2303.03926_VALL-E_X: Speak Foreign Languages with Your Own Voice: Cross-Lingual Neural Codec Language Modeling¶
组织: Microsoft
官网有音频样例:https://aka.ms/vallex
Abstract¶
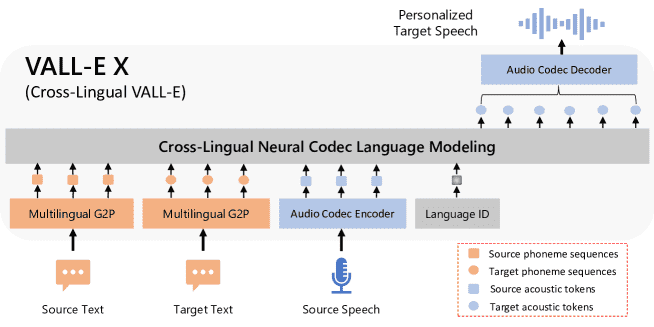
Figure 1: The overall framework of VALL-E X, which can synthesize personalized speech in another language for a monolingual speaker. Taking the phoneme sequences derived from the source and target text, and the source acoustic tokens derived from an audio codec model as prompts, VALL-E X is able to produce the acoustic tokens in the target language, which can be then decompressed to the target speech waveform. Thanks to its powerful in-context learning capabilities, VALL-E X does not require cross-lingual speech data of the same speakers for training, and can perform various zero-shot cross-lingual speech generation tasks, such as cross-lingual text-to-speech synthesis and speech-to-speech translation.
VALL-E X 是一个跨语言语音合成模型。它基于 VALL-E,能用一种语言的语音和目标语言的文本作为提示,生成目标语言的语音。
特点包括:
零样本跨语言语音合成:只需一个源语言语音提示,无需目标语言的声音样本。
保留说话人的声音、情绪和环境特征。
减少外语口音问题,可以通过设置语言ID来控制。
可用于文本转语音和语音翻译任务。
1. Introduction¶
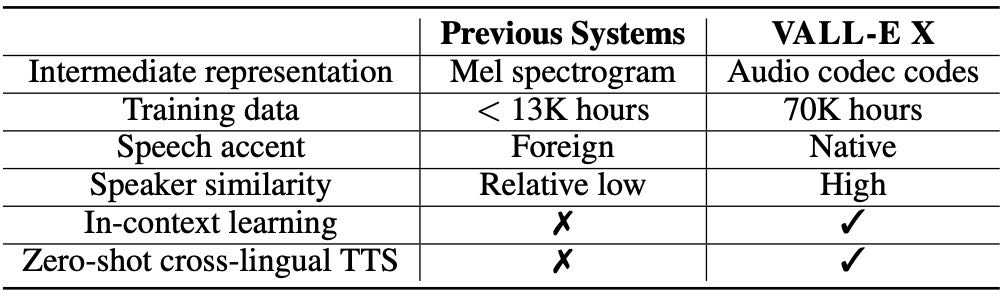
Table 1: A comparison between VALL-E X and previous cross-lingual TTS systems.
这段内容主要讲了一个名为 VALL-E X 的跨语言语音合成模型,它解决了以往跨语言 TTS(文本转语音)存在的一些问题。
🌍 问题背景¶
以往的 TTS 技术已经能合成出接近真人的语音,但只能支持特定语言和特定说话人。
跨语言 TTS 目标是:保留说话人的声音特征,让其说另一种语言。
但跨语言 TTS 的效果差,原因:
同一说话人的多语言数据难收集(数据稀缺)
模型能力不足,难以保留声音特征和情感
🧠 现有方法的不足¶
以前的方法通常增加专门模块来控制说话人和语言,但:
无法支持零样本(zero-shot)说话人
合成语音口音重,像“外国人说话”
说话人相似度低
🚀 VALL-E X 的创新点¶
使用一种神经编解码语言模型(neural codec LM)
支持零样本跨语言 TTS:只需一句原语音+目标语言文本
能有效保持:
说话人声音
情感
背景特征
显著减少“外国口音”
🔧 技术方法¶
收集大规模多语言语音和转写数据(英/中共 7 万小时)
文本转音素(G2P),语音转“声学 token”
联合训练一个多语言条件语言模型
使用音素 + 声学 token 预测目标语音
📊 实验效果¶
在多个评估指标上超越现有最强方法:
说话人相似度更高
外语口音更少,语音更自然
语音识别错误率(WER)和翻译得分(BLEU)都有提升
人类评测得分也更高(SMOS, MOS, CMOS)
🎧 应用场景¶
零样本 TTS:比如让不会说中文的美国人“用中文讲话”
零样本语音翻译(Speech-to-Speech Translation):直接将一个人的英语语音翻译成中文语音,并保留声音特征
3 Cross-Lingual Codec Language Model¶
VALL-E X 能让你用自己的声音,说出另一种语言。
3.1 Background¶
VALL-E X 是一个跨语言文本到语音(TTS)模型,基于之前的 VALL-E 模型。它的目标是:只用几秒的语音样本,就能生成带有“你声音”的外语语音。
核心思想:用“语音的词”来生成语音
传统TTS会先生成连续的梅尔谱图(mel-spectrogram),再转成音频。
