2307.08691_FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning¶
作者: 普林斯顿大学, 斯坦福大学
Abstract¶
Scaling Transformers to longer sequence lengths has been a major problem in the last several years, promising to improve performance in language modeling and high-resolution image understanding, as well as to unlock new applications in code, audio, and video generation.
The attention layer is the main bottleneck in scaling to longer sequences, as its runtime and memory increase quadratically in the sequence length.
FlashAttention exploits the asymmetric GPU memory hierarchy to bring significant memory saving (linear instead of quadratic) and runtime speedup (2-4× compared to optimized baselines), with no approximation.
However, FlashAttention is still not nearly as fast as optimized matrix-multiply (GEMM) operations, reaching only 25-40% of the theoretical maximum FLOPs/s.
We observe that the inefficiency is due to suboptimal work partitioning between different thread blocks and warps on the GPU, causing either low-occupancy or unnecessary shared memory reads/writes.
We propose FlashAttention-2, with better work partitioning to address these issues.
- In particular, we
tweak the algorithm to reduce the number of non-matmul FLOPs
parallelize the attention computation, even for a single head, across different thread blocks to increase occupancy, and
within each thread block, distribute the work between warps to reduce communication through shared memory.
These yield around 2× speedup compared to FlashAttention, reaching 50-73% of the theoretical maximum FLOPs/s on A100 and getting close to the efficiency of GEMM operations.
We empirically validate that when used end-to-end to train GPT-style models, FlashAttention-2 reaches training speed of up to 225 TFLOPs/s per A100 GPU (72% model FLOPs utilization).
这段内容主要讲述了FlashAttention-2(FA2)如何改进FlashAttention(FA)来提高Transformer模型在长序列上的计算效率。
- 以下是主要要点的解释:
- 问题背景:长序列Transformer计算瓶颈
Transformer模型在处理长序列(long sequence)时,主要的计算瓶颈来自注意力层(attention layer)。
这个瓶颈的核心问题是,注意力机制的计算复杂度和内存消耗是二次增长的(O(N²)),当序列长度增加时,计算成本会非常高。
这不仅影响了语言建模(language modeling),还影响了高分辨率图像理解、代码生成、音频处理、视频生成等任务的扩展能力。
- FlashAttention(FA)的优化
FlashAttention 通过优化GPU的存储层级(memory hierarchy),降低了内存使用(从O(N²)降到O(N)),同时提升了运行速度(比优化后的baseline快2-4倍)。
重要的是,FA 没有牺牲计算精度(non-approximation),即不会影响模型的准确性。
- FlashAttention的不足
虽然FA提高了效率,但仍然远不及GPU的最佳计算效率(理论最高FLOPs/s的25-40%)。
- 主要的性能瓶颈在于:
线程块(thread block)和warp的工作划分不均,导致GPU的低占用率(low-occupancy)。
不必要的共享内存(shared memory)读写,增加了通信开销。
- FlashAttention-2(FA2)的优化方案
- 目标:进一步优化GPU计算,接近矩阵乘法(GEMM)的效率,具体优化点:
减少非矩阵乘法(non-matmul)运算的FLOPs,提高计算效率。
