2303.11366_Reflexion: Language Agents with Verbal Reinforcement Learning¶
组织:多个美国大学
Large language models (LLMs) have been increasingly used to interact with external environments (e.g., games, compilers, APIs) as goal-driven agents. However, it remains challenging for these language agents to quickly and efficiently learn from trial-and-error as traditional reinforcement learning methods require extensive training samples and expensive model fine-tuning. We propose Reflexion, a novel framework to reinforce language agents not by updating weights, but instead through linguistic feedback. Concretely, Reflexion agents verbally reflect on task feedback signals, then maintain their own reflective text in an episodic memory buffer to induce better decision-making in subsequent trials. Reflexion is flexible enough to incorporate various types (scalar values or free-form language) and sources (external or internally simulated) of feedback signals, and obtains significant improvements over a baseline agent across diverse tasks (sequential decision-making, coding, language reasoning). For example, Reflexion achieves a 91% pass@1 accuracy on the HumanEval coding benchmark, surpassing the previous state-of-the-art GPT-4 that achieves 80%. We also conduct ablation and analysis studies using different feedback signals, feedback incorporation methods, and agent types, and provide insights into how they affect performance.
大型语言模型 (LLMs) 已越来越多地用于与外部环境(例如,游戏、编译器、API)作为目标驱动的代理进行交互。然而,由于传统的强化学习方法需要大量的训练样本和昂贵的模型微调,因此对于这些语言代理来说,快速有效地从试错中学习仍然具有挑战性。我们提出了 Reflexion,这是一种新颖的框架,它不是通过更新权重,而是通过语言反馈来增强语言代理。具体来说,反射代理口头反思任务反馈信号,然后在情景记忆缓冲区中保留自己的反思文本,以在随后的试验中诱导更好的决策。反射足够灵活,可以整合各种类型的反馈信号(标量值或自由格式语言)和源(外部或内部模拟),并在各种任务(顺序决策、编码、语言推理)中比基线代理获得显着改进。例如,Reflexion 在 HumanEval 编码基准上实现了 91% 的pass@1准确率,超过了之前最先进的 GPT-4 达到 80% 的准确率。我们还使用不同的反馈信号、反馈结合方法和代理类型进行消融和分析研究,并深入了解它们如何影响性能。
最近的工作,如
ReAct,SayCan,Toolformer,HuggingGPT,enerative agents和WebGPT已经证明了建立在大型语言模型 (LLM) 核心之上的自主决策代理的可行性。这些方法用于LLMs生成文本和“操作”,这些文本和“操作”可以在 API 调用中使用并在环境中执行。由于它们依赖于具有大量参数的大规模模型LLM,因此到目前为止,这些方法仅限于使用上下文示例作为提示Agent的一种方式,因为更传统的优化方案(如具有梯度下降的强化学习)需要大量的计算和时间。Reflexion 使用语言强化来帮助智能体从先前的失败中学习。Reflexion 将来自环境的二进制或标量反馈以文本摘要的形式转换为口头反馈,然后在下一集中将其添加为LLM代理的附加上下文。这种自我反思的反馈充当了“语义”梯度信号,为智能体提供了一个具体的改进方向,帮助智能体从以前的错误中学习,从而在任务中表现得更好。这类似于人类如何迭代地学习以几次成功的方式完成复杂的任务——通过反思他们之前的失败,以便为下一次尝试形成一个改进的攻击计划。
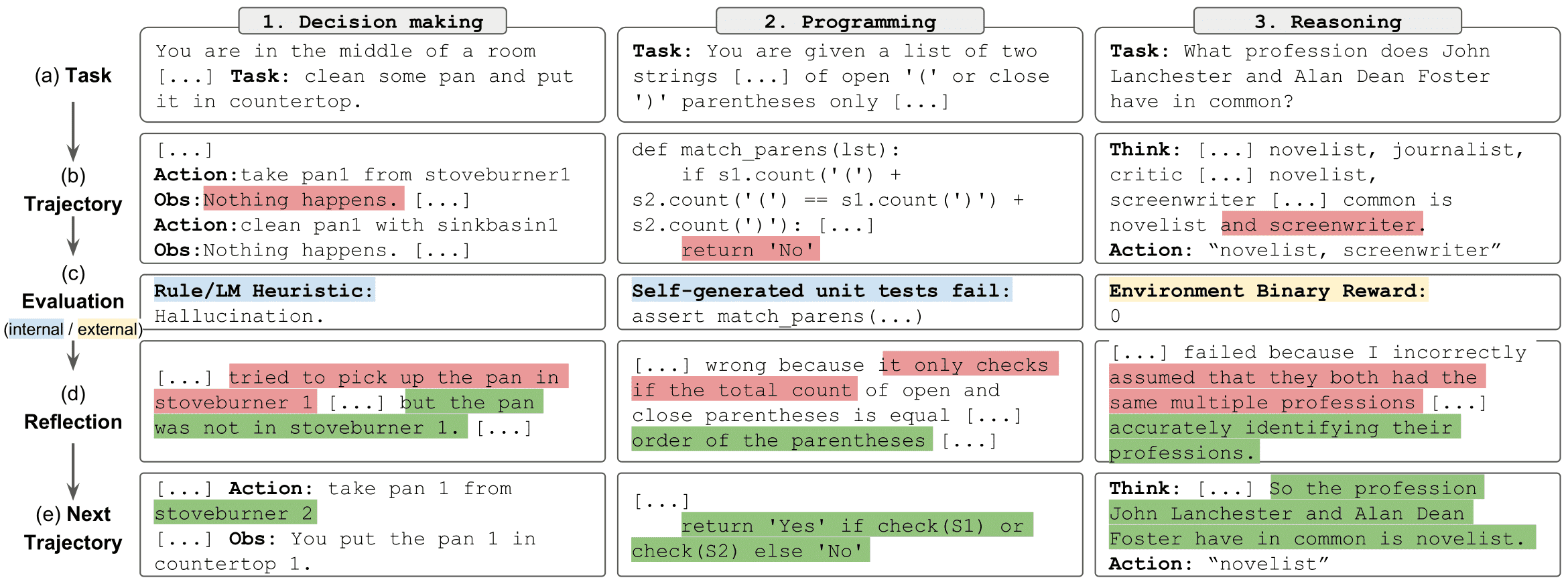
反思适用于决策 4.1、编程 4.3 和推理 4.2 任务。¶
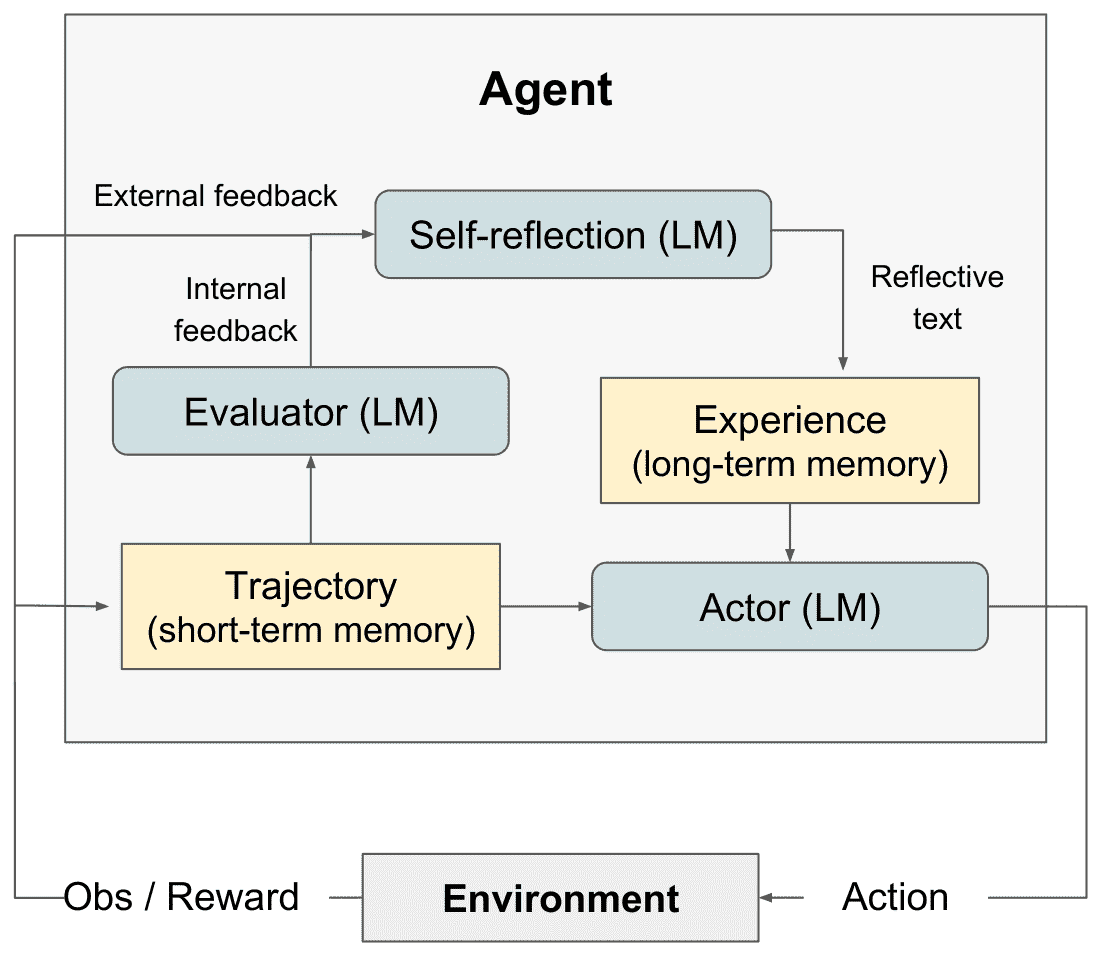
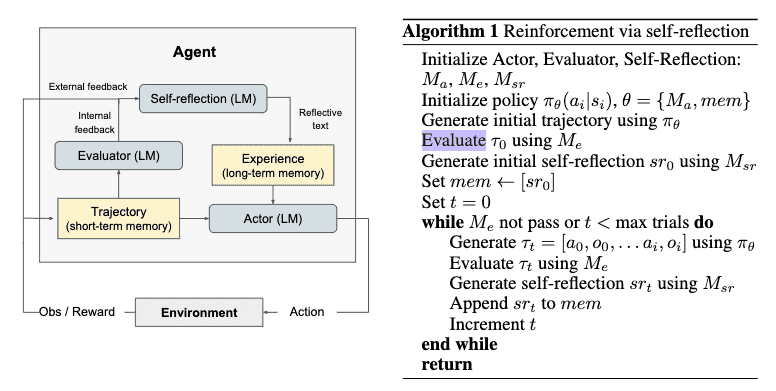
Figure 2: (a) Diagram of Reflexion. (b) Reflexion reinforcement algorithm¶
Actor:Actor 建立在一个大型语言模型 (LLM) 之上,该模型被专门提示生成必要的文本和操作。
Evaluator:Reflexion 框架的评估者组件在评估 Actor 产生的生成输出的质量方面起着至关重要的作用。它采用生成的轨迹作为输入,并计算出反映其在给定任务上下文中的表现的奖励分数。
