2411.15858_SVTRv2: CTC Beats Encoder-Decoder Models in Scene Text Recognition¶
GitHub: https://github.com/Topdu/OpenOCR
组织: 复旦大学,中科大,北交大
定义¶
STR: Scene Text Recognition(场景文本识别)
CTC: Connectionist Temporal Classification(连接时序分类)
MSR: Multi-Size Resizing(多尺寸重采样策略)
FRM: Feature Rearrangement Module(特征重排模块)
SGM: Semantic Guidance Module(语义引导模块)
EDTR: Encoder-Decoder-based Text Recognition(基于编码器-解码器架构的场景文本识别方法)
Abstract¶
介绍了一种新型的场景文本识别(Scene Text Recognition, STR)方法 —— SVTRv2,它基于连接时序分类(CTC,Connectionist Temporal Classification),并在准确率和推理速度方面都优于主流的**编码器-解码器结构(EDTR)**方法
原始问题与背景:
CTC-based方法(如SVTR):结构简单,只包含视觉模型和一个CTC对齐的线性分类器,因此推理速度快。
缺点:在复杂或具有挑战性的场景中,准确率通常低于**基于Encoder-Decoder结构(EDTR)**的方法,比如图像中的弯曲文字、多语种、长文本等情况。
SVTRv2(一种升级的CTC模型) 的贡献与创新点:
同时提升了准确率和推理速度,超过了当前最强的EDTR方法;
引入了两个关键模块以增强对复杂文本的处理能力
主要技术细节:
MSR:Multi-Size Resizing 多尺寸重采样策略
作用:自适应地调整文本图像尺寸,确保其在输入模型时仍然易于识别和阅读;
目的:增强模型对不同字体、尺寸、形状文本的适应性。
FRM:Feature Rearrangement Module 特征重排模块
作用:重排视觉特征,使其更符合CTC对齐的要求;
目的:解决CTC结构在字符对齐上的困难(alignment puzzle),提升识别精度。
SGM:Semantic Guidance Module 语义引导模块
作用:将语言上下文信息引入视觉模型中,提升语言理解能力;
特点:只在训练阶段使用,推理阶段不引入额外开销;
优点:既能提升准确率,又保持推理高效。
总结:SVTRv2 实现了CTC模型的性能飞跃,通过:
输入预处理(MSR)+特征优化(FRM)+语言信息融合(SGM);
在不增加推理成本的前提下,提高了对复杂文本的识别能力。
1. Introduction¶
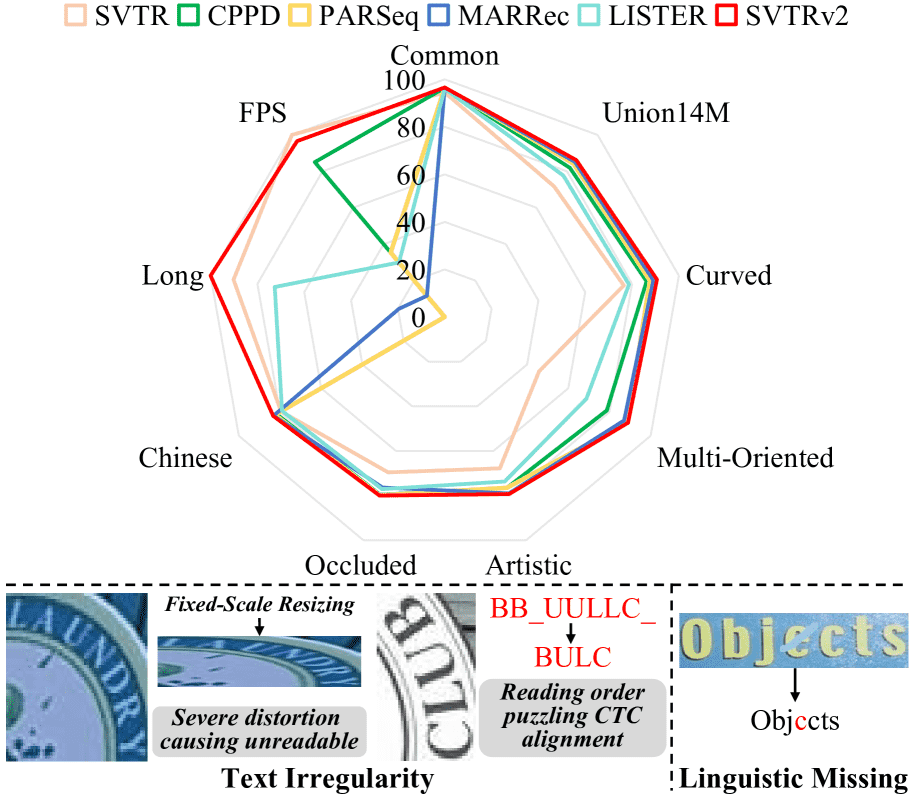
Figure 1:Top: comparison with previous methods best in a single scenario, where long text recognition accuracy (Long) and FPS are normalized. Our SVTRv2 achieves the new state of the arts in every scenario except for FPS. Nevertheless, SVTRv2 is still the fastest compared to all the EDTRs. Bottom: challenges caused by text irregularity and linguistic missing.
