2504.03137_LightPROF: A Lightweight Reasoning Framework for Large Language Model on Knowledge Graph¶
组织: 北邮,杭州电子,新加波管理大学等
LightPROF: Lightweight and efficient Prompt-learning ReasOning Framework
Abstract¶
- 问题背景
大语言模型(LLMs) 很擅长理解文本、进行零样本推理。
但问题是:它们的知识更新有滞后,可能导致推理错误,甚至输出有害信息。
解决思路:知识图谱(KGs)能提供结构化、可靠的背景信息,帮助LLMs更好地推理。
- 现有方法的局限
- 当前的 KG+LLM 方法,通常只把知识图谱信息转换为纯文本再给LLM使用。
例如,把一个图谱表示的关系转成“X is the capital of Y”这类句子。
- 问题:
忽视了KG原本的结构信息(图结构、路径、实体连接等)。
多数方法还依赖闭源模型或超大型开源模型,资源消耗高,训练困难。
- LightPROF 的贡献
- LightPROF 是一个新的轻量高效的提示学习推理框架,设计目标是:
让中小型LLM也能处理复杂推理任务;
节省计算资源(参数高效);
更好地利用KG的结构信息。
- LightPROF 的工作流程:“Retrieve-Embed-Reason”
- Retrieve(检索):
从知识图谱中精确稳定地检索出与当前问题相关的“推理子图”(reasoning graph)
- Embed(编码):
使用一个Transformer-based Knowledge Adapter
把KG中提取的结构信息 + 事实信息整合编码;
并将其映射到LLM的token embedding空间;
结果是一个对LLM友好的提示(prompt)。
- Reason(推理):
将这个生成的结构化 prompt 输入到LLM中,完成最终的推理和回答。
- 优势与实验结果
LightPROF 只需训练知识适配器部分,不需要微调整个LLM,因此参数高效。
还能兼容各种开源LLM,比如 LLaMA、Mistral、ChatGLM等。
- 总结一下
- LightPROF 是一个为知识图谱问答任务设计的轻量级框架,它:
利用“检索—结构化编码—推理”的流程;
保留了KG的结构优势;
不依赖大模型或闭源模型;
在低资源条件下也能高效完成复杂推理任务。
Introduction¶
- 🔍 关键词
zero-shot,知识密集任务,知识更新困难
Knowledge Graphs, KGQA, 可更新、结构化的语义支持
