2310.03744_LLaVA2: Improved Baselines with Visual Instruction Tuning¶
组织: University of Wisconsin–Madison, Microsoft Research, Redmond
Abstract¶
研究者在LLaVA框架下,系统性地分析了多模态大模型(LMM)的设计选择。
发现,LLaVA中简单的视觉语言连接模块效果很好,且对数据需求低。通过小改进(比如用更大的CLIP模型、添加学术任务的VQA数据),他们在11个评测中都达到了最先进水平。
最终模型参数为13B,只用了120万条公开数据,在一台8张A100的服务器上1天内训练完成。
初步探索了LMM在高分辨率输入、组合推理和幻觉等方面的问题,希望推动该领域研究的普及。
1. Introduction¶
当前多模态大模型(LMMs)是实现通用智能助手的关键,研究重点正转向“视觉指令微调”。
如 LLaVA 和 MiniGPT-4 等模型在视觉推理和指令跟随方面表现出色。
尽管已有很多工作和基准,但关于如何最有效地训练这类模型仍无定论。
LLaVA-1.5 的贡献:
结构简单、效率高:
LLaVA 用一个简单的全连接模块连接图像和语言部分,
仅用 60 万组公开图文数据训练,就能在多个任务上达到 SOTA(最先进)表现。
两个关键改进:
使用 MLP 连接器(视觉-语言模态之间);
引入学术类任务数据(如问答格式的视觉任务)。
相比其他模型(如 InstructBLIP、Qwen-VL),LLaVA 更轻量,不依赖私有数据或复杂结构。
进一步探索的发现:
高分辨率图像输入:通过将图像切分为网格,可支持高分辨率,提升细节理解,减少幻觉。
组合能力:长文本语言推理与短视觉任务结合训练,有助于提升多模态写作能力。
数据高效:即便将训练数据减少 75%,性能也变化不大,显示出更高效的数据利用潜力。
数据扩展性:模型能力提升依赖于更精细的数据扩展策略。
总结:
提出了一个系统性的训练方案,使用简单设计和公开数据实现了强大的 LMM(即 LLaVA-1.5)。
这项工作为开放源头的多模态研究提供了高效可复现的参考路径。
2. Related Work¶
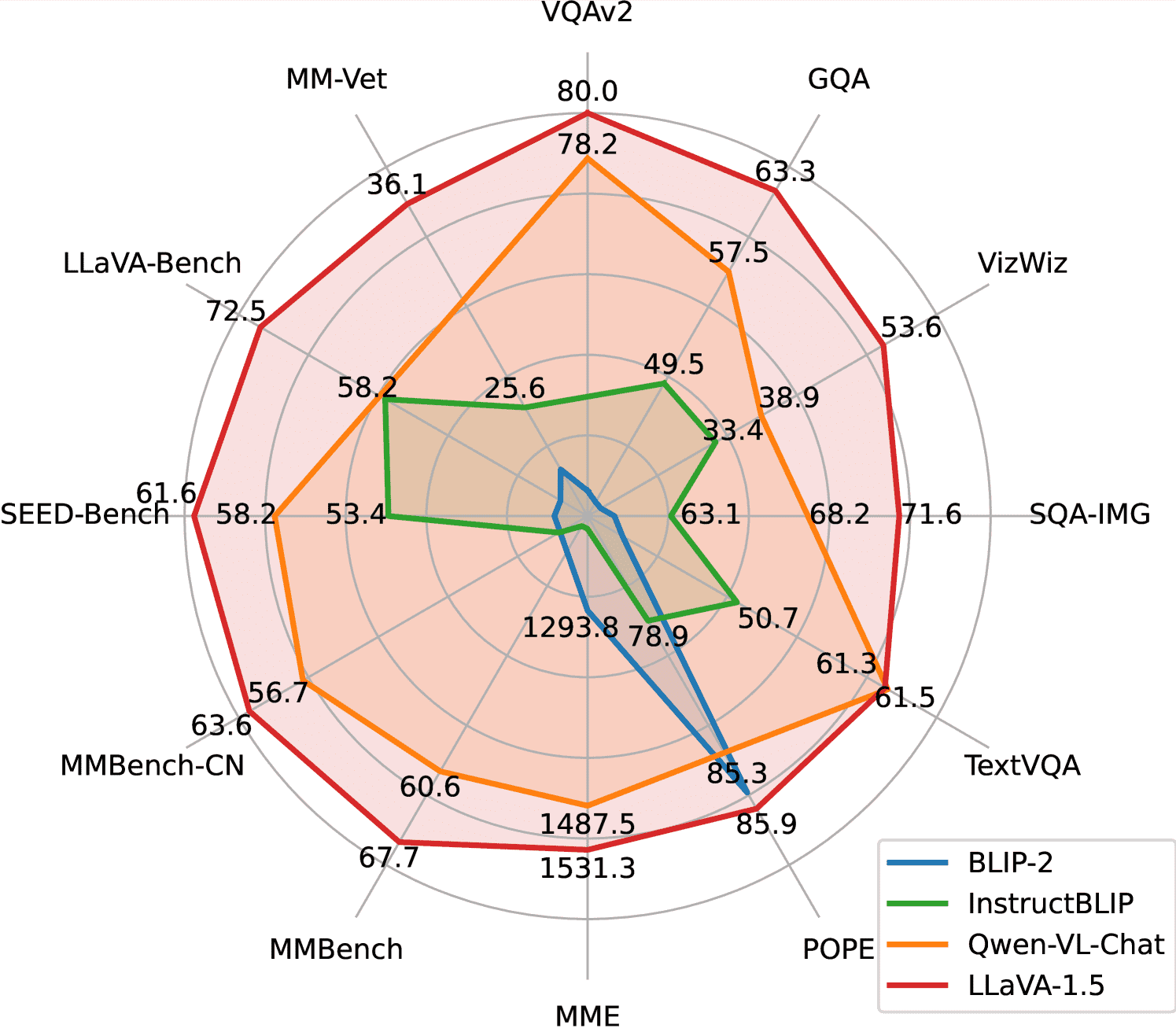
Figure 1:LLaVA-1.5 achieves SoTA on a broad range of 11 tasks (Top)
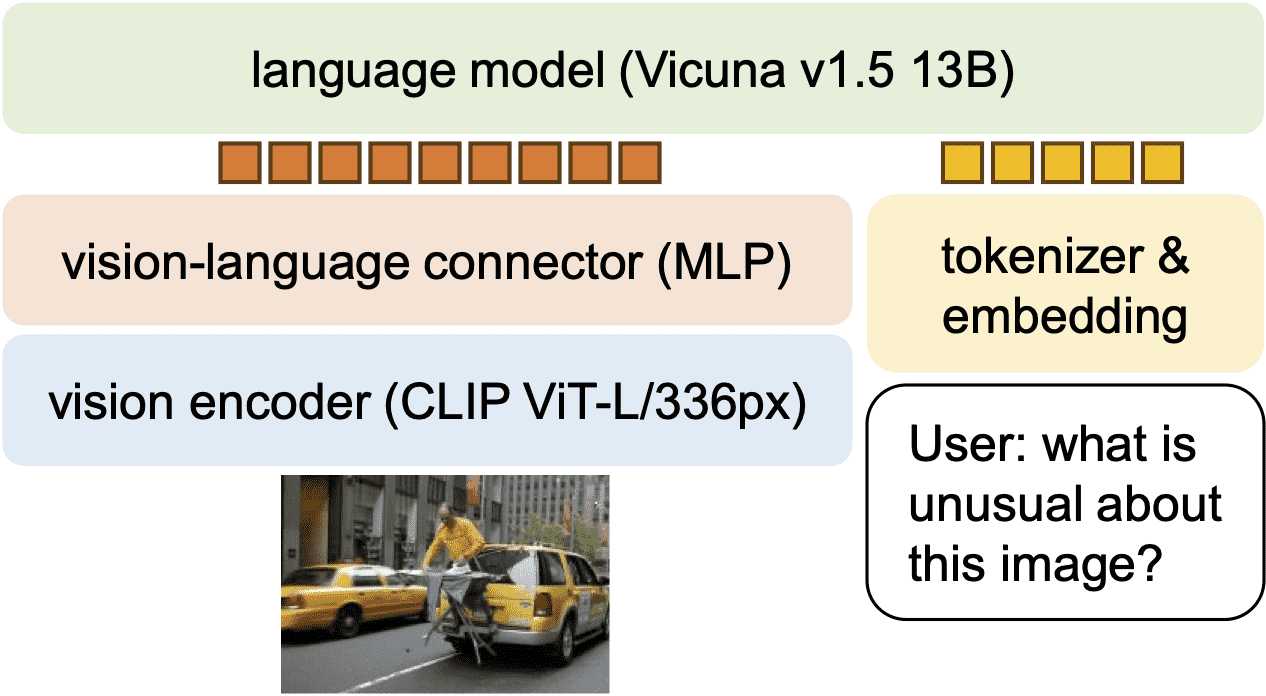
Figure 1: an MLP connector and including academic-task-oriented data with response formatting prompts.
