2205.00159_SVTR: Scene Text Recognition with a Single Visual Model¶
组织: 北交大, 复旦大学, 百度
Abstract¶
背景现状
传统的 场景文本识别(STR)方法 通常由两个模块组成:
视觉模型(用于图像特征提取)
序列建模器(比如 RNN、Transformer,用于字符顺序的建模)
这种“两段式架构”虽然效果好,但 结构复杂,推理效率低,尤其是在移动设备或实时系统中难以部署。
💡 SVTR 的核心创新
SVTR(Single Visual model for Text Recognition):
是一个只有视觉模型的 STR 方法,完全去掉了序列建模器。
它通过图像切片(patch-wise tokenization) 的方式,把输入图像分解成更细的单位进行建模。
🔍 SVTR 的关键机制
把文本图像分成多个小块(patch),每块被称为一个字符组件(character component),粗略对应于一个或多个字符的一部分。
这些小块经过分层处理(hierarchical stages),进行特征混合、融合与整合,逐步构建更高级的表示。
引入了两种混合模块:
Global mixing:识别字符之间的模式(inter-character)。
Local mixing:识别字符内部的细节(intra-character)。
最终获得**多粒度(multi-grained)**的字符理解能力。
最后,只需要一个简单的线性预测层就可以识别字符 —— 完全不需要复杂的语言建模器或解码器。
📊 实验效果
在英文和中文的 STR 任务中都取得了良好效果。
大模型版本 SVTR-L:
在英文任务中准确率与最优方法持平。
在中文任务中大幅超过已有方法。
同时还运行更快。
小模型版本 SVTR-T:
参数少,体积小。
在保持较好准确率的同时,推理速度非常快,适合边缘设备或实时场景。
🎯 总结一句话:
SVTR 通过完全取消序列建模器,提出一种纯视觉、基于 patch 的文本识别方法,在保持高精度的同时显著简化了结构、提升了速度,尤其适合中文识别和轻量化场景。
1. Introduction¶
全面介绍了场景文本识别(STR)的挑战、现有主流方法的演变与局限性,并引出 SVTR 的设计动机和主要贡献。
任务定义与挑战
任务目标:将自然图像中的文本转化为字符序列(如照片中的门牌号、招牌文字等 → 可识别的文本)。
应用意义:这些信息通常包含高层语义(例如地址、品牌名),对场景理解非常重要。
主要挑战:
文本变形(弯曲、旋转)
字体多样
遮挡、背景杂乱等
从方法论上讲,场景文本识别可以看作是从图像到字符序列的跨模态映射。
识别器由两个构建块组成:用于特征提取的视觉模型和用于文本转录的序列模型
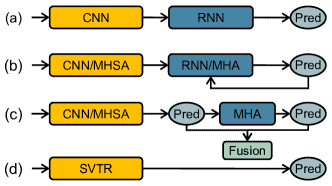
Figure 1:(a) CNN-RNN based models. (b) Encoder-Decoder models. MHSA and MHA denote multi-head self-attention and multi-head attention, respectively. (c) Vision-Language models. (d) Our SVTR, which recognizes scene text with a single visual model and enjoys efficient, accurate and cross-lingual versatile.
主流 STR 方法的架构演变:
CNN-RNN + CTC 模型
CNN 提取图像特征 → reshape 成序列 → BiLSTM 建模 → CTC 预测
优点:结构简单、速度快
缺点:对文本的扭曲、遮挡等敏感
编码器-解码器(Encoder-Decoder)自回归模型
编码图像 → 每次解码一个字符(自回归)
优点:建模上下文,提高准确率
缺点:推理速度慢(逐字符解码)
Vision-Language 模型
融合语言模型(如 BERT)+ 并行预测
优点:上下文理解更强,适合复杂文本
缺点:依赖大模型,推理复杂,速度慢
SVTR 模型(本文提出)
纯视觉模型(Single Visual Model),无需序列建模也无需语言模型
优势:结构简单,速度快,跨语言泛化能力强(可识别中文、英文等)
现有简化架构的尝试及其局限
有些研究尝试在保持精度的前提下简化结构、提升速度:
有的在训练时使用复杂模型,推理时用简单模型(如 PREN2D、VisionLAN)
有的完全依赖 CNN 或 ViT 提取特征,但准确度一般(例如 Borisyuk 和 Atienza 的方法)
作者的核心观点
两种关键能力必须同时具备:
局部细节建模(Intra-character):识别字符的笔画细节
全局依赖建模(Inter-character):建模字符之间的语言关系
