2402.04615_ScreenAI: A Vision-Language Model for UI and Infographics Understanding¶
组织: Google DeepMind
GoogleScholar(star: 51)
Abstract¶
ScreenAI——一个专门用于理解用户界面(UI)和信息图(infographic)的视觉-语言模型。它主要解决UI和信息图相关的任务,比如界面元素识别、问答(QA)、导航和摘要等。
- 主要内容解析:
- UI和信息图的作用
UI和信息图共享相似的视觉语言和设计原则,在人类交流和人机交互中扮演重要角色。
- ScreenAI 的创新点
改进模型架构:基于 PaLI(Pathways Language and Image model) 进行优化,并结合了 pix2struct 的灵活 patching 策略(即将界面划分成更合适的图像块来处理)
训练数据集:使用了一个独特的数据集组合,其中包含一个新的 屏幕标注任务(screen annotation task),要求模型识别 UI 元素的类型和位置
自动生成训练数据:通过这些文本标注,让大语言模型(LLM)理解屏幕信息,并自动生成大规模的QA、UI导航、摘要等任务数据
- 实验验证
进行了消融实验(ablation studies),分析不同设计决策对模型表现的影响。
仅 50 亿参数(5B parameters),但达到了多个任务的 SOTA(State-of-the-Art, 最先进性能):
UI 和信息图相关任务:Multipage DocVQA, WebSRC, MoTIF
其他任务的最佳表现(best-in-class):ChartQA, DocVQA, InfographicVQA
对比相似规模的模型,ScreenAI 在多个任务上表现优越。
- 发布新数据集
一个专注于屏幕标注任务的数据集
两个专注于问答(QA)任务的数据集
- 关键点总结:
ScreenAI 是一个专门理解 UI 和信息图的视觉-语言模型,改进了现有的 PaLI 架构并结合了 pix2struct。
其核心创新点是屏幕标注任务,可以识别 UI 元素的类型和位置,并用文本描述屏幕内容,从而大规模自动生成 QA、导航、摘要等训练数据。
在多个任务上达到了 SOTA 级别,特别是在 UI 和信息图任务中表现突出。
公开了三个新数据集,促进 UI 和信息图理解领域的发展。
1. Introduction¶
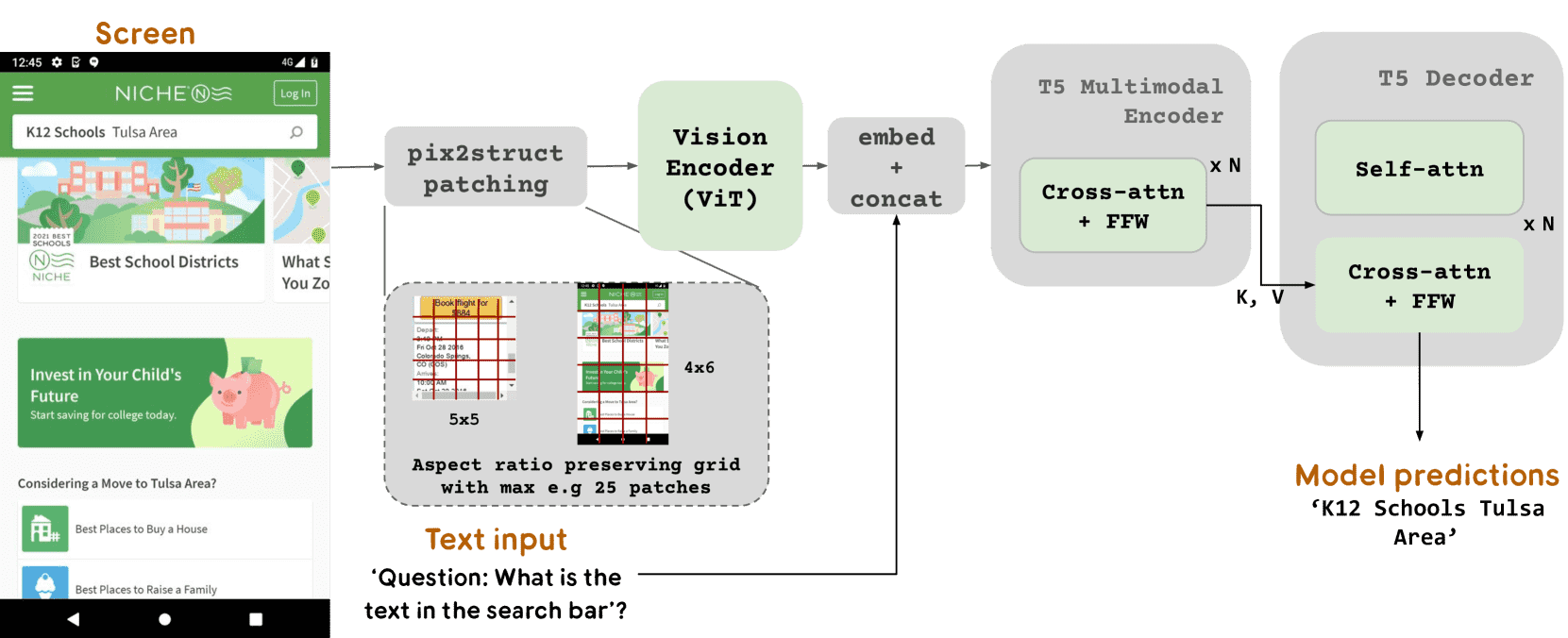
Figure 1: The overall architecture of our model. The model contains an image encoder followed by a multimodal encoder consuming embedded text and image features. The output of the multimodal encoder is fed to an autoregressive decoder to generate the final text output. This figure also illustrates pix2struct patching, where the grid size adapts to the aspect ratio and shape of the image.¶
本章主要介绍了 ScreenAI 的目标、架构、创新点、以及与相关工作的对比。
- 论文背景
信息图(Infographics)(如图表、地图、表格、文档布局等)在数据可视化和人机交互中至关重要。
现代 UI(用户界面)(如移动端和桌面端的界面)与信息图共享相似的视觉语言和设计原则,提供了交互性更强的用户体验。
挑战:由于 UI 和信息图的复杂性,开发一个能同时理解和推理 UI 与信息图的统一模型是一项挑战。
- ScreenAI 的核心创新
为了解决 UI 和信息图的理解问题,论文提出了 ScreenAI,一个专门用于 UI 和信息图理解的视觉-语言模型(VLM)。
- 1)模型架构
图像编码器(Image Encoder):负责处理 UI 或信息图,并提取视觉特征。
多模态编码器(Multimodal Encoder):结合图像特征和嵌入的文本特征,以支持跨模态理解。
自回归解码器(Autoregressive Decoder):生成最终的文本输出(如 UI 元素的描述、问答答案等)。
Pix2Struct Patch 机制:自适应网格尺寸(grid size),使模型能更好地处理不同尺寸和比例的 UI 和信息图。
- 2)主要贡献
ScreenAI 作为一个统一的 VLM:专门针对 UI 和信息图进行理解,充分利用二者相似的视觉语言和设计原则。
引入 UI 的文本表示:使模型在预训练过程中学习如何理解 UI 结构。
利用 UI 表示和大语言模型(LLM)自动生成大规模训练数据,降低人工数据标注成本。
设计了预训练和微调任务集合,覆盖 UI 和信息图的多个理解任务(如QA、导航、摘要、元素标注)。
- 发布了 3 个新数据集,包括:
Screen Annotation(屏幕标注)
ScreenQA Short(短文本 QA)
Complex ScreenQA(复杂 QA)
- 3)关键成果
模型规模:4.6B(46 亿参数),但在多个基准测试中超越比它大 10 倍的模型。