Instruction-following large multimodal models (LMMs).¶
典型结构包括三个部分:
视觉编码器:处理图像(如ViT)。
语言模型(LLM):理解文本指令并生成回答。
视觉-语言连接器:把视觉特征转化为语言模型能理解的格式。
有时还会使用视觉重采样器(如Qformer)来减少处理图像的负担。
训练流程通常分两步:
视觉-语言预训练:通过图文对齐,把图像特征对齐到语言模型的词向量空间。训练数据量从几十万到十几亿不等。
视觉指令微调:进一步训练模型理解和响应用户带视觉内容的指令。
二、多模态指令跟随数据¶
数据质量对模型效果影响很大。
LLaVA 通过 GPT-4 把 COCO 数据扩展成包含三种类型(问答、描述、推理)的指令跟随数据,成为早期代表。
该方法被用于扩展更多类型(如文字理解、百万级别数据、区域级对话)。
InstructBLIP 使用学术问答数据集(VQA)增强模型,但这种混合数据容易导致模型过拟合,难以进行自然对话。
FLAN 系列(只在语言任务中)表明加入大量学术任务能提高模型泛化能力。
作者希望研究为何多模态模型难以在“自然对话”和“学术任务”之间做到平衡。
3. Approach¶
3.1 Preliminaries¶
LLaVA:首个视觉指令调优的大模型,在真实场景对话任务中表现好,但在学术类问答(如简短答案)上表现差。
InstructBLIP:引入了专门的VQA学术数据集(如VQA-v2),在学术基准上表现好,但在真实对话任务中不如LLaVA,容易过拟合短答案。
3.2 响应格式提示(Response Format Prompting)¶
问题:InstructBLIP不能很好区分长/短答案,因为:
指令不清(例:Q: 问题 A: 答案),让模型偏向短答案;
只微调了视觉模块(Qformer),未微调语言模型。
解决方案:在问题后添加明确指令(如“请用一个词或短语回答”)+ 微调语言模型。
效果:LLaVA 加上这种方法后,能更好区分长短答案,准确生成相应格式,无需额外处理,性能超过 InstructBLIP。
3.3 数据与模型扩展¶
MLP连接器:将图像特征接入语言模型时,改用两层MLP(比原来的线性层更强),提升多模态能力。
加入更多数据集:比如 OKVQA、OCRVQA、Visual Genome 等,用不同格式提示优化模型对细粒度图像细节的理解。
提升图像分辨率:将输入分辨率提升至 336×336,用更大的 CLIP 模型增强视觉感知。
扩大语言模型规模:将 LLM 扩展到 13B 参数,性能提升显著。
最终模型 LLaVA-1.5:综合以上所有改进,性能远超原版 LLaVA。
训练成本:由于分辨率提升,训练时长约为原来的两倍(用 8 张 A100,预训练 6 小时,微调 20 小时)。
3.4 支持更高分辨率(LLaVA-1.5-HD)¶
问题:CLIP 模型最高只支持 336×336 分辨率。
方法:将高分辨率图像切成多个小块分别编码,然后合并成一张大图的特征图,同时加入缩小图的全局特征。
优点:不需重新训练大模型,任意分辨率都能支持,保持数据效率。
新模型名为 LLaVA-1.5-HD。
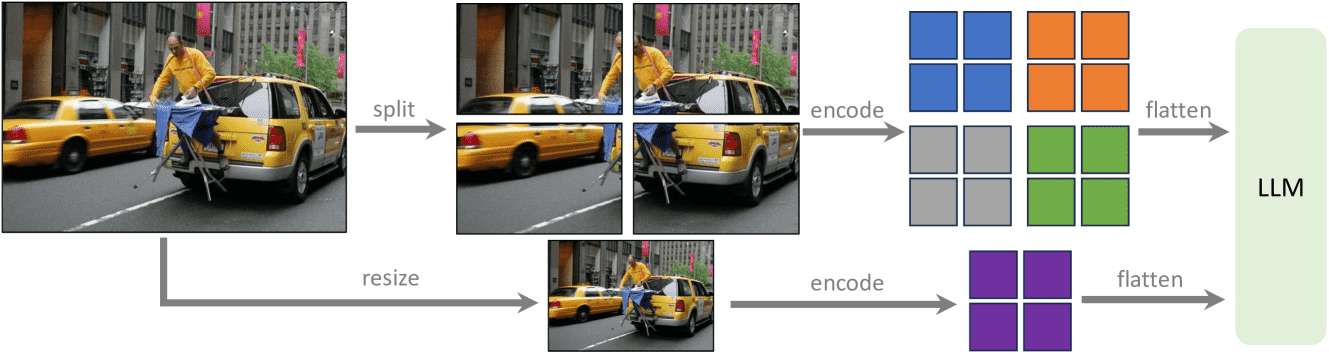
Figure 2:LLaVA-1.5-HD. Scaling LLaVA-1.5 to higher resolutions by splitting the image into grids and encoding them independently. This allows the model to scale to any resolution, without performing positional embedding interpolation for ViTs. We additionally concatenate the feature of a downsampled image to provide the LLM with a global context.
