2407.05407_CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer based on Supervised Semantic Tokens¶
GitHub: https://github.com/FunAudioLLM
组织: Alibaba
引用: 145(2025-06-22)
Abstract¶
近年来,基于大语言模型(LLM)的文本转语音(TTS)因其自然度高和零样本能力强而逐渐成为主流。这类方法通常把语音信号转为离散的“语音token”,LLM根据文本生成这些token,再由vocoder还原成音频。
但现在常用的语音token是无监督学习的,缺乏明确的语义和与文本的对齐。
这篇论文提出一种有监督的语义token,是从多语种语音识别模型中提取出来的,并用向量量化技术生成。
基于这些token,作者设计了一个名为CosyVoice的系统,包括:
一个用于生成token的LLM;
一个用于将token转成语音的模型。
实验表明:
有监督的语义token比无监督的效果更好,尤其在零样本克隆时内容更一致、说话人更相似;
使用大规模数据能进一步提升效果,说明这个方法具有可扩展性。
这是首次将有监督语音token引入TTS模型的尝试。
1. Instructions¶
背景与问题:
近年来,TTS技术快速发展,得益于大语言模型(LLM)的引入,TTS 能更自然地合成语音,甚至支持零样本克隆(zero-shot)。
传统的语音 token 通常是无监督学习得到的,可能不能很好地表达语义,也难与文本对齐。
核心创新:
本文提出用Whisper 模型中提取的监督式语义 token,相比以往无监督方法(如 k-means 聚类)更能准确对齐语音与文本。
基于这些 token,作者提出一个新的 TTS 系统:CosyVoice,它由:
一个 LLM:负责将文本转为语义 token 序列;
一个 条件流匹配模型(Conditional Flow Matching):将 token 转为语音。
与以前的方法不同,CosyVoice 不需要强制对齐器或音素处理器,训练与推理也更快。
**进一步改进:**在建模中加入了 x-vector,将语音建模分为:
语义 + 韵律 → LLM 来建模;
音色 + 环境信息 → Flow 模型来建模。
并用了优化技巧如 classifier-free guidance 和 cosine 学习率等。
实验结果:
实验表明,监督语义 token 比无监督的效果更好,CosyVoice 在大规模数据下也表现优异,证明了其可扩展性和自然度。
一句话总结:
CosyVoice 是一个结合 LLM 和流模型的高效零样本 TTS 系统,首次引入监督语义 token,有效提升了语音自然度和一致性。
2. CosyVoice: A Scalable TTS model using Supervised Semantic Tokens¶
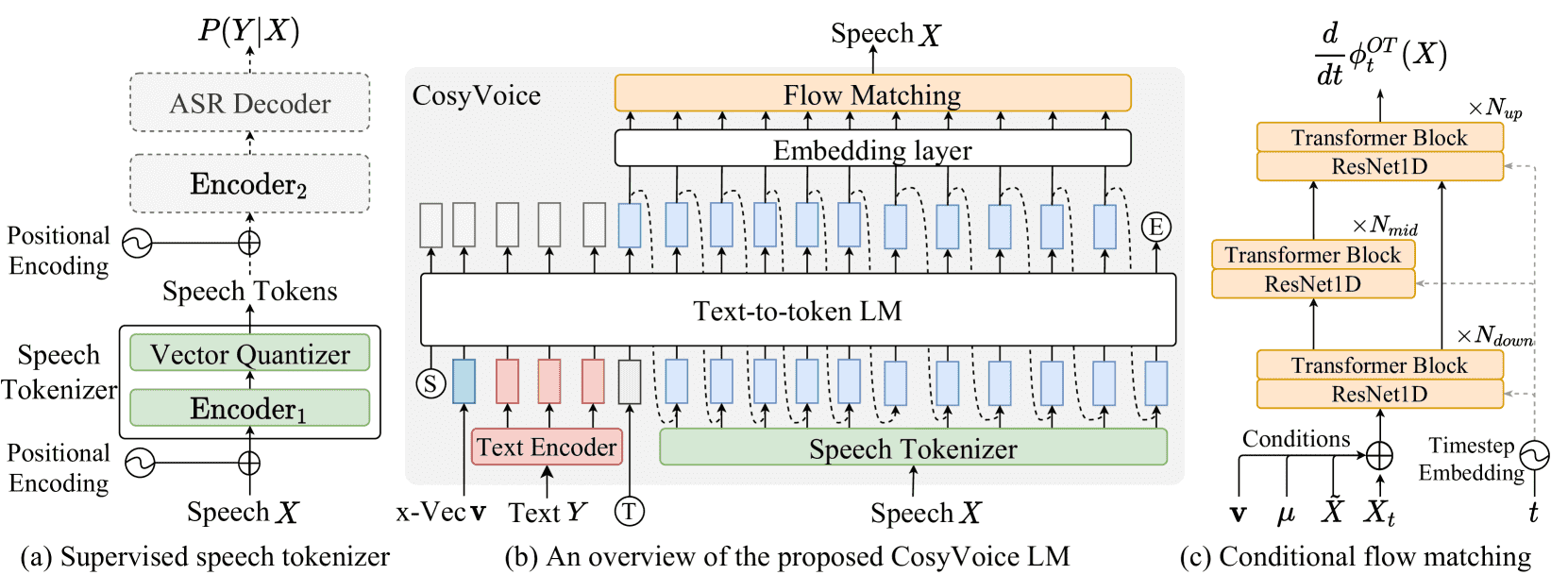
Figure 1: An overview of the proposed CosyVoice model. (a) demonstrates the \(𝒮^3\) tokenizer, where dashed modules are only used at the training stage. (b) is a schematic diagram of CosyVoice, consisting of a text-to-token LLM and a token-to-speech flow matching model. S, E and T denote the “start of sequence”, “end of sequence” and “turn of speech” tokens. Dashed