在 4 个公开的信息图 QA 基准测试中取得了 SOTA(State-of-the-Art, 最佳)性能。
其他任务上达到最佳或接近最佳的表现。
随着模型规模增大,性能显著提升(表明未来可进一步扩展)。
- 相关工作
- 1)屏幕 UI 相关模型
过去的大部分 UI 研究聚焦于特定任务,如:
图标检测(icon detection)
UI 元素识别(UI element detection)
UI 结构分析
屏幕摘要(screen summarization)
单步导航任务(single-step navigation)
近年来,结合 LLM 进行 UI 分类和任务执行的研究逐渐兴起。
- 2)通用基础模型(Generalist Foundation Models)
近年来,多模态大模型(如 PaLI、Flamingo、OFA、UniTAB)能够执行图像理解相关任务(问答、图像字幕、目标检测等)。
Pix2Seq 是一个类似的方法,将目标检测问题转换为文本预测任务。
- 3)高效视觉-语言模型
其他文档和 UI 相关的多模态 Transformer 研究:
LayoutLMv3、Donut、Pix2Struct、UDOP、MatCha、Spotlight
VuT(Vision-Understanding Transformer):结合多模态编码器+文本解码器+目标检测任务头。
其他 UI 研究:
UIBert、DocLLM 结合 UI 结构信息进行文本理解(基于 DOM 结构或 OCR 提取)。
- ScreenAI 创新点:
过去的模型大多专注于单一领域(如网页 UI、移动 UI),ScreenAI 的表示方式则通用于多个领域(如 UI、信息图、文档等)。
通过 跨领域(屏幕、文档、信息图)联合训练,ScreenAI 在多个任务上取得更优性能。
- 结论
ScreenAI 是目前 UI 和信息图理解的最佳 VLM 之一,在多个任务上达到了 SOTA 级别。
其创新点在于 UI 的文本表示、自动训练数据生成、以及跨领域联合训练。
未来可以通过扩大模型规模,进一步提升性能。
- 总结
ScreenAI 是一个多模态模型,专门用于 UI 和信息图理解,其架构结合了PaLI 和 Pix2Struct,并使用自适应 patching 机制。
模型关键任务包括:问答(QA)、元素标注、导航、摘要等。
自动生成训练数据:利用 UI 的文本表示+LLM,大规模构造训练集。
性能卓越:比 10 倍大的模型表现更好,在多个 UI 和信息图任务上达到 SOTA。
未来方向:进一步扩展模型规模,可能会带来更大提升。
2. Methodology¶
本章主要讲了 ScreenAI 这个模型的架构、配置和训练方法。
2.1 Architecture¶
- ScreenAI 的架构借鉴了 PaLI(Pathways Language and Image)系列模型:
采用 ViT(Vision Transformer) 作为图像编码器,将输入图像转换成嵌入向量。
采用 mT5(Multilingual T5) 作为语言编码器,将文本输入转化成嵌入向量,并和图像嵌入拼接后送入多模态编码器。
使用 自回归解码器(autoregressive decoder),把多模态编码器的输出生成最终的文本输出。
- 不同于 PaLI 只能使用固定网格切割图像(固定 patch 方案),ScreenAI 采用了 Pix2Struct 提出的灵活 patch 机制:
允许根据输入图像的 形状和比例 调整 patch 方案,而不是强制调整图像大小(避免 padding 或拉伸)。
适用于 手机(竖屏)和桌面(横屏) 等不同 UI 格式,增强泛化能力。
2.2 Model Configurations¶

Table 1: Model variants and details of their parameter counts and split among vision and language models.(ScreenAI 训练了 三种规模的模型)¶
小型模型(670M 和 2B)基于预训练的单模态(unimodal)模型进行初始化,即 图像编码器 和 文本编码-解码器 先分别训练过。
5B 规模的模型使用了 PaLI-3 的多模态(multimodal)预训练权重,意味着 ViT 和 UL2 编码-解码器 之前就联合训练过。
2.3 Stages of Training¶
- 预训练(Pre-training)
目标:让模型适应 UI 和信息图表(Infographics) 的理解任务。
- 数据来源:
自监督学习 生成的大规模数据(自动标注)。
少量人工标注 以提升数据质量。
LLM 生成数据,扩展任务覆盖面。
- 训练策略:
先训练 ViT 和语言模型,让视觉编码器适应 UI 相关数据。
后期 冻结 ViT 编码器,减少计算成本,只优化语言模型。
- 微调(Fine-tuning)
- 目标:优化特定任务,如:
UI 组件标注
信息图表问答
UI 导航
文本摘要
- 策略:
先用 多个 QA 任务混合训练 提升泛化能力。
再对每个具体任务进行 单独微调,提升针对性效果。
- 总结
ScreenAI 采用 PaLI 结构,并引入灵活的图像 patch 机制,以适应各种 UI 和信息图表的输入格式。
模型有三种规模(670M、2B、5B),较大模型基于 PaLI-3 预训练,性能更强。
- 训练分为预训练和微调:
预训练阶段使用自监督和 LLM 生成的数据,使模型适应 UI 相关任务。
微调阶段针对具体任务进行优化,并且采用 先泛化再精调 的策略。
3. Automatic data generation¶
本章主要介绍了 ScreenAI 的自动数据生成方法,主要解决 如何构造多样化、高质量的大规模数据集 以用于模型预训练。
- 核心思想
- 自动化数据标注(Screen Annotation)
获取 UI 界面截图(来自桌面、移动端、平板等设备)。
使用 DETR(DEtection TRansformer)模型检测 UI 组件(如图片、图标、按钮、文本等)。
使用 OCR 提取文本 并结合 UI 组件信息,形成 完整的界面描述(Screen Schema)。
生成 UI 任务数据,供 LLM 进一步扩展。
- 利用 LLM 生成更多任务(Task Generation using LLMs)
先利用 PaLM 2-S 生成界面结构信息(Screen Schema)。
再基于这个结构 自动生成问答对(QA Pairs) 和任务数据。
人工审核一部分数据,确保质量符合标准。
3.1 Screen Annotation¶

Figure 2: Task generation pipeline: 1) the screens are first annotated using various models; 2) we then use an LLMs to generate screen-related tasks at scale; 3) (optionally) we validate the data using another LLM or human raters.¶
目标: 让模型理解 UI 组件的层次结构和关系。
- 获取界面截图
通过 爬取应用和网页(来自桌面、移动端、平板)。
目标是覆盖不同 UI 风格,提高数据多样性。
- 界面组件检测
使用 DETR 目标检测模型 识别 UI 组件:
组件类别:IMAGE、PICTOGRAM、BUTTON、TEXT 等。
相比传统分类器(如 Li et al. 2022),DETR 直接预测 边界框 + 类别,而不依赖候选框。
- 图标分析
采用 Sunkara et al.(2022)图标分类器,识别 77 种 图标类型。
未识别的图标,用 PaLI 图像字幕模型 生成描述信息。
- OCR 文本提取
识别界面上的文本,并与 UI 组件信息结合,形成 完整的界面描述(Screen Schema)。
结合 边界框信息,确保空间布局关系得到保留。
- Screen Schema
- 这是一个 结构化的界面描述,包含:
UI 组件
位置坐标
文本内容
作为预训练任务之一:让模型从输入的 UI 界面 自动生成 Schema,以提高其对 UI 结构的理解能力。
- Screen Schema 还能用于 LLM 交互
LLM 处理 UI 任务时,可以使用 结构化的 Screen Schema,提高上下文理解能力。
- 例如:
生成 UI 导航说明
推理用户意图
QA 任务
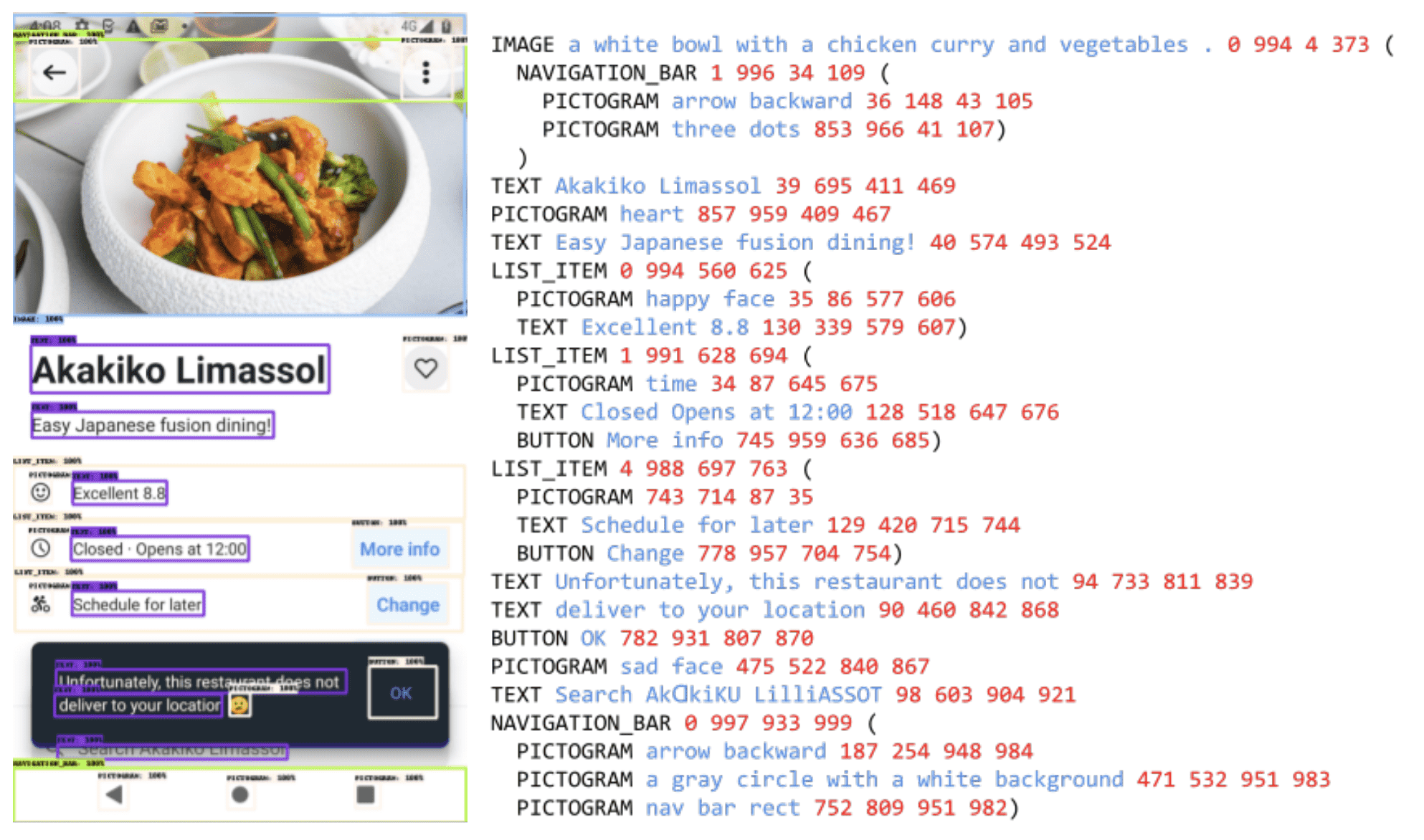
Figure 3:Example of our screen schema. See Appendix B for more.¶
3.2 LLMs to Generate Additional Tasks¶
目标: 扩展数据集,提高任务多样性。
- 两步生成任务数据
第一步:用 PaLM 2-S 生成 界面结构(Screen Schema)。
第二步:基于 Schema,自动生成任务数据(如问答对)。
这个过程 依赖 Prompt Engineering,需要反复优化 Prompt 才能得到理想的任务数据。
总结¶
ScreenAI 采用自动数据生成策略,利用小模型和 LLM 生成 多样化、高质量 的数据。
界面截图 + DETR 目标检测 + OCR 提取文本,形成 结构化的 UI 界面描述(Screen Schema)。
Screen Schema 作为训练任务,让模型学会 自动理解 UI 结构。
利用 LLM(PaLM 2-S)生成 UI 任务数据(如 QA 对),并进行人工质量审核。
这套方法确保了 ScreenAI 在 UI 任务上的泛化能力,能处理不同设备和屏幕格式,提高对用户界面的理解和交互能力。
4. Data Mixtures¶
本章主要介绍了一种名为 ScreenAI 的视觉语言模型(Vision-Language Model, VLM),用于 用户界面(UI)和信息图表(Infographics)理解。
文中重点介绍了 训练数据的组成,分为 预训练(pretraining) 和 微调(fine-tuning) 两个阶段,以及模型在不同基准测试(benchmarks)上的表现。
本章介绍了 ScreenAI 的训练方法,强调 大规模自监督学习 和 针对特定任务的微调。该模型主要用于 UI 和信息图的理解,训练数据覆盖多种 UI 解析任务,并在多个基准测试中表现优越,具备广泛的应用价值。
4.1 Pretraining Mixture¶
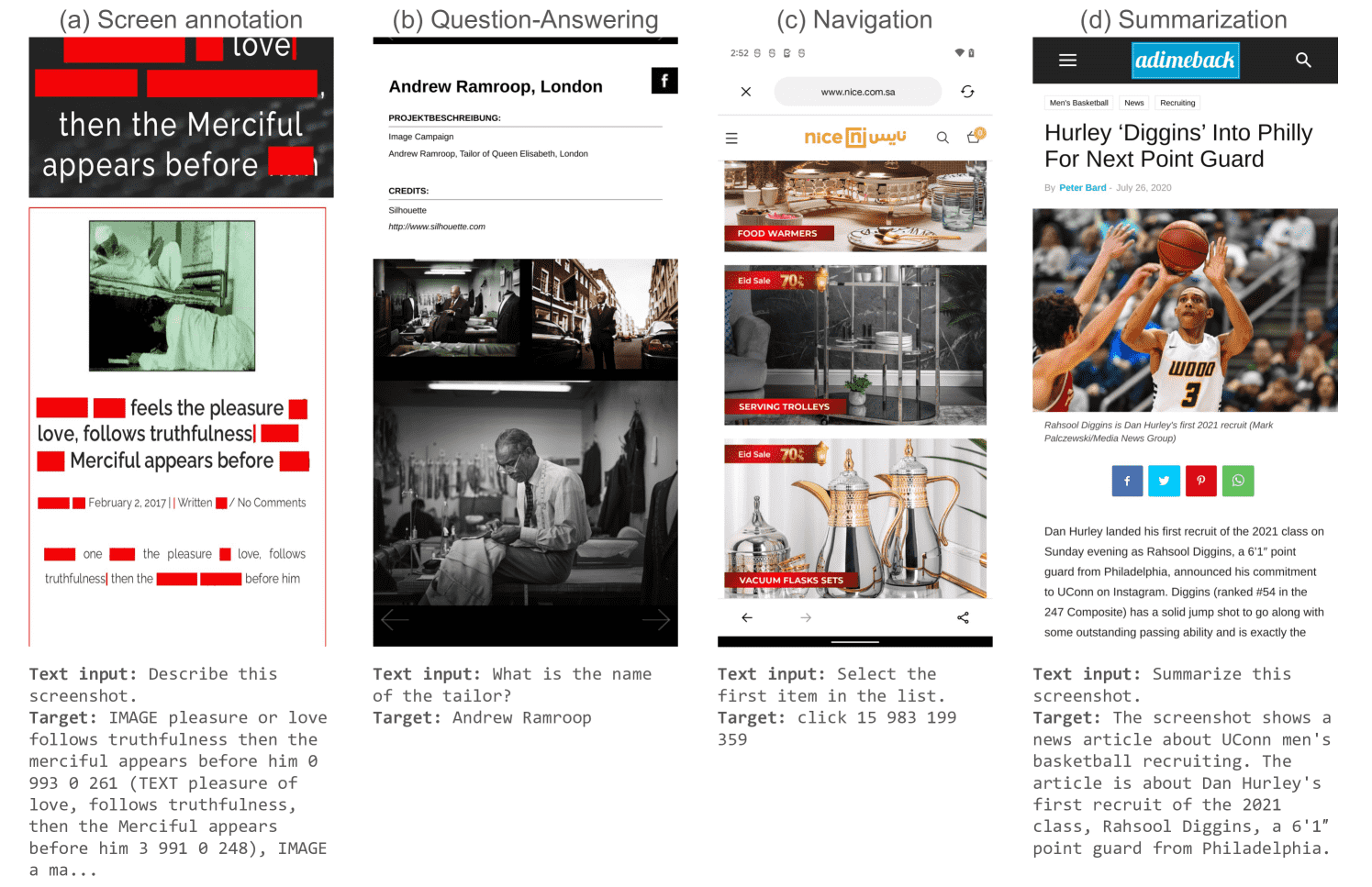
