2502.14282_PC-Agent: A Hierarchical Multi-Agent Collaboration Framework for Complex Task Automation on PC¶
组织: 中国科学院自动化研究所, 中国科学院大学, Alibaba Group, 北京交通大学, 上海科技大学
Abstract¶
🔍 背景介绍
在基于多模态大语言模型(MLLM, e.g., GPT-4V)的图形界面代理(GUI agents)领域,PC 场景相较于手机更复杂。 这体现在两个方面:
界面更复杂(多个窗口、组件、菜单等)
任务流程更复杂,包括:
同一应用内(intra-app)的多步骤操作
跨应用之间(inter-app)的协同,比如复制文件到压缩软件中再发送邮件
🧠 方法概览:提出了 PC-Agent 框架
为了解决这些问题,作者提出了一个分层多智能体框架,命名为 PC-Agent。
“分层”意味着他们把复杂任务拆分成更小的子任务,由不同角色的 agent 各司其职来协同完成。
👁️ 感知层:主动感知模块(APM)
从“感知”的角度来看,当前的 MLLM 对截图内容的理解能力还不够强,因此他们设计了一个 主动感知模块(APM)
提升模型对于 GUI(图形界面截图)中按钮、菜单、图标等内容的理解能力。
这个模块可能会让 agent 主动探索界面、定位关键元素,而不是被动等着输入截图。
🧩 决策层:层次化的多智能体协同架构
Instruction(指令):用户发出的复杂自然语言指令(如“把今天的 PPT 用 WinRAR 压缩后发邮件给张三”)
Subtask(子任务):将指令拆解为多个子任务(如打开文件夹 → 找到 PPT → 压缩 → 打开邮箱 → 发邮件)
Action(动作):每个子任务由若干具体动作组成(如点击按钮、输入文本、拖动文件等)
👥 三类 Agent + 1个反思 Agent
Agent 类型 |
职责 |
|---|---|
Manager |
负责将指令拆解成子任务 |
Progress |
追踪任务进展,确保当前完成到哪一步 |
Decision |
对每个子任务逐步做出操作决策 |
Reflection |
如果出现错误,它会反馈并调整策略,相当于一个“自我修正机制” |
🧪 实验&效果
他们还提出了一个新基准数据集 PC-Eval,包含了 25 个真实世界中的复杂任务指令。
在这个测试集上,他们的 PC-Agent 在任务成功率上比此前最好的方法提升了 32 个百分点,说明这个方法确实有效果。
✅ 总结一句话
PC-Agent 是一个为 PC 场景设计的多智能体系统,通过主动感知和层次化决策,显著提升了复杂任务自动化执行的成功率。
PC-Agent: A Hierarchical Multi-Agent Collaboration Framework for Complex Task Automation on PC
1. Introduction¶
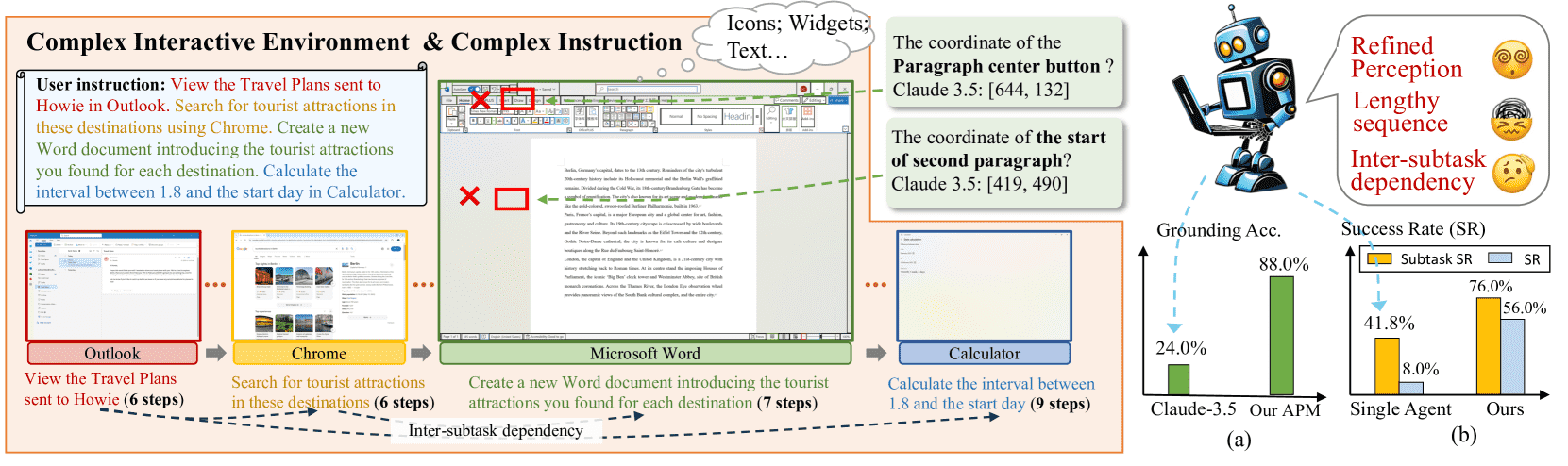
Figure 1:Illustration of the complexity of the PC scenario: (1) Complex interactive environment with dense and diverse elements. (2) Long and complex task sequences containing intra- and inter-software workflows.
