2506.13642_Stream-Omni: Simultaneous Multimodal Interactions with Large Language-Vision-Speech Model¶
组织: Chinese Academy of Sciences, University of Chinese Academy of Sciences
Abstract¶
随着类似 GPT-4o 的多模态大模型(LMM)出现,研究者开始探索如何更好地融合文本、图像和语音,让模型支持更灵活的多模态交互。以往的做法是把不同模态的表示拼接成一串序列,再输入到大语言模型中,这种方法简单,但往往需要大量数据来训练模态之间的对齐关系。
本文提出了一个新的模型 Stream-Omni,它更有目的性地建模模态之间的关系,从而能更高效、灵活地完成对齐。
Stream-Omni 以大语言模型为核心:
对于“图像+文本”这种语义互补的情况,仍然采用传统的序列拼接方式;
对于“语音+文本”这种语义一致的情况,引入一种基于 CTC 的层级映射方法来对齐。
这样一来,即使在数据量较少的情况下(尤其是语音数据),也能实现良好的模态对齐,并将文本能力迁移到语音或图像中。
实验证明 Stream-Omni 在图像理解、语音交互和视觉引导的语音任务中表现优秀。而且由于采用了层级映射,在语音交互过程中还能同时输出中间结果,比如语音识别文本和模型回复,带来更完整的多模态体验。
1. Introduction¶
这段话讲的是一个叫 Stream-Omni 的大模型,它支持文本、图像和语音三种模态的交互,并尝试解决目前多模态大模型在语音、图像与文本融合上的一些难题。
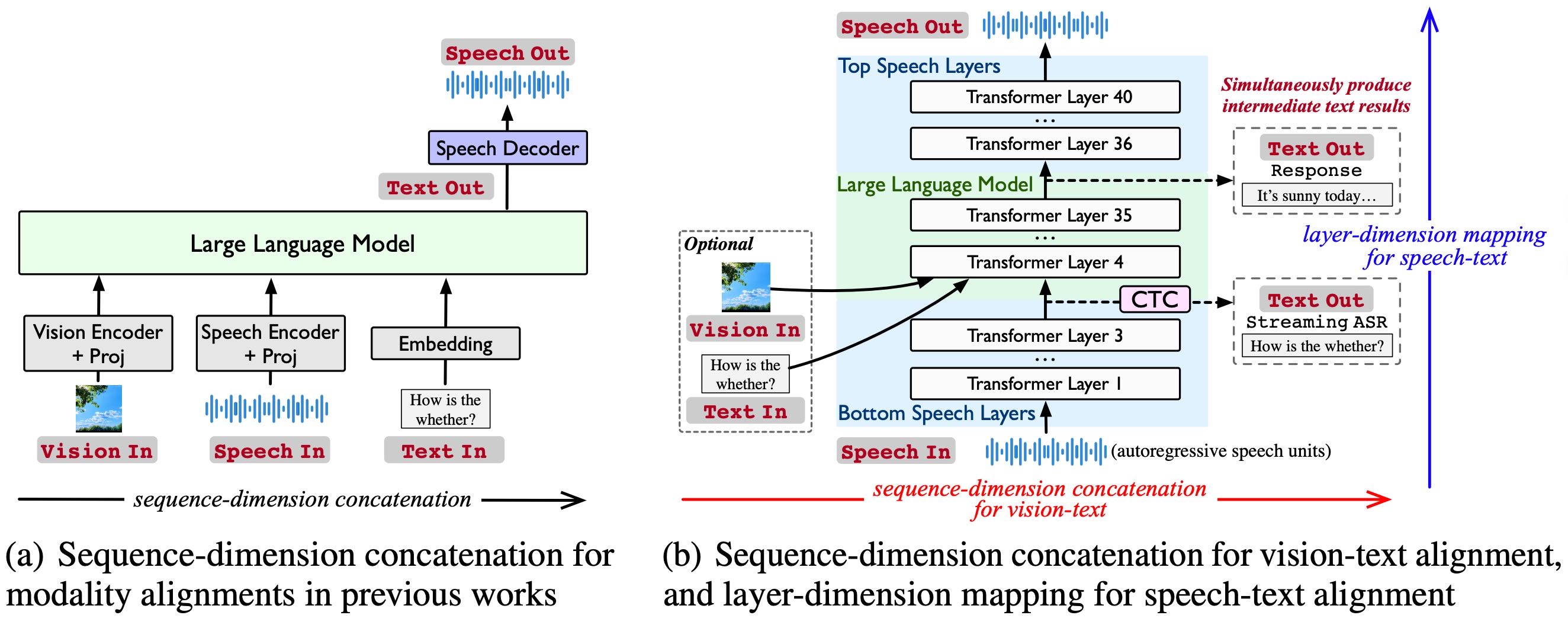
Figure 1: Comparison of modality alignments in Stream-Omni and previous works.
