2408.01800_MiniCPM-V: A GPT-4V Level MLLM on Your Phone¶
组织: MiniCPM-V Team, OpenBMB
Abstract¶
最近,多模态大模型(MLLM)发展迅速,推动了AI的进步,但它们运行成本高,需要大量算力,通常只能部署在云端服务器,限制了在手机、离线、节能或隐私场景中的应用。
为了解决这个问题,研究者提出了 MiniCPM-V 系列模型,能在终端设备(如手机)上运行,同时具备以下优势:
性能强,超过 GPT-4V、Gemini Pro 和 Claude 3(在 OpenCompass 的多个评测中)。
图像识别能力强,能处理高达 180 万像素的图片。
幻觉率低,表现更可信。
支持 30 多种语言。
可以高效部署在手机上。
更重要的是,这代表一个趋势:实现 GPT-4V 级别性能所需的模型正在变小,而终端设备的算力越来越强,这意味着未来在手机等设备上运行高水平AI将成为现实,应用范围也将更广。
1. Introduction¶
背景问题:
多模态大模型(MLLMs)虽然能力强(能看图说话、识图推理等),但参数多、算力要求高,通常只能部署在云端。这带来了高能耗和隐私风险,也难以在手机等设备上使用。
解决方案:
为了解决这些问题,研究者开发了轻量化、能在终端设备(如手机、电脑、汽车、机器人)上运行的 MLLM 系列模型 —— MiniCPM-V。
MiniCPM-V 系列模型进展:
MiniCPM-V 1.0(2B):2024年2月发布,为手机设计的早期版本。
MiniCPM-V 2.0(2B):2024年4月发布,性能超过多个大模型(如 Qwen-VL 9B)。支持高分辨率图像和 OCR。