🧠 背景
最近,多模态大语言模型(MLLM)在感知和推理方面取得了巨大进展,很多研究者把它们扩展成“多模态智能体”,用于辅助人类完成各类任务。
其中一个热门方向就是基于GUI的智能体,让模型像人类一样操作手机、电脑等智能设备。
💻 PC端的挑战
相比手机端,PC端任务的复杂性主要体现在两个方面:
交互界面更复杂
PC软件中有更密集、更复杂的控件(如Word的顶部菜单栏,有大量图标但没有文字说明)。
页面布局也更加多样(如代码编辑器 VS Code 和文字编辑器 Word),这对模型的“屏幕感知”提出了更高要求。
当前的MLLM即使很强(如 Claude-3.5),在感知这些图标和文字的功能上依然表现不佳,在GUI定位任务上的准确率只有24%。
任务流程更复杂
PC更常用于生产力场景,如旅行计划可能涉及打开浏览器、文档、邮件、日历等多个程序。
操作步骤更多(如一个任务可能有28步),还要考虑“前后步骤之间的依赖关系”(比如填写完申请表后,才能发送邮件)。
🧠 现有方法的局限
例如 UFO 提出双智能体架构:一个负责选择程序,另一个负责操作;但它感知能力不强。
Agent-S 结合在线搜索和本地记忆来增强规划;但也缺乏对屏幕文字的精细理解,也没考虑任务之间的依赖关系。
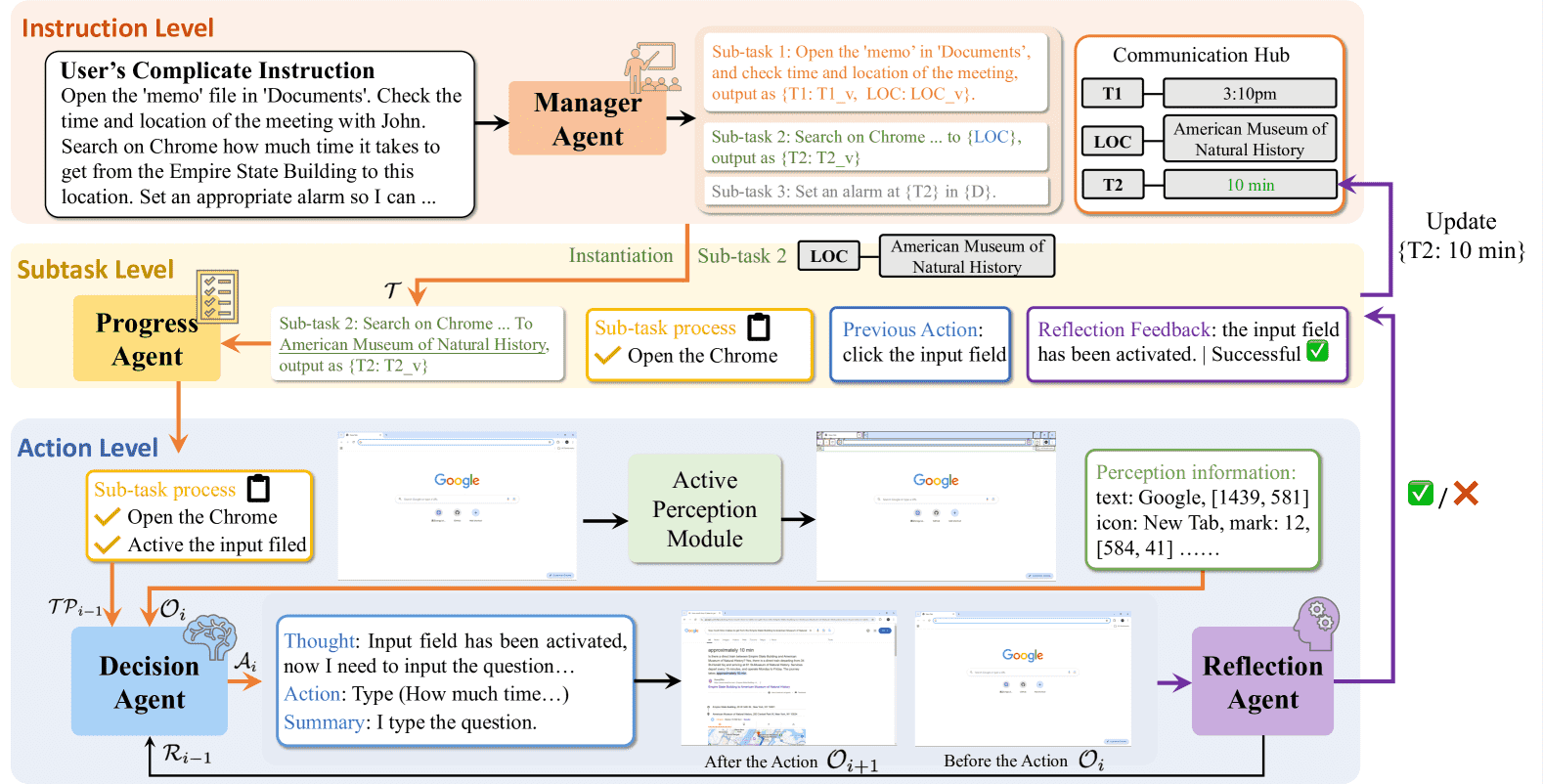
Figure 2:Overview of the proposed PC-Agent, which decomposes the decision-making process into three levels. The orange lines denote the top-down decision-making decomposition, and the purple lines represent the bottom-up reflection process.
💡 本文提出的解决方案:PC-Agent
主动感知模块(APM, Active Perception Module)