4. Empirical Evaluation¶
4.1 评估基准(Benchmarks)¶
LLaVA-1.5 被评估于 12 个视觉语言任务上,包括:
传统学术任务(如 VQA-v2、GQA、TextVQA、ScienceQA):
测试模型对图像内容的理解和回答问题的能力。
新的多模态指令跟随任务(如 POPE、MMBench、SEED-Bench):
测试模型在指令执行、文本识别、多语言、多模态对话等方面的泛化能力。
4.2 主要结果(Results)¶
LLaVA-1.5 在所有任务中表现最好,尽管训练数据远少于其他模型。
使用更高分辨率(LLaVA-1.5-HD)能进一步提升在细节感知类任务上的表现(如图文 OCR)。
简单架构 + 公共数据 + 学术级算力就能达到领先性能,挑战了“需要大规模预训练才能做好视觉-语言任务”的传统观点。
4.3 能力展示(Examples)¶
在“有误导性问题”任务中,LLaVA-1.5 能识别问题是否有错误并做出合理回答。
在“结构化 JSON 输出”任务中,能按指定格式提取图像中的关键信息。
多语言能力强,尽管没进行专门训练,仍能很好地理解中文任务,优于部分中文多模态模型。

Table 5. LLaVA-1.5 can detect and answer tricky questions when prompted to verify the question.

Table 6. LLaVA-1.5 can extract information from the image and answer following the required format, despite a few errors compared with GPT-4V.
4.4 架构分析与消融实验(Ablation)¶
基础语言模型很重要:Vicuna-v1.5(基于 LLaMA-2)比早期版本表现更佳,说明底层语言模型影响很大。
指令微调的数据也重要:使用多语言数据(如 ShareGPT)能显著提升模型的跨语言泛化能力。
4.5 结论¶
LLaVA-1.5 是一个性价比极高、完全可复现的强大视觉语言模型。它表明:
好的视觉语言表现不一定要依赖庞大的训练数据和复杂架构;
精准的指令调优和合理的训练策略同样能达成卓越效果。
5. Open Problems in LMMs¶
5.1 数据效率(Data Efficiency)¶
虽然 LLaVA-1.5 比其他方法(如 InstructBLIP)更节省数据,但相比旧版 LLaVA,所需训练数据仍然翻倍。
实验发现:只用 50% 的数据,性能依然达到 98%,甚至在某些任务(如 MMBench)上略有提升。
说明:可以在保持效果的前提下减少训练数据,有“少即是多”的潜力。
5.2 幻觉问题(Hallucination)¶
模型有时会“编造”信息(幻觉),过去认为是训练数据质量问题。
发现:即使训练数据中虚假的详细描述,将输入图像分辨率提高(如 448x448)后,幻觉明显减少。
启示:问题可能不是数据细节太多,而是模型无法正确处理低分辨率下的复杂信息,需要在数据细节和模型能力之间找到平衡。
5.3 组合能力(Compositional Capabilities)¶
模型即使只在单一任务上训练,也能在组合任务(如同时理解图像和语言)中表现出不错的泛化能力。
加入 ShareGPT 和一些视觉任务数据后,模型在视觉对话中语言能力和细节描述能力提升。
但也存在局限,比如:
能答对图像中某个属性,却不能在整图描述中准确表达它;
对某些语言(如韩语)仍不够擅长。
6. Conclusion¶
结论总结:
本文提出了一个简单、高效、节省数据的大型多模态模型基线——LLaVA-1.5,用于帮助理解大模型的设计。
同时,研究还探讨了视觉指令调优中的问题,提升了模型对高分辨率图像的处理能力,并发现了模型在幻觉(生成虚假信息)和组合能力方面的一些有趣现象。这些成果有望为开源多模态模型的后续研究提供参考。
局限性:
虽然LLaVA-1.5表现不错,但仍有不足,例如
高分辨率图像训练耗时长、不能处理多张图像、在某些领域解决问题的能力有限,还可能产生幻觉。
因此,不建议在关键场景(如医疗)中直接使用。
A. Implementation Details¶
好的,以下是对这段内容的简洁总结,按模块整理,便于快速理解:
🔧 A.1 实现细节(LLaVA-1.5-HD)¶
📷 A.1.1 预处理¶
图像编码器:用 CLIP-ViT-L-14(224x224)编码器处理图像。
分辨率选择:根据预设的多种网格布局选择合适的目标分辨率(最大 672x448),兼顾图像细节和计算效率。
特征处理流程:
删除补齐区域的特征,减少无效 token;
每行结尾加一个标记 token,帮助模型识别图像形状;
将特征展平成序列,供语言模型处理。
🏋️♂️ A.1.2 训练¶
视觉特征:直接用 CLIP 224x224 生成的特征,无需再训练视觉编码器或投影层。
训练数据:共约 66.5 万条,来自 VQA、OCR、视觉对话等多个数据集,部分有专门的回答格式要求(如用选项字母作答)。
训练策略:
将同一张图的多个问题合并成对话;
ShareGPT 数据过滤无效对话,截断太长的;
A-OKVQA 增强数据:每道题复制多份,对应多个选项;
OCRVQA 采样 8 万条;
RefCOCO、Visual Genome等做了结构优化;
视觉/语言对话分批训练以提升效率(快25%)。
📚 A.2 数据构成¶
包括视觉问答(VQA)、OCR识别、区域描述、图文对话等数据类型。
训练中对不同数据进行了整理和增强,并统一采样概率,确保多样性和平衡。
⚙️ A.3 超参数设置¶
基础模型:Vicuna v1.5。
变化点:因用了 MLP 投影层,预训练阶段学习率减半。
训练配置:
阶段 |
batch size |
学习率 |
其它设置 |
|---|---|---|---|
预训练 |
256 |
1e-3 |
cosine 学习率调度、0.03 热身比例 |
微调 |
128 |
2e-5 |
DeepSpeed stage 3 |
评估阶段采用贪婪解码(greedy decoding)确保结果可复现。
B. Qualitative Results¶
B.1. Response Format Prompts¶
多样化响应格式
模型能根据用户的要求灵活调整回答格式(如:一句话、详细解释等)。
即使是没见过的新格式提示语,模型也能理解并生成合理的回答
视觉写作任务
LLaVA-1.5能生成更丰富、细致的图文内容(如旅游博文),优于旧版LLaVA。
给出图片后,它能写出有结构、有细节的游记,包括标题、段落分布和文化背景描写。
B.2. Compositional Capabilities¶
多语言对话能力
虽然只用英语图文数据训练,但LLaVA-1.5可以进行多语言视觉对话。
这种能力被认为来自于**“视觉 + 英文”训练数据 + ShareGPT提供的多语言文本数据**的组合。
不过,在某些语言(如韩语)仍有错误,提示未来可通过补充数据改进。
Stable Diffusion 的约束式提示词生成
模型能根据指定模板生成用于图像生成的准确提示词(prompt)。
示例中展示了如何根据图像提取特征并填入格式化提示中,适用于AI绘图。

Table 12. Constrained prompt generation for Stable Diffusion. Corresponding components are marked in color.