MiniCPM-Llama3-V 2.5(8B):2024年5月发布,性能超越 GPT-4V、Gemini Pro、Claude 3,并可高效部署在终端设备上。
关键技术亮点:
领先性能:在多个标准测试中表现优异。
强大OCR能力:识别文字、表格转Markdown等,支持高分辨率图像输入。
可信赖行为:幻觉率更低,响应更可靠。
多语言支持:可支持30多种语言。
高效终端部署:通过量化、内存优化、编译优化和NPU加速等技术,适合在移动设备上运行。
趋势判断:
模型越来越小、性能却越来越强,这一趋势类似“摩尔定律”(称为 MLLM 的摩尔定律)。
随着终端设备性能的提升,像 GPT-4V 级别的模型将在手机等设备上变得可行。
总贡献:
发布了可在终端运行的高效 MLLM 系列 MiniCPM-V;
提出了实现高性能-高效率平衡的关键技术;
总结了 MLLM 的发展趋势,并通过 MiniCPM-V 实例验证了这一趋势。
3. Model Architecture¶
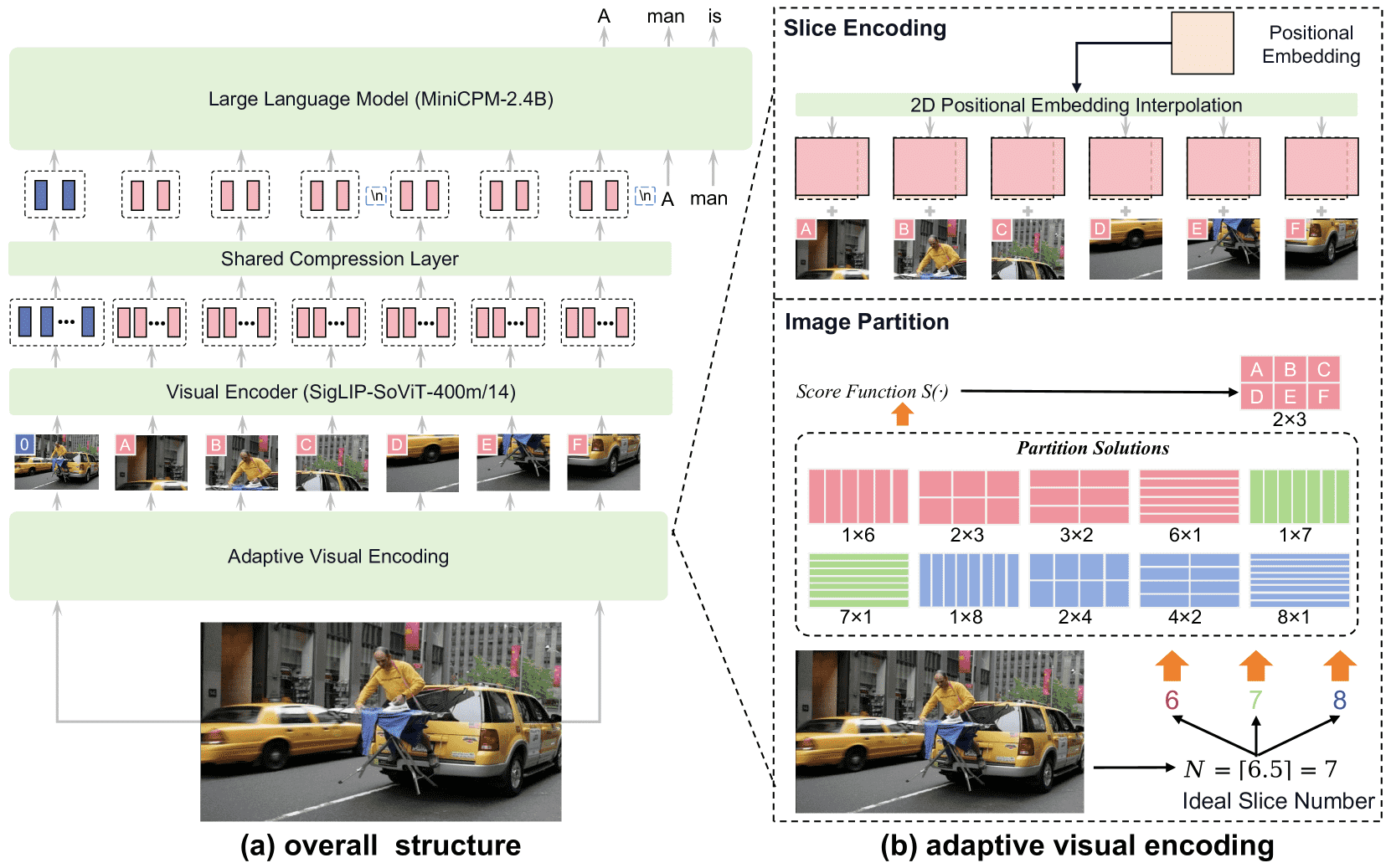
Figure 3:Model architecture. (a) Overall structure presents the architecture of the model including the visual encoder, shared compression layer, and LLM. (b) Adaptive visual encoding deals with high-resolution inputs in various aspect ratios.