用于更精细的界面理解和操作。
利用可访问性树(accessibility tree)提取交互元素的位置和语义。
用MLLM理解意图,配合OCR精确识别目标文字位置。
分层多智能体协作架构(Hierarchical Multi-Agent Collaboration)
将决策过程分成三层:指令层 → 子任务层 → 操作层,分而治之:
Manager Agent(MA):将用户指令拆解为参数化的子任务,并处理任务之间的依赖。
Progress Agent(PA):跟踪任务进度,知道当前任务进行到哪一步。
Decision Agent(DA):根据PA的进度和APM的界面感知,逐步执行每一步操作。
反思机制(Reflection-based Dynamic Decision-making)
引入 Reflection Agent(RA):
在每一步操作后,观察屏幕变化,判断是否执行成功。
如果失败,及时反馈给DA和PA进行调整,实现“底向上的反思反馈”。
整个架构实现了 自顶向下的任务拆解 和 自底向上的反馈修正。
新基准 PC-Eval
涉及8个常见PC应用(如Word、Chrome、VS Code等)
包含25个真实复杂任务,每个任务都包含多个相互依赖的子任务
更真实地模拟生产力任务,强调“长序列决策”和“复杂任务依赖”
本文三点贡献总结:
提出PC-Agent框架,解决复杂PC界面和任务问题。
引入多智能体分层协作 + 反思机制,提升决策与适应能力。
构建新基准 PC-Eval,真实反映PC端任务复杂性,并验证了方法效果。
2. PC-Agent¶
2.1 Task Formulation¶
把“让一个GUI智能体(Agent)完成PC上的操作”这件事,抽象成了一个标准流程:
输入: 你给Agent一个用户指令(比如:”打开Word文档,改成加粗”),同时Agent可以看到环境观测(比如屏幕截图)。
推理+计划: Agent根据当前屏幕截图、过去的操作记录,以及用户指令,推理下一步该怎么做。
