2309.16609_Qwen Technical Report¶
组织: 阿里
GitHub: https://github.com/QwenLM/Qwen
1. Introduction¶
大语言模型(LLM)的崛起¶
大语言模型(如 GPT 系列、T5、PaLM 等)彻底改变了人工智能领域。它们可以:
理解和生成自然语言内容
执行复杂的推理和创造性任务(如写诗、写代码)
与人类对话,成为强大的助手
不仅限于文字任务,LLM 还能:
执行代码
使用工具
处理多模态信息(图像+文本)
Qwen 模型系列介绍¶
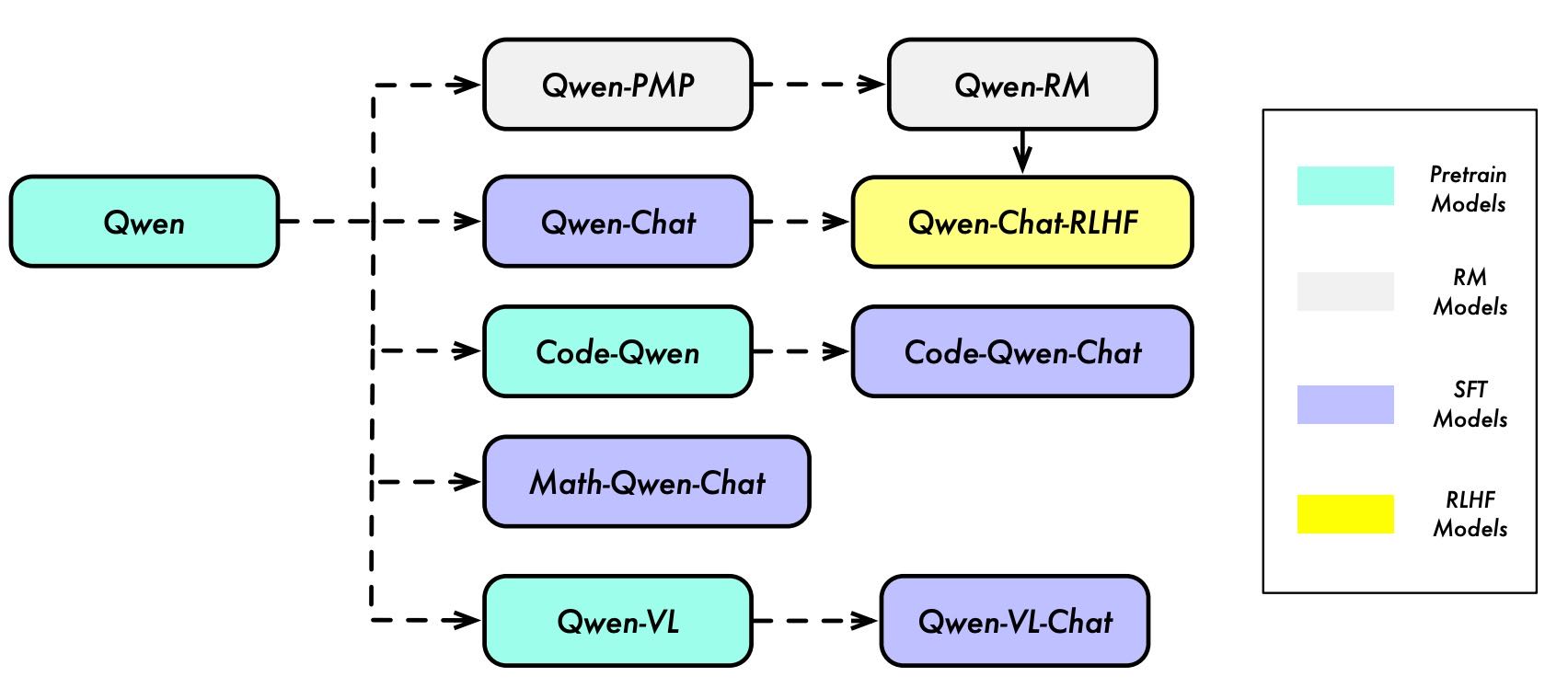
Figure 1: Model Lineage of the Qwen Series. We have pretrained the language models, namely QWEN, on massive datasets containing trillions of tokens. We then use SFT and RLHF to align QWEN to human preference and thus we have QWEN-CHAT and specifically its improved version QWEN-CHAT-RLHF. Additionally, we also develop specialized models for coding and mathematics, such as CODE-QWEN, CODE-QWEN-CHAT, and MATH-QWEN-CHAT