MiniCPM-V 模型结构简介¶
MiniCPM-V 主要由三个模块组成:
视觉编码器(Visual Encoder):使用 SigLIP SoViT-400M 模型,对输入图像进行高分辨率编码。
压缩层(Compression Layer):把视觉编码结果压缩为更少的 token,减轻 LLM 的负担。结构上使用了 Perceiver Resampler 的交叉注意力方式。
大语言模型(LLM):接收压缩后的图像 token 和文本,一起生成输出文本。
自适应视觉编码(Adaptive Visual Encoding)¶
为了在保证图像细节的同时降低计算量,模型采用了“图像切片”的方式处理高分辨率图像:
图像切片(Image Partition):将输入图像按比例分割成多个小块(slices),使每块的尺寸尽可能接近 ViT 模型训练时的图像尺寸。这样能提升模型识别能力,特别是在 OCR 等任务中。
切片的数量是根据图像尺寸计算的,并选取最优的行列数组合(m × n)来分割图像。
为了避免某些特殊情况(如 N 是质数)导致切分组合太少,计算中会考虑 N±1 的情况。
最大支持约 1344×1344 像素的图像。
切片编码(Slice Encoding):
每个切片会被调整尺寸,并重新插值位置编码,使其适配 ViT 的输入要求。
同时,整体图像也作为一个“全景切片”加入,以保留全局信息。
Token 压缩(Token Compression)¶
每个图像切片编码后会生成 1024 个 token,如果图像被分成 10 片就会有超过 1 万个 token。
为提升效率,使用交叉注意力结构将每个切片压缩成 64 或 96 个 token,大幅降低内存和推理成本,使得模型适用于更多场景。
空间结构标记(Spatial Schema)¶
每个切片的 token 被特殊符号
<slice>和</slice>包裹,用于标记切片的边界。不同行之间用换行符
\n分隔,以提供切片在整图中的位置信息。
4. Training¶
模型训练总体结构:¶
训练分为三阶段:
预训练(Pre-training)
有监督微调(Supervised Fine-tuning)
RLAIF-V 阶段(基于反馈的对齐)
一、预训练阶段(Pre-training)¶
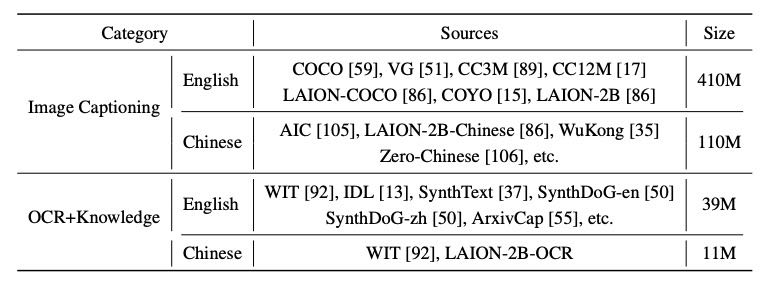
Table 1: Pre-training data. The pre-training data consists of image captioning and OCR data in English and Chinese. LAION-2B-OCR is generated by applying OCR tools to LAION-2B images.