输出: Agent做出一个动作决策(比如:点击Word顶部的“加粗”按钮)。
执行动作: 这个动作会改变屏幕上的状态,然后进入下一步。
这个过程可以用一个公式来表示:
意思是:第 \(i\) 步的动作 \(\mathcal{A}_i\),是由Agent(\(\rho\))根据用户指令(\(\mathcal{I}\))、当前观测到的环境(\(\mathcal{O}_i\))、之前的操作历史(\(\mathcal{H}_{i-1}\))综合决定的。
2.2 Active Perception Module¶
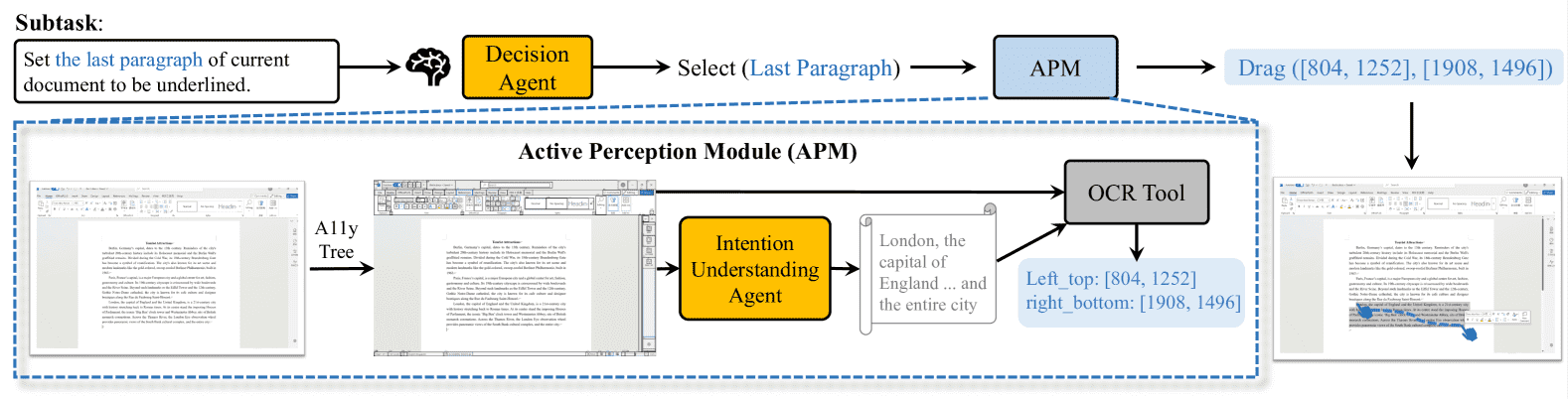
Figure 3:Illustration of the active perception module. For interactive elements, the A11y tree is adopted to obtain the bounding boxes and functional information. For text, an intention understanding agent and an OCR tool are utilized to perform precise selecting or editing.
1)交互元素感知(比如按钮、输入框)
用 pywinauto 这个库,去提取Windows界面的A11y树(无障碍树),这个树里面包含了:
界面上每个可交互元素的位置(坐标)
以及它们的功能描述(比如“保存按钮”)。
然后,在屏幕截图上,按照 SoM方法(一种把元素包围框标注到截图上、辅助MLLM理解的方法),给这些元素做上标注。
目的: 让MLLM能知道:屏幕上这些地方可以点、这些地方是什么意思。
2)文本感知(比如文档里的段落)
文本(比如Word里的文字)不能直接通过A11y树提取。
并且用户的指令经常是模糊的,比如:“把文档最后两段加粗”,并不会直接告诉你是哪几行。
怎么做?