STR任务简介及挑战
任务目标:从自然图像中提取文本,区别于扫描文档(结构规整),自然场景下的文字更复杂。
挑战:背景杂乱、文字变形、布局不规则、艺术字体等。
主流方法分类:
CTC-based(连接时序分类)方法:结构简单、推理快。
EDTRs(Encoder-Decoder Transformer based)方法:精度更高,尤其适合复杂场景。
CTC方法的优劣
优点:简单高效,适合工业应用如 OCR。
缺点:
不能很好处理不规则文字(如旋转、扭曲等)。
缺乏对上下文语义的建模。
因此,引入了更复杂的 注意力机制的解码器(EDTR)。
EDTR的优势与问题
优势:能融合多模态信息(视觉、语言、位置信息),因此在中英文基准测试上优于CTC模型。
缺点:
推理速度慢,结构复杂。
对长文本识别不够好(如 LISTER 的效果仍不如 CTC 的 SVTR)。
CTC 精度差的原因
不适应不规则文字排列(CTC 假设从左到右顺序)。
缺乏语言建模能力(无法理解上下文)。
尽管一些工作尝试通过校正、2D CTC 或掩码图像建模等手段改进,但与 EDTR 仍有明显差距。
本文目标——提升 CTC 的识别能力(提出 SVTRv2)
针对问题1:处理不规则文本
提出 MSR(多尺寸缩放):避免固定缩放带来的文字变形。
提出 FRM(特征重排模块):重排二维特征,使其更符合真实阅读顺序,提升 CTC 对非水平文本的处理能力。
针对问题2:加入语言上下文
提出 SGM(语义引导模块):在训练时引导模型使用上下文识别当前字符,提升语言建模能力。
推理阶段不引入额外开销。
数据集问题及改进
近年来研究发现,真实世界大规模数据集 对性能提升至关重要。
但当前很多 STR 模型还是基于合成数据训练,导致泛化性能差。
Union14M-L 数据集中存在数据泄露问题,结果需要更新。
作者构建了 U14M-Filter:更干净、真实的新版本训练数据集。
3. Methods¶
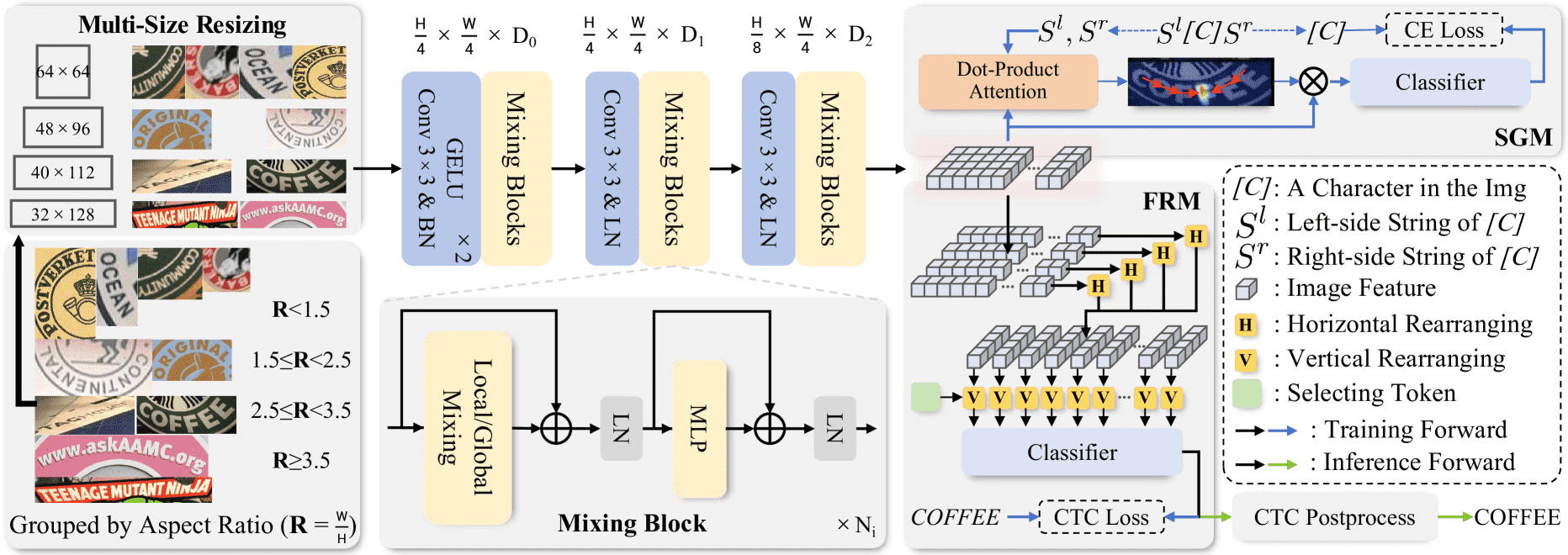
Figure 2:An illustrative overview of SVTRv2. The text is first resized according to multi-size resizing (MSR), then experiences feature extraction. During training both the semantic guidance module (SGM) and feature rearrangement module (FRM) are employed, which are responsible for linguistic context modeling and CTC-oriented feature rearrangement, respectively. Only FRM is retained during inference.
上图概括了整个流程,具体如下
输入的一张文本图像首先通过 MSR(多尺度缩放)策略 调整为合适的宽高比例(aspect ratio),形成输入张量 \(X ∈ ℝ^{3×H×W}\) ,即高为 H,宽为 W,3个通道(RGB图像)。
图像输入经过 三个特征提取阶段,得到视觉特征 \(F ∈ ℝ^(H/8 × W/4 × D₂)\) ,也就是:
