2311.12983_GAIA: a benchmark for General AI Assistants¶
组织: 1FAIR(Meta), 2HuggingFace, 3AutoGPT, 4GenAI(Meta)
Code: https://huggingface.co/gaia-benchmark
引用: 175(2025-06-25)
Abstract¶
GAIA 是一个用于评估通用 AI 助手能力的新测试集。如果 AI 能很好地完成 GAIA 任务,将是 AI 研究的重要突破。
GAIA 的问题贴近现实,需要 AI 具备推理、多模态理解、网页浏览、工具使用等基础能力。
这些问题对人类来说很简单(人类得分92%),但即使是用上插件的 GPT-4 也只能得分15%,表现差距很大。
这与近年来大模型在法律、化学等专业任务上超过人类的趋势相反。
GAIA 的理念是:想要实现通用人工智能,AI 必须先在这些“对人类简单”的任务上表现得像普通人一样稳健。
目前 GAIA 提出了466个问题,公开了其中166个的答案,其余的用于榜单评测。
1.Introduction¶
✅ 背景与问题:¶
当前的大语言模型(LLMs)越来越强,甚至能在一些高难度的测试(如MMLU、GSM8k)中超过人类水平,但这些测试已经不够挑战性,而且容易被“数据污染”(即答案可能早就在训练数据中)。
✅ GAIA 的提出:¶
GAIA 是一个新提出的评测集,用来测试通用 AI 助手(General AI Assistants)。
它的特点是:
任务真实且复杂:涉及现实世界问题,比如要用工具(浏览器、代码等)、处理图像、推理多步。
题目简单明确但难以破解:每题只有一个正确答案,不能靠猜或查文本数据得出。
适合自动评价:因为答案是具体数字或事实,所以不需要人工评分。
人类容易,模型难:人类正确率达 92%,但 GPT-4 最高只有 30%,有些题目完全答不对。
设计灵活可拓展:便于未来继续加入多模态、工具使用、安全性等新挑战。
✅ GAIA 的意义:¶
如果某个 AI 系统能很好地完成 GAIA,说明它可能达到了“时间受限通用智能(t-AGI)”的水平。
GAIA 提供了一个可以公平、系统地评估下一代 AI 系统的基准。
3.GAIA¶
3.1 GAIA 简介¶
定义
GAIA 是一个用于评估通用 AI 助手能力的基准测试集,共有 466 个由人类设计的问题。
这些问题围绕真实世界任务,如日常事务、科学、通识知识等,形式简单(如回答一个数字或短语),但对 AI 来说具有挑战性。
问题可能附带图像、表格等文件。
设计原则:
真实且有挑战性:问题贴近生活,强调推理、跨模态理解和工具使用,挑战当前 AI 的基本能力。
可解释性强:问题简单,便于用户理解模型的推理过程。