先:Agent下达一个 “选中文本(target text)” 的动作。
再:用一个 MLLM驱动的意图理解Agent,根据当前指令和截图推理出需要选的文本范围。
最后:用OCR(文字识别工具)精确定位文字的实际位置,执行细粒度操作(比如拖动、选中、编辑)。
这个叫做主动感知,意思是智能体不是被动地接受界面内容,而是主动去理解并找到指令里提到的目标。
2.3 Hierarchical Multi-agent Collaboration¶
参考图2:Overview of the proposed PC-Agent
整体框架:三层架构
用户输入的复杂指令,被层层分解:
Instruction层(指令级)
Manager Agent (MA) 负责
把整体指令拆成多个小任务(Subtasks),并管理它们之间的数据流转关系。
Subtask层(子任务级)
Progress Agent (PA) 负责
跟踪每一个小任务的执行进度,帮助下层决策,同时反馈结果给Manager。
Action层(动作级)
Decision Agent (DA) 负责
一步步实际执行子任务操作,比如点击、输入文字等,直接控制PC。
把原本很复杂的一大坨指令,变成了: 指令 → 一组子任务 → 每个子任务一步步动作。
减少了单个Agent要处理的信息量,让决策更准确成功率更高。
2.3.1 Manager Agent (MA)
目标:
负责高层管理,把大指令拆分成小任务,并管理子任务之间的数据传递。
怎么做:
指令分解:
比如“打开Excel,整理表格,发邮件”,
会分成子任务:[打开Excel] → [编辑表格] → [发送邮件]。
子任务通信:
子任务之间可能有依赖关系,比如“编辑表格”必须在“打开Excel”之后。
MA负责记录每个子任务的输出,传给下一个子任务。
通信中心(communication hub)
相当于一个中转仓库,存子任务的执行结果,方便后续任务使用。
简单理解:Manager就是指挥官,负责把一场大作战拆成多个小分队任务,并协调他们之间的配合。
2.3.2 Progress Agent (PA)
目标
负责跟踪每个子任务的执行进度,并向DA和MA提供更新。
为什么需要它:
如果直接由MA记录所有执行细节,会太复杂;
而且DA每次决策都得看太长的历史,不方便。
怎么做:
每次动作执行后,PA记录当前子任务的进度。
当子任务完成时,PA把结果反馈给Manager。
给DA提供清晰简洁的历史信息,告诉它当前任务执行到了哪一步,还剩什么没做。
简单理解:Progress Agent像一个记录员,专门跟踪每个小分队的执行日志。
2.3.3 Decision Agent (DA)
目标:在环境中实际执行动作,一步步完成子任务。
怎么做:
感知环境:比如截图当前屏幕,识别应用界面(用感知模块获取Observation)。
结合历史和反思信息(PA和RA提供的),做出一步的决策,比如“点击‘文件’菜单”。
Chain-of-Thought推理:
DA先自己生成一段思考(Inner monologue),再决定下一步做什么。
这样推理更清晰、决策更稳妥。
动作执行:
决策被映射成标准动作,比如点击、输入、拖拽,使用pyautogui这样的库去实际操作PC。
限制动作空间(只有Click、Type、Drag等),让动作简单又容易解析。
简单理解:Decision Agent就是前线小兵,拿着命令,一步步具体去操作电脑。
2.4 Reflection-based Dynamic Decision-making¶
在一个复杂任务中,为了减少错误,提高成功率,系统设计了一个新的机制,叫做基于反思的动态决策机制(Reflection-based Dynamic Decision-making)。
为什么需要这个机制?
即使是很先进的多模态大模型(像 GPT-4o、Claude-3.5),也很容易在感知、推理中出错。
特别是操作步骤很长的任务,只要中间一步错了,整个任务就可能失败。
所以,需要一种方法,在每一步执行后及时检查有没有出错,并且及时纠正。
反思智能体(Reflection Agent, RA) 具体实现
设置位置:
在系统里,有一个决策智能体(DA,Decision Agent),它负责“决定做什么动作”。
同时,旁边并行地放一个反思智能体(RA),它观察动作执行前后的变化,判断这步操作是不是成功了。
RA的输入和输出:
输入包括:任务目标(𝒯)、这步动作(𝒜ᵢ)、动作前的观察结果(𝒪ᵢ₋₁)、动作后的观察结果(𝒪ᵢ)。
用公式写是: $\( \mathcal{R}_i = RA(\mathcal{T}, \mathcal{A}_i, \mathcal{O}_{i-1}, \mathcal{O}_i) \)$
简单理解:RA根据动作和前后系统状态,做出反思判断。
RA可能做出三种判断:
第一种情况:动作执行后,界面变化了,但变化不对(比如点击错了位置或者操作错了类型)。
→ 需要重新规划,改正错误。
第二种情况:动作执行后,界面没有变化。
可能是点击了无效的位置,比如点到一片空白,或者点了但界面没响应。
→ 需要调整动作的位置或方式。
第三种情况:动作执行后,界面变化是正确的。
→ 可以直接继续执行下一步。
如果发现异常怎么办?