高被压缩为 H/8
宽压缩为 W/4
通道数为 D₂
这种降采样方式常用于视觉模型中,便于提取多尺度特征。
SGM(Semantic Guidance Module):用于训练阶段,引导模型学习语言上下文信息(建模语义关联)。
FRM(Feature Rearrangement Module):将视觉特征
F重排列为字符序列 \(F̃ ∈ ℝ^(W/4 × D₂)\) ,即以字符阅读顺序排列,方便后续识别。
注意:推理时不使用 SGM,减少计算,提高速度。
┌───────────────┐
Text Image ────▶│ Multi-Scale │───▶ Resized X ∈ ℝ³×H×W
│ Resizing (MSR)│
└───────────────┘
│
▼
┌───────────────────────┐
│ 3-Stage Feature │
│ Extraction (Mixing │
│ Blocks: Local + MHSA)│
└───────────────────────┘
│
▼
┌────────────────────────────┐
│ Feature F ∈ ℝ^(H/8×W/4×D₂) │
└────────────────────────────┘
│ │
┌─────▼────┐ ┌─────▼─────┐
│ SGM │ │ FRM │
└──────────┘ └───────────┘
│ │
(only used in training) ▼
F̃ ∈ ℝ^(W/4 × D₂) → aligned with text reading order
3.1 Multi-Scale Resizing¶
传统方法会直接将所有输入图像拉伸成一个固定尺寸(如 32×128),这可能会严重扭曲文字形状,影响特征提取质量。
SVTRv2 的改进做法是:
根据图像的 宽高比 R = W / H,将图像自适应地缩放成更合适的尺寸。分成四个区间:
宽高比 R 范围 |
采用的尺寸 |
|---|---|
R < 1.5 |
64 × 64 |
1.5 ≤ R < 2.5 |
48 × 96 |
2.5 ≤ R < 3.5 |
40 × 112 |
R ≥ 3.5 |
32 × ⌊R⌋×32(如 R=4,则是 32×128) |
优点: - 更好保留文字结构; - 避免人为变形带来的识别误差; - 提高视觉特征的可辨别性。
3.2 Visual Feature Extraction¶
这个模块源自前作 SVTR,通过三阶段结构逐步提取特征。每个阶段包含若干个 Mixing Block(混合模块),分为两类:
🟩 Local Mixing(局部混合)
使用 两个连续的 grouped convolution(分组卷积)
用于提取文字的 局部结构特征,如边缘、笔画、纹理等
有利于捕捉字符本身的信息
🌍 Global Mixing(全局混合)
使用 MHSA(Multi-Head Self-Attention)多头自注意力机制
建模整个图像范围内的上下文,捕捉字符之间的关系
有利于理解整段文本的布局与语义
🎛 参数设置
分组卷积的组数,MHSA的 head 数,设为
Dᵢ / 32,也就是说,越深通道越宽,全局建模能力也更强。调节每一阶段的模块数
Nᵢ和维度Dᵢ可以构造三种版本:Tiny(轻量级)
Small(中等)