结构损失、多次调用LLM、大上下文开销
- 现有LLM+KG方法的现状
从KG中检索相关信息 → 把它转为文本 → 塞进LLM的输入中。
利用LLM的语言推理能力来回答问题。
- 两个核心问题
- 📌 问题1:结构信息丢失
把KG转成文本时,丢掉了图结构(谁连着谁、层级、路径)。
比如把图转成“列表”或“句子”,复杂关系就很难表达清楚。
- 📌 问题2:效率低、资源消耗大
有些方法是一步步检索图谱信息(比如从一个实体逐层找关系):
LLM调用次数多;
推理效率差;
输入文本太长,导致需要更大的context window,也增加出错概率。
- LightPROF 方法简介
- 提出一个新框架:LightPROF
全称:Lightweight and efficient Prompt-learning ReasOning Framework
设计目标:让小规模LLM也能做高质量的KGQA推理
- 采用三步走的架构:Retrieve - Embed - Reason
- 1️⃣ Retrieval 模块
以“关系”为单位来检索KG中相关子图(reasoning graph);
基于问题语义限制检索范围 → 提高准确性 & 降低LLM调用频率。
- 2️⃣ Embedding 模块
使用Transformer-based Knowledge Adapter:
把图谱中的结构 + 文本信息编码成向量;
映射到LLM的embedding空间,生成“LLM友好的表示”;
压缩输入,减少上下文长度,提升效率与准确性。
- 3️⃣ Reasoning 模块
把结构化的向量嵌入与自然语言 prompt 结合;
交给LLM完成推理 → 输出最终答案。
- 贡献总结
📌 首次融合KG的文本和结构信息进入LLM的prompt中;
📌 提出了一个小模型也能用、效率高、只需微调Knowledge Adapter的框架;
- 📌 实验结果表明:
在两个KGQA数据集上,小模型 + LightPROF 的效果超过了大模型(如 LLaMa-2-70B、ChatGPT);
在输入token数量和推理时间上,也显著更优。
- 🎯 总结一句话:
> 传统的KG+LLM方法丢失结构、成本高,LightPROF 用三步框架巧妙保留图结构、节省计算资源,让小模型也能高效做知识推理。
Preliminaries¶
本章主要给出后续方法中涉及的基础概念定义,主要围绕知识图谱(KG)中的核心术语:三元组、锚点实体、关系链、推理路径等。
1. Knowledge Graph (KG)¶
- 定义:
> KG 是由三元组 (h, r, t) 组成的数据结构,表示实体之间的关系。