目的:让视觉模块(视觉编码器+压缩层)与大语言模型(LLM)对齐,具备多模态基础能力。
分为3个小阶段:
阶段1:
只训练压缩层(视觉编码器输出转为LLM输入),冻结其它模块。
用200M图文数据,图片分辨率为 224×224。
阶段2:
提升图像分辨率到 448×448,仅训练视觉编码器,其它模块冻结,继续用200M图文数据。
阶段3:
训练视觉编码器+压缩层,引入OCR数据,提升处理高分辨率和不同长宽比图片的能力。
补充技术:
Caption Rewriting:用GPT-4重写低质量图文对齐数据的文字描述,提升训练稳定性。
Data Packing:将不同长度的样本打包成固定长度序列,提升显存效率和训练速度(加速2~3倍)。
多语言泛化:只用中英文训练,再通过轻量微调扩展到30多种语言,依赖于强大的多语言LLM。
二、有监督微调阶段(SFT)¶
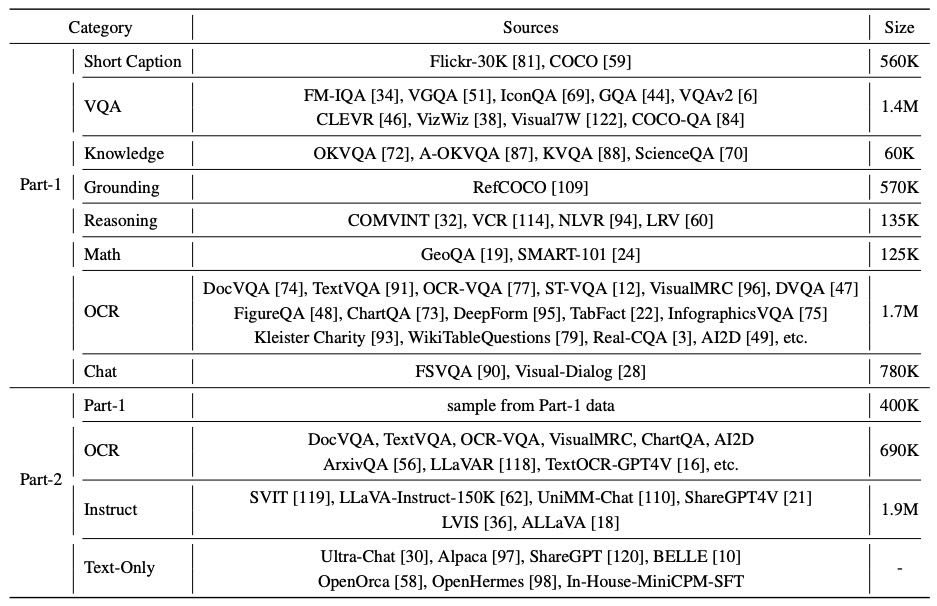
Table 2: SFT data for MiniCPM-V series. Part-1&2 data are concatenated sequentially in the SFT phase. Part-1 focuses on bolstering basic recognition capabilities, while part-2 aims to enhance advanced capabilities in generating detailed responses and following human instructions.
目的:通过高质量人工标注数据进一步提升模型问答能力和理解能力。
解冻所有参数:充分利用标注数据进行能力增强。
数据来源:
Part-1:短回答(基础识别能力)
Part-2:长回答(复杂互动与指令跟随)
共用到 200万 Cauldron 数据 + 9万 多语言数据(36种语言)
三、RLAIF-V 阶段(强化对齐)¶
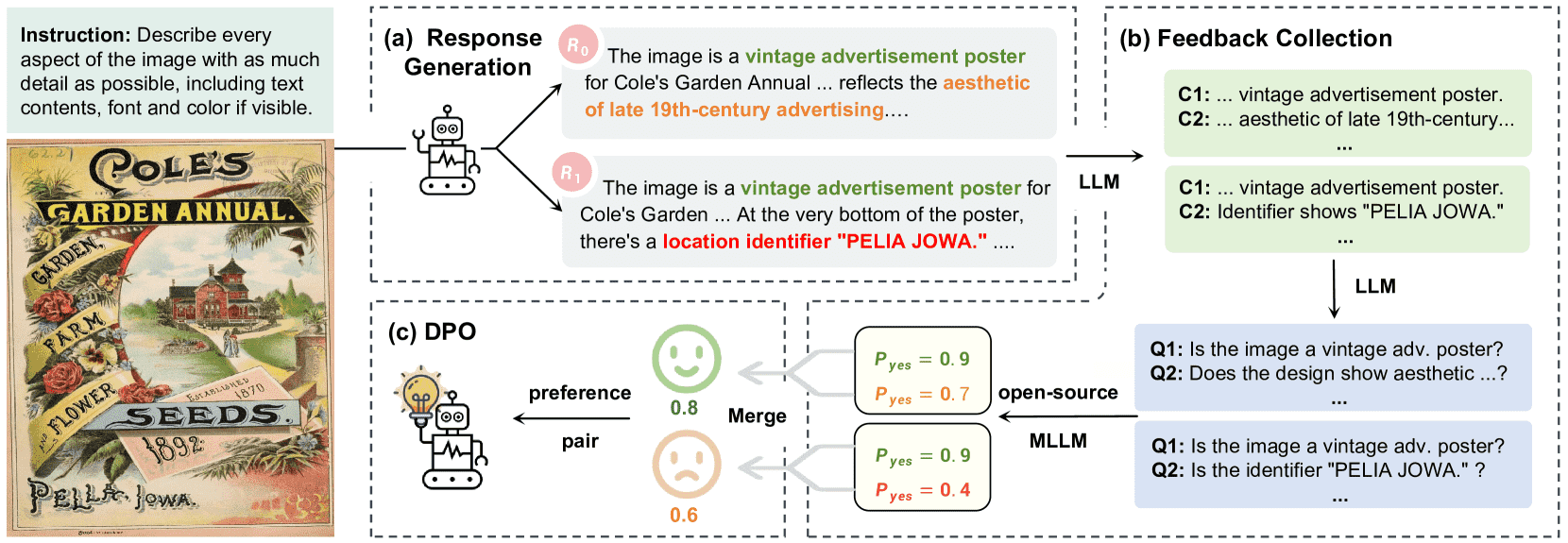
Figure 4:RLAIF-V framework for hallucination reduction. (1) Response generation produces multiple responses for an instruction using the policy model. (2) Feedback collection evaluates the correctness of each response in a divide-and-conquer fashion. (3) DPO optimizes the model on the preference dataset.