Figure 4: Sample of tasks that we are using in our pretraining mixture: (a) Screen annotation with masking; (b) Question-Answering; (c) Navigation; (d) Summarization. The last three have been generated using our screen annotation model, coupled with PaLM-2-S.¶
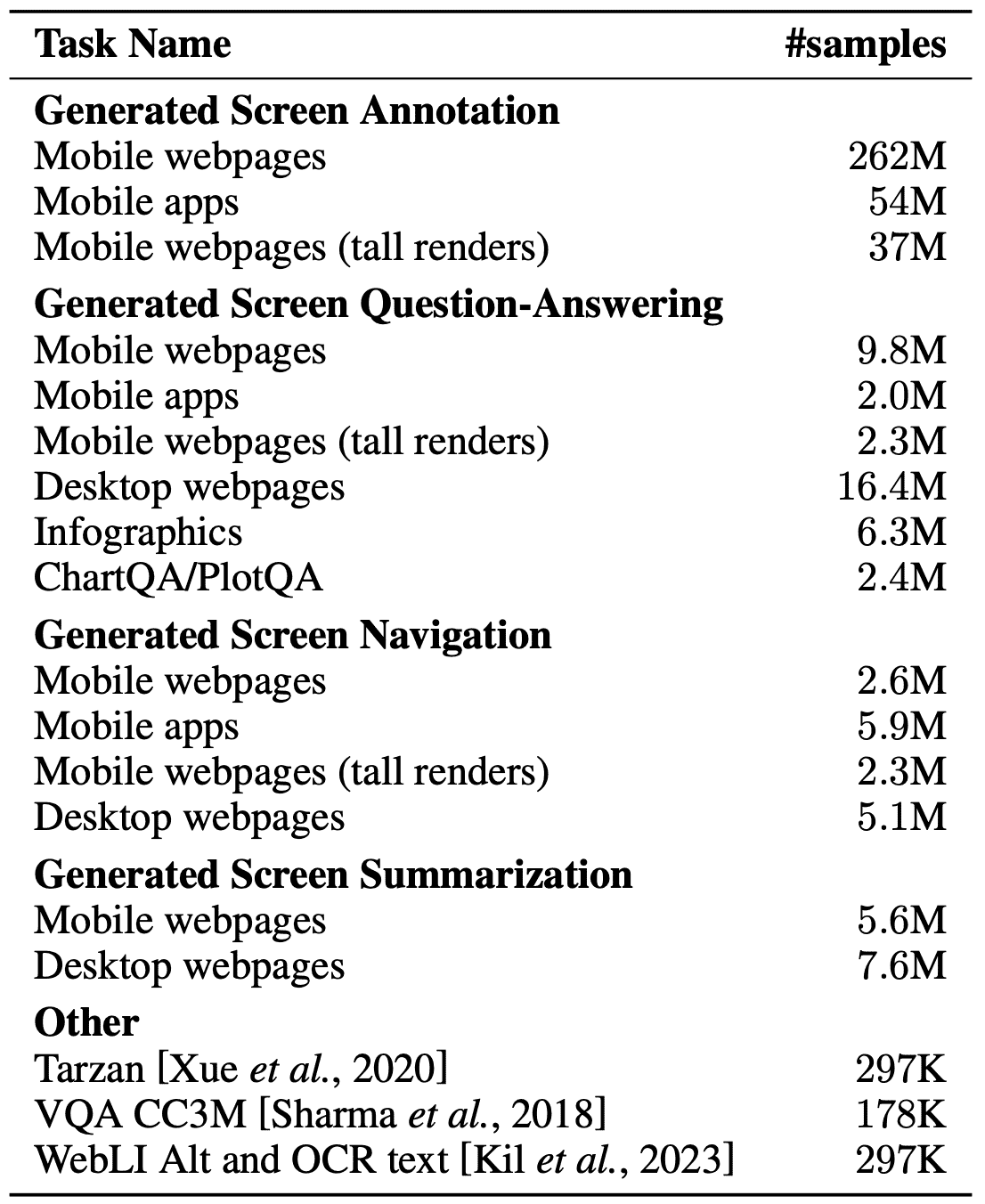
Table 2: Detailed breakdown of our pretraining mixture.¶
这些任务的目的是让模型具备多种能力,以应对不同的现实场景。
- 屏幕标注(Screen Annotation)
任务:识别 UI 界面上的元素(OCR 识别、图像描述等)。
重点:屏幕上部分文本被遮挡,迫使模型利用上下文推理缺失信息。
- 屏幕问答(Screen QA)
任务:回答关于 UI 界面或信息图表的相关问题。
额外挑战:涉及算术、计数、复杂图表等,需增强模型的能力。
- 屏幕导航(Screen Navigation)
任务:理解用户导航指令,如 “返回上一页”,并找到正确的 UI 元素(输出目标 UI 元素的边界框坐标)。
- 屏幕摘要(Screen Summarization)
任务:用一两句话总结屏幕内容,考察模型的压缩信息能力。
- 补充数据
- 额外的数据集用于训练模型的多模态能力,如:
图表到表格翻译(Chart-to-Table Translation)
VQA(Visual Question Answering)数据
WebLI(网页文本与图像数据)
4.2 Fine-Tuning Tasks and Benchmarks¶
- 微调任务的主要目标:
使模型在 UI 解析、问答、导航、摘要 等具体任务上精调,并达到更高的性能。
- 评估基准测试包括:
Screen Analysis(屏幕分析)
Screen QA(屏幕问答)
Screen Navigation(屏幕导航)
Screen Summarization(屏幕摘要)
信息图问答(Infographic VQA)
文档问答(Doc VQA)
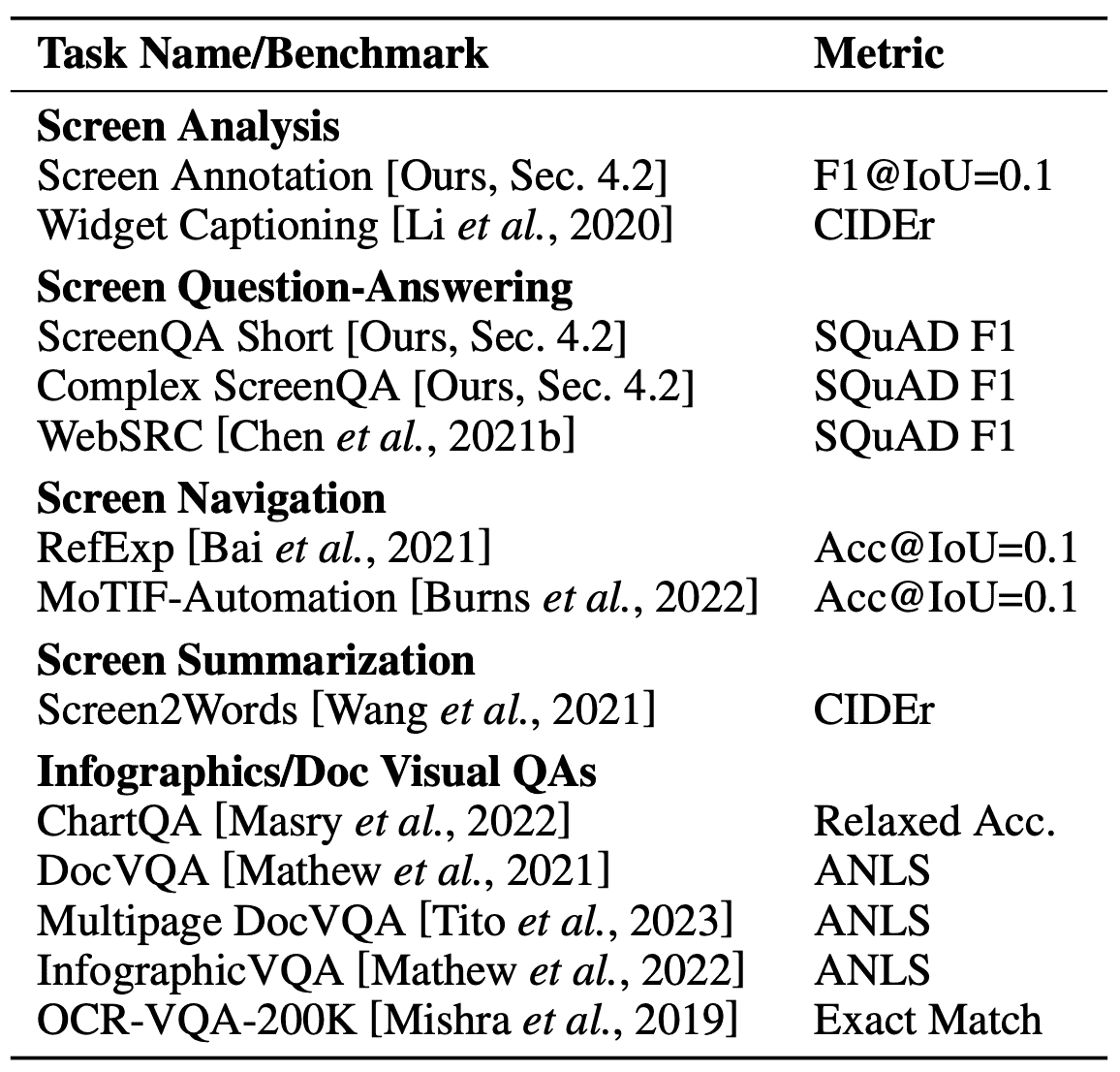
Table 3: Detailed breakdown of our fine-tuning mixture and their associated metrics. We assume readers are familiar with these metrics, but include descriptions and citations in Appendix A for reference.¶

Figure 5: Examples of questions and answers from the ScreenQA dataset, together with their LLM-generated short answers.¶
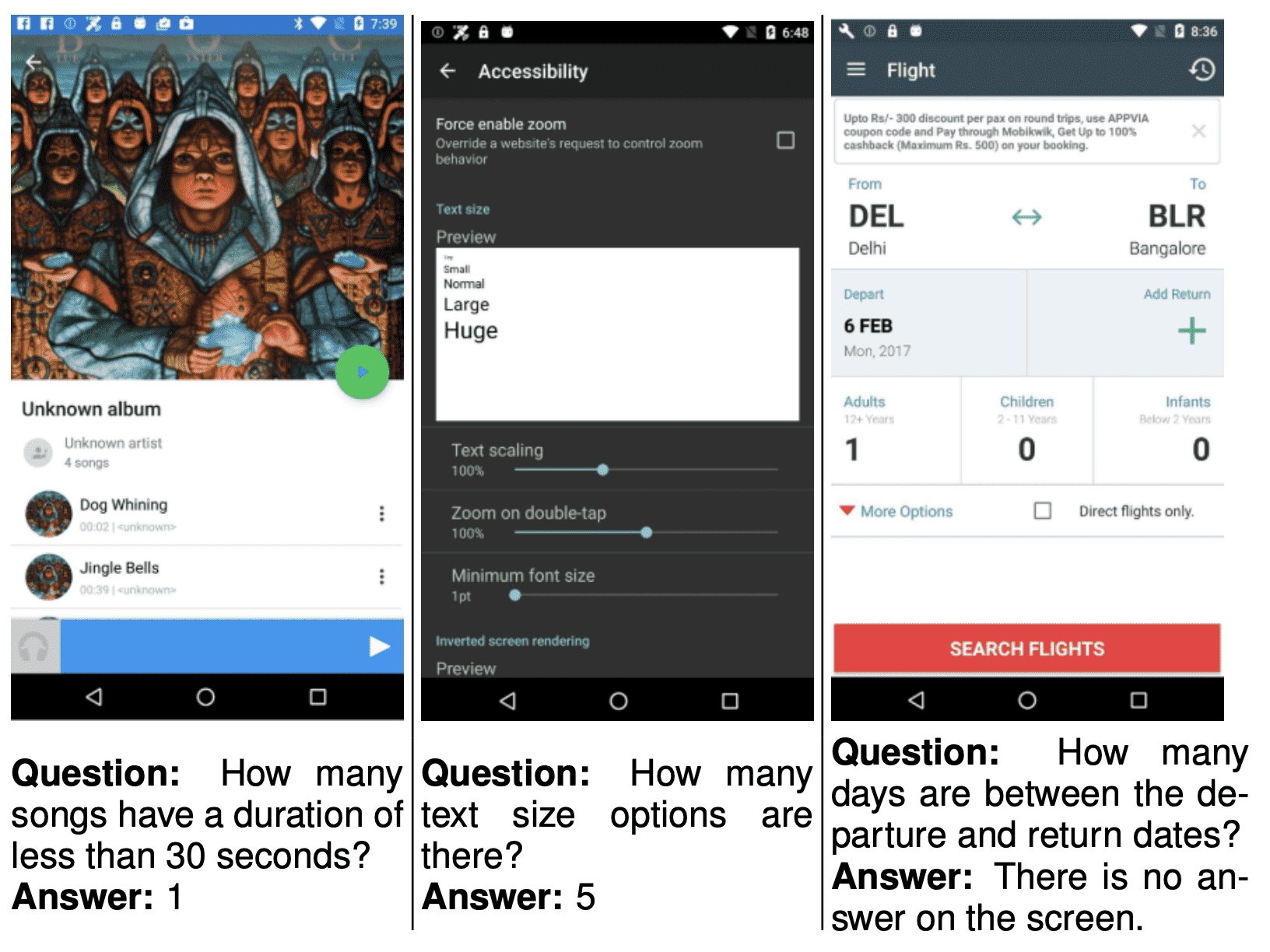
Figure 6: Examples of mobile screen in Complex QA dataset.¶

Figure 7: An example of desktop screen in Complex QA dataset.¶
关键点总结¶
- ScreenAI 采用两阶段训练:
第一阶段(预训练):大量数据,主要依靠自监督学习和自动生成数据。
第二阶段(微调):针对具体任务进行优化,并使用人工标注数据。
- 预训练数据侧重 UI 解析和多模态能力:
屏幕 OCR、问答、导航、摘要等任务。
结合网页、信息图、图表等多种数据源。
- 微调数据包含多个基准测试,强调模型的应用能力:
屏幕解析(UI 结构分析)
屏幕导航(目标 UI 元素识别)
屏幕问答(普通 & 复杂问题)
屏幕摘要(自动生成 UI 内容总结)
多种信息图/文档解析任务
- ScreenAI 在多个基准测试上表现优异:
通过微调任务优化模型,使其适用于 UI 解析、文档理解、图表分析等场景。
结合 OCR 技术提升准确度。
适用场景¶
无障碍技术(Accessibility):自动解析 UI 界面,帮助视觉障碍用户操作界面。
自动化测试(UI Automation):检测 UI 界面中的元素,辅助 UI 设计和自动化测试。
智能问答(AI Assistants):提升 AI 对网页、UI、信息图表的理解能力,提供更智能的交互。
信息提取(Information Extraction):从复杂的图表或网页提取结构化数据。
5. Experiments and Results¶
本章内容是关于 ScreenAI 模型的实验和结果分析,主要包括实验设置、结果分析(包括添加 OCR 和模型规模的影响)、以及消融实验(ablation studies)对不同设计选择的影响。
- 核心结论
ScreenAI 刷新了多个任务的 SoTA 记录,表现领先。
添加 OCR 数据能提升 QA 任务性能,但会增加计算成本。
更大规模的模型表现更好,特别是在复杂任务上 2B 到 5B 提升最明显。
Pix2Struct 在适配不同 UI 设计时比固定网格方法更优(相比 Fixed-Grid)。
使用 LLM 生成数据进行预训练能提升模型性能(+4.6%)。
6. Conclusions¶
本章主要总结了 ScreenAI 模型的贡献、实验发现、与其他大模型的对比,以及未来研究方向。