📌 背景:¶
GPT-4o 等多模态大模型(LMMs)可以处理文本、图像和语音,为各种应用带来可能。
GPT-4o 甚至可以边听边看边显示文字(如转录结果),这需要强大的跨模态能力。
❗ 现有问题:¶
构建这种同时支持三种模态的模型很难,因为语音、图像、文本的表达方式差别很大。
目前的模型往往只专注于语音或图像,并把模态特征拼接后输入 LLM,这种方式:
对数据依赖很强(需要大量三模态数据);
不能像 GPT-4o 那样在语音交互时生成中间文本结果(如转录)。
✅ Stream-Omni 的创新点:¶
核心理念:不同模态和文本的关系不同,不能一刀切拼接在一起。
图像:补充文本信息(语义互补)→ 可以拼接对齐;
语音:跟文本很像(语义一致)→ 更适合“图层映射”对齐。
模型结构:
以 LLM 为核心;
图像通过序列拼接方式对齐到文本;
语音通过图层映射方式对齐,使用 CTC(连接时序分类)机制实现语音到文本的映射;
可以边听边转写、边对话。
📈 效果:¶
Stream-Omni 用了 23,000 小时的语音数据,在多个视觉、语音、视觉语音结合任务上表现出色;
能同时进行语音对话和生成中间文本结果,实现更流畅的多模态交互体验。
3. Stream-Omni¶
Stream-Omni 是一个支持 文本、图像和语音三种模态的多模态大模型(LMM),其核心是一个大语言模型(LLM)。图像和语音都通过与文本对齐来实现联合理解和生成。
3.1 Architecture¶
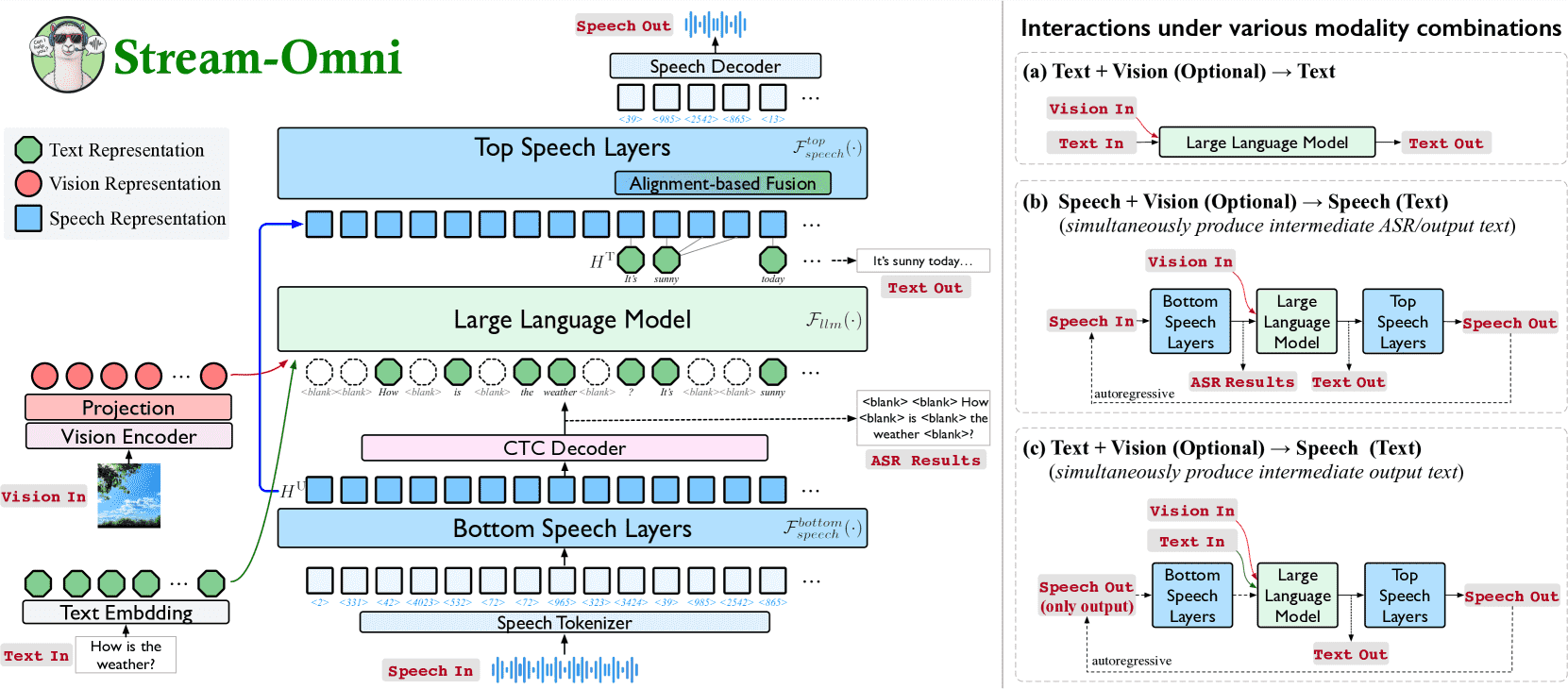
Figure 2:Architecture of Stream-Omni. Right: Interactions under various modality combinations.