RA会把反馈信息告诉DA(决策智能体),让DA可以根据反思结果,改正错误或者避免无效动作。
同时,RA也会把信息告诉PA(进度智能体,Progress Agent),让PA能更精准地追踪整个任务进度,及时发现哪里卡住了。
总结一下:
这段其实讲的是,为了防止一步错毁全局,他们在每次小操作后,用“反思智能体”检查动作是否成功,发现问题及时纠正,不是盲目往下走。这种设计,让系统在执行复杂任务时更加稳健、容错能力更强。
3. Experiments¶
3.1 PC-Eval¶
新提出的评测基准(比OSWorld、WindowsAgentArena复杂),包含25条复杂指令、79个子任务,涉及Chrome、Word、Excel、Notepad、Clock等应用。
目的:评估复杂真实PC操作任务,补充现有基准简单、脱离实际的问题。
特点:25条指令,79个子任务,涉及8款PC应用,强调长序列、跨应用、多依赖。
指标:指令成功率(SR),子任务成功率(SSR)。
Table 1: Examples of complex instructions in PC-Eval.
Applications |
Instruction |
Steps |
|---|---|---|
File Explorer Notepad, Clock Calculator |
In the Notepad app, open the ’travel_plan’ file in ’Documents’, and check the time and location of the travel plans. Add the travel destination to the World Clock list on the Clock app. Calculate the interval between February 18 and the start time of the travel on the Calculator. |
20 |
Chrome Excel |
Search on Chrome for the total population of China, the United States, and India in 2024 respectively. Create a new spreadsheet in Excel, write the three countries’ names in column A in descending order of population, and the corresponding populations in column B. |
23 |
File Explorer Word |
Open the ’test_doc1’ file in ’Documents’ in File Explorer, set the title to be bold, and set the line spacing of the first two paragraphs to 1.5x in Word. |
8 |
3.2 Result¶
单智能体方法(如GPT-4o)几乎无法完成,Qwen2.5-VL成功率最高仅12%。
多智能体方法(UFO、Agent-S)有提升,但整体SR仍低(12%-24%)。
PC-Agent显著领先:SSR 76.0%,SR 56.0%。
Table 2: Dynamic evaluation results on the PC-Eval benchmark.
Model |
Type |
Subtask SR (%) ↑ |
Success Rate (%) ↑ |