based on QWEN with similar techniques. Note that we previously released the multimodal LLM, QWEN-VL and QWEN-VL-CHAT (Bai et al., 2023), which are also based on our QWEN base models
preference model pretraining (PMP) and reward model (RM)
模型开源情况¶
Qwen 和 Qwen-Chat 的 7B 和 14B 参数规模版本
目标是为开发者和应用提供强大、易用的 LLM
2. Pretraining¶
Qwen 模型的预训练阶段包含多个核心内容,旨在构建具备语言、算术、逻辑推理和编程能力的大模型。
2.1 数据¶
数据规模大,涵盖网页、百科、书籍、代码等多种类型。
多语言,以英文和中文为主。
质量控制:
去重(精确匹配+模糊去重)
使用规则和模型筛选低质量内容
引入人工抽检和高质量指令数据
总训练数据高达 3万亿个Token
2.2 分词(Tokenization)¶
使用 BPE 分词法,起点为
cl100k词表(来自 GPT)。增强了中文词汇的支持,并将数字拆分为单个数字。
词表总规模约为 15.2万个词。
实验表明:Qwen 分词器在多语言压缩效率优于其他模型。
2.3 模型架构¶
基于 Transformer,并借鉴 LLaMA 的结构。
主要改进:
输入/输出嵌入权重不共享
使用 RoPE 位置编码(精度为 FP32)
注意力层中 QKV 使用 bias,其他层不加 bias