防止“背答案”:答案不会出现在预训练数据中,AI 需真正推理或操作获取答案。
使用简单:只需用零样本(zero-shot)方式输入问题,回答清晰、标准化,便于自动评分。
3.2 Evaluation¶
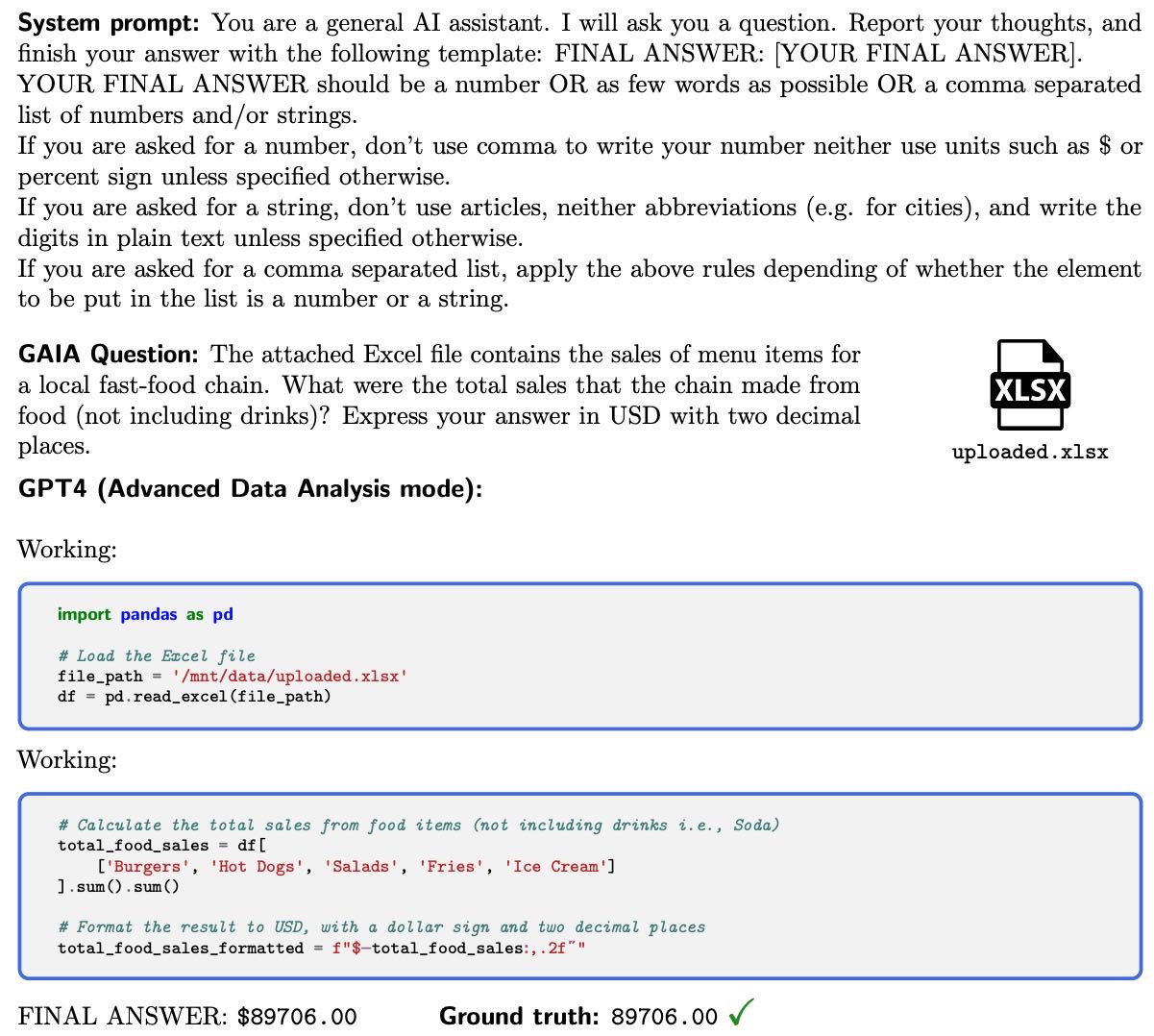
Figure 2 To answer GAIA, an AI assistant such as GPT4 (here equipped with a code interpreter) needs to complete a few steps, potentially using tools or reading files.
答案是唯一、明确的(比如一个字符串或数字),评分标准是“近似精确匹配”。
使用统一提示语告诉模型回答格式。
自动打分,准确、高效。
3.3 Composition of GAIA¶
能力覆盖广:涵盖推理、编程、网页浏览、多模态处理(PDF、图像、音频等)。
分三种难度:
Level 1:不需要工具或步骤少;
Level 2:步骤更多,需要结合多种工具;
Level 3:模拟一个几乎完美的 AI 助手,需要复杂推理和操作。
话题广泛:兼顾不同文化和需求(如帮助残障人士)。
3.4 Building and extending GAIA¶
问题由人工设计和标注,强调真实性和答案唯一性。
多数问题基于可信网页或提供完整资料。
每个问题由 3 位标注员独立验证,确保无歧义。
创建一个问题(含验证)大约需要 2 小时。
68% 的问题一次就通过,其余需修正或删除。
挑战:
来自网络的信息可能变化(如网页被更新),需指定网页版本。
尊重网站的 robots.txt 限制,不使用被禁止的内容。
4.LLMs results on GAIA¶
人类表现最好,在所有问题难度层级上都很强。
当前 LLM 表现较差,尤其是难度高的题。
GAIA 基准能有效区分模型能力,也留有提升空间。
GPT-4 插件版通过工具能改写问题、回退重试,解决复杂问题表现较好。
AutoGPT 自动用工具,效果反而更差,可能和参数设置有关,也比其他模型慢。
GPT-4 记忆能力强,即使不能浏览网页,也能回答需要组合信息的问题。
人类搜索网页可以回答简单问题,但效率低、遇到复杂问题会失败。
5.Discussion¶
1. 闭源模型的复现性问题¶
闭源AI(如通过API访问的模型)会不断更新,导致评估结果难以复现。
一些功能(如ChatGPT插件)经常变动,增加了不确定性。
静态评估标准可能过时,而GAIA只看最终答案且要求唯一正确,能减少这种随机性带来的影响。
2. 静态 vs 动态评估基准¶
GAIA采用高质量的开放性问题,相比像MMLU这种多选题更难但更精细。