目的:解决“幻觉”问题,让模型生成更可信、符合图像内容的回答。
生成多个回答:给每个输入指令采样10个回答。
反馈收集:
每个回答拆成多个原子“事实断言”。
将每个断言转换成Yes/No问题,用开源大模型判对错(如OmniLMM)。
最后统计错误断言数作为评分。
偏好优化(DPO):
对比不同回答的评分,形成“更好/更差”的成对偏好数据。
用这些偏好对模型进行训练,使其学习更可信的回答风格。
5. End-side Deployment¶

Figure 5:An overview of end-side deployment. Current end-side chips for computation acceleration include CPU, GPU and NPU. We list their generality, (estimated) ideal and current performance, and related deployment frameworks.
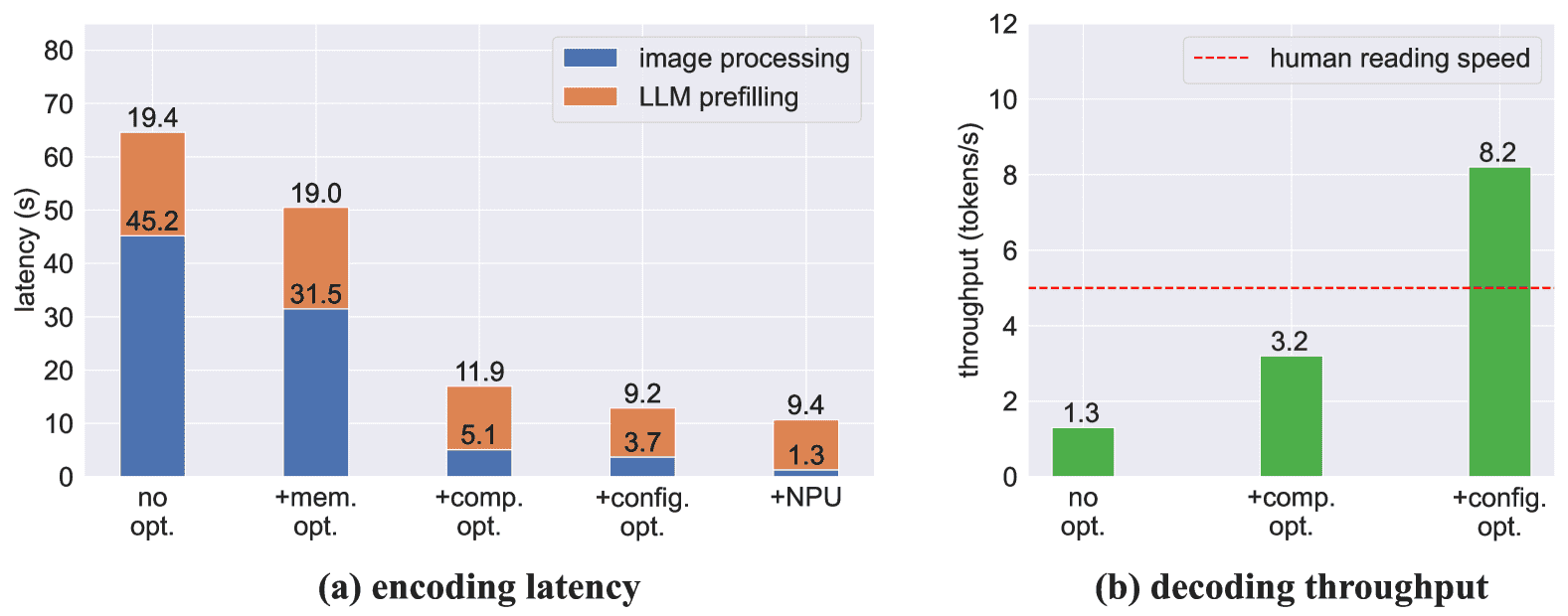
Figure 6:Ablation study on the Xiaomi 14 Pro (Snapdragon 8 Gen 3). We show the influence of different techniques on the (a) encoding latency and (b) decoding throughput. No opt.: non-optimized, mem. opt.: memory usage optimization, comp. opt.: compilation optimization, config. opt.: configuration optimization, NPU: NPU acceleration. Note that the encoding latency includes both model loading time and encoding time, which differs from Fig. 5’s encoding time only.