问题在于:CNN 擅长局部,但无法建模长距离依赖;而 Transformer 虽然能建模长依赖,但对局部特征不够敏感。
SVTR 的设计理念与技术细节
核心思想:
借鉴 Vision Transformer(ViT)的成功经验,SVTR 把一张图像分割成许多小块(patches),称为 character components。
每个 patch 并不一定是一个完整字符,可能只是字符的一部分 —— 更细粒度。
然后对这些 patch 进行 tokenization(转为 token)+ 自注意力(self-attention),捕捉字符之间的局部和全局线索。
特定设计(“text-customized”):
构建了一个三阶段(three-stage)、高度逐步降低的骨干网络(backbone)。
每个阶段都有:
局部与全局混合块(local & global mixing blocks),反复使用
合并或组合操作(merging/combining)
这种结构让模型可以同时捕捉:
字符局部的 stroke-like 特征(例如笔画)
字符之间的长期依赖关系(long-term dependencies)
整体上形成了 多尺度(multi-scale) 和 多粒度(multi-grained) 的特征感知能力,有利于识别各种语言、字体或模糊图像中的文字。
论文贡献总结(三点)
首次证明:一个纯视觉模型(无语言模型、无序列模型)可以在场景文本识别中达到甚至超过 SOTA 性能。
提出 SVTR 架构:专为文本识别设计的混合结构,能建模局部细节和字符依赖关系。
大量实验验证其有效性:尤其在中文任务上优于现有所有方法,小模型也兼顾速度和效果。
总结
SVTR 是一种无需序列模型或语言模型、基于 patch-token 的纯视觉文本识别架构,通过局部和全局混合模块构建强大的字符感知能力,在多个语言场景下实现高精度和高效率的统一识别。
2. Method¶
2.1 Overall Architecture¶
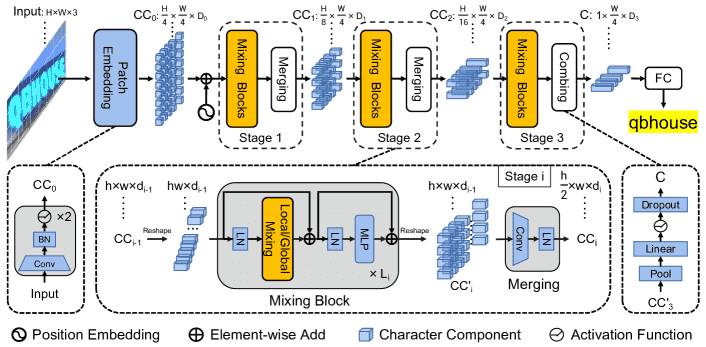
Figure 2:Overall architecture of the proposed SVTR. It is a three-stage height progressively decreased network. In each stage, a series of mixing blocks are carried out and followed by a merging or combining operation. At last, the recognition is conducted by a linear prediction.
整体架构设计:
输入:图像尺寸为 \(H \times W \times 3\)。
第一步:将图像分成大小为 \(\frac{H}{4} \times \frac{W}{4}\) 的 patch,每个 patch 是一个子区域,称为“字符组件(character components)”,每个 patch 可能只包含一个字符的一部分。
特征提取:整个网络被分成 三个阶段(three stages),每个阶段都包含多个 Mixing Block,后接一个 merge/combine 操作,目的是在不同尺度上提取局部和全局特征。
输出:输出特征为 \(1 \times \frac{W}{4} \times D_3\),表示一维序列形式的多尺度字符特征。
识别过程:通过一个简单的 并行线性预测模块 直接输出字符序列,去重后得到最终文本结果。
📌 重点:整个识别过程完全不依赖语言模型或 RNN,只依靠一个视觉模型完成识别,简单高效。
2.2 Progressive Overlapping Patch Embedding¶
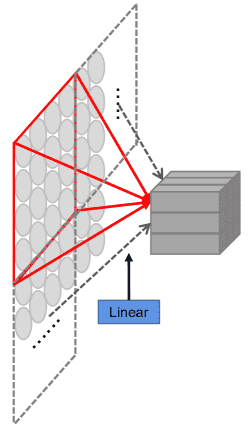
Figure 3:(a) The linear projection in ViT Dosovitskiy et al. (2021). (b) Our progressive overlapping patch embedding.
如何将输入图像转换为字符组件 patch:
传统方法通常是一次性用 4×4 的投影或 7×7 的卷积直接降采样(图 3a)
SVTR 方法使用 两次stride为2的 3×3 卷积 + BN(batch normalization)(图 3b),逐步减少图像尺寸,同时逐步提高特征维度,有助于后续的特征融合。
虽然略微增加计算量,但这种渐进式方式在实验中效果更好
📌 重点:选择渐进式嵌入,是为了更好地保留字符局部细节与结构信息。
2.3 Mixing Block¶

Figure 4:Illustration of (a) global mixing
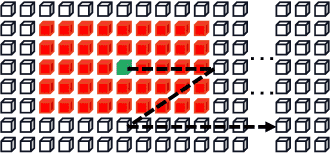
Figure 4:Illustration of (b) local mixing.