3.1.1 Vision Modality¶
使用图像编码器提取视觉特征。
把这些图像特征和文本 token 拼接在一起,一起输入 LLM,从而实现图文融合。
3.1.2 Speech Modality¶
为什么需要 Stream-Omni?
相比图像,语音和文本的对齐更难,因为语音表现形式变化大,而且高质量语音数据少。
Stream-Omni 利用语音和文本间的语义一致性,设计出一种更容易训练的映射方式。
它在 LLM 前后各添加了额外的语音层:
底部语音层(bottom speech layers)用于 语音转文本;
顶部语音层(top speech layers)用于 文本转语音。
Speech Tokenizer¶
语音编码:先用预训练的 CosyVoice 模型将原始语音编码成离散的语音单元。
词表扩展:将这些语音单元与文本词表合并,形成一个多模态词表(text + speech + ⟨blank⟩ 空白符)。
Speech-Text Mapping¶
用底部语音层把语音单元转换为特征表示,再用 CTC 解码器输出对应的文本序列。
CTC 允许对齐模糊并能输出流式结果,还能用空白符判断用户何时说完。
Text Generation¶
模型将从语音中得到的文本表示,喂入 LLM,生成回答。
中间会去掉无用的空白符 ⟨blank⟩,提升文本结构质量。
Streaming Speech Generation¶
生成文本时,顶部语音层根据对齐关系,同步生成对应的语音单元。
利用 CTC 的对齐特性,让每个语音单元只在其对应的文本生成后才开始生成。
使用交叉注意力(Cross-Attn)模块融合文本上下文,指导每一步语音生成。
类似“等 K 个 token 再说”的 wait-K 策略可加快响应。
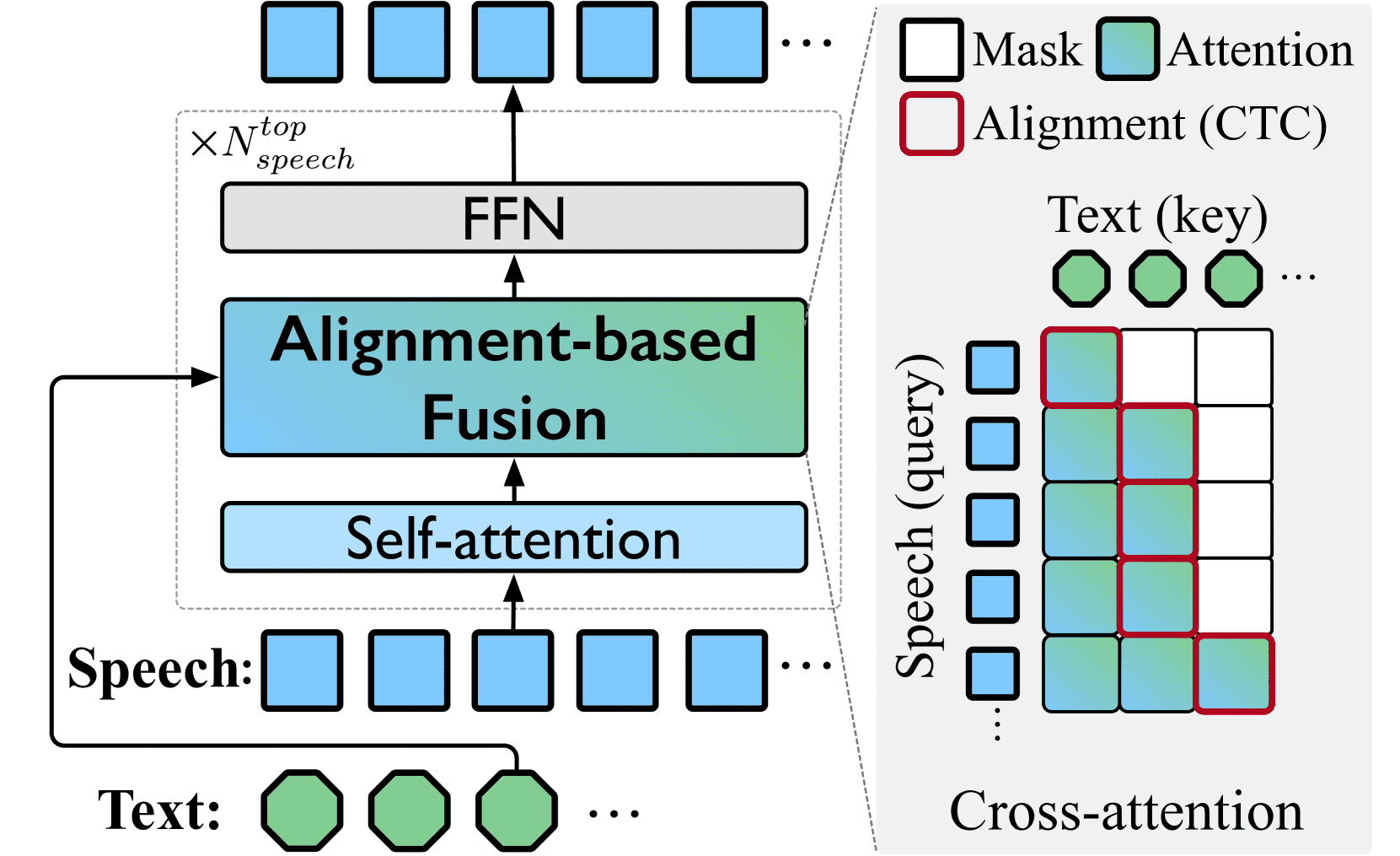
Figure 3:Diagram of top speech layers.
最终用顶层生成的语音单元,通过 CosyVoice 解码器合成最终的语音。
🚀 Stream-Omni 的优势¶
灵活扩展语音和图像能力,不破坏 LLM 的文本能力。
支持 流式语音输入输出,适合实时交互。
利用文本能力迁移到语音,无需大规模语音数据重复训练。
3.2 Training¶
目标:Stream-Omni 是一个同时处理文本、图像和语音的多模态大模型。为了让这三种模态协同工作,它通过“三阶段训练法”逐步对齐这些模态。
3.2.1 Data Construction¶