Base(基础版)
3.3 Feature Rearranging Module¶
旨在解决场景文字识别中由于文字旋转、弯曲导致的 CTC(Connectionist Temporal Classification)对齐难题。
模块目标
问题背景:
在使用CTC进行文本识别时,模型需要将图像特征序列与文字的阅读顺序对齐。
如果图像中的文字有旋转或弯曲,普通的从左到右提取特征的方式就不能很好地对齐阅读顺序,导致识别效果下降。
解决方法(FRM):
FRM的核心思路是:重新排列2D特征图中的位置,使得重新排列后的特征序列能更好地与文字的实际阅读顺序对齐
输入输出特征
输入特征图 \( \mathbf{F} \in \mathbb{R}^{(H/8 \times W/4) \times D_2} \):大小为 \( H/8 \times W/4 \),每个位置有 \( D_2 \) 维特征。
输出序列 \( \tilde{\mathbf{F}} \in \mathbb{R}^{W/4 \times D_2} \):长度为 \( W/4 \) 的特征序列(与阅读顺序对齐)。
这个过程本质上是从二维特征图中提取和重排特征向量 \( \mathbf{F}_{i,j} \in \mathbb{R}^{1 \times D_2} \),重新排列成一个有顺序的一维序列 \( \tilde{\mathbf{F}}_m \)。
重排的数学实现
用一个矩阵 \( \mathbf{M} \in \mathbb{R}^{W/4 \times (H/8 \times W/4)} \) 来表示从二维特征图中重新排列成一维序列的过程。
- \[ \tilde{\mathbf{F}} = \mathbf{M} \times \mathbf{F} \]
分解为两步:横向 + 纵向重排
考虑到文本旋转、曲线的偏移可以被分解为横向和纵向两个方向的变化,因此:
横向重排(Horizontal Rearrangement):
逐行地对特征做重排。
对每一行 \( \mathbf{F}_i \in \mathbb{R}^{W/4 \times D_2} \),学习一个重排矩阵: $\( \mathbf{M}_i^h \in \mathbb{R}^{W/4 \times W/4} \)\( 每个元素 \) \mathbf{M}_{i,j,m}^h \( 表示第 \) j \( 个位置的特征应该对应原始的第 \) m $ 个位置的概率。
计算方式:
类似自注意力机制,公式如下:$\( \mathbf{M}_i^h = \text{Softmax}\left(\mathbf{F}_i W_i^q (\mathbf{F}_i W_i^k)^T\right) \)$
其中 \( W_i^q, W_i^k \in \mathbb{R}^{D_2 \times D_2} \) 是学习到的权重。
应用重排并增强特征:
加权重排后加入原始特征:$\( \mathbf{F}_i^{h'} = \text{LN}(\mathbf{M}_i^h \cdot \mathbf{F}_i W_i^v + \mathbf{F}_i) \)$
再通过 MLP(多层感知机)和残差连接得到最终的横向特征:$\( \mathbf{F}_i^h = \text{LN}(\text{MLP}(\mathbf{F}_i^{h'}) + \mathbf{F}_i^{h'}) \)$
