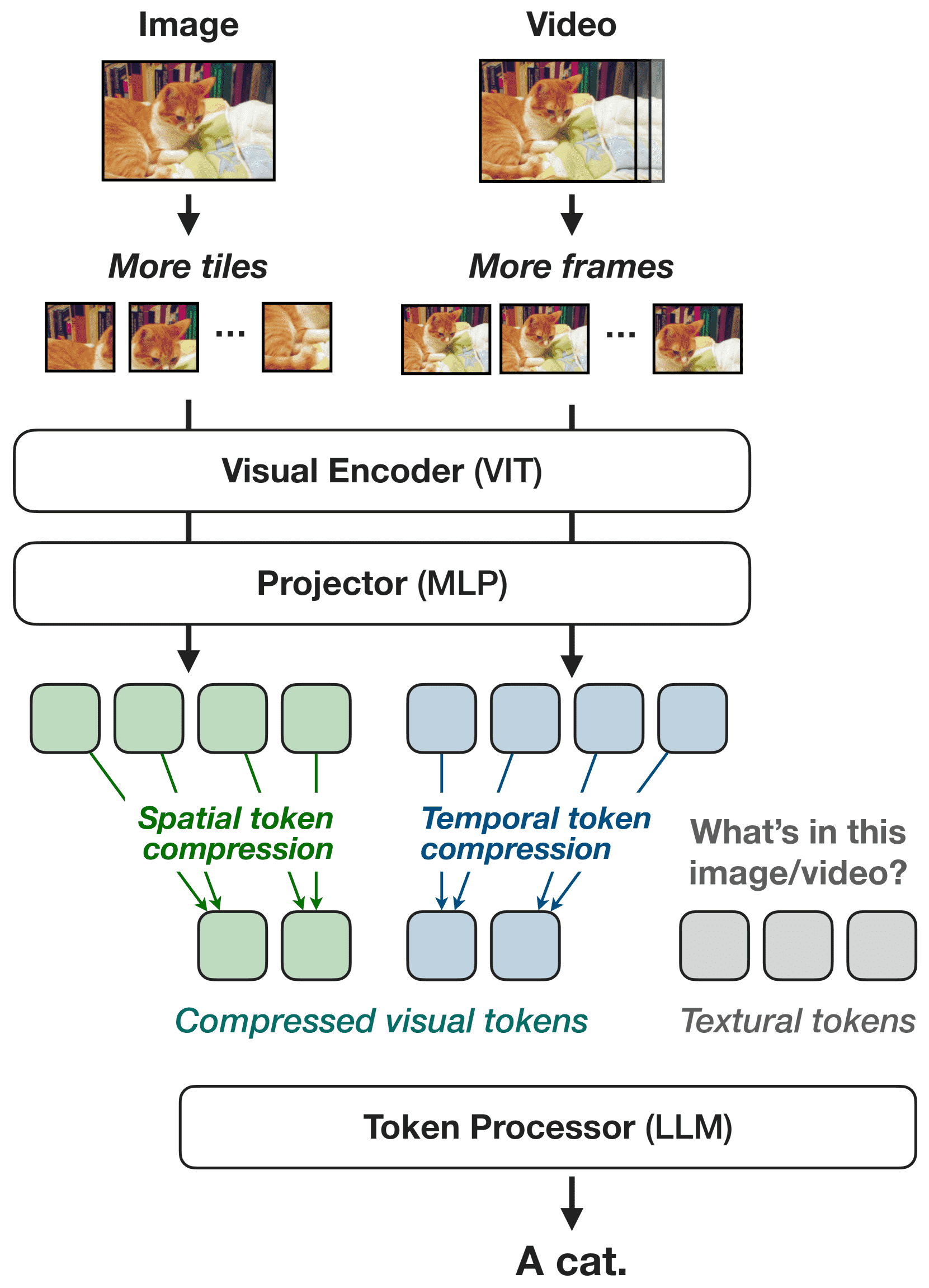
Figure 3:Model architecture.
NVILA 是基于 VILA 改进的视觉语言模型(VLM),分三部分:
视觉编码器:提取图像/视频特征(用的是 SigLIP)。
投影器:连接视觉和语言特征(2层 MLP)。
大语言模型(如 Qwen2):生成文本输出。
“先放大、再压缩”策略:
放大图像分辨率或视频帧数,提升性能上限;
然后压缩视觉 token 数量,降低计算成本。
空间维度优化(2.1.1 Spatial “Scale-Then-Compress”)¶
提高图像分辨率(如从 448×448 提升到 896×896),但不是对所有图像一刀切。
S2 方法:把图像切成小块(tiles)分别处理,避免内存浪费。
Dynamic-S2:解决不同宽高比的图像变形问题,保持原始比例切块。
压缩方案:
使用 “2×2 Spatial-to-Channel” 结构压缩 token 数量,不降性能;
更激进压缩(如 3×3)会掉精度,通过增加预训练阶段来缓解。
时间维度优化(2.1.2 Temporal “Scale-Then-Compress”)¶
增加视频帧数(比如从 8 帧增加到 32 帧)提高理解力;
时间压缩方法:用“时间平均”把相邻帧信息合并,减少冗余。
结果:模型精度大幅提升,计算成本只略有增加。
2.2 Efficient Training¶
训练大规模视觉语言模型(VLM)非常耗资源。为了加快训练速度、降低成本,作者从算法和系统两个方面进行了优化。
1. 数据集剪枝(Dataset Pruning)¶
问题: 数据量越多并不一定越好,很多数据是冗余的,反而会拖慢训练速度,甚至影响模型效果。
方法: 使用一种叫 DeltaLoss 的指标来衡量哪些训练样本更有价值,丢弃“太简单”或“太难”的样本。
简单样本:大小模型都做对 → 没什么学习价值。
太难样本:小模型做对但大模型做错 → 干扰学习。
有用样本:小模型错但大模型做对 → 对大模型提升有帮助。
结果: 用 DeltaLoss 剪掉 50% 的训练数据,模型效果基本不变,但训练速度提升约 2 倍。
结论: 比起盲目扩大训练集,智能筛选数据更有效。

Figure 4:Dataset pruning. DeltaLoss visualizations in NVILA training: Left, Middle, and Right sections show examples that are too easy, distracting, and helpful for training, respectively.