一、面临的挑战¶
内存限制:手机内存(12~16GB)远小于服务器(上百GB),难以支持大模型运行。
算力不足:手机CPU/GPU远弱于服务器。例如
Snapdragon 8 Gen3 具有 8 个 CPU 内核,而 Intel Xeon Platinum 8580 等高性能服务器具有 60 个 CPU 内核
Adreno 750只有6 TFLOPS,而NVIDIA 4090有83 TFLOPS。
二、基础部署方法¶
量化:将模型参数压缩为低位(如4-bit)以降低内存需求,从16~17GB降到约5GB。
部署框架:优先考虑兼容性好的CPU方案,如
llama.cpp框架。但这对于用户来说仍然远非可接受(如编码64.2s,解码仅1.3 token/s)。
三、高级优化策略¶
内存优化:按顺序加载 ViT 和 LLM,释放内存,提升处理效率(如图像处理时间从 45.2s 降到 31.5s)。
编译优化:在目标设备本地编译模型,提升运行效率(编码时间降至 17.0s,解码提速到 3.2 token/s)。
配置优化:自动搜索最优配置(如CPU核心分配),进一步提速(解码速度升至 8.2 token/s)。
NPU加速:将视觉模型(ViT)部署在 NPU 上,大幅降低视觉编码时间(3.7s 降至 1.3s)。
四、实验结果与展望¶
多设备测试:优化后的模型可在小米、vivo 手机及Mac M1上顺畅运行,速度接近人类阅读水平。
主要瓶颈:目前主要瓶颈是 LLM 的预填阶段,未来优化方向包括视觉Token减少和GPU/NPU加速 LLM。
展望:随着硬件和优化技术的发展,实现终端上实时运行大模型已逐渐可行。
6. Experiments¶

Table 3: The MiniCPM-V series, with key components and configurations. AR.: aspect ratio.