- ScreenAI 模型 & 统一表示框架:
ScreenAI 提出了一种 新的统一表示方法(schema),可以兼容 信息图(Infographics)、文档图像(Document Images)、各种用户界面(UIs)。
这种统一表示方法使得模型能够同时从多个领域的数据中学习,并适用于多种任务。
- 自监督学习任务 & 数据融合的优势:
通过设计 混合的自监督学习任务(Self-Supervised Learning Tasks),利用多个领域的数据进行训练。
- 这种数据融合(screen、infographics、documents)可以产生 正迁移(positive transfer),即:
训练一个任务的数据能帮助提升其他任务的表现。
例如,屏幕 UI 相关任务的学习可以促进对文档、信息图等的理解。
- 实验验证 & SoTA 结果:
实验表明:使用大规模语言模型(LLM)生成数据有助于提升 ScreenAI 的表现。
消融实验(Ablation Studies) 进一步证明了模型设计的合理性。
训练出的模型在多个公共基准测试(public benchmarks)上表现出色,达到或超越了 SoTA(State-of-the-Art,最先进)水平。
- 与 GPT-4、Gemini 的对比 & 未来研究:
虽然 ScreenAI 在多个任务上表现最佳,但在某些任务上,仍然 无法完全匹敌 GPT-4 和 Gemini 这样的超大规模模型(这些模型的参数规模远超 ScreenAI)。
这表明 未来仍需要更多研究,以缩小与这些更强大模型的性能差距。
- 数据集开放,促进研究:
为了促进社区研究,ScreenAI 团队开放了一个包含统一表示的数据集,以及另外 两个专门用于 UI 相关任务的基准数据集,以帮助更全面地评估模型的表现。
In this work, we introduce the ScreenAI model along with a new unified schema for representing complex data and visual information, compatible with infographics, document images, and various UIs.
This unified representation enables the design of a mixture of self-supervised learning tasks, leveraging data from all these domains.
We show that training on this mixture results in a positive transfer to screen-related tasks as well as infographics and document-related tasks.
We also illustrate the impact of data generation using LLMs and justify our model design choices with ablation studies.
We apply these techniques to train a model that performs competitively and achieves SoTA on a number of public benchmarks.
While our model is best-in-class, we note that, on some tasks, further research is needed to bridge the gap with models like GPT-4 and Gemini, which are orders of magnitude larger.
To encourage further research, we release a dataset with this unified representation, as well as two other datasets to enable more comprehensive benchmarking of models on screen-related tasks.
A Definitions of Metrics¶
- 对象检测任务 (Object Detection Tasks)
计算预测的 UI 元素(bounding boxes)与真实值的匹配度,使用标准的目标检测方法。
设定 IoU (Intersection over Union, 交并比) 阈值为 0.1 进行匹配,并按类别匹配(而不是全局匹配)。
- 指标:
F1@IoU=0.1 - 在 IoU=0.1 时计算的 F1 分数(即精确率和召回率的调和平均值)。
Acc@IoU=0.1 - 在 IoU=0.1 时的 Top-1 准确率。
- 文本输出任务 (Plain Text Output Tasks)
CIDEr (图像描述评估) - 用于衡量生成文本与参考文本的相似性。
SQuAD F1 - 结合 Stanford Question Answering Dataset (SQuAD) 预处理后计算 F1 分数。
Relaxed Accuracy - 可能是一种更宽松的匹配度计算方式。