但 VALL-E 和 VALL-E X 采用了**“语音的离散代码”**(由 EnCodec 提取的 acoustic tokens),将语音看作是一种可以建模的语言。
3.2 Model Framework¶
VALL-E X 有两个主要模块:
多语种自回归模型(Autoregressive LM):
用于生成 EnCodec 的第一层 acoustic tokens,它像写文章一样一个一个生成语音片段的“词”。
多语种非自回归模型(Non-Autoregressive LM):
并行生成 EnCodec 的其余7层 acoustic tokens。
它参考当前句子的音素(phoneme)和同一个说话人之前句子的 acoustic tokens,使得说话风格一致。
3.3 Multi-lingual Training¶
训练方式
使用两种语言的语音-文本对进行训练。
引入了语言ID(Language ID),帮助模型更好地区分语言风格(例如中文是声调语言,英文不是),提高跨语言生成的准确性和自然性。
3.4 Cross-Lingual Inference¶
输入目标语言的文本和源语言说话人的语音。
用源语言的声音特征引导生成目标语言的 acoustic tokens。
先用自回归模型生成第一层 acoustic tokens,再用非自回归模型补齐剩下7层。
最后通过 EnCodec 解码器合成语音,实现跨语言的声音克隆。
4. VALL-E X Application¶
VALL-E X 是一种强大的跨语言语音生成模型,可以在**无需训练的前提下(zero-shot)**完成以下任务:
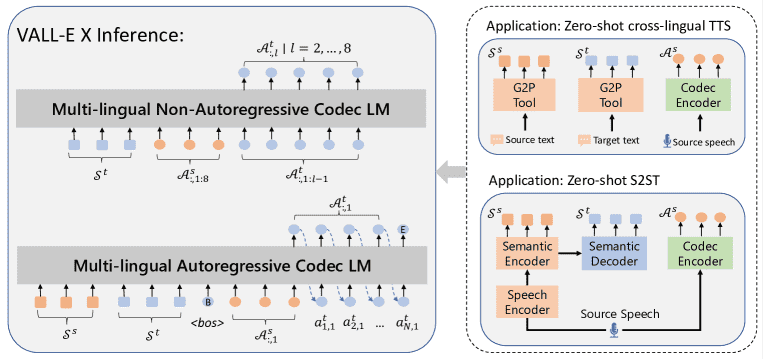
Figure 3:Inference illustration of the cross-lingual neural codec language model VALL-E X, with two-stage decoding strategies. VALL-E X can support zero-shot cross-lingual TTS and zero-shot speech-to-speech translation tasks.
1. 零样本跨语言语音合成(Zero-Shot Cross-Lingual TTS)¶
目标:用某人的语音风格,说出另一种语言的文字内容。
原理:利用编码器将源语音转成声学token、将文本转成音素,再交给VALL-E X生成目标语言的语音token,最后还原成语音。
特点:不需要专门训练特定语言的模型,直接就能合成。
2. 零样本语音翻译(Zero-Shot Speech-to-Speech Translation)¶
目标:输入一段源语言语音,输出另一种语言的翻译语音,保留原说话人声音特征。
流程:
用改进的SpeechUT模型把源语音识别为源音素和目标音素。
用 EnCodec 编码源语音生成声学token。
把源音素、目标音素、声学token输入VALL-E X,生成目标语音token,再解码输出语音。
3. 效果评估¶
评估指标包括:
说话人相似度(ASV)
语音识别错误率(ASR-WER)
翻译准确度(ASR-BLEU)
自然度(用NISQA模型 + 人工打分)
5. Experiments¶
评估新模型 VALL-E X 在两种任务中的零样本能力(无需再训练):
跨语言语音合成(TTS):
中文人声提示生成英文语音
英文人声提示生成中文语音
语音到语音翻译(S2ST):
中文 → 英文
英文 → 中文
5.1 Dataset¶
训练用数据:
中文 ASR:WenetSpeech(1万小时)
英文 ASR:LibriLight(6万小时,无标注)+ 利用 Kaldi 模型生成伪标注
翻译数据:
机器翻译(MT):多个开源数据集,约7300万对句子
语音翻译(ST):GigaST(英文→中文)+ 自制(中文→英文)
测试用数据:
EMIME 数据集(中英双语,由同一人录制)用于评估 TTS 和 S2ST
LibriSpeech 数据集用于英文语音
5.2 Experimental Setup¶
处理流程:
文本统一转为音素(IPA)
使用 EnCodec 神经音频编码器量化语音为离散 token
模型结构:
两个 Transformer 解码器组成的 codec 语言模型(分别处理自回归和非自回归)
S2ST 模型结构见附录
训练:
最大语音片段:20秒
使用32块V100 GPU训练80万步
每模块单独训练,部分优化策略做了加速处理
对比基线模型:
YourTTS:多说话人英文 TTS 系统(无法生成中文)
S2ST 基线:ASR → MT → TTS(级联方案)
5.3 Zero-Shot Cross-Lingual TTS Evaluation¶
自动评估指标:
ASV Score(说话人相似度):VALL-E X(0.36)优于 YourTTS(0.30)