将单个注意力头(attention head)的计算并行化,跨多个线程块(thread block),增加GPU利用率。
在每个线程块(thread block)内,优化warp之间的工作分配,减少通过共享内存的通信,提升计算吞吐量。
- 最终性能提升
通过上述优化,FlashAttention-2 比FlashAttention快2倍。
在A100 GPU上,FA2 能达到理论FLOPs的50-73%,接近最优矩阵乘法(GEMM)的效率。
在GPT模型的训练中,FA2 达到了225 TFLOPs/s的训练速度(72%模型FLOPs利用率),意味着更高效的训练能力。
- 总结
FlashAttention-2 主要优化了GPU上的计算方式,使得长序列 Transformer 的训练和推理更加高效。它通过更好的线程调度和减少非核心计算,使得注意力计算的速度接近GPU计算的极限,提升了Transformer模型的可扩展性。
1. Introduction¶
- 长序列问题和现有优化方法
- 问题背景:
传统的注意力机制 (standard attention) 计算的时间复杂度和内存消耗是 O(N²),其中 N 是序列长度。这意味着当 N 很大(例如 32k、65k)时,计算和存储成本变得极高,限制了实际应用。
- 长序列的需求:
- 近几年,深度学习(特别是大模型)已经能够处理比过去更长的上下文长度:
GPT-4 的上下文长度可达 32k
MosaicML MPT 的上下文长度达到 65k
大语言模型对更长上下文的需求越来越大,例如用于处理长篇文章、长对话和视频内容。
- 现有优化方法的不足
- 尽管已经有很多方法(如线性注意力)尝试优化 O(N²) 的计算复杂度,但目前大多数大规模训练仍然使用标准的Softmax注意力
计算 S = QKᵀ,存入 HBM
计算Softmax(S) → P,再次存入 HBM
O = P × V,需要额外的 HBM 访问,导致大量数据搬运和存储开销
反向传播时,P 也需要存储,导致 O(N²) 级别的内存消耗
由于计算需要存储 S(N×N) 和 P(N×N),所以内存占用O(N²),当 N 较大(比如8k),显存需求会变得非常高。
- 主要原因:大规模训练仍然更偏好标准注意力,而非其他优化方法,主要是因为:
许多优化方法只适用于特定情况,适用范围有限。
这些方法仍然无法完全匹敌矩阵乘法(GEMM)的计算效率。
- FlashAttention:改进的注意力计算
为了解决计算量大、内存占用高的问题,Dao et al.
提出了 FlashAttention 方法:
思路:通过重新排序计算步骤,减少访存次数,并将更多计算放到GPU的矩阵计算单元(GEMM)上,从而减少内存带宽限制。
- 关键优化点:
减少中间结果的物理存储,避免标准注意力中 S 和 P 这两个 O(N²) 级别的存储需求,从而节省大量内存
(O(N²)→O(N))更少的显存读写操作(减少HBM访问),优化访存带宽限制。
提高计算单元(SM和Tensor Core)利用率,尽量让线程保持忙碌状态,减少浪费的计算资源。
- 优化
重新排列计算步骤,减少HBM的访问(HBM访问瓶颈)。
利用GPU共享内存(SRAM)加速计算,减少显存开销。
避免不必要的内存读写(例如P的物理存储)。
FlashAttention 比标准注意力机制快 2-4 倍,内存需求仅 O(N×d),不需要存 S 和 P,大大节省内存。
- FlashAttention-2 的目标
优化计算流程:避免不必要的非GEMM计算,提高矩阵乘法的计算比例。
更好的线程分配(work partitioning):优化GPU中线程块(Thread Block)和warp的工作分配,提高并行度,减少因低线程占用率(low occupancy)和共享内存的读/写开销。
- 优化关键点
减少非矩阵乘法(non-GEMM)计算,尽可能让计算集中在高效的 GEMM 操作上,提高 GPU 计算单元的利用率。
- 优化 GPU 并行策略,使得:
前向传播(Forward Pass) 和 反向传播(Backward Pass) 都能并行化,不仅在 batch 维度,还在 序列长度(N)和头数(H) 维度上并行。
减少共享内存(Shared Memory)访问,优化 GPU 线程分配,使得计算核心(SM)更高效地工作。
- 原文
- We tweak the algorithms to reduce the number of non-matmul FLOPs while not changing the output.
While the non-matmul FLOPs only account for a small fraction of the total FLOPs,
they take longer to perform as GPUs have specialized units for matrix multiply,
and as a result the matmul throughput can be up to 16× higher than non-matmul throughput.
It is thus important to reduce non-matmul FLOPs and spend as much time as possible doing matmul FLOPs.
- We propose to parallelize both the forward pass and backward pass along the sequence length dimension, in addition to the batch and number of heads dimension.
This increases occupancy (utilization of GPU resources) in the case where the sequences are long (and hence batch size is often small).