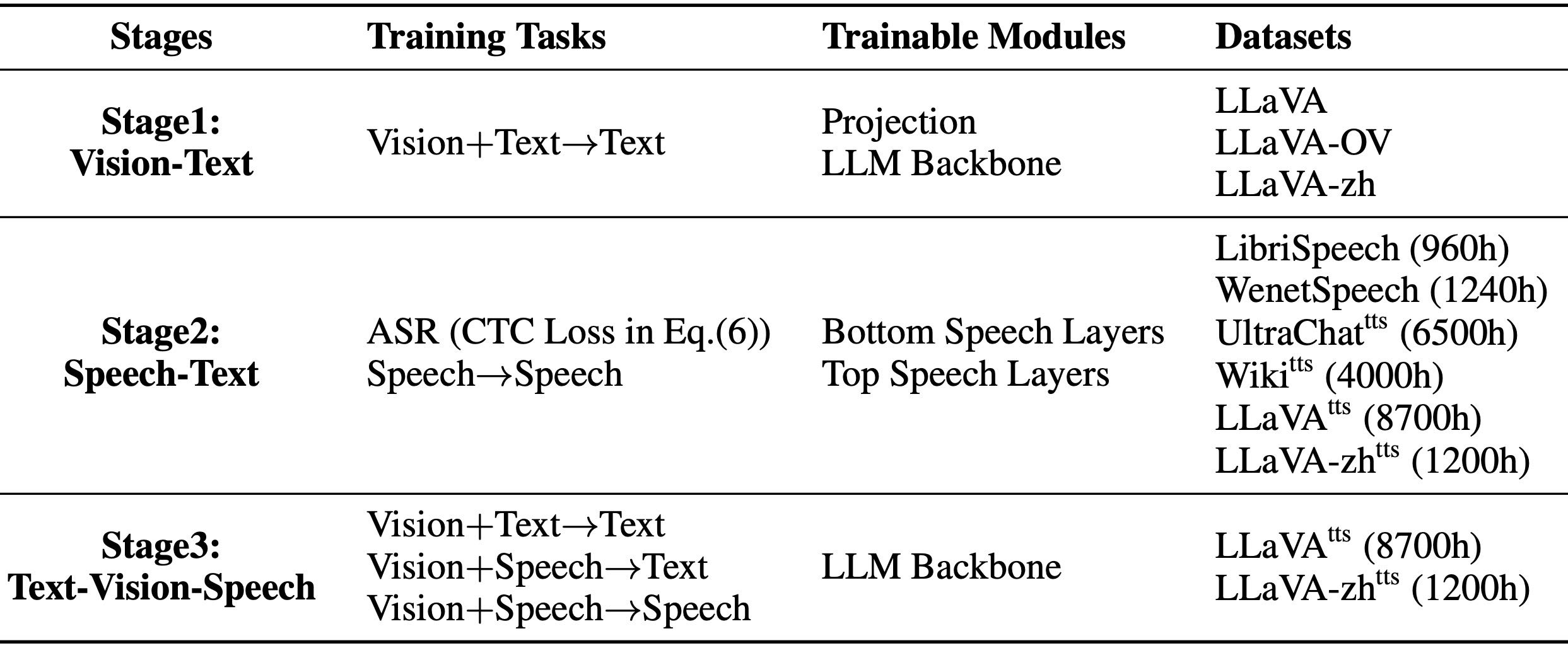
Table 1: Training stages and data of Stream-Omni.
因为三模态的数据稀缺,研究者自建了训练数据集:
图文数据:来自 LLaVA 系列(如 LLaVA、LLaVA-zh 等)
语音文本数据:主要用 LibriSpeech 和 WenetSpeech 两个公开 ASR(语音识别)数据集
三模态数据:将现有的图文数据通过 TTS(文本转语音)合成对应的语音,得到伪三模态数据(称为 InstructOmni)
3.2.2 3-Stage Training¶
Stage 1: Vision-Text Alignment
学习让图像和文本一起协同生成文字,方法类似 LLaVA。
Stage 2: Speech-Text Alignment
用 CTC 损失训练底层语音层,用交叉熵训练上层语音层。
训练时使用真实转录文本,而非模型生成的,确保文本和语音一致。
Stage 3: Text-Vision-Speech Alignment
用构建的图文语音混合数据同时训练,支持三种输入组合:
图+文 → 文
图+语音 → 文
图+语音 → 语音
3.3 Inference¶

Algorithm 1 Inference of Stream-Omni
Stream-Omni 可实现边生成文字边生成对应语音的能力:
首先从图像和语音中提取特征。
使用 LLM 生成下一个文本 token(文字片段)。
同时用语音模块根据当前生成的文字生成对应的语音单元(units)。
用 CTC 判断当前语音是否已完整表达该 token。
如果识别出新文字,说明语音完整了,可以继续生成下一个 token。
否则继续生成当前文字对应的语音。
重复上述步骤,直到生成
<eos>(结束)。
这种机制使得模型可以同步生成文字和语音,实现多模态交互。
总结¶
Stream-Omni 的核心思路是:
构建伪三模态数据;
分阶段训练,先对齐两两模态,再对齐三模态;
推理时可以同时生成文字和语音,保持一致性和实时性;
架构灵活,支持任意模态组合交互(如图+语音、图+文等)。
4. Experiments¶
4.1 基准测试(Benchmarks)¶
为了验证 Stream-Omni 在图像和语音方面的多模态能力,作者做了以下测试:
图像任务:在LLaVA使用的11个图像问答等基准数据集上测试,比如 VQAv2、GQA、TextVQA 等。