使用 Pre-Norm + RMSNorm 提高稳定性
激活函数为 SwiGLU,比 GeLU 效果更好
FFN 维度从 4x 降为 8/3x,提升效率

Table 1: Model sizes, architectures, and optimization hyper-parameters.
2.4 训练过程¶
使用标准自回归训练(预测下一个词)
上下文长度为 2048,使用 Flash Attention 提高效率
优化器:AdamW,使用余弦退火学习率调度
全程使用 BFloat16 混合精度训练
2.5 上下文长度扩展¶
Transformer 的注意力机制在长上下文下计算成本高。
使用 NTK-aware 插值 等方法,在不额外训练的情况下扩展上下文。
引入两种机制提升长文本处理能力:
LogN 缩放:使注意力值更稳定
窗口注意力:限制关注范围
不同层使用不同窗口大小,低层窗口小,高层窗口大
2.6 实验结果¶
Qwen 在多个基准测试中表现优异,特别是 Qwen-14B 在某些任务中超越了 LLaMA2-70B。
Qwen-7B 超过了 LLaMA2-13B,接近 Baichuan2-13B。
Qwen-1.8B 虽然体量小,但在一些任务中仍优于更大的模型。
在长文本任务中,结合多种上下文扩展技术后,Qwen 保持了优秀性能。
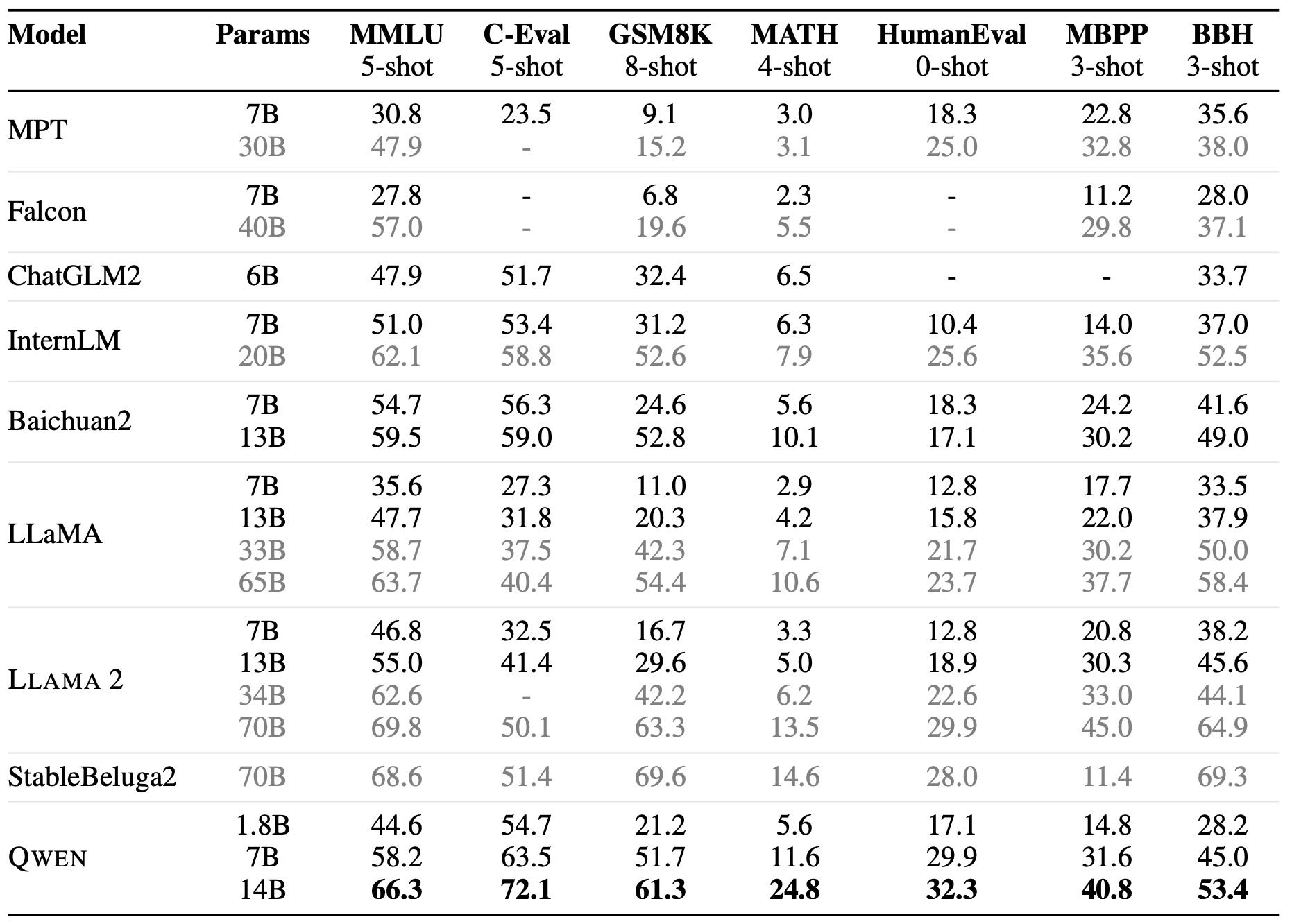
Table 2: Overall performance on widely-used benchmarks compared to open-source base models.