Self-reflection:自我反思模型实例化为 LLM,在反思框架中起着至关重要的作用,它通过产生口头自我反思为未来的试验提供有价值的反馈。
Memory:反射过程的核心组成部分是短期记忆和长期记忆的概念。在推理时,Actor 根据短期和长期记忆来调节其决策,类似于Actor将其对短期和长期记忆的决策进行调整,以适应人类记住最近细粒度的细节的方式,同时也回忆起从长期记忆中提炼出的重要经历。
The Reflexion process:
Actor:The Actor is built upon a large language model (LLM) that is specifically prompted to generate the necessary text and actions conditioned on the state observations
Evaluator:The Evaluator component of the Reflexion framework plays a crucial role in assessing the quality of the generated outputs produced by the Actor. It takes as input a generated trajectory and computes a reward score that reflects its performance within the given task context.
Self-reflection:The Self-Reflection model instantiated as an LLM, plays a crucial role in the Reflexion framework by generating verbal self-reflections to provide valuable feedback for future trials.
Memory:Core components of the Reflexion process are the notion of short-term and long-term memory. At inference time, the Actor conditions its decisions on short and long-term memory, similar to the way that humans remember fine-grain recent details while also recalling distilled important experiences from long-term memory.
The Reflexion process:

示例:附录B Decision-making¶

示例:附录D1 Reasoning-Full example¶

示例:附录D2 Chain-of-Thought + Reflexion¶

示例:附录D3 HotPotQA Chain-of-Thought (GT) + Reflexion¶