字符识别需要关注两个层面的信息:
局部模式:例如字符的笔画结构,这些特征用于区分相似字符。
全局依赖:字符之间的上下文关系、文本与背景的差异等。
SVTR 设计了两个互补的模块:
Global Mixing(全局混合)
全局处理图像中所有组件之间的依赖关系,包括字符与背景、字符之间的长距离关系。
实现方法:LayerNorm → Multi-head Self Attention(MHSA)→ LayerNorm → MLP → 残差连接(如标准 Transformer)。
优点:可以增强字符之间的关联性,抑制非文字区域的干扰。
Local Mixing(局部混合)
在每个字符组件的 局部窗口(7×11) 内进行自注意力运算,模仿 CNN 的滑窗方式。
目的:提取字符的笔画特征,理解字符形态结构。
类似于“局部注意力机制”,对字符本身细节更敏感。
在 SVTR 的每一阶段中,这两种 Mixing Block 会重复交替使用,以充分学习局部结构和全局上下文,形成丰富、层次化的特征表达。
📌 重点:局部混合提笔画,全球混合提上下文,互为补充,组合提特征。
备注
SVTR 用“渐进式 patch 嵌入 + 局部与全局混合模块”构建了一个不依赖语言模型、纯视觉模型的文本识别系统,能高效而准确地识别包括中文在内的多语言场景文字。
2.4 Merging¶
目的:
降低计算成本,并避免冗余特征表示。
做法:
每一阶段结束后(除了最后一阶段),对特征图进行“合并”操作。
输入的特征是 shape 为
h × w × d_{i-1}。先用一个 3×3 卷积,高度方向步长为 2,宽度方向步长为 1。
作用效果是将高度
h减半(变为 h/2),宽度w不变,同时通道数从d_{i-1}增加到d_i。
2.5 Combining and Prediction¶
最后一阶段的处理方式,与前面的 merging 不同。
Combining(组合)操作:
不再用卷积,而是先把高度方向池化为 1。
然后通过一个全连接层(FC)、激活函数、dropout处理,变成一个新的 feature sequence。
每个元素的特征长度是
D_3。
为什么这么设计:
因为此时特征图高度已经很小,再用卷积效率很低,甚至可能失效。
用池化 + FC 更简单直接。
Prediction(预测)操作:
采用并行的线性分类器进行字符识别。
预测结果是长度为
W/4的字符序列。同一个字符的多个组件,可能会预测出重复字符。
非文本区域可能预测为 “空白”符号。
最终使用 去重合并(de-duplication) 得到最终文本。
输出分类数(N):
英文设置为 37(26 字母 + 数字 + 特殊符号 + blank)。
中文设置为 6625。
2.6 Architecture Variants¶
定义了四种规模的版本:Tiny、Small、Base、Large。
名称 |
通道数 |
每阶段的 Mixing Block 数 |
每阶段注意力头数 |
最终通道 D3 |
Mixing Block 排列 |
参数量 (M) |
FLOPs (G) |
|---|---|---|---|---|---|---|---|
SVTR-T |
[64,128,256] |
[3,6,3] |
[2,4,8] |
192 |
L6 + G6 |
4.15M |
0.29G |
SVTR-S |
[96,192,256] |
[3,6,6] |
[3,6,8] |
192 |
L8 + G7 |
8.45M |
0.63G |
SVTR-B |
[128,256,384] |
[3,6,9] |
[4,8,12] |
256 |
L8 + G10 |
22.66M |
3.55G |
SVTR-L |
[192,256,512] |
[3,9,9] |
[6,8,16] |
384 |
L10 + G11 |
38.81M |
6.07G |
其中:
Lx表示使用多少次 Local Mixing。Gx表示使用多少次 Global Mixing。
核心思想:
分层设计:通过合并高度 + 保持宽度,建立文字友好的层级结构。
双重注意力模块:Local Mixing 捕捉笔画,Global Mixing 捕捉字符之间关系。
最终识别策略:直接用线性分类器并去重,非常高效。
灵活可调:支持从轻量级到高精度的多种架构。
3. Experiments¶
3.1 Datasets¶
英文识别任务使用了两个合成数据集来训练模型:
MJSynth (MJ) 和 SynthText (ST),都是生成的合成文字图像数据集。
测试数据集包含6个公开英文文本识别基准:
ICDAR 2013 (IC13):初始有1095张,去除一些无效图像后剩857张。