ANLS (Average Normalized Levenshtein Similarity) - 计算编辑距离的平均归一化得分。
B. Screen Schema Examples¶
- 说明屏幕架构的组成,包括:
The UI element names.
The OCR text (when applicable).
The element descriptions (e.g. captioning, or the icon name).
The bounding box coordinates, quantized and normalized between 0 and 999.
结构上使用括号表示层级关系,并将边界框信息叠加到屏幕截图上。

Figure 10: Examples of our screen schema.¶
C. Prompts For LLM Generated Content¶
提供给 LLM(如 PaLM 2-S)的输入提示,用于生成屏幕问答 (ScreenQA)、屏幕导航 (Screen Navigation) 和屏幕摘要 (Screen Summarization) 的数据。
- 示例:
ScreenQA: 让 LLM 生成 5 个关于屏幕内容的问题及其简短答案。
Screen Navigation: 让 LLM 生成点击 UI 元素的单步导航指令,如 “click 0 137 31 113”。
Screen Summarization: 让 LLM 生成 2-3 句话总结屏幕内容,不具体描述 UI 元素名称,而是关注内容。
Screen Question Answering:
You only speak JSON. Do not write text that isn’t JSON.
You are given the following mobile screenshot, described in words. Can you generate 5 questions regarding the content of the screenshot as well as the corresponding short answers to them? The answer should be as short as possible, containing only the necessary information. Your answer should be structured as follows:
questions: [
{{question: the question,
answer: the answer
}}, ...]
{THE SCREEN SCHEMA}
Screen Navigation:
You only speak JSON. Do not write text that isn’t JSON.
You are given a mobile screenshot, described in words.
Each UI element has a class, which is expressed in capital letter.
The class is sometimes followed by a description, and then 4 numbers between 0 and 999 represent the quantized coordinates of each element.
Generate {num_samples} single-step navigation instructions and their corresponding answers based on the screenshot.
Each answer should always start with ‘click‘, followed by the coordinates of the element to click on, e.g. ‘click 0 137 31 113‘.
Be creative with the questions, do not always use the same wording, refer to the UI elements only indirectly, and use imperative tense.
Your answer should be structured as in the example below:
"questions": [
{{"question": "the question",
"answer": "click 0 137 31 113"
}},
...
]
{THE SCREEN SCHEMA}
Screen Summarization:
You only speak JSON. Do not write text that isn’t JSON.
You are given the following mobile screenshot, described in words.
Generate a summary of the screenshot in 2-3 sentences.
Do not focus on specifically naming the various UI elements, but instead, focus on the content.