形式化定义:
- 其中:
h :头实体(head entity)
t :尾实体(tail entity)
r :关系(relation)
\(\mathcal{E}\) :实体集合(entities)
\(\mathcal{R}\) :关系集合(relations)
例子:
("Paris", "isCapitalOf", "France") 属于 KG 中的一个三元组。
2. Anchor Entities¶
- 定义:
锚点实体 \($ B = \{ b_1, b_2, \ldots, b_K \} $\) 是问题中涉及的实体。
也就是说,这些实体是问题中的“关键词”,我们会从它们出发在知识图谱中进行推理。
例子:
> 问题:“爱因斯坦在哪所大学工作?”
> → 锚点实体可能是:`"爱因斯坦"`
3. Relation Link¶
- 定义:
关系链 \($ l = \{ r_1, r_2, \ldots, r_J \} $\) 是从某个锚点实体开始,进行 J 次跳转时所经过的一串关系。
也就是一条“可能的路径结构”,但还没有填入具体的实体。
例子:
> `["attended", "locatedIn"]` 表示:
> - 实体先通过“attended”跳转到另一实体(比如学校),
> - 然后通过“locatedIn”跳转到该学校的位置。
4. Reasoning Path¶
- 定义:
> 推理路径是具体实体填入后的关系链,表示一条从锚点出发,按顺序进行多跳推理的路径。
- 其中:
\(b_1\) :起点锚点实体
\(r_m\) :路径中第 m 条关系
\(e_m\) :第 m 跳之后到达的实体
例子:
从 “爱因斯坦” 出发
→ 通过 "workedAt" 关系到 “普林斯顿大学”
→ 再通过 "locatedIn" 到 “美国新泽西州”
# 就构成了一个完整推理路径:
["爱因斯坦", "workedAt", "普林斯顿大学", "locatedIn", "新泽西州"]
Methodology¶
LightPROF 是一个为“小模型”(如小规模的LLMs)设计的轻量级推理框架,用于处理复杂的知识图谱推理(KG Reasoning)问题。它的目标是:用尽可能小的模型实现尽可能强的复杂推理能力。
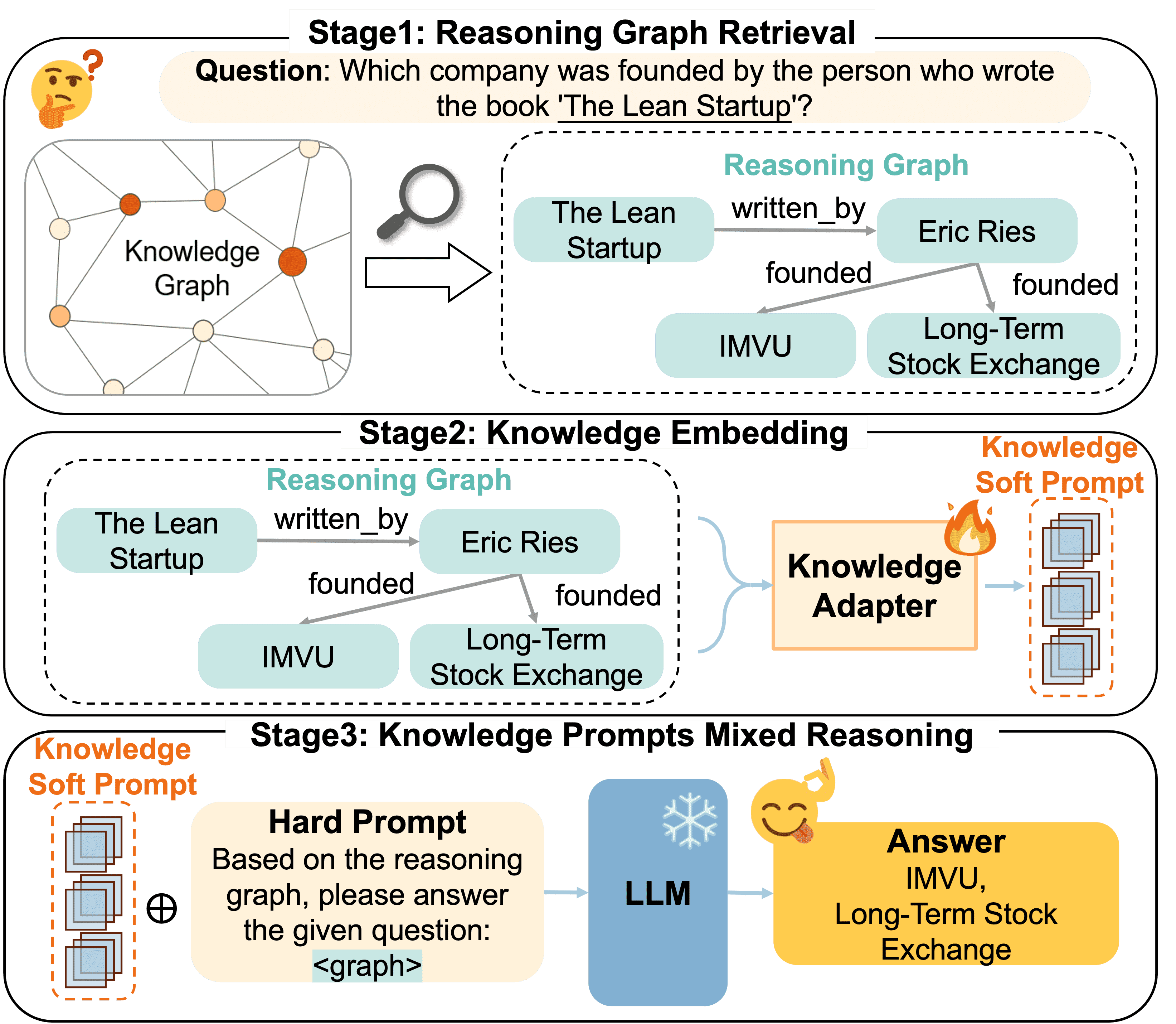
Figure 1:The architecture of our proposed Retrieve-Embed-Reason framework for knowledge graph question answer.¶