lines indicate the autoregressive decoding at the inference stage. (c) provides an enlarged view of our flow matching model conditioning on a speaker embedding \(\mathbf{v}\), semantic tokens \(𝜇\), masked speech features \(tilde{X}\) and intermediate state \(X_i\) at timestep \(t\) on the probabilistic density path.
CosyVoice 是一个可扩展的文本转语音(TTS)系统,它主要包括以下四个模块:
文本编码器(Text Encoder):将输入的文字编码成向量,目的是让文字语义和语音语义在同一空间中对齐。
语音分词器(Speech Tokenizer):将语音转换成语义token(不是声学特征),这些token表示语音中的高级语义内容。
大语言模型(LLM):把TTS当作“给定文本生成语音token的序列”问题,像ChatGPT那样逐步生成语音token。
条件流匹配模型(Conditional Flow Matching):将语义token转成Mel频谱,再用HifiGAN把Mel频谱转为真实语音波形。
2.1 Supervised Semantic Tokens for Speech¶
使用一个经过微调的 ASR(语音识别)模型生成语义token,称为 S³(Supervised Semantic Speech Token)。
关键步骤如下:
用 ASR 模型的前半部分编码 Mel 频谱,得到中间表示
H。用 向量量化(VQ) 把每一帧的表示
h_l映射到一个离散token(即最近的码本向量)。用 EMA(指数滑动平均)更新码本。
得到的token序列再输入 ASR 模型后半部分,用于文字预测(用于训练时监督token质量)。
2.2 Large Language Model for TTS¶
将整个 TTS 看成一个自回归的token生成问题:给定文字编码,逐个预测语音token。
输入序列结构为:
[S, 说话人向量 v, 文本token ȳ1...U, 标记T, 语音token μ1...L, E]
S、E:起始/结束符号
v:说话人向量(用于保留音色特征)
ȳ:文本编码(通过BPE和TextEncoder获得)
μ:监督语音token
T:文本和语音之间的分隔符
训练时使用 teacher forcing(用真实前一token作为输入),只在语音token部分计算loss(交叉熵)。
2.3 Optimal-transport Conditional Flow Matching¶
这段内容主要介绍了 CosyVoice 语音生成模型中的一个关键组件:
OT-CFM(Optimal-Transport Conditional Flow Matching),以及它在语音合成、零样本学习、指令控制生成中的应用。
核心思想:OT-CFM 是一种用于生成 Mel 频谱(语音特征)的新方法:
它比传统扩散模型(DPM)训练更简单、生成更快。
它通过一种连续时间的“流”(flow)把随机噪声逐步变换成语音数据。
如何工作的:
流的定义:
用一个向量场 \(\nu_t(X)\) 描述数据从初始噪声 \(p_0(X)\) 到目标分布 \(q(X)\) 的路径。
训练方法:
使用“最优传输”(Optimal Transport)来定义一个参考流,
再训练一个神经网络来模仿这个流(最小化两者差距)。
神经网络输入:
说话人向量 \(v\)
语音 token 序列 \(\mu_l\)
被遮盖的 Mel 频谱 \(\tilde{X}_1\)
训练技巧:
用余弦函数调度时间步(开始阶段更密集采样)。