其中 LN 是 LayerNorm,\( W_i^v \in \mathbb{R}^{D_2 \times D_2} \) 也是可学习参数。
总结要点
FRM 目的是为了让 2D 特征图中的特征重新排列成符合文字“阅读顺序”的序列,以便于后续 CTC 解码。
它通过学习一个 重排矩阵 \( \mathbf{M} \),来在特征图中“挑出”符合阅读顺序的路径。
整个过程借鉴了 Transformer 的自注意力机制,学习每一行中的“重排权重”。
横向重排是第一步,文中也会有纵向重排(这里未展开),来进一步适配弯曲或旋转严重的文字。
3.4 Semantic Guidance Module¶
.. figure:: https://img.zhaoweiguo.com/uPic/2025/05/1tphFZ.png
Figure 3:Visualization of attention maps when recognizing the target character by string matching on both sides, where $l_i$ is set to 5. [P] denotes the padding symbol.
其核心目的是帮助CTC(Connectionist Temporal Classification)模型更好地利用语言上下文信息来提升视觉特征的识别能力。
🎯 背景与动机
CTC模型通常是直接基于图像特征来分类出字符序列的,它并不显式建模语言上下文(比如上下文中哪些字更可能一起出现)。
因此,该方法需要视觉特征隐式融合语言上下文,才能得到更准确的识别结果。
为了解决这个问题,论文提出了Semantic Guidance Module(SGM)来加强视觉特征对语言上下文的感知能力。
🧩 SGM 模块设计
🔡 输入字符上下文建模
对于一张文本图像中每一个字符 \( c_i \),我们定义其语言上下文为:
左边字符序列 \( S_i^l = \{c_{i-l_s}, \dots, c_{i-1}\} \)
右边字符序列 \( S_i^r = \{c_{i+1}, \dots, c_{i+l_s}\} \)
\( l_s \) 表示上下文窗口大小。
SGM会利用字符周围的语言上下文(例如“你”这个字前后可能是“谢谢”或“好”)来引导视觉特征的理解。
🧠 左侧上下文信息处理流程(右侧类似)
将左侧字符串 \( S_i^l \) 映射为向量序列 \( E_i^l \in \mathbb{R}^{l_s \times D_2} \)
—— 即把字符序列变成嵌入(embedding),每个字符一个向量。
将字符嵌入经过编码器得到隐藏表示 \( Q_i^l \in \mathbb{R}^{1 \times D_2} \)
—— 表示整个左侧字符串的语义概括信息。
构造注意力机制:用 \( Q_i^l \) 去查询视觉特征 \( F \),得到注意力图 \( A_i^l \)
用点积计算注意力: $\( A_i^l = \sigma(Q_i^l W^q (F W^k)^T) \)$
用注意力图去加权视觉特征,得到上下文引导后的视觉特征: $\( F_i^l = A_i^l F W^v \)$
加入一个额外的上下文编码token \( T^l \),并使用LayerNorm和残差连接进行特征融合:
- \[ Q_i^l = \text{LN}(\sigma(T^l W^q (E_i^l W^k)^T) E_i^l W^v + T^l) \]
将融合后的特征 \( F_i^l \) 输入分类器:
\(\tilde{Y}_i^l = F_i^l W^{sgm} \)
得到该字符的预测概率分布。
🧩 总结
SGM模块通过如下方式强化视觉模型对语言上下文的感知:
利用字符左右的语言上下文字符串;
构建注意力机制将语义信息注入到视觉特征中;
最终提升字符分类的准确率。
3.5 Optimization Objective¶
核心是在训练过程中通过联合损失函数来优化模型,该损失函数由两个子损失组成:一个是CTC损失(用于对齐),另一个是左右分支的分类损失。
🔧 总体目标函数:
- \[ \mathcal{L} = \lambda_1 \mathcal{L}_{ctc} + \lambda_2 \mathcal{L}_{sgm} \]
其中:
\(\mathcal{L}_{ctc}\) 是 CTC(Connectionist Temporal Classification)损失;
\(\mathcal{L}_{sgm}\) 是“左右分支”的分类损失;
\(\lambda_1 = 0.1\),\(\lambda_2 = 1\):是两个损失项的加权系数。
📘 1. CTC损失(\(\mathcal{L}_{ctc}\)):
公式: $\( \mathcal{L}_{ctc} = \text{CTCLoss}(\tilde{\mathbf{Y}}_{ctc}, \mathbf{Y}) \)$
其中
\(\tilde{\mathbf{Y}}_{ctc}\):模型预测的序列输出;
\(\mathbf{Y}\):真实的标签序列;
CTCLoss 是常用于语音识别、OCR 等时序任务中的一种损失,用来处理输入输出长度不一致的情况。
📘 2. 左右分支的分类损失(\(\mathcal{L}_{sgm}\)):
公式: $\( \mathcal{L}_{sgm} = \frac{1}{2L} \sum_{i=1}^{L} \left( ce(\tilde{\mathbf{Y}}^{l}_{i}, \mathbf{c}_{i}) + ce(\tilde{\mathbf{Y}}^{r}_{i}, \mathbf{c}_{i}) \right) \)$
其中
\(L\):总样本数;
\(\tilde{\mathbf{Y}}^{l}_{i}, \tilde{\mathbf{Y}}^{r}_{i}\):左右分支对第 \(i\) 个样本的预测;
\(\mathbf{c}_i\):第 \(i\) 个样本的真实类别;
\(ce\):交叉熵损失(cross-entropy),是常用的分类损失函数。
这个损失项的设计目的是让左右两个分支都能准确地预测类别,并保持一致性。
✅ 总结
模型的训练目标是最小化一个联合损失函数,包括:
基于时间对齐的 CTC 损失(用于时序建模);
左右两个输出分支的分类交叉熵损失(提高分类准确性和分支一致性);
通过调整两个损失的权重(\(\lambda_1 = 0.1, \lambda_2 = 1\)),重点优化分类准确性,同时保留一定的序列对齐能力。
4 Experiments¶
4.1 Datasets and Implementation Details¶
✅ 评测数据集:
常规文字识别数据集(Com 类):
包含6个经典数据集:
IC13, SVT, IIIT5K → 比较规则的英文街景或自然图像
IC15, SVTP, CUTE80 → 包含更多复杂和变形文本
Union14M-L 测试集(U14M):
包含7个子集,涵盖复杂场景:
Curve(弯曲文字)
MO(多方向)
Artistic(艺术风格)
Cless(无上下文)
Salient(显著文字)
MW(多词)
General(综合)
遮挡场景文字(OST):
OSTw:弱遮挡
OSTh:强遮挡
长文本数据集(LTB):
包含 3376 条长度为 25~35 的长文本数据
中文识别数据集(BCTR):
分为四个子集:Scene、Web、Doc、HW(手写)
✅ 训练数据与策略:
英文识别:
使用三大真实世界数据集(Real、REBU-Syn、U14M-Train)进行训练;
但这些数据集中部分样本和测试集 U14M 有重叠(数据泄漏问题);
因此,作者构建了 U14M-Filter 版本,过滤掉重叠样本,避免泄漏;
SVTRv2 及 24 个主流方法都在 U14M-Filter 上重新训练以保证公平。
中文识别:
使用 BCTR 的训练集;
不同于过去每个子集单独训练的做法,这里是把全部子集整合后统一训练。
✅ 实现细节:
优化器:使用 AdamW,权重衰减 0.05;
学习率(LR):6.5 × 10⁻⁴;
批量大小(batch size):1024;
学习率调度器:OneCycleLR,英文模型前 1.5 个 epoch 线性 warmup,中文为 4.5;
总训练 epoch:英文 20,中文 100;
英文模型:先用无 SGM(结构引导匹配)版本预训练,然后用加 SGM 的版本微调;
评估指标:使用 word-level accuracy;
数据增强:包括旋转、透视、运动模糊、高斯噪声等;
最大文本长度:25;
字符集大小(Nₐ):
英文:94
中文:6624
训练硬件:使用 4 张 RTX 4090 GPU + 混合精度训练;
默认模型:若未说明,SVTRv2 指的是 SVTRv2-B(大模型版本)。
这段内容主要突出了:
数据集覆盖面广;
公平训练避免数据泄漏;
模型在英文和中文场景下的训练方法不同;
工程实现上的优化(大 batch、混合精度、数据增强等)保障训练效率。
4.2 Ablation Study¶
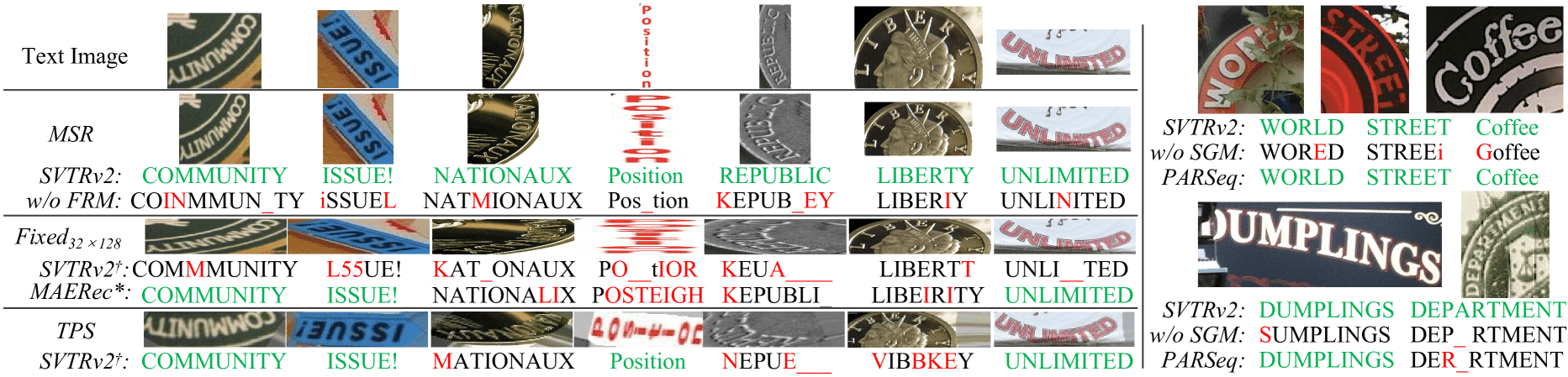
Figure 4:Qualitative comparison of SVTRv2 with previous methods on irregular and occluded text. † means that SVTRv2 utilizes the fixed-scale (Fixed32×128) or rectification module (TPS) as the resize strategy. MAERec* means that SVTRv2† integrates with the attention-based decoder from the previous best model. Green, red, and _ denotes correctly, wrongly and missed recognition, respectively.