Stage1: Reasoning Graph Retrieval¶
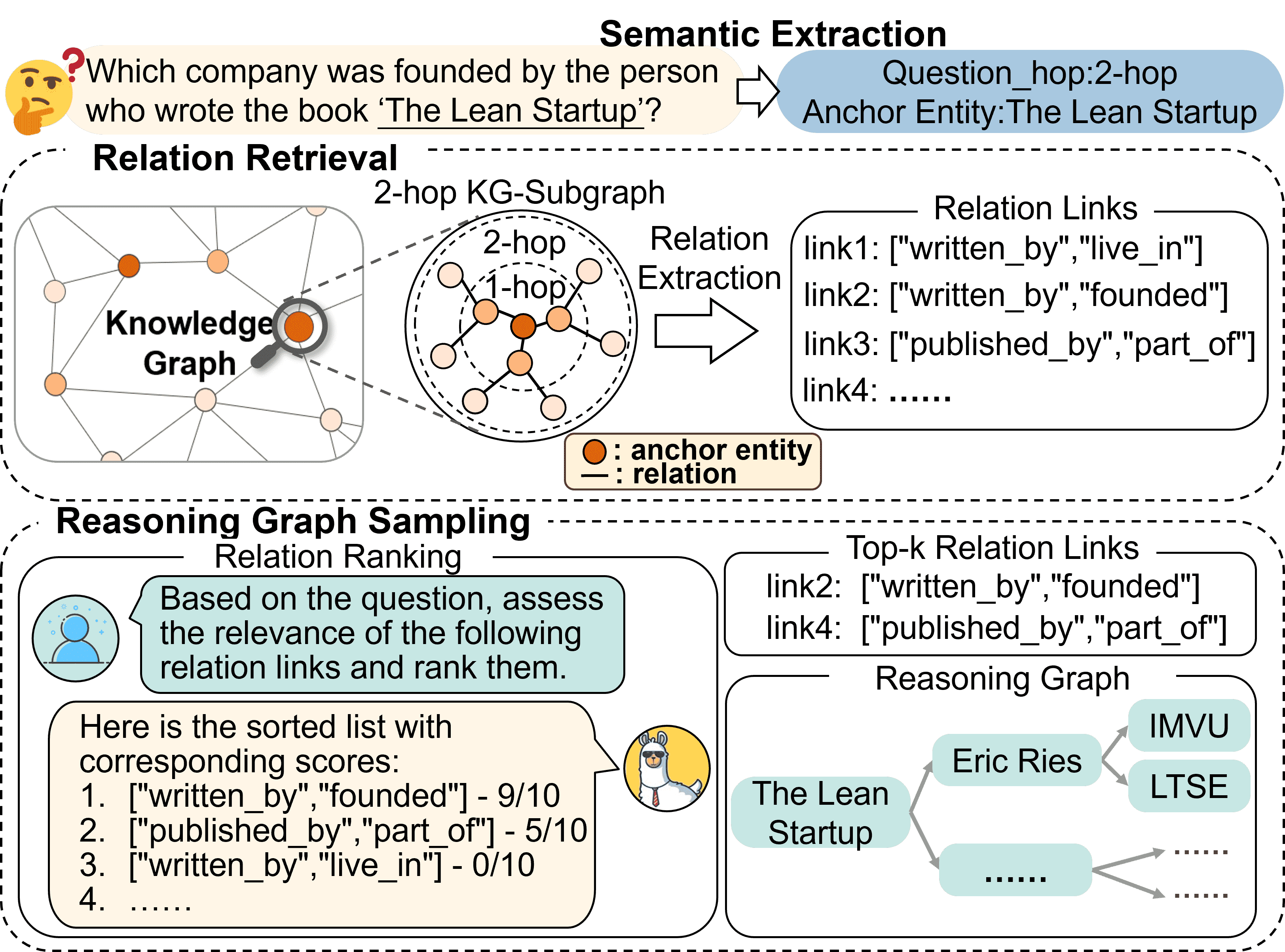
Figure 2:Three Steps Retrieval Module, including: semantic extraction, relation retrieval, and reasoning graph sampling.¶
目的:如何从庞大的知识图谱中,精准、高效、稳定地找到和问题相关的知识片段
1. 语义提取(Semantic Extraction)¶
- 目标:从自然语言问题中提取出关键语义信息:
跳数
h_q:回答问题需要跨几跳(multi-hop)?锚点实体
B:问题提到的关键实体(比如“奥巴马”)。
做法:微调一个PLM(如BERT),让它根据问题向量预测跳数。
- 形式化:
V_q = PLM(q):将问题变成向量;h_q = argmax P(h|V_q):分类预测最合适的跳数。
➡️ 这样我们就限定了搜索范围,不需要在整个图谱中乱搜。
2. 关系检索(Relation Retrieval)¶
目标:找到与锚点实体相关、且在 h_q 跳范围内的关系链接(KG中的边)。
- 做法:
先选定锚点实体;
然后在KG中做受限的广度优先搜索(BFS),只看跳数在 h_q 范围内的边;
得到一堆可能有用的关系路径。
➡️ 这一步利用KG中关系的稳定性和表达力,过滤无用信息。
3. 推理图采样(Reasoning Graph Sampling)¶
目标:从上一步得到的大量关系链接中,选出最有可能有用的。
- 做法:
把这些关系链接喂给LLM;
让LLM根据语义相关性打分;
挑出前k个最相关的;
在KG中,围绕这些关系路径采样,得到多个推理路径;
拼成一个“小而精”的推理子图 G_R。
Stage2: Knowledge Embedding¶
本节主要解决的是如何将结构化知识图谱(KG)中的图结构信息与文本信息融合,以便让大语言模型(LLMs)更有效地进行推理。
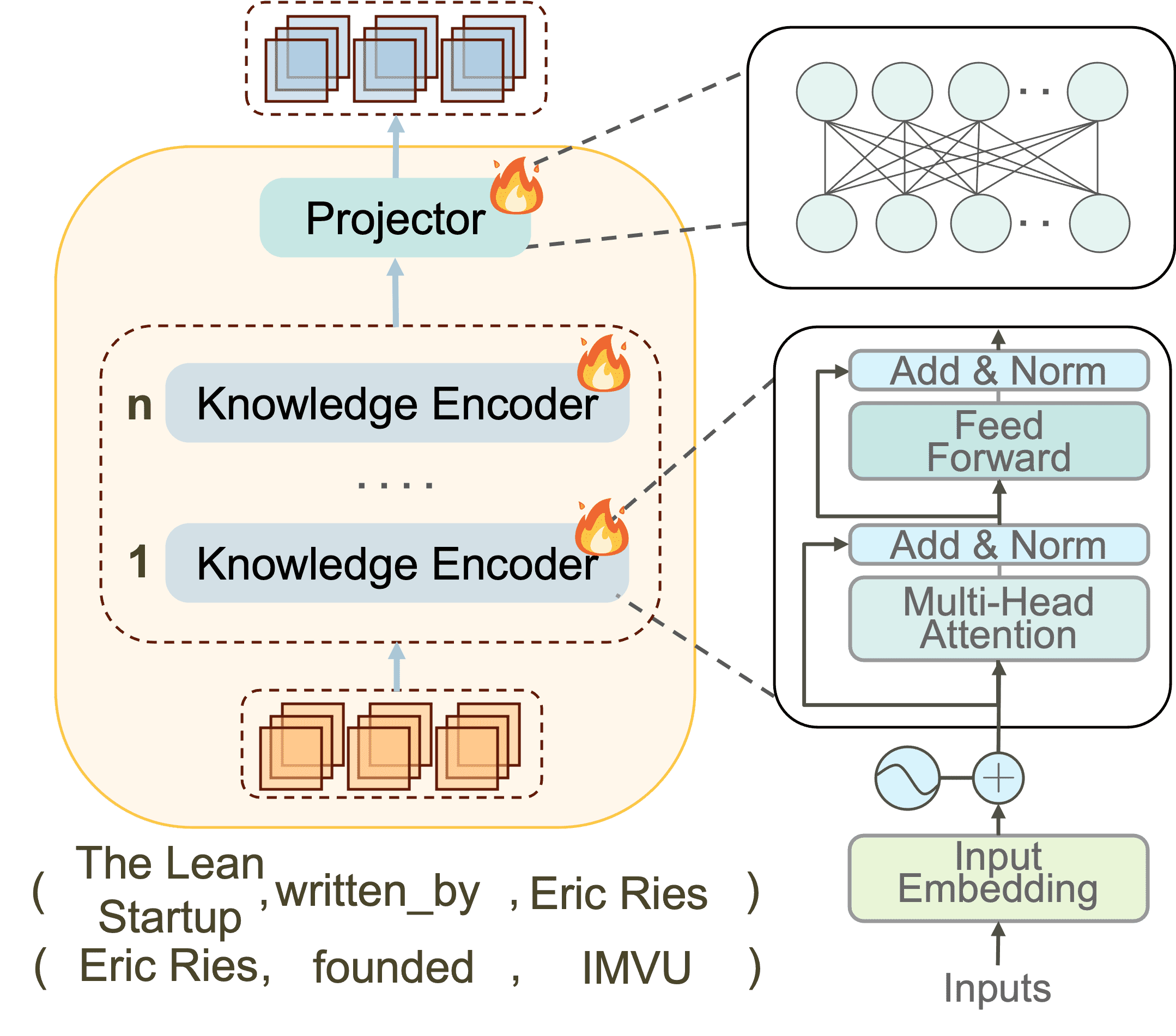
Figure 3:Illustration of the Knowledge Adapter and the schematic representation of its crucial components.¶
- 💡 背景问题
KG中包含了大量复杂的结构信息(如子图结构、关系模式、实体间的相对关系等)。
这些结构信息对于 LLM 理解知识图谱非常关键,但如果仅用自然语言表达结构信息,常常会冗余、混乱、不清晰,从而影响 LLM 推理效果。