Even within one block of attention computation, we partition the work between different warps of a thread block to reduce communication and shared memory reads/writes.
- 总结
Transformer 需要 O(N²) 的计算量和存储空间,主要开销是两次 GEMM 矩阵乘法(计算 S 和 O),以及 softmax 计算(需要存 S),导致长序列处理成本极高。
FlashAttention 通过优化计算顺序和减少访存,实现了2-4× 加速,同时 降低内存使用,使得计算更接近理想线性复杂度 O(N)。
- FlashAttention-2
减少非矩阵乘法(non-GEMM)操作,因为它们的吞吐量远小于GEMM
优化GPU上的工作分配(线程块、warp),减少内存访问,提高SM利用率,避免不必要的数据传输。
2. Background¶
介绍了GPU架构特性、标准注意力机制的计算流程,以及为什么标准实现的计算和内存消耗很高。
2.1 Hardware characteristics¶
- GPU的核心组成
- 计算单元:负责执行浮点运算(如矩阵乘法)。
现代GPU通常有专门的硬件单元来加速低精度矩阵运算(如Nvidia的Tensor Cores,可优化FP16/BF16计算)。
- 存储层次结构(Memory Hierarchy)
HBM(高带宽内存,高速但远离计算单元):例如Nvidia A100 GPU有40-80GB HBM,带宽1.5-2.0TB/s。
SRAM(片上共享内存,低延迟):A100每个流处理多处理器(SM)有192KB的共享内存,总带宽约19TB/s。
L2缓存(不受编程控制):这里不考虑它的作用,主要聚焦在HBM和SRAM。
- 什么是 Kernel
Kernel(内核)是指在 GPU 上执行的并行计算函数。
它描述了一段代码,这段代码会在大量 GPU 线程上同时执行,并且每个线程通常会处理数据的一小部分。
CPU 负责调用 Kernel,GPU 负责执行 Kernel。