|---|---|---|---|
Gemini-2.0 |
Single-Agent |
35.4% |
0.0% |
Claude-3.5 |
15.2% |
0.0% |
|
Qwen2.5-VL |
46.8% |
12.0% |
|
GPT-4o |
41.8% |
8.0% |
|
UFO Zhang et al. (2024) |
Multi-Agent |
43.0% |
12.0% |
Agent-S Agashe et al. (2024) |
55.7% |
24.0% |
|
PC-Agent (Ours) |
76.0% |
56.0% |
3.3 Ablation Study¶
APM模块:主动感知模块对性能有显著的影响(SSR 下降了近 20%,而 SR 则急剧下降了 30%以上)。
Manager Agent:没有 MA,一条复杂的指令就会被看作是 PA 和 DA 的单个任务来执行(SR 显着下降至 12%)。
Reflection Agent:错误恢复机制关键(SSR 中下降 27.9%,SR 中下降 44.0%)。
3.4 Case Study¶
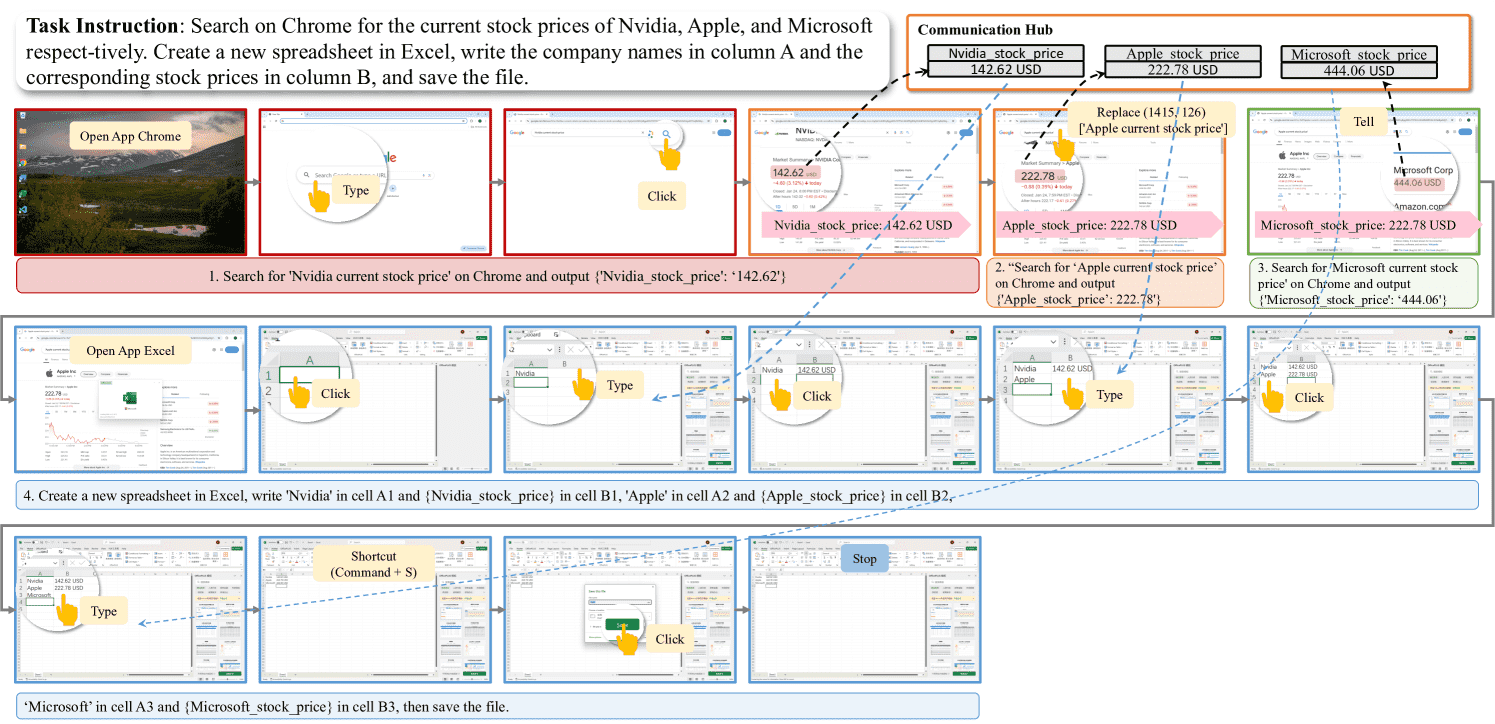
Figure 4:A case of searching for information multiple times and build an Excel sheet accordingly.
5. Conclusion¶
提出了 PC-Agent 框架
目标是应对PC端复杂环境和任务。
关键技术
APM模块:提升感知和操作的精细度。
分层多智能体架构:把决策流程分为三层,逐层解决复杂问题。
基于反思的动态决策:可以及时发现错误并调整。
构建了新的评测基准
PC-Eval:包含真实、复杂的用户指令,用来测试系统能力。
实验结果
PC-Agent在复杂PC任务上明显优于现有方法。
总结:
本文通过引入细粒度感知、多层次决策和动态反思机制,成功打造了一个在复杂PC任务上表现优异的PC-Agent系统。
A.3 Action Space¶
We define the action space as follows:
Open App (name): Open a specific app using the system’s search function.
Click (x, y): Click the mouse at position (x, y).
Double Click (x, y): Click the mouse twice at position (x, y).
Select (text): Acquire the content and position of the target text by invoking the active perception module (APM).
Type (x, y) [text]: Input text content at position (x, y).
Drag (x1, y1) (x2, y2): Select a specific area of text content by dragging.
Scroll (x, y) (value): Scroll the page up or down at position (x, y).
Shortcut (key list): Use shortcut keys, such as saving through ctrl+s.
Stop: All the requirements have been met, end the current process.