- ✅ 解决方案:精简且高效的知识适配器(Knowledge Adapter):
目标:将“推理图”中的结构和文本信息紧密融合,让 LLM 能更好理解。
- 实现:如下图(Figure 3)所示,包括:
结构信息编码
文本信息融合
全局推理路径表示整合
1. 定义推理图(Reasoning Graph)¶
假设一个推理图 \($ G_R = \{ R_n \}_{n=1}^{N} $\) ,其中包含 N 条推理路径(即多跳关系链),每条路径 R_n 可拆解成若干个三元组集合:
- 说明
\($ h_i^n, r_i^n, t_i^n $\) :表示第 i 个三元组中的头实体、关系和尾实体
\($ h_q $\) :该路径中三元组数量,也对应 reasoning hops(推理跳数)
2. 获取三元组的嵌入¶
- 使用 BERT 类的模型进行编码:
每个关系嵌入: \(\mathbf{e}_i^r = \text{Embed}(r_i^n)\)
每个实体嵌入(同理): \(\mathbf{e}_i^h, \mathbf{e}_i^t\)
3. 结构信息编码¶
- 局部结构信息:
\(\mathbf{s}_i = \text{StructEmb}(\mathbf{e}_i^h, \mathbf{e}_i^r, \mathbf{e}_i^t)\)
- 全局结构信息(整条路径):把所有 \(\mathbf{s}_i\) 通过 Linear 层聚合成:
\(\mathbf{z}^s = \text{Linear}(\mathbf{s}_1, \mathbf{s}_2, ..., \mathbf{s}_{h_q})\)
4. 文本信息融合(Fusion)¶
- 将整条路径中所有头实体、关系、尾实体的嵌入分别融合:
头实体: \(\mathbf{z}^{t_h} = \text{Fusion}(\mathbf{e}_1^h, ..., \mathbf{e}_{h_q}^h)\)
关系: \(\mathbf{z}^{t_r} = \text{Fusion}(\mathbf{e}_1^r, ..., \mathbf{e}_{h_q}^r)\)
尾实体: \(\mathbf{z}^{t_t} = \text{Fusion}(\mathbf{e}_1^t, ..., \mathbf{e}_{h_q}^t)\)
- 然后将这三部分拼接形成完整文本信息表示:
\(\mathbf{z}^t = f_c(\mathbf{z}^{t_h}, \mathbf{z}^{t_r}, \mathbf{z}^{t_t})\)