消融实验表明:
MSR 能避免图像形变、
FRM 能处理文字结构错乱、
SGM 能应对遮挡和缺字,
三者对 SVTRv2 的性能提升起到了关键作用,且具有很强的通用性。
4.3 Comparison with State-of-the-arts¶
1. 核心结论(英文识别)
SVTRv2-B 在15个评估场景中有12个拿下第一,几乎在所有任务中都胜过了 EDTR(Encoder-Decoder Text Recognizers)模型。
模型轻量、推理速度快
长文本识别能力强
小模型(SVTRv2-T 和 SVTRv2-S)也有很强表现
2. 弯曲文本(Curve)和多方向文本(MO)表现
SVTRv2 明显超越了现有的 CTC 模型,SVTRv2-B 相对上一代 SVTR-B 精度在 Curve 和 MO 场景分别提升了 14.4% 和 44.5%,这是非常大的飞跃。
3. 中文文本识别
SVTRv2-B 在中文场景中同样表现出色,达到了 state-of-the-art(最先进水平),说明其跨语言的泛化能力很强。
总结一句话
SVTRv2 系列模型不仅在传统 CTC 强项(如速度和长文本)方面保持优势,还通过新结构突破了 CTC 模型在弯曲、不规则文本方面的劣势,全面超越了目前主流的 EDTR 模型,适用于多种语言和复杂场景。
5. Conclusion¶
✅ 核心观点
SVTRv2 是一种基于 CTC 的新型场景文本识别(STR)方法,兼顾高精度和高效率。
🔧 技术亮点
MSR(Multi-Scale Recognition)模块 和 FRM(Feature Refinement Module)模块:解决了 CTC 模型以往对不规则文本(如弯曲、旋转)处理能力弱的问题。
SGM(Semantic Guidance Module)模块:在不引入语言模型的情况下,通过视觉模型引入语言语义信息,提升了语义理解能力。
这些模块的引入没有改变 CTC 模型的基本架构,保持了其“轻量、高速”的特点。
📊 实验结果
在多个基准测试中(包括规则文本、不规则文本、遮挡文本、中文、长文本等场景)都表现优异。
在精度和推理速度两个维度都领先于主流 EDTR 方法(Encoder-Decoder based Text Recognizers)。
📦 开源和社区贡献
作者自己从零开始复现了 24 个主流模型,在他们构建的新数据集 U14M-Filter 上进行了公平评估(无数据泄漏)。
这为 后续研究提供了标准化、可信的实验平台。
总结
SVTRv2 通过引入 MSR、FRM 和 SGM 模块,大幅提升了 CTC 模型在复杂文本识别任务中的能力,同时保持了 CTC 高效的优势,并提供了可靠的 benchmark,推动了整个 OCR 领域的进步。
8. More detail of real-world datasets¶
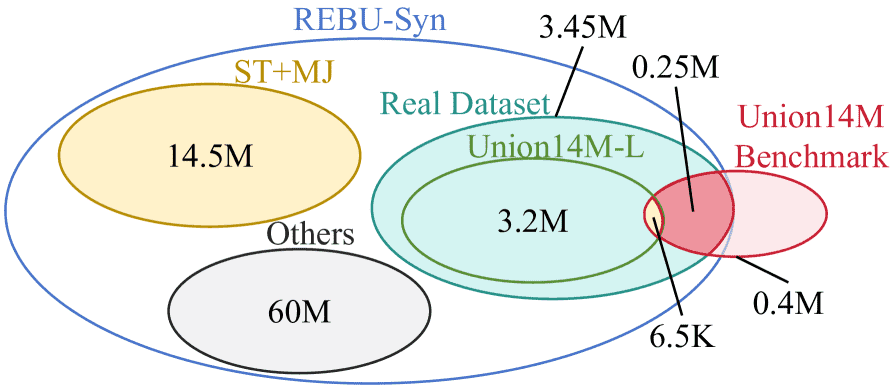
Figure 6:The relationship between the three real-world training sets.
目前有三个大规模的真实训练集,分别是
Real Dataset
REBU-Syn
Union14M-L 训练集 ( U14M-Train )
这3个数据集与 Union14M-Benchmarks 都有重叠,会导致数据泄露问题
因为增加一个过滤这个重叠部分的数据集 U14M-Filter