Kernel 依赖 GPU 线程模型(线程 → 线程块 → Warp → SM)。
Kernel 典型的执行流程:从 HBM 读取数据 → 并行计算 → 写回 HBM。
- GPU的执行模型
- 线程组织结构:
线程 (Thread):最基本的执行单元,每个线程执行一个指令序列。
线程块 (Thread Block):多个线程组成一个线程块,一个线程块可以包含数百个线程。
- 线程束 (Warp):线程块内的线程进一步分成多个 warp,每个 warp 包含 32 个线程
warp 内的线程会同步执行(SIMD/SIMT 方式)
它们可以快速通信
- 线程如何被调度
流式多处理器 (Streaming Multiprocessor, SM):GPU 由多个 SM 组成,每个 SM 负责执行多个线程块
调度方式:线程块被分配到 SM 上执行,每个 SM 可同时运行多个 warp
- 线程之间的通信方式
Warp 内的通信: 通过快速 shuffle 指令,线程可以高效地交换数据。
线程块内的通信: warp 之间可以使用共享内存 (Shared Memory) 进行数据交换。共享内存位于 SM 内部,比全局内存(HBM)快得多。
- Kernel 的数据流
数据加载 (Load):Kernel 先从高带宽存储器 (HBM, High Bandwidth Memory) 读取数据,加载到 寄存器 和 片上 SRAM(共享内存)。
计算 (Compute):GPU 进行计算,比如矩阵乘法。
写回 (Store):计算完成后,结果写回 HBM。
- 总结
GPU 通过层级化的组织方式(线程 → 线程块 → Warp → SM)来高效管理并行计算。
- 执行时,Kernel 会:
从 HBM 读取数据,存入寄存器或共享内存。
线程并行计算,warp 级别使用 shuffle,block 级别使用共享内存。
将计算结果写回 HBM。
2.2 Standard Attention Implementation¶
- 输入:
Q (Query), K (Key), V (Value) ∈ ℝ^(N×d)
N 是序列长度, d 是头部维度(一般64-128)
目标是计算注意力输出 O ∈ ℝ^(N×d)