2. FP8 混合精度训练(FP8 Training)¶
背景: 传统用 FP16/BF16 精度训练模型,在不损失精度的情况下提升训练效率。
新进展: 新一代显卡(如 H100、B200)支持更节省资源的 FP8 精度。
做法:
使用 FP8 来处理权重、激活、优化器信息等,进一步减小内存消耗、提升速度。
针对 VLM 中不同样本长度差异大的特点(比如视频很长,文本很短),通过使用 FP8 可以增大 batch size(从4到16),提升计算效率。
再配合一些优化技术(如 Liger 的交叉熵内核),即使不开激活量量化,训练仍可提速 1.2 倍。
结论: 在视觉语言模型训练中应用 FP8,有显著的 加速效果和资源节省优势。
2.3 Efficient Fine-Tuning¶
训练好一个基础的多模态大模型(VLM)后,还需要通过微调来适应特定领域或任务。
传统的参数高效微调(PEFT)方法多用于纯文本任务,针对VLM的微调研究还不够多。
NVILA模型发现两个关键点:
视觉编码器(ViT)和语言模型(LLM)需要设置不同的学习率:ViT的学习率要比LLM小5到50倍。
微调哪些部分要根据具体任务选择。
此外,用 LayerNorm 微调视觉部分的效果与 LoRA 差不多,但更省资源,可减少25%的训练时间,而且能在24GB内存下适配多种任务。
2.4 Efficient Deployment¶
多模态模型常用于机器人等边缘设备中,对计算资源要求高。
NVILA开发了一个高效推理引擎,采用量化技术加速部署:
推理分两阶段:
预填阶段(主要消耗计算资源):
对输入token做压缩,减轻LLM负担;
视觉模型成了瓶颈,占90%以上的延迟;
用 W8A8 量化优化视觉模型,加快首个输出token的生成。
解码阶段(主要受内存限制):
对语言模型使用 W4A16 量化(基于AWQ);
并在此基础上引入 FP16累加优化,让核心计算速度提升 1.7倍,精度不受影响。
3. Experiments¶
训练细节
NVILA采用五个阶段训练: 1)初始化投影器; 2)视觉编码器预训练(为补偿空间信息压缩导致的性能损失); 3)令牌处理器预训练; 4)图像指令微调; 5)视频指令微调(提升长视频理解能力)。
其中第2和第5阶段是相较之前VILA模型新增的。
训练用PyTorch和DeepSpeed,使用128块NVIDIA H100 GPU,采用AdamW优化器和cosine学习率调度,结合FlashAttention等技术提升效率。
准确率结果
在多个图像理解基准测试上,NVILA表现优异,尤其在科学和视觉问答任务中与其他顶级模型(包括GPT-4o、Gemini等)竞争力强。
模型大小(8B、15B参数)越大,推理和知识类任务表现越好。
具备较强的OCR识别、多图像理解和推理能力。
视频理解方面,NVILA支持从短视频到长达一小时视频的理解,在多个视频基准上有良好表现。
总结:NVILA通过多阶段训练策略及优化技术,实现了在图像和视频多模态理解任务上的高性能和高效率。
4. More Capabilities¶
时间定位(Temporal Localization)
通过在视频中加入时间戳标记,NVILA在定位视频中事件的时间上表现优于之前的模型(比如LITA和VILA-1.5),准确度和精度都有明显提升。
机器人导航(Robotic Navigation)
NVILA可以作为机器人视觉语言导航的基础模型,能够实时处理语言指令和视频输入,规划动作并执行。
它支持多帧输入,结合历史和当前视觉信息,实现高效导航。
实验结果显示NVILA在导航任务中的表现超过了其他模型,并且能在普通笔记本GPU上实时运行。
医疗应用(Medical Application)
NVILA结合了多个医学专用的专家模型,提升了医学图像的诊断和报告生成能力。
其在医学视觉问答、报告生成和分类等任务中表现优异,整体性能较现有最先进模型提高了约9%。
总结:NVILA通过时间信息整合、多模态融合和领域专家模型支持,在视频理解、机器人导航和医疗影像分析方面实现了领先的性能。
6. Conclusion¶
论文介绍了一个名为 NVILA 的开源视觉语言模型系列,目标是在效率和准确率之间找到最佳平衡。
它采用“先放大再压缩”的方法,能高效处理高分辨率图像和长视频,同时保持准确性。
在训练、微调和推理等全过程中都做了效率优化。
NVILA 的性能达到或超过现有主流模型,但资源消耗更少。
它还能用于时间定位、机器人导航和医学影像等新场景。