语音任务:在 Llama Questions 和 Web Questions 这两个“语音问答”数据集上测试,看模型回答是否正确。
图像+语音任务:自己构造了一个真实场景下的图像+语音交互测试集 SpokenVisIT,由GPT-4o对模型的语音回答打分(1到5分),并分成两种设置:
语音→文本(S→T)
语音→语音(S→S)
对语音回答先用 Whisper 模型转为文本再评估。
4.2 对比基线模型(Baselines)¶
他们拿 Stream-Omni 和多个已有模型做对比,分成三类:
图像为主的模型:如 BLIP-2、Qwen-VL、LLaVA 等。
语音为主的模型:如 TWIST、SpeechGPT、Moshi、GLM-4-Voice 等。
全模态模型:主要和 VITA-1.5 比较,它也是一个图文语三模态模型,训练数据规模接近。
4.3 模型配置(Configuration)¶
Stream-Omni 模型的结构组成:
主体基于 LLaMA 3.1 8B 指令微调版(共32层 Transformer)。
图像编码器:使用 SigLIP-400M 模型。
语音模块:
下层语音处理有3层 Transformer,上层语音生成有5层。
所有语音层结构和主模型一致。
语音编码器和解码器来自 CosyVoice。
词表:
文本词:128K(来自LLaMA)
语音单位:4096(来自CosyVoice)
外加一个
<blank>空白符
训练设备:用8块 H800 GPU 训练,用1块 A100 GPU 测试。
5. Results and Analyses¶
5.1 图像理解能力¶
Stream-Omni 在多个视觉任务中表现出色,虽然它是一个统一支持图像、语音、文本的多模态模型,但其视觉表现接近甚至超过了专门的视觉大模型(如 LLaVA、VITA-1.5),说明它很好地解决了多模态干扰的问题。
5.2 语音问答能力¶
在语音问答(SpeechQA)任务中,Stream-Omni 通过少量语音数据就能取得比许多基于大规模语音预训练的模型(如 SpeechGPT、Moshi)更好的效果。特别是在语音转文本(S→T)方面表现强劲,这是由于它使用了基于 CTC 的语音识别机制,有效地把文本知识迁移到语音。
5.3 视觉引导语音交互¶
Stream-Omni 在 SpokenVisIT 基准上的表现优于其他模型(如 GPT-4V、VITA-1.5),而且它不仅支持图像+语音→文本,还能生成语音,实现真正的多模态交互。
5.4 语音-文本映射质量¶