- 前向传播(Forward Pass)
- 计算注意力权重矩阵: \(S = QK^\top \in \mathbb{R}^{N \times N}\)
这是一个矩阵乘法(GEMM操作),复杂度是 \(O(N²d)\)
- 计算Softmax: \(P = \text{softmax}(S) \in \mathbb{R}^{N \times N}\)
作用是归一化注意力权重
- 计算最终输出: \(O = P V \in \mathbb{R}^{N \times d}\)
这也是矩阵乘法(GEMM操作),复杂度是 \(O(N²d)\)
- 反向传播(Backward Pass)
- 计算梯度:
\(dV = P^\top dO \in \mathbb{R}^{N \times d}\)
\(dP = dO V^\top \in \mathbb{R}^{N \times N}\)
\(dS = d\text{softmax}(dP) \in \mathbb{R}^{N \times N}\)
\(dQ = dS K \in \mathbb{R}^{N \times d}\)
\(dK = Q dS^\top \in \mathbb{R}^{N \times d}\)
- 关键问题:
必须存储 P (N×N) 以用于反向传播,这会占用大量内存。
- 标准注意力的瓶颈
- 主要问题:
计算瓶颈: 计算主要由 GEMM 组成,但大量的HBM访问(数据读写)限制了性能。
内存瓶颈: 需要存储 S 和 P,导致 O(N²) 内存消耗,使得长序列难以处理。
- 计算开销(Compute Cost):
核心计算是矩阵乘法(GEMM),但由于涉及大量读写(memory-bound),速度受限。
- 具体而言:
计算 S = QKᵀ 需要 GEMM 操作,并把结果写入 HBM
计算 P = softmax(S),再次访问HBM
计算 O = PV 需要 GEMM 操作,并把结果写入 HBM
必须存储P用于反向传播
- 内存瓶颈(Memory Cost):
S 和 P 的存储需要 O(N²) 内存
- 当 N=8k, d=128 时:
S(注意力得分矩阵)大小为 (8k×8k) = 64M,单精度FP32下占用256MB