⚠️ 注意:这里的 \(f_c\) 采用的是简单拼接操作(concat),而不是复杂神经网络,主要是为了保留语义完整性并降低训练难度。
—
5. 最终融合¶
- 最终,使用 KnowledgeEncoder 将上面两部分结合:
\(\text{Fused Representation} = \text{KnowledgeEncoder}(\mathbf{z}^t, \mathbf{z}^s)\)
得到一条推理路径的融合表示,可以输入给下游推理模块(比如 LLM)。
小结¶
LightPROF 利用一个轻量级的「知识适配器」,将结构化三元组的图结构信息(结构嵌入)和文本语义信息(融合嵌入)结合起来,从而更有效地支持 LLM 在多跳推理任务中使用知识图谱。
Stage3: Knowledge Prompts Mixed Reasoning¶
硬提示(hard prompts):是设计好的自然语言模板,用来组织问题,比如:“请基于以下图谱回答这个问题……”。
软提示(soft prompts):是一种可学习的向量序列,表示“推理图”(reasoning graph),用于注入外部知识。
模型在训练时的优化目标
公式如下:
- 解释如下:
𝒜:模型需要生成的答案序列(如回答)。
𝒟:训练数据集。
\(a_t\):答案序列中的第 t 个 token。
\(a_{1:t-1}\):前面已经生成的 token 序列(用于预测下一个 token)。
\(p_h\):硬提示(hard prompt),即结构化的语言问题模板。
\(p_s\):软提示(soft prompt),即推理图向量。
\(p_p= (ph, ps)\) :完整的输入序列。
- ✳️ 那公式里说的“训练目标”到底优化什么
目标:让模型在给定 hard prompt $ p_h $ 和 soft prompt $ p_s $ 的前提下,最大概率地生成正确答案 $ mathcal{A} $。
训练的对象:其实是 soft prompt $ p_s $ 的表示(也就是那组插入的向量),而不是模型参数。
优化方式:计算输出 token 序列的 log-likelihood(对数似然),使用梯度更新 soft prompt 的向量,使得模型输出更接近正确答案。
Experiments¶
- 🌟 总体目标(通过以下三个关键问题来评估 LightPROF):
Q1: LightPROF 能在 KGQA 任务中显著提升大语言模型的表现吗?
Q2: LightPROF 是否能无缝集成到不同的大模型中?
Q3: 使用小模型时,LightPROF 是否能保持输入高效、输出稳定?