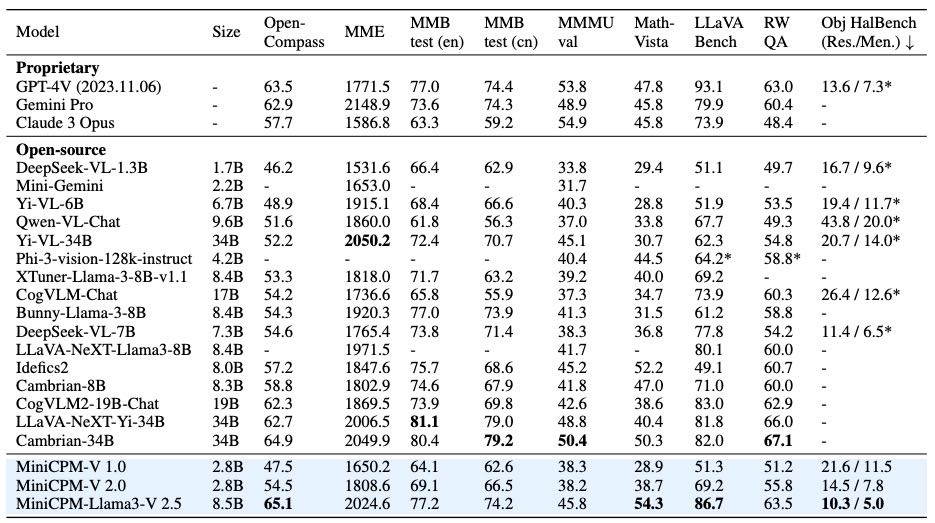
Table 4: Experimental results on general multimodal benchmarks. RW QA: RealWorldQA, Obj HalBench (Res./Men.) : Object HalBench with response/mention-level hallucination rates, *: our tested results with official checkpoints. The best open-source results are highlighted in bold.
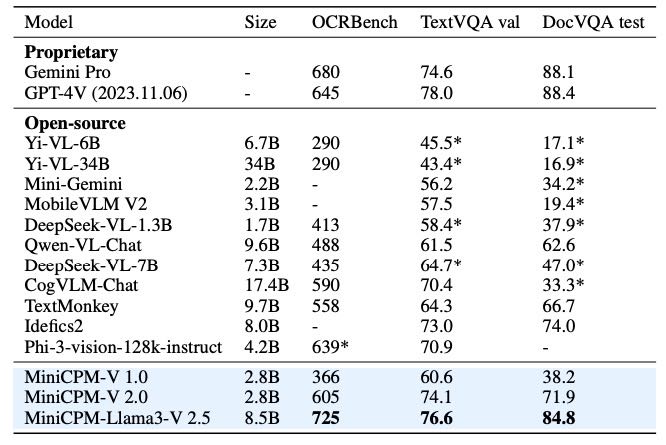
Table 5: Results on OCR benchmarks. *: our tested results with official checkpoints. The best results are marked in bold.
模型版本¶
MiniCPM-V 1.0:基本训练,无自适应视觉编码和RLAIF-V。
MiniCPM-V 2.0:加入完整训练流程 + 自适应视觉编码。
MiniCPM-Llama3-V 2.5:基于 Llama3-8B,加入RLAIF-V和多语言训练。
消融实验结论¶
RLAIF-V:有效降低幻觉率,提升可靠性,同时提升整体性能(OpenCompass +0.6)。
多语言训练:只需 <0.5% 的多语言SFT数据即可显著增强多语种能力(平均提升25+分)。
案例展示¶
OCR:能识别截图中的英文、中文、代码逻辑,并输出Markdown格式。
超宽图处理:可处理极端比例(如10:1)的高清图像,并识别细节。
多语言对话:支持德语、法语、日语、韩语、西班牙语等多语种。
响应更可信:幻觉更少,部分场景下比GPT-4V更可靠。
7. Conclusion¶
本文贡献:¶
我们提出了 MiniCPM-V 系列模型,探索了适用于终端设备的强大多模态大模型(MLLMs)。
通过一些关键技术(如自适应视觉编码、多语言泛化、RLAIF-V 方法等),MiniCPM-Llama3-V 2.5 用更少参数实现了接近 GPT-4V 的效果,并能在手机等设备上提供不错的使用体验。
局限性:¶
深度不足:多模态理解能力和推理效率仍有提升空间。
广度有限:目前只支持图像,未来应扩展到视频、音频等模态。
此外,终端部署面临挑战,如推理速度慢、电池限制、现有芯片和框架对 MLLM 支持不佳,仍需针对 MLLM 做专门优化。
未来方向:¶
未来将有更多学术界和工业界的努力,提升模型能力和终端部署效率。我们相信模型与设备能力同步提升后,终端应用将带来更好的用户体验。