P(softmax后矩阵)同样占用 256MB
如果batch size较大,内存需求会更高。
2.3 FlashAttention¶
本文主要讲 FlashAttention 如何优化注意力计算的 前向传播(Forward Pass) 和 反向传播(Backward Pass),主要通过 减少显存访问(Memory IO) 来加速计算并节省存储需求。
2.3.1 Forward pass¶
- 使用 “Tiling” 技术减少显存访问
FlashAttention 通过 分块计算(Tiling),避免存储完整的 S 和 P 矩阵,减少显存传输的开销:
分块加载数据:将 Q、K、V 的一部分加载到高速缓存 SRAM(比 HBM 速度快很多)。
局部计算注意力:只计算该块的 S = QK^T,然后立即执行 Softmax。
计算并更新输出:计算 O = P × V,然后直接更新输出,而不用把 S 和 P 存回 HBM。
- 使用 Online Softmax
由于 Softmax 操作涉及整行的数据计算,因此 FlashAttention 采用 在线 Softmax(Online Softmax)技术来支持分块计算:
- 传统 Softmax:
需要一次性对整行的 S 做 Softmax,需要存整个 S,导致高显存消耗。
- 在线 Softmax:
先对每个块单独计算 Softmax,得到局部归一化的结果。
然后调整每个块的 Softmax 结果,以保证最终结果和全局 Softmax 一致。
- 关键优化点:
避免存储完整的 S 和 P 矩阵,仅存小块数据,提高计算效率。
仅在 SRAM 里处理数据,减少 HBM 访问,加速计算 2-4×。
2.3.2 Backward pass¶
- 问题:标准反向传播的计算和存储开销
在反向传播时,计算梯度 \(\nabla Q, \nabla K, \nabla V\) 需要用到前向传播生成的 S 和 P 矩阵。
但这些矩阵规模是 N × N,存储它们会占用大量显存。
- FlashAttention 解决方案
动态重计算 S 和 P:而不是存储整个 S 和 P,FlashAttention 只在需要的时候重新计算 S 和 P,避免显存占用。