Your answer should be structured as follows:
"summary": the screen summary
{THE SCREEN SCHEMA}
D. Screen Navigation Generated Examples¶
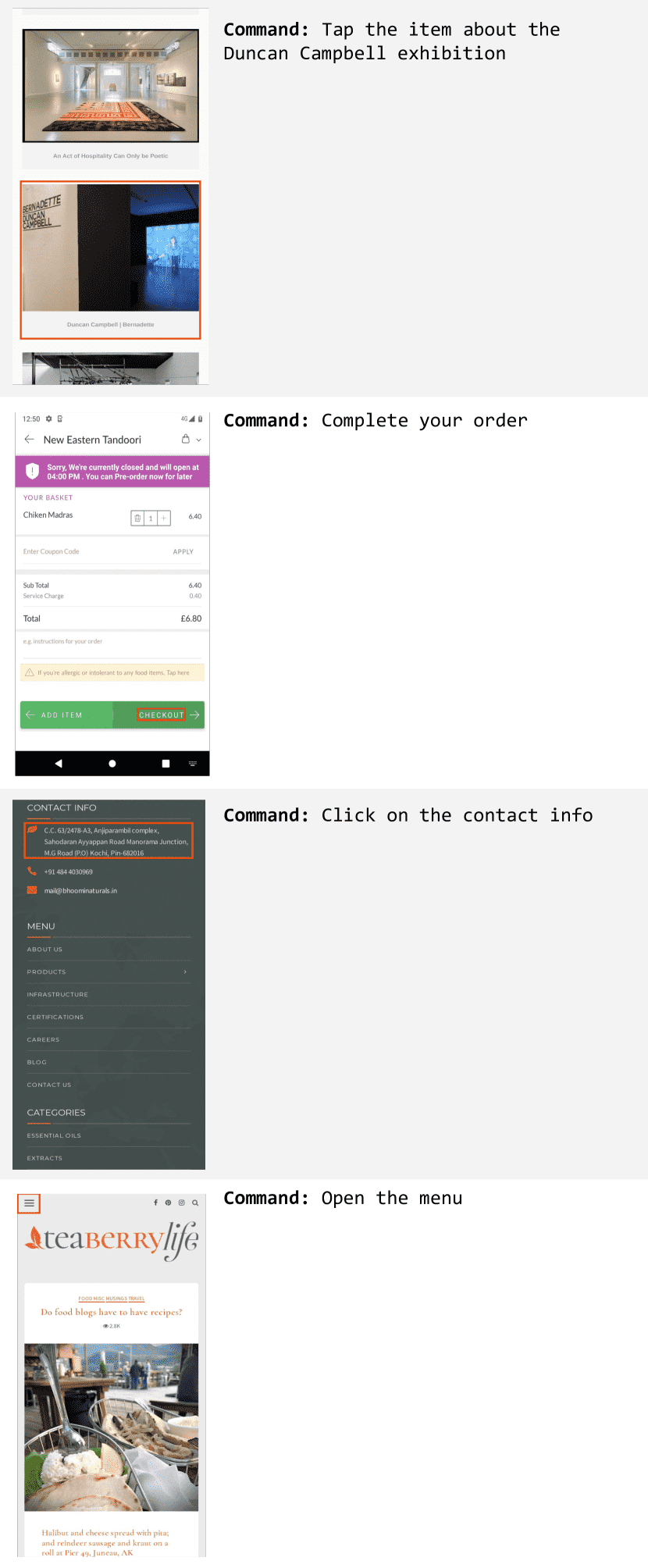
Figure 11:Examples of Screen Navigation data generated using an LLM. The target bounding box is highlighted in red.¶
F. ScreenQA Short Answers Generation¶
由于相同的信息可能有多种表达方式(如不同的日期格式),所以改进数据集时,不仅提供单一正确答案,而是生成一组等效的正确答案列表。
使用 PaLM 2-S 在 few-shot setting 下生成多个可能的短答案。
- 例如:
“25.01.2023”、”25th of January 2023” 和 “January 25, 2023” 都是同一个日期,不应因为格式不同而影响评分。
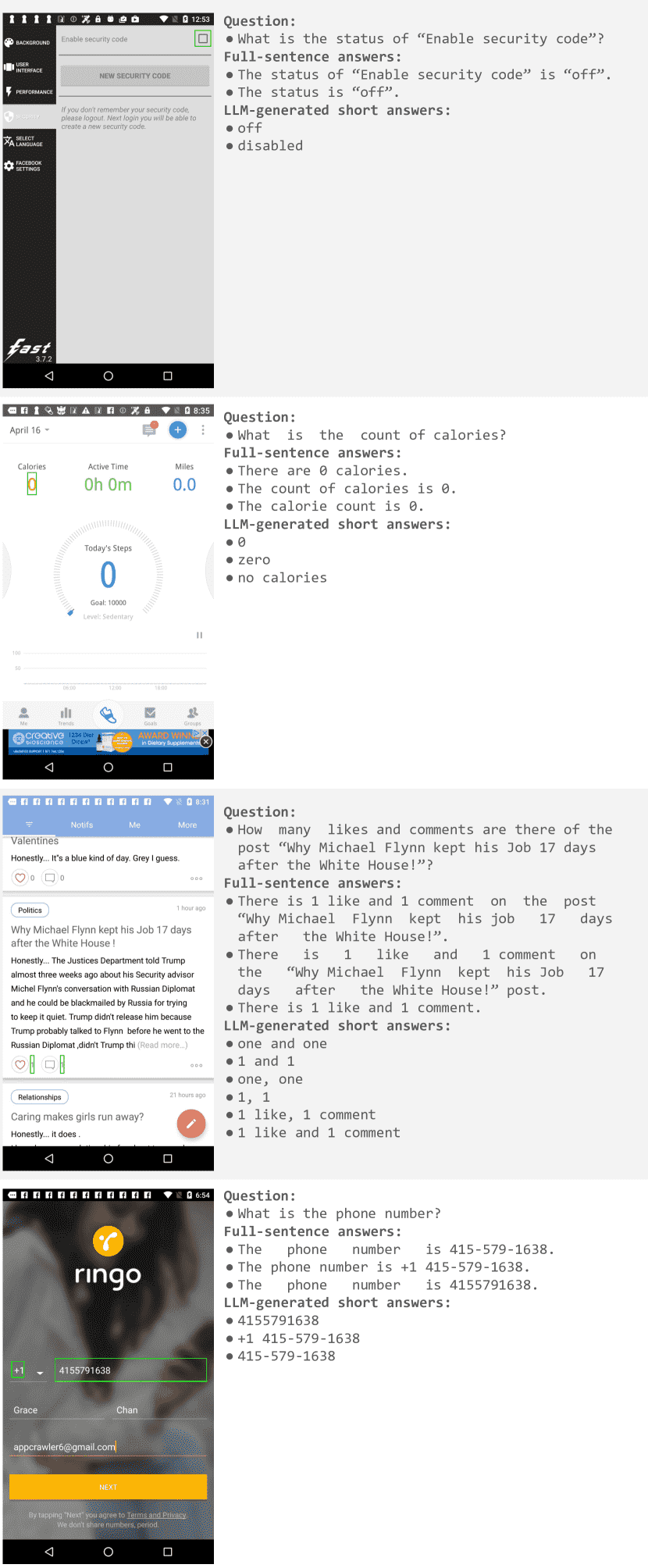
Figure 12:Examples of questions and answers from the ScreenQA dataset, together with their LLM-generated short answers.¶
F.1 For answers contained in a single UI element¶
List various ways to rephrase the answer. The answer should be as short as possible, without extra words from the question.
Use all provided elements in each answer. Provide the output in square brackets.
Here is an example:
Question: ’What’s the percentage of humidity?’
Answer elements: [’65%’]
Full answer: ’The humidity is 65%’
Rephrases: [’65%’]
Here is another example:
Question: ’What is the gender?’
Answer elements: [’Male’]
Full answer: ’The gender is male.’
Rephrases: [’male’]
Here is another example:
Question: ’What is the status of "24 hr clock"?’
Answer elements: [’on’]
Full answer: ’The status is "on".’
Rephrases: [’on’, ’enabled’]
[...]
Now is your turn.
Question: {THE QUESTION}
Answer elements: {THE UI ELEMENT DESCRIPTION}
Full answer: {THE FULL-SENTENCE ANSWER}
Rephrases:
F.2 For answers contained in multiple UI elements¶
List various ways to rephrase the answer.
The answer should be as short as possible, without extra words from the question.
Use all provided elements in each answer.
Provide the output in square brackets.
Here is an example:
Question: ’What’s the temperature?’
Answer elements: [’59’, ’◦F’]
Full answer: ’The temperature is 59 degrees Fahrenheit.’