SVT:Google 街景图像,647张,很多图像有严重的模糊和噪声。
IIIT5K:网页收集图像,共3000张测试图。
ICDAR 2015 (IC15):用 Google Glass 拍摄,图像有很多角度和聚焦问题,本实验使用1811张版本。
SVTP:带有透视变形的街景图像,共639张。
CUTE80 (CUTE):用于识别曲线文本,包含288张测试图像。
中文识别任务:
使用了 Chinese Scene Dataset,分别有约50万张训练图、6.3万张验证图、6.3万张测试图。
3.2 Implementation Details¶
使用 SVTR模型,训练前先通过一个文字矫正模块(Shi et al., 2019)对图像做预处理,将图片缩放为
32×64。优化器:使用 AdamW,权重衰减为 0.05。
英文模型:
学习率初始化为
5e-4 * batch_size / 2048。使用 cosine 学习率衰减,前2个 epoch 线性 warm-up,训练共21个 epoch。
使用多种数据增强(旋转、透视变形、模糊、噪声)。
最大预测长度设为25,覆盖大多数英文单词长度。
中文模型:
学习率初始化为
3e-4 * batch_size / 512。warm-up 5个 epoch,训练100个 epoch。
不使用数据增强。
最大预测长度设为40。
使用 PaddlePaddle 框架,4张 Tesla V100 GPU 训练。
评估指标:词准确率(word accuracy)。
3.3 Ablation Study¶
通过有针对性的消融实验( Patch Embedding、合并策略、模块排序)验证了其各个模块的设计是合理且有效的,尤其擅长处理扭曲或不规则文本的识别任务。
对比三种嵌入方式(Patch Embedding):
Linear:最普通的嵌入方式。
Overlap:带有重叠的窗口嵌入。
Ours(作者自定义的渐进式嵌入):效果最好,平均提升 0.75%(IC13)和 2.8%(IC15)。
结论:作者的渐进式嵌入方式在处理不规则文本(IC15)时尤其有效。
对比两种策略:
None:不进行特征图降采样(保持相同的空间分辨率)。
Prog(Progressive):在网络中逐渐降低分辨率。
结论:降采样不仅提升精度,还降低计算开销(FLOPS),说明“在高度方向上进行多尺度采样”是识别文本特别是复杂文本的关键。
对比不同排列方式:
None:不使用 Mixing Block,性能最差(IC13:91.6,IC15:68.2)
[G]6[L]6:先用 6 层全局混合,再用 6 层局部混合
[L]6[G]6:先局部再全局(最优方案)
[GL]6 或 [LG]6:交替组合
说明: Mixing Block 是 SVTR 用于捕捉局部与全局特征的重要模块。有两种类型:
L(Local Mixing Block):局部特征提取
G(Global Mixing Block):全局建模能力
3.4 Comparison with State-of-the-Art¶
核心结论是:一个纯视觉模型,只要特征提得好,就能有效完成文字识别任务。
总结:
无需语言模型,仅靠视觉模块就能应对中英文复杂文字识别;
注意力可视化证明模型真正理解了字符结构与上下文关系。
3.5 Visualization Analysis¶
结论
SVTR-L 具有准确、快速和多功能的优点,在以精度为导向的应用中是一个极具竞争力的选择
虽然 SVTR-T 是一种有效且体积小得多的模型,但速度相当快。它在资源有限的情况下很有吸引力。
4. Conclusion¶
提出了一个新模型,叫做 SVTR,专门用于处理图片中的文字识别任务(scene text recognition,简称 STR)。
SVTR 不只看单个字母/字符的局部笔画(stroke-like patterns),还可以理解字符之间的结构关系(inter-component dependence),比如文字之间的上下文信息。
“multi-grained” 表示特征具有不同层次、尺度;“multiple height scales” 则暗示模型在竖直方向上有更强的鲁棒性和感知能力,适合处理不同排版或字体变化。
SVTR 可以不借助语言模型或后处理,单靠视觉信息就能完成识别,并且效果很好,不仅快而且适用于多种语言。
模型不仅准确率高,还跑得快,比其他 SOTA 方法更高效。
总结(简洁版):
提出了 SVTR 模型,能够同时识别字符笔画和字符之间的依赖关系,实现了在不同语言和场景下都表现优异的文字识别性能。
该模型可以在不依赖语言模型的前提下实现高精度、快速度,并适配不同计算资源。实验验证其在英文和中文数据集上均优于其他先进方法,具有广泛的应用潜力。