分块计算(Tiling):与前向传播类似,使用 Tiling 来减少数据访问和显存需求。
减少显存消耗 10-20×:
传统方法:存储 O(N²) 大小的 S 和 P,占用大量显存。
FlashAttention:只存储 O(N) 大小的数据,使显存占用从 O(N²) → O(N),大幅减少显存需求。
- 关键优化点:
不存储完整的注意力矩阵 S 和 P,而是在需要时动态重计算,避免显存瓶颈。
通过 Tiling 降低显存访问需求,使反向传播加速 2-4×。
3. FlashAttention-2: Algorithm, Parallelism, and Work Partitioning¶
3.1 Algorithm¶
3.1.1 Forward pass¶
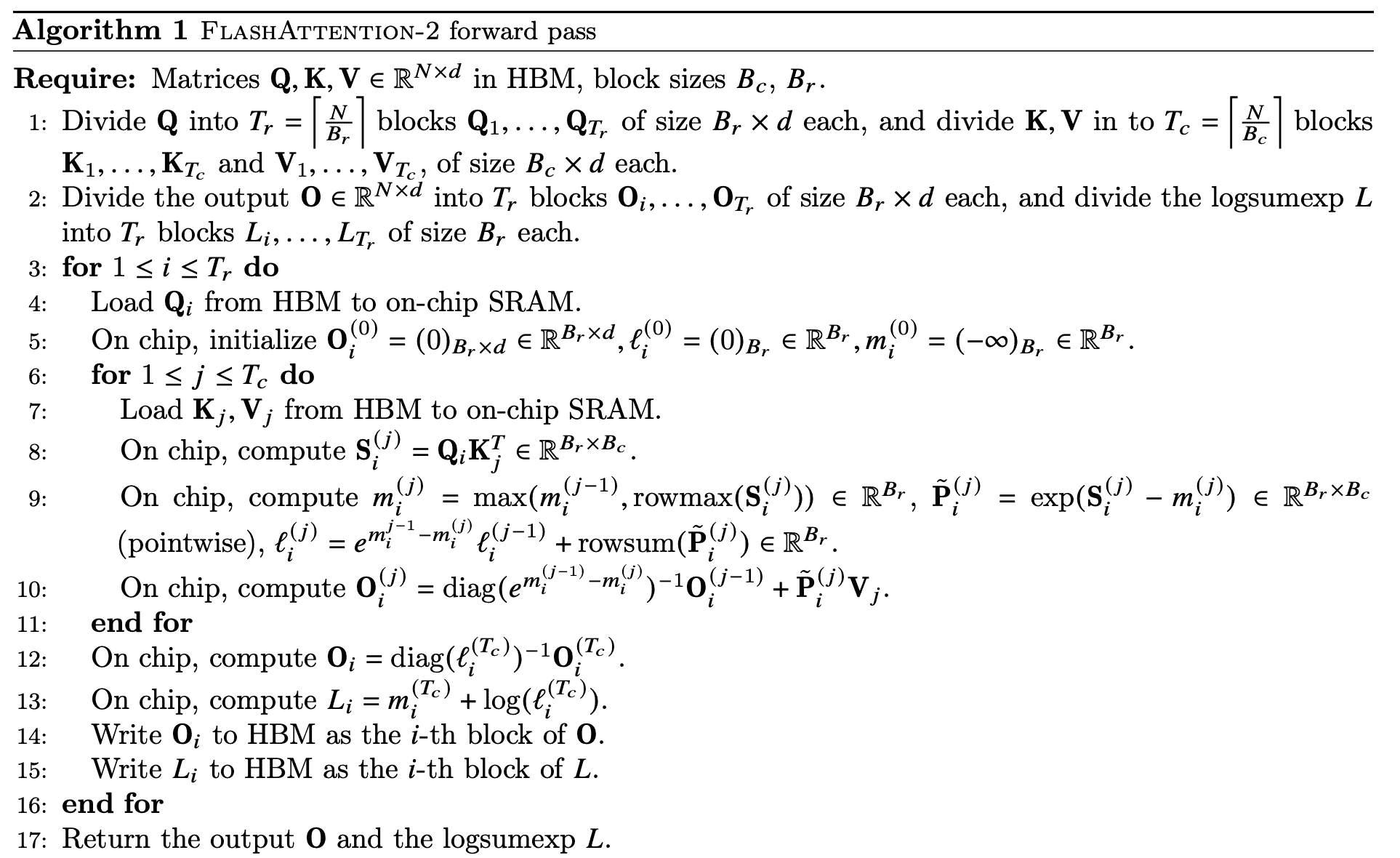
Algorithm 1 FlashAttention-2 forward pass¶
3.1.2 Backward pass¶

Algorithm 2 FlashAttention-2 Backward Pass¶
3.2 Parallelism¶
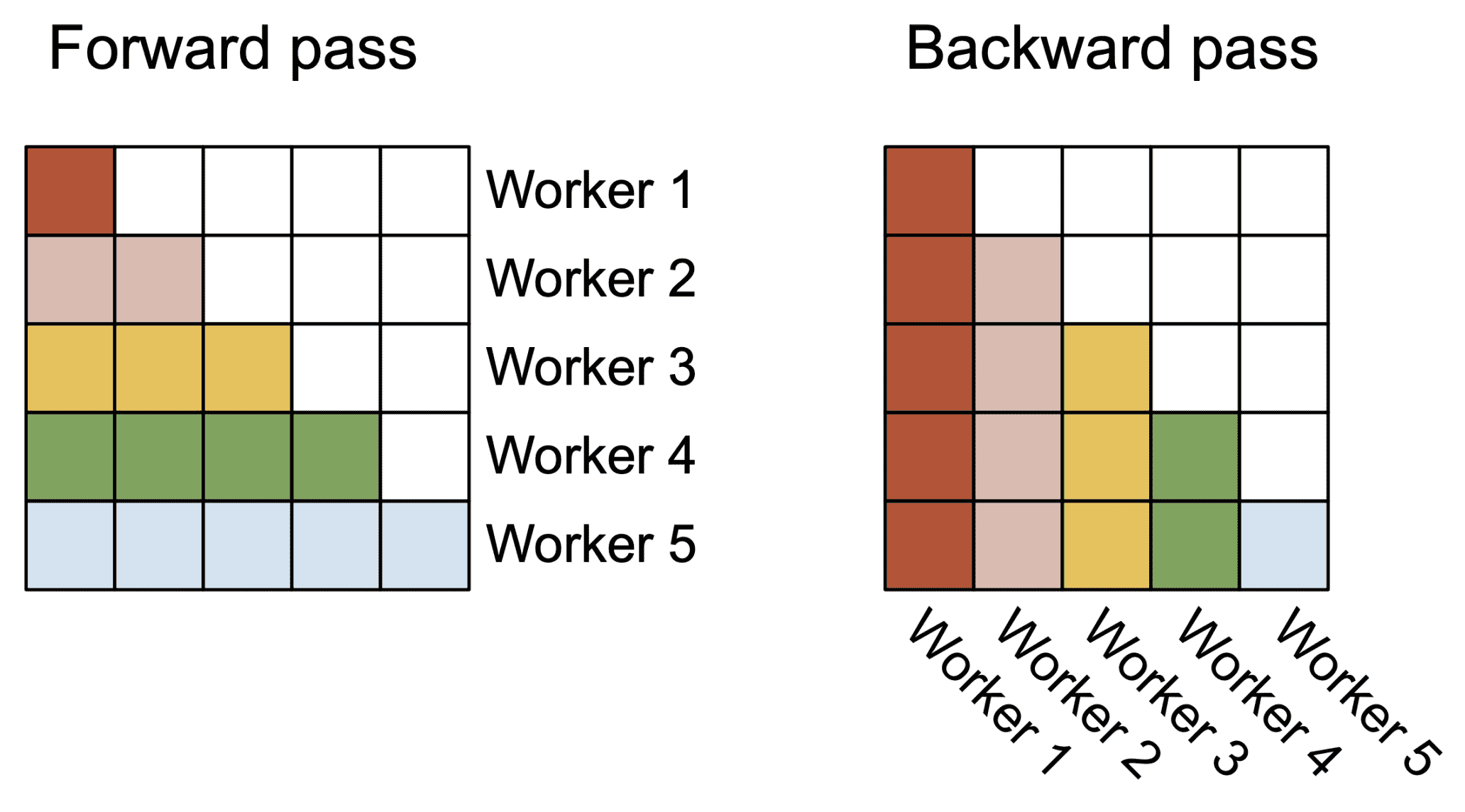
Figure 2: In the forward pass (left), we parallelize the workers (thread blocks) where each worker takes care of a block of rows of the attention matrix. In the backward pass (right), each worker takes care of a block of columns of the attention matrix.¶
3.3 Work Partitioning Between Warps¶
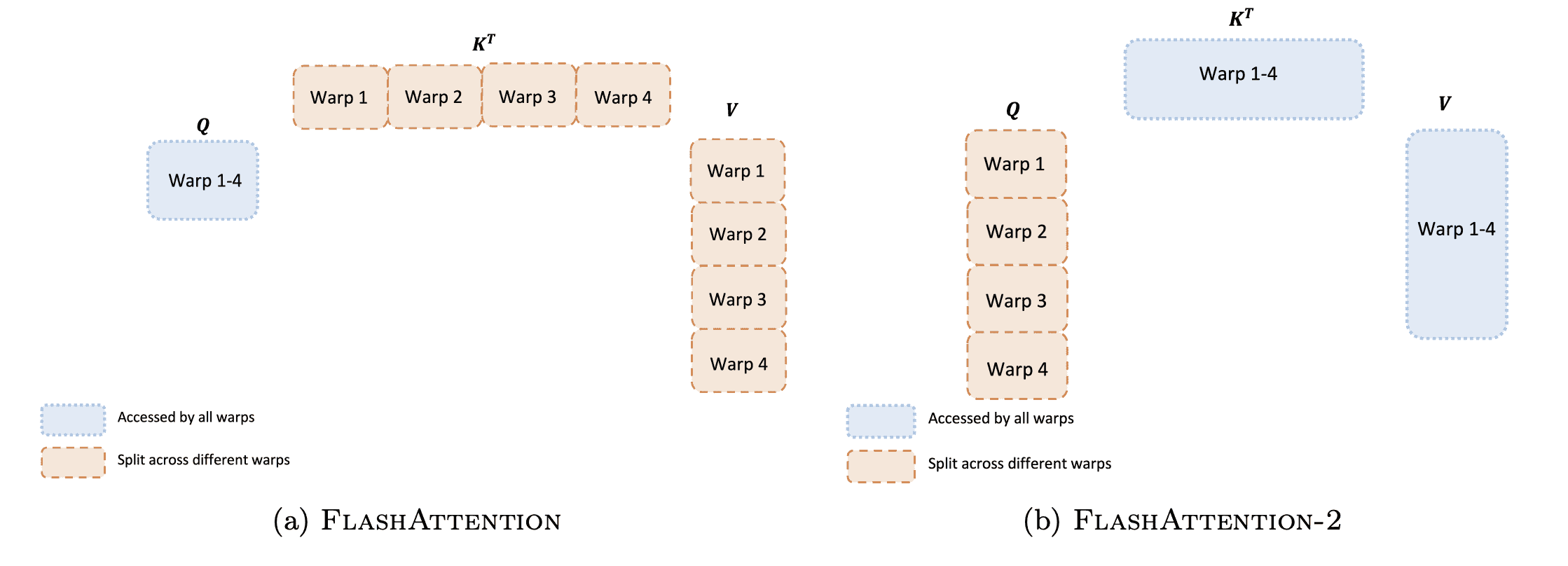
Figure 3: Work partitioning between different warps in the forward pass¶