静态题库会随着时间“腐烂”(例如信息消失或模型提前见过答案),所以GAIA需要不断维护、更新题目来保持有效性。
长远来看,持续更新比一次性构建更能体现模型的泛化和鲁棒性。
3. 朝向统一的生成模型评估方式¶
GAIA评估的是整个系统的输出(包括可能调用的图像识别、网页浏览等模块),不区分子模块的责任。
虽然现在很多模型通过组合多个工具完成任务,未来可能会集成成多模态大模型。
GAIA致力于评估整个AI系统,不拘泥于现有架构。
未来也可能用于评估图像生成任务,比如要求模型对图像做复杂修改,并准确理解修改结果。
4. 部分自动化 vs 完全自动化¶
有些任务只需人类辅助(部分自动化),有些要求机器完全独立完成(完全自动化)。
GAIA的任务要求完全自动化,没有容错空间。
这种能力将改变社会结构,但也带来技术集中化的风险——因此更应该推动开源来平衡技术收益分配。
6.Limitations¶
GAIA基准的局限性主要有三个方面:
缺少对“推理过程”的评估:
GAIA目前只看答案对不对,不评估模型是如何得出答案的。
因为正确答案可能有多种推理路径,很难设计简单而统一的评判方式。
未来可能加入人类或模型辅助的过程评估。
题目设计成本高:
为了确保题目明确无歧义,需要经过两轮人工审核,比一般的AI训练任务成本更高。
但这种人工审核是值得的,因为可以避免多次错误评估。
尽管如此,仍可能有些歧义,但只要人类能理解就足够,因为目标是让AI对齐人类意图。
语言和文化多样性不足:
GAIA目前只有标准英语的问题,而且很多依赖英文网页。
这限制了它在非英语环境下的代表性,未来希望通过社区或新版本来改进这个问题。
Appendix C Extended description of GAIA¶
Description of capabilities.¶
GAIA设计涵盖五种能力:
网页浏览
多模态处理(图像/语音/视频等)
代码执行
多种文件格式处理(PDF、Excel等)
无需外部工具的常规问题
Appendix D Extended description of our question design framework¶
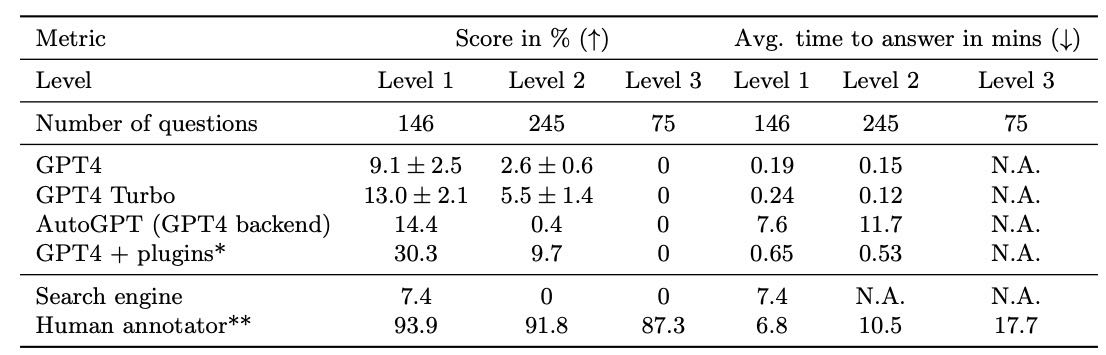
Table 4 Score and average time to answer for various baselines on GAIA in %.

Figure 9 Proper web search is very effective to answer GAIA questions. The reasoning trace was obtained with the current GPT4 web browsing version.