Rephrases: [’59◦F’, ’59 Fahrenheits’, ’59 degrees Fahrenheit’]
Here is another example:
Question: ’What is the name?’
Answer elements: [’Jon’, ’Brown’]
Full answer: ’The name is Jon Brown.’
Rephrases: [’Jon Brown’]
Here is another example:
Question: ’What is the rest interval duration?’
Answer elements: [’00’, ’:’, ’34’]
Full answer: ’The rest interval lasts 00:34.’
Rephrases: [’00:34’, ’34 seconds’, ’0 minutes and 34 seconds’, ’34 minutes’, ’0 hours and 34 minutes’]
[...]
Now is your turn.
Question: {THE QUESTION}
Answer elements: {THE FIRST UI ELEMENT DESCRIPTION, ...}
Full answer: {THE FULL-SENTENCE ANSWER}
Rephrases:
G. Complex Question Answering Datasets¶
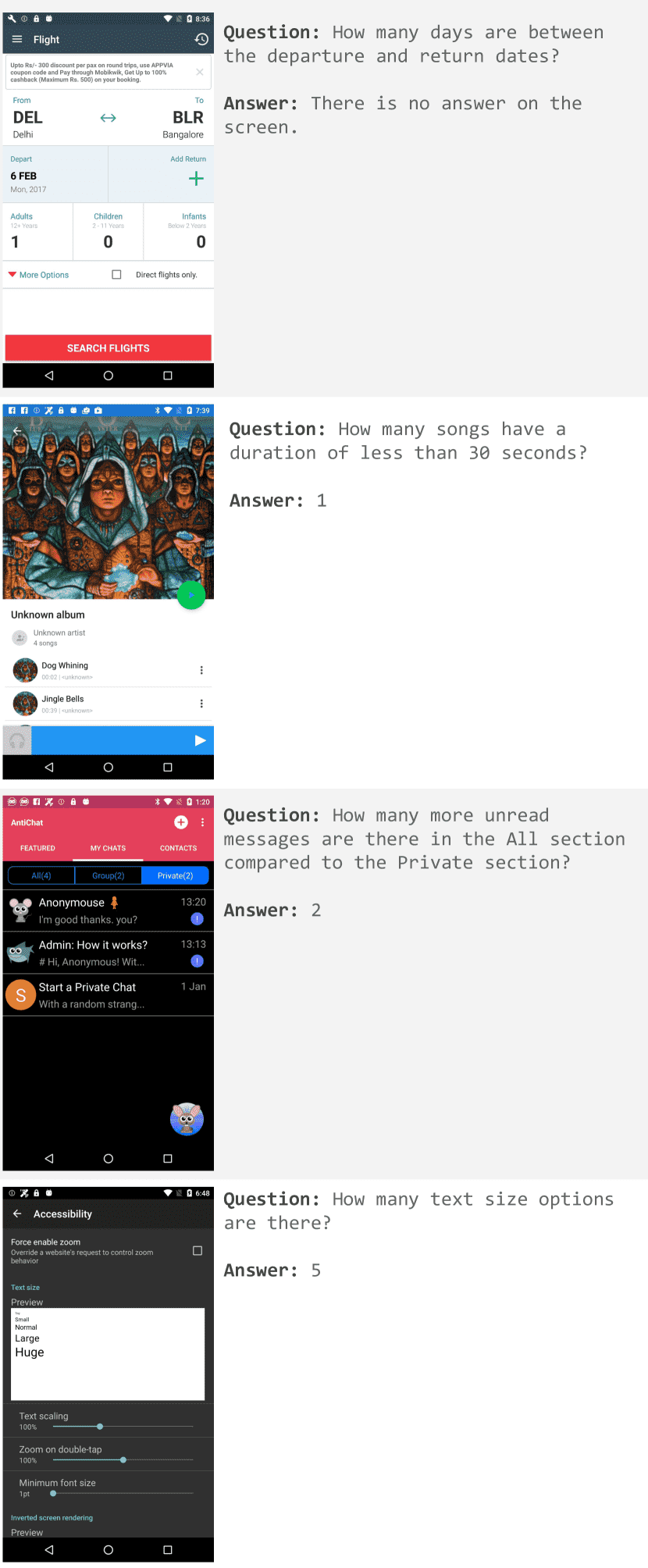
Figure 13: Examples of mobile Complex QA evaluation examples.¶
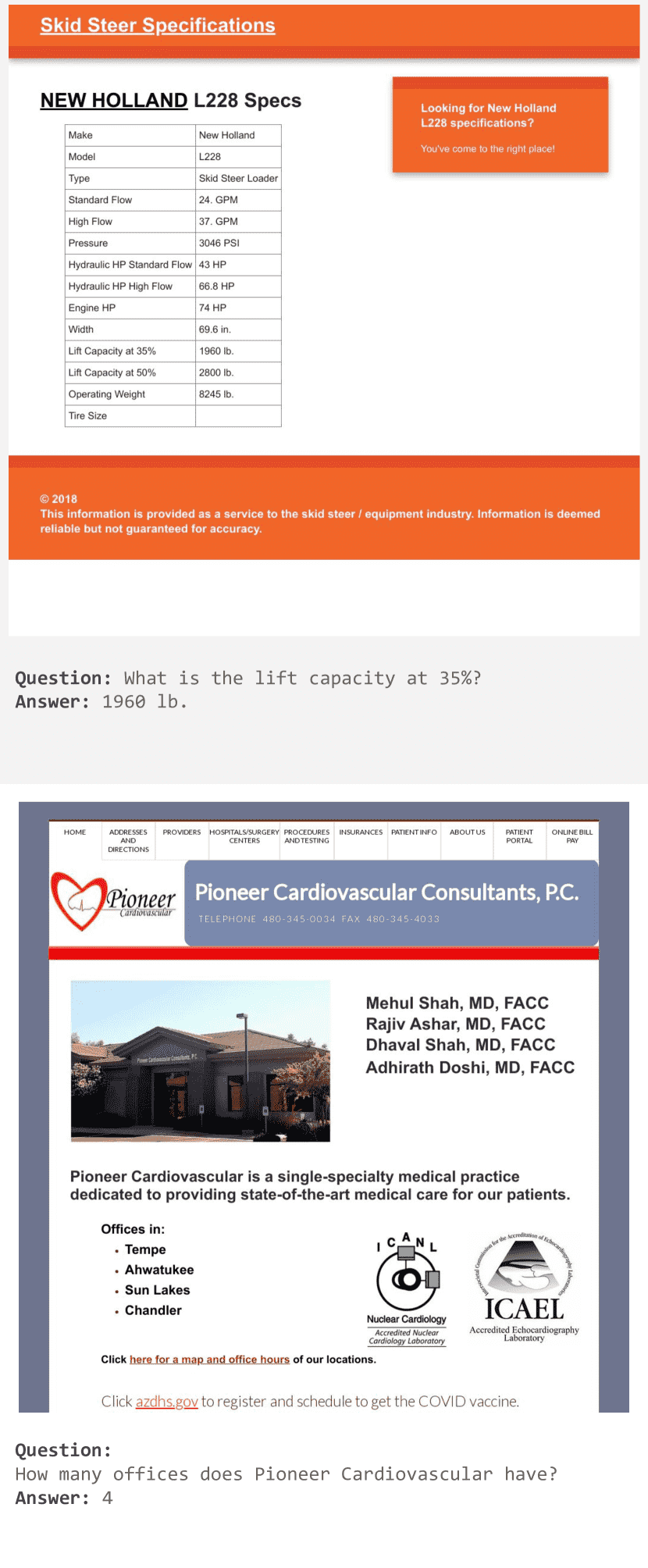
Figure 14: Examples of desktop Complex QA evaluation examples.¶
H. New Benchmarks Repositories¶
Screen Annotation (SA): https://github.com/googleresearch-datasets/screen_annotation
ScreenQA ( Short & Complex): https://github.com/googleresearch-datasets/screen_qa