引入了“Classifier-Free Guidance”:训练时随机去掉条件信息(20%概率),这样模型既能学习有条件也能学习无条件的生成。
2.3.1 Zero-shot In-context Learning¶
CosyVoice 可以用一小段参考语音直接合成同一个人说其它话的声音,不需要再训练:
如果参考语音和输入文本是同一种语言,把两者拼成一个序列;
如果是不同语言,就只用目标文本,避免被原语音的语调影响;
支持通过人工或 ASR 获取参考文本;
参考语音提取出的 token 和 Mel 特征被用来控制生成的一致性(声音、环境等)。
2.4 Rich Generation with Instruction¶
CosyVoice-instruct 是 CosyVoice 的增强版本,支持更丰富的可控生成:
控制说话人特征(如性别、语速、情绪、音高等);
支持插入笑声、呼吸声、强调词等精细语音特征;
使用指令微调技术训练得到,不再依赖说话人 embedding。

Table 1:Examples of speaker identity, speaking style, and fine-grained paralinguistics.
总结¶
CosyVoice 通过 OT-CFM 高效地生成语音频谱,同时支持零样本迁移和指令控制,让生成的语音更自然、更可控。
3. Dataset¶
小规模英文数据集(单语)
使用的是 LibriTTS 语料库,共 585 小时音频,来自 2456 个英语说话人。
大规模多语种数据集
CosyVoice 模型训练使用了大规模多语种数据,共约 171,800 小时,包含:
中文(ZH):130,000 小时
英文(EN):30,000 小时
粤语(Yue):5,000 小时
日语(JP):4,600 小时
韩语(KO):2,200 小时
4. Experimental Settings¶
4.1 Supervised Semantic Speech Tokenizer¶
小规模单语数据集:
使用 ESPNet 的 Conformer ASR模型 做骨干。
在前6层编码器后加入一个 向量量化器(vector quantizer),用于将语音转为离散token。
使用一个 4096个code的码本(codebook)。
文本部分使用一个 词级别的 SentencePiece tokenizer(词表大小4000)。
在 LibriSpeech 上从零开始训练50轮。
大规模多语种数据集:
使用 SenseVoice-Large(通义听语2024)模型。
同样在前6层后插入4096码的量化器。
与小模型不同的是:不是从零训练,而是用预训练模型初始化,再微调。
用 8块 A800 GPU 训练21万步。
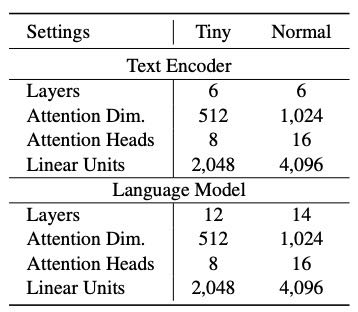
Table 4: Details of model architecture settings in the tiny and normal CosyVoice models.
4.2 CosyVoice Model Settings¶
Tiny模型:
在单语的 LibriTTS 数据集上训练。
使用 4块V100-32G显卡训练50轮。
学习率:1e-3。
Normal模型:
在内部多语种数据集上训练。
使用 64块V100-32G显卡训练80万步。
学习率:1e-4。
两者的 预热步数(warmup steps)为1万步。
6. Conclusion¶
我们提出了一个叫 CosyVoice 的多语种语音生成模型。它具有以下能力:
零样本学习(无需训练直接使用)
跨语言声音克隆(模仿说话人的声音到其他语言)
指令生成(根据指令生成语音)
细粒度控制情感和语音特征
实验发现:
模型结构对模仿说话人很重要,
文本和语音的分词器对内容准确性影响大,
增大模型和数据量能显著提升效果。