在语音识别任务(LibriSpeech)中,Stream-Omni 兼顾了高准确率和低延迟。相比传统模型需要整个大模型参与推理,它只用底层语音层进行非自回归识别,大大加快了速度,还能边说边显示中间结果,提升了用户体验。
5.5 跨模态融合策略¶
Stream-Omni 使用“对齐融合”(alignment-based fusion)策略把文本信息融合到语音生成中:
使用注意力机制效果最好,能动态关注上下文;
使用合适的“窗口长度”融合文本比用全部文本或很少文本更有效,因为语音生成具有顺序性和局部性。
6. Conclusion¶
我们提出了 Stream-Omni,一种能同时处理多种模态(比如图像、语音、文本)交互的大模型。
它通过“按顺序拼接”的方法来整合图像信息,通过“按层对应”的方法来整合语音信息,从而高效地对齐不同模态。
在语音交互时,它还能实时输出中间的文本结果,提升多模态使用体验。
Appendix A Construction of InstructOmni¶
为了补充当前缺乏的语音和三模态(文本、图像、语音)指令数据,研究者构建了一个叫 InstructOmni 的全模态数据集。
他们的方法是:在已有的文本或图文指令数据基础上,用 TTS 技术把文本转成语音,生成配套的语音数据。
具体来说,他们从 LLaVA、UltraChat 和维基百科中提取文本指令与回答,并用 CosyVoice TTS 转成语音;为了增加语音的多样性,还引入了不同说话人的特征(从 LibriSpeech 和 AISHELL 中采样)进行语音克隆。
结果是,虽然他们只用了 2.3 万小时的语音数据,比其他大模型用的语音数据量少得多(如 Moshi 用了 700 万小时),但效果仍然很好,说明数据利用效率高。
Appendix B Construction of SpokenVisIT¶
研究者构建了一个名为 SpokenVisIT 的基准测试,用来评估模型在“图像+语音交互”场景下的能力。
它基于一个真实场景的视觉问答数据集 VisIT,这个数据集有574张图片和70种任务,内容用的是口语化语言,适合语音交互。
为了变成语音任务,他们用**文本转语音(TTS)**把文字问题转换成语音,并删除了8个不适合用语音表达的数学题。
模型听用户语音并给出语音回答(通过ASR转成文字后评估),评分由GPT-4o完成,标准包括:有用性、反应性、共情能力和实际适用性,满分5分。
评估时给出图片描述、用户问题和模型回答,GPT输出一个分数(JSON格式)。