- 📚 数据集(Datasets)
- WebQSP:
4737 个问题,平均需要 2-hop 推理。
每个问题都包括实体、推理链和 SPARQL 查询。
- CWQ:
从 WebQSP 派生,包含 34,689 个问题,支持更复杂(最多 4-hop)推理。
自动生成 SPARQL 查询和自然语言问题,更加多样。
- 🧪 实验配置(Implementation)
用了两个小模型版本:LLaMa-7B-chat 和 LLaMa-8B-Instruct。
Optimizer:使用了一个 epoch 的训练,batch size=4,初始学习率为 2e-3,采用 cosine annealing 调度。
Knowledge Encoder 使用 BERT + MLP 映射知识向量到 LLM 输入维度。
- ✅ 总结-LightPROF 的优势在于:
结构理解强: 能有效处理多跳复杂推理问题;
模型兼容好: 各类 LLM 可插即用,且提升明显;
资源效率高: 输入更紧凑,运行更高效;
即能小模型也能超大模型: 使用优化后的小模型超过了很多大模型。
Conclusion¶
本文提出了 LightPROF 框架,它可以精准检索并高效编码知识图谱(KG),以增强大语言模型(LLM)的推理能力。
为了有效地缩小知识检索范围,LightPROF 以“稳定关系”为单位,逐步采样知识图谱。
为了让参数较少的 LLM 也能进行高效推理,我们设计了一个精巧的 知识适配器(Knowledge Adapter),它能有效解析图结构、进行细粒度信息整合,从而将原始推理图压缩成更少的 token,再通过 投影器(Projector) 将其全面对齐到 LLM 的输入空间中。
实验结果表明,LightPROF 的表现优于其他基线方法,尤其是在与大规模语言模型结合时效果更佳。
- 关键点:
“知识适配器(Knowledge Adapter)”做结构解析+信息融合;
“投影器(Projector)”负责把融合后的图数据投影到 LLM 可以理解的向量空间;
整体目的:压缩结构化知识 → 少量 token 表达丰富图结构 → 更适配 LLM 输入格式。
- Future Work(未来工作)
设计泛化性更强、兼容性更高的知识图谱编码器,使其能在无需重新训练的情况下应用于全新的 KG 数据。
开发一个统一的跨模态编码器,可以对多模态知识图谱进行编码(例如图像、文本、结构同时存在的 KG)。
🧠 总结一句话:LightPROF 用一种轻量、结构化、可插拔的方式,让大模型能真正理解和用好知识图谱,不仅效果好,还节省计算资源。未来将向通用性和多模态方向继续推进。