3. Alignment¶
这段内容介绍了 Qwen 模型是如何通过对齐技术(Alignment)来更好地理解和响应人类语言的
🌟 整体概述¶
大语言模型(LLM)虽然预训练后具备强大能力,但不够“贴近人类意图”,不能直接用于 AI 助手。
因此,研究者使用 SFT(监督微调)+ RLHF(人类反馈强化学习) 来“对齐”模型,使其更像人类。
🧠 3.1 监督微调 SFT¶
目的:让模型学会更自然、更有帮助的对话方式。
做法:用大量“人类风格”的对话(问题+回答)训练模型。
技术细节:
使用 ChatML 格式标明对话角色(如 user / assistant)。
模型预测下一个词(next-token prediction)。
设置学习率、批大小等常规训练参数。
🎯 3.2 人类反馈强化学习 RLHF¶
目的:解决 SFT 模型“死板”、“泛化弱”的问题,让模型更有创造力、更符合人类偏好。
步骤:
构建奖励模型:用人类评分的数据训练奖励模型(判断哪个回答更好)。
策略优化(PPO):在奖励模型的指导下改进回答策略。
技巧:
使用多种模型生成回答来增加多样性。
设置合适的学习率、正则化参数等。
使用“预训练梯度”减轻所谓的“对齐税”(alignment tax)。
📊 3.3 自动评估与人工评估¶
自动评估:用标准测试集(如 MMLU、HumanEval)对模型能力打分。
人工评估:300条中文指令,比较 SFT 和 RLHF 版本 Qwen 的表现,并与 GPT-3.5 / GPT-4 对比。
结论:RLHF 显著优于 SFT,但仍略弱于 GPT-4。
亮点:Qwen 在代码生成(HumanEval)上的表现超越其他开源模型。
🤖 3.4 工具调用、代码解释器与 Agent 能力¶
Qwen 模型具备作为 Agent(助理/自动化助手)的潜力:
能用 ReAct 技术调用工具/API。
会用 Python 执行代码做推理/分析。
能访问 Hugging Face 多模态模型。
使用自举式“自我指令生成(Self-Instruct)”来进一步增强这方面能力。
✅ 总结¶
Qwen 模型通过监督微调+人类反馈强化学习,配合高质量数据和评估体系,提升了它:
更自然地对话、
更符合人类喜好、
更会调用工具执行任务,
4. CODE-QWEN: SPECIALIZED MODEL FOR CODING¶
✅ 什么是 CODE-QWEN?¶
CODE-QWEN 是在 Qwen 基础语言模型上,专门为编程任务打造的模型系列,主要包括:
CODE-QWEN:通过继续在代码数据上预训练得到。
CODE-QWEN-CHAT:在 CODE-QWEN 的基础上再进行监督微调,用于对话式编程任务。
🧠 模型训练方式¶
继续预训练(Code Pretraining)
先用通用数据(文本 + 代码)训练出基础模型 Qwen。
然后再用大约 900 亿个代码 token 继续预训练。
最大上下文长度设为 8192,适应复杂编程场景。
使用 Flash Attention 提升效率,优化器是 AdamW。
监督微调(Code Supervised Fine-tuning)
使用多阶段 SFT(Supervised Fine-Tuning)策略。
仍用 AdamW 优化器。
学习率使用余弦调度+预热策略。
📊 模型评估表现¶
在多个代码生成测试集(如 Humaneval、MBPP、HumanEvalPack)上,CODE-QWEN 系列模型的 pass@1 表现优于同体量的模型(如 OctoGeeX、CodeT5+、CodeGeeX2)。
与大模型如 Starcoder 相当,虽然整体上还是落后 GPT-4,但差距正在缩小。
🔍 总结重点¶
CODE-QWEN 系列专为编程优化,综合表现强大。
相较同体量模型有明显优势,未来有望追赶 GPT-4。
评估方式还不够全面,未来需更严谨的测试标准。
5. MATH-QWEN: SPECIALIZED MODEL FOR MATHEMATICS REASONING¶
MATH-QWEN 是一个专为数学推理设计的大模型系列,基于 QWEN 语言模型构建。