ASR-WER(识别错误率):从8.53降到4.07
自然度评分:VALL-E X 更自然
人工评估指标:
SMOS(相似度):VALL-E X = 4.00,高于 YourTTS = 3.42
CMOS(相对质量):VALL-E X 相对提升 +0.24 分
5.4 Zero-Shot S2ST Evaluation¶
在中英双语数据集上,VALL-E X Trans 被用来测试“能否保留说话人声音、翻译是否准确、语音是否自然”,包括人工和自动评估:
🗣️ 说话人相似度(Speaker Similarity)¶
使用 ASV 分数衡量合成语音是否保留了原说话人的声音。
中→英方向:VALL-E X Trans 明显优于传统方法(Baseline),更能保留说话人特征。
英→中方向:生成语音和原语音的相似度还不够高,仍有提升空间。
即使用准确的翻译文本,提升也不大,说明声音保留与翻译质量无关。
🌐 翻译质量(Translation Quality)¶
用 BLEU 分数来评估翻译准确性。
中→英:VALL-E X Trans BLEU 分数(30.66)高于 Baseline(27.49),说明端到端方法更好。
用“真实目标文本”作为输入时 BLEU 分数接近 85,说明模型本身能力强。
🔉 语音自然度(Speech Naturalness)¶
用 NISQA 工具打分。
中→英方向:VALL-E X Trans 的语音比传统方法更自然(3.54 vs. 3.44)。
👂 人工评估(Human Evaluation)¶
对 56 个翻译样本进行主观评分(1-5 分):
SMOS 评估保留说话人声音的程度:VALL-E X 明显优于 Baseline。
MOS 评估语音质量:VALL-E X 略好。
5.5 Analysis¶
🏷️ 语言标签(Language ID)的影响¶
加入正确语言 ID 有助于提升翻译准确性(BLEU 分数)。
去掉或用错语言 ID 会使语音更像原说话人(ASV 分高),但翻译更差。
说明:语言 ID 是翻译准确的关键,但也会影响声音“迁移”。
🗣️ 控制外语口音¶
添加正确语言 ID 能有效减少外语口音问题。
评价分数显示:带语言 ID 的语音更像母语者(如英→中从 2.35 提升到 4.03)。
😢 保留情感(Voice Emotion Maintenance)¶
虽然没专门训练情感模型,但 VALL-E X 能在一定程度上保留原语音的情绪。
这归因于:
大量多语种数据中本身包含情感语音;
模型具备强大的上下文学习能力。
🔁 中英混合语音合成(Code-Switch Speech Synthesis)¶
即使只用单语数据训练,VALL-E X 也能生成流畅的中英混合语音。
展现出很强的上下文理解能力,能处理中英文混合句子。
6. Conclusion¶
我们提出了 VALL-E X,一种跨语言的语音生成模型。
它可以在生成另一种语言的语音时保留原说话人的声音特征,而且不需要同一说话人跨语言的配对数据。
通过在大规模多语言多说话人的语音和文本数据上训练,它具备很强的上下文学习能力,支持零样本的跨语言语音合成和语音翻译。
未来我们计划用更多数据和语言来提升这个方法。
A. Appendix¶
该模型包含三个主要部分:
语音编码器(θ_enc1)
语义编码器(θ_enc2)
语义解码器(θ_dec)
A.1.1 模型预训练¶
语音端预训练(Speech-side):
输入:语音波形 + 对应的音素序列(S^s)
目标:用语音编码器和语义编码器预测这些音素
损失函数:两个 log 概率的加和(从 speech encoder 和 semantic encoder 各预测一次)
文本端预训练(Text-side):
输入:双语音素序列(S^s 和 S^t)
目标:用语义编码器和解码器进行序列到序列的翻译建模
损失函数:自回归地预测目标语言的音素
总预训练目标:
总损失 = 语音损失 + 文本损失
A.1.2 模型架构¶
基于 SpeechUT 的 Base 架构
编码器和解码器都是 6 层 Transformer,带相对位置偏置
FFN 维度为 3072,注意力维度为 768
在语音编码器前加入了一个卷积下采样模块(7 层一维卷积),能将音频下采样 320 倍并转换为固定维度的嵌入
A.1.3 训练细节¶
预训练阶段(Pre-training):
使用 SpeechUT 的超参数设置
语音掩码概率:8%,掩码长度:10
批大小:每个 GPU 上语音数据为 140 万帧,音素为 3000 个
学习率最大为 5e-4,warm-up 步数为 32K
用 32 个 V100 GPU 训练 40 万步
微调阶段(Fine-tuning):
同时做 ASR(语音识别)和 ST(语音翻译)
ASR:通过 CTC 层从语义编码器输出预测音素(去重后)
ST:通过语义解码器预测翻译音素
CTC 损失权重设为 0.2
微调使用 32 个 GPU,每个 GPU 批量为 200 万帧(125 秒),训练 20 万步