MATH-QWEN-7B-CHAT(70亿参数)
MATH-QWEN-14B-CHAT(140亿参数)
训练方式:¶
在增强后的数学指令数据集上进行了微调(SFT)。
数据主要是考试题,因此训练时不让模型学习输入本身(如题目中的数字),加快了收敛。
使用 AdamW 优化器,训练5万步,学习率为 2×10⁻⁵。
数学能力评估:¶
在四个数学测试集上评估,包括小学数学、竞赛题、中文小学题等。结果显示:
MATH-QWEN 在数学推理和算术能力方面优于其他开源模型和普通 QWEN 模型。
7B 版本超过了 Minerva-8B,14B 版本接近 Minerva-62B 和 GPT-3.5 的表现。
7. Conclusion¶
QWEN 系列是新一代的大语言模型,包括 14B、7B 和 1.8B 参数规模,使用海量数据预训练,并通过先进技术(如 SFT 和 RLHF)进行微调。
系列中还有专门用于编程和数学的模型,如 CODE-QWEN、CODE-QWEN-CHAT 和 MATH-QWEN-CHAT,针对特定领域优化。
实验表明,QWEN 在多个评测中表现优秀,达到甚至媲美一些闭源模型的水平。官方开放这些模型,旨在推动研究和应用的发展,激励更多创新。 总结:QWEN 是一个重要成果,代表语言模型的一大进步,未来有望推动更多突破。
A.1 MORE TRAINING DETAILS¶
在训练对话型AI助手时,虽然任务还是“预测下一个词”,但需要特别设计的数据格式,比如“human-assistant”格式或ChatML格式。
早期Anthropic提出了“human: / assistant:”的格式,但这些词是常见词,模型可能会混淆。
OpenAI提出的ChatML格式用的是不在预训练中出现的特殊标记(如
<im_start>和<im_end>),更容易让模型识别对话角色,效果更好。

A.2 EVALUATION¶
A.2.1 AUTOMATIC EVALUATION¶
为了全面评估我们Qwen系列模型的表现,我们采用了OpenCompass团队提出的一套综合评测体系,并展示了模型与基线模型的详细对比结果。
评测分为多个维度,如考试类、语言能力、知识掌握、理解能力和推理能力。对于基线模型,我们采用了报告中或排行榜上较高的分数。
考试类评测数据集包括:
MMLU:多任务语言理解,测试模型的语言理解能力,用5-shot方式评估。
C-Eval:中文多学科考试数据集,覆盖52个学科,用5-shot方式评估。
CMMLU:专为中文语言理解设计的数据集,用5-shot方式评估。
AGIEval:涵盖人类考试(如高考、法考、奥数等),用zero-shot方式评估。
Gaokao-Bench:包含中国高考题目的数据集,用zero-shot方式评估。
ARC:小学生水平的科学选择题数据集,分为简单集(ARC-e)和挑战集(ARC-c),用zero-shot方式评估。
语言支持差异
LLAMA 2 只报告了英文部分的测试结果,因此他们引用了 OpenCompass 上的数据。
一些模型(如 MPT、Falcon、LLaMA 系列)没有针对中文优化,在中文相关的数据集(CMMLU、AGIEval、高考题)上表现较差。
知识与语言理解评估
使用以下英文数据集测试模型的知识和语言理解能力:
BoolQ:维基百科问答,回答是/否(零样本)。
CommonsenseQA:常识问答(8-shot)。
NaturalQuestions:用户提问 + 专家审核答案(零样本)。
LAMBADA:通过预测词汇评估理解能力(零样本)。
推理能力评估
测试模型在自然语言推理方面的表现,使用的数据集有:
HellaSwag:常识推理(零样本)。
PIQA:物理常识推理(零样本)。
SIQA:社交常识推理(零样本)。
OCNLI:中文自然语言推理(零样本)。
A.2.2 HUMAN EVALUATION¶
构建了自定义中文评测数据集,包括手写或人工改写的指令,来源如 CLiB、C-Eval、FacTool、LeetCode 等。
每个案例中比较多个模型的回答,并提供 Elo 评分。
所有中文数据也提供英文翻译,便于理解。