2404.07972_OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments¶
GoogleScholar(star: 103)
组织: 香港大学, CMU(Carnegie Mellon University), Salesforce Research, University of Waterloo
Abstract¶
Autonomous agents that accomplish complex computer tasks with minimal human interventions have the potential to transform human-computer interaction, significantly enhancing accessibility and productivity.
However, existing benchmarks either lack an interactive environment or are limited to environments specific to certain applications or domains, failing to reflect the diverse and complex nature of real-world computer use, thereby limiting the scope of tasks and agent scalability.
To address this issue, we introduce OSWORLD, the first-of-its-kind scalable, real computer environment for multimodal agents, supporting task setup, execution-based evaluation, and interactive learning across various operating systems such as Ubuntu, Windows, and macOS.
OSWORLD can serve as a unified, integrated computer environment for assessing open-ended computer tasks that involve arbitrary applications.
Building upon OSWORLD, we create a benchmark of 369 computer tasks involving real web and desktop apps in open domains, OS file I/O, and workflows spanning multiple applications.
Each task example is derived from real-world computer use cases and includes a detailed initial state setup configuration and a custom execution-based evaluation script for reliable, reproducible evaluation.
Extensive evaluation of state-of-the-art LLM/VLM-based agents on OSWORLD reveals significant deficiencies in their ability to serve as computer assistants.
While humans can accomplish over 72.36% of the tasks, the best model achieves only 12.24% success, primarily struggling with GUI grounding and operational knowledge.
Comprehensive analysis using OSWORLD provides valuable insights for developing multimodal generalist agents that were not possible with previous benchmarks.
备注
OSWORLD 是一个 真实计算机环境,专门用于测试 AI 在实际计算机任务中的表现。现有 AI 代理在 GUI 交互和操作知识方面存在明显不足,远未达到人类水平。OSWORLD 通过大规模、多样化的任务,提供了改进 AI 计算机智能的新方向。
1. Introduction¶
本章主要讲了一种新的计算机交互环境 OSWORLD,专门用于研究和训练多模态人工智能(AI)代理,使其能够在真实计算机环境中执行复杂任务。
- 背景与挑战
人类与计算机交互通常依赖图形界面(GUI)和命令行(CLI),涉及网页浏览、视频编辑、文件管理、数据分析、软件开发等任务。
AI 代理(如大模型驱动的自动化助手)可以通过自然语言指令执行任务,提升效率并降低使用门槛。
- 挑战:
缺乏真实的交互环境:现有的基准测试(benchmark)只提供数据集,而没有可执行的交互环境,使得AI模型只能学习静态数据,无法进行真实交互和探索。
评估方式不合理:现有测试默认每个任务只有唯一的正确解法,导致其他正确方案被误判为错误,并且无法支持交互式学习。
- 现有研究的局限
- 过去的一些研究尝试建立可执行环境,但大多局限于特定应用或任务:
仅限网页导航(如特定网站的操作)
仅限编程任务
仅支持单一应用,无法模拟真实世界中需要跨应用、多界面的复杂任务。
- OSWORLD 的创新
首个可扩展的真实计算机环境,支持多模态 AI 代理执行多种实际计算机任务,而不是受限于特定应用。
- 特点:
真实交互:支持键盘和鼠标操作,而不仅限于模拟数据。
多操作系统兼容:支持 Ubuntu、Windows、macOS。
任务覆盖广:涵盖从图像浏览到软件集成功能和编程等任务。
无需特定的模拟环境,用户可以自由定义任务,而不用创建单独的应用环境。
总结:OSWORLD 是一个 全新的、真实的计算机环境,用于训练和评估 AI 代理的能力,使其能够完成复杂的多应用任务。然而,当前最先进的大模型(如 GPT-4V、Gemini 等)在这些任务上的表现仍然远远不及人类,暴露出 GUI 交互、操作稳定性、任务泛化能力 等问题。OSWORLD 的开源有助于推动该领域的发展,未来的研究将围绕 提升 AI 代理的 GUI 交互能力和任务执行智能 展开。
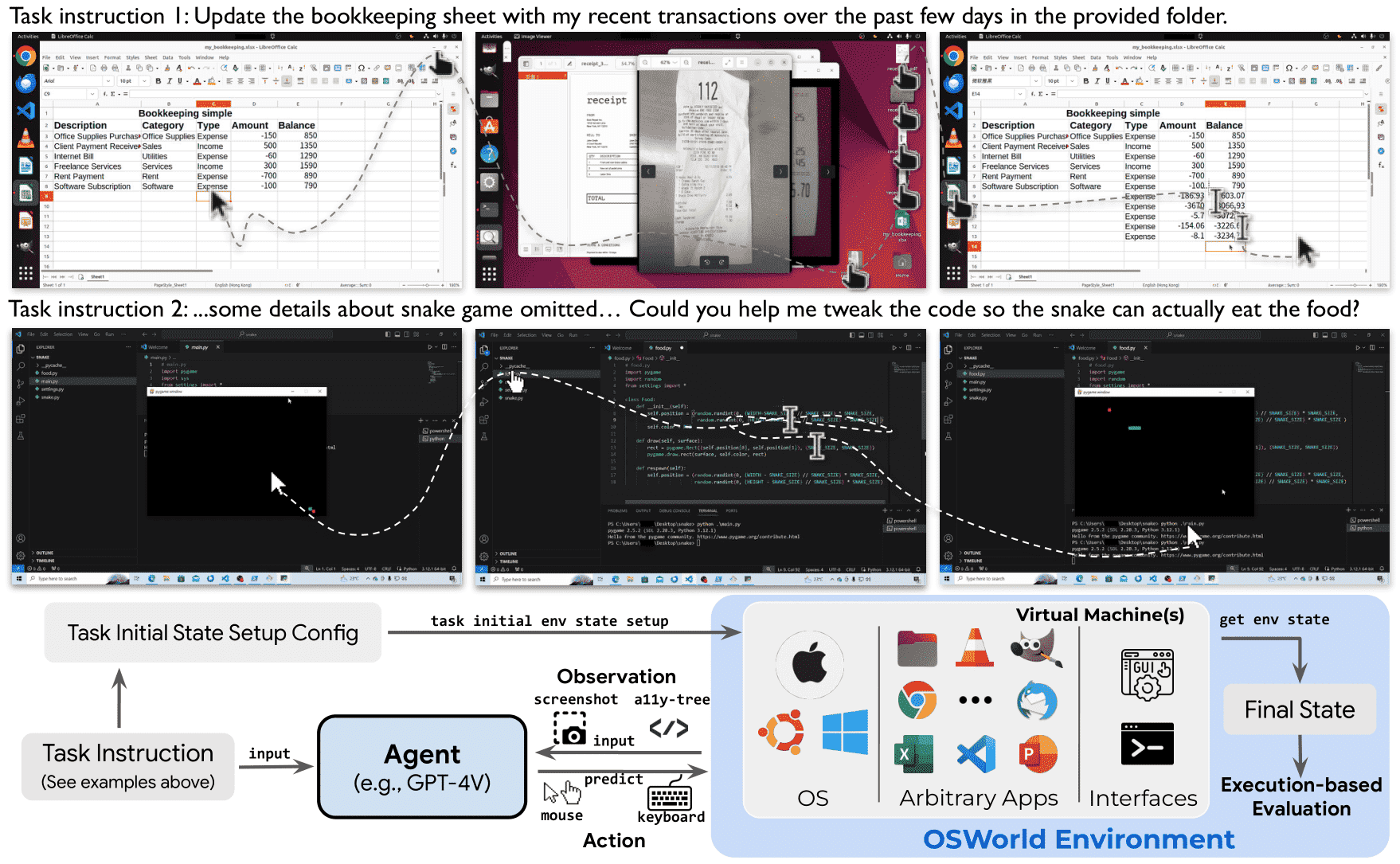
Figure 1: OSWORLD is a first-of-its-kind scalable, real computer environment for multimodal agents, supporting task setup, execution-based evaluation, and interactive learning across operating systems. It can serve as a unified environment for evaluating open-ended computer tasks that involve arbitrary apps (e.g., task examples in the above Fig). We also create a benchmark of 369 real-world computer tasks in OSWORLD with reliable, reproducible setup and evaluation scripts.¶
2. OSWORLD Environment¶
OSWorld: 一个用于训练和评估自动化数字代理(autonomous digital agents)的计算机环境。它的核心目标是在真实计算机环境中(如Ubuntu、Windows、macOS)模拟和测试AI代理如何执行复杂的计算机任务,例如操作软件、管理文件、执行网页任务等。
2.1 Task Definition¶
OSWORLD 将代理的任务建模为部分可观察的马尔可夫决策过程(POMDP)
- 核心要素包括:
状态空间 (S):表示计算机的状态,比如当前打开的窗口、文件等。
观察空间 (O):代理获取的信息,包括自然语言指令、屏幕截图、辅助功能(a11y)树等。
动作空间 (A):代理可以执行的操作,如点击鼠标、按键组合等。
状态转移函数 (T):描述代理执行操作后,计算机状态如何变化。
- 奖励函数 (R):衡量代理任务完成的效果,例如:
成功完成任务或部分完成 → 奖励 1 或小于 1 的正数
任务失败或执行无效操作 → 奖励 0
正确预测任务不可行 → 也可能获得奖励
- 代理的交互流程是:
观察当前状态(o_t)
选择并执行动作(a_t)
进入新的状态(s_{t+1})并观察新的环境(o_{t+1})
循环进行,直到执行终止操作(DONE/FAIL)或达到最大步数(如实验中设定的15步)。
2.2 Real Computer Environment Infrastructure¶
OSWORLD 运行在虚拟机(VM)中,以确保安全性,并且可以随时恢复快照,避免对真实主机造成不可逆影响。
- 2.2.1 Overview
- 任务管理器(Task Manager)使用配置文件初始化环境,比如:
恢复特定的虚拟机快照(即恢复到任务开始前的某个计算机状态)
下载相关文件
打开软件、调整窗口布局
代理开始与环境交互,执行鼠标、键盘等操作,虚拟机模拟这些输入。
- 2.2.2 Initial Task Environment Setup
真实世界中的计算机任务往往发生在中间状态(例如软件已打开,或系统崩溃后恢复),而不是计算机刚启动时。
OSWORLD 采用混合方法进行任务恢复,而不是简单的快照恢复,以减少存储占用(避免每个任务存储大量不必要的硬件状态信息)。
- 初始化过程分为:
启动虚拟机
下载任务相关文件(可选)
执行预处理命令(如打开文件、调整窗口大小)
- 2.2.3 Execution-Based Evaluation
- 计算机任务的成功标准难以统一衡量,因此 OSWORLD 采用具体任务定制的评估方法:
解析软件的内部文件(如 Chrome Cookie、VS Code 插件)
结合逆向工程工具(如解密 Thunderbird 账户信息)
采集实时数据(如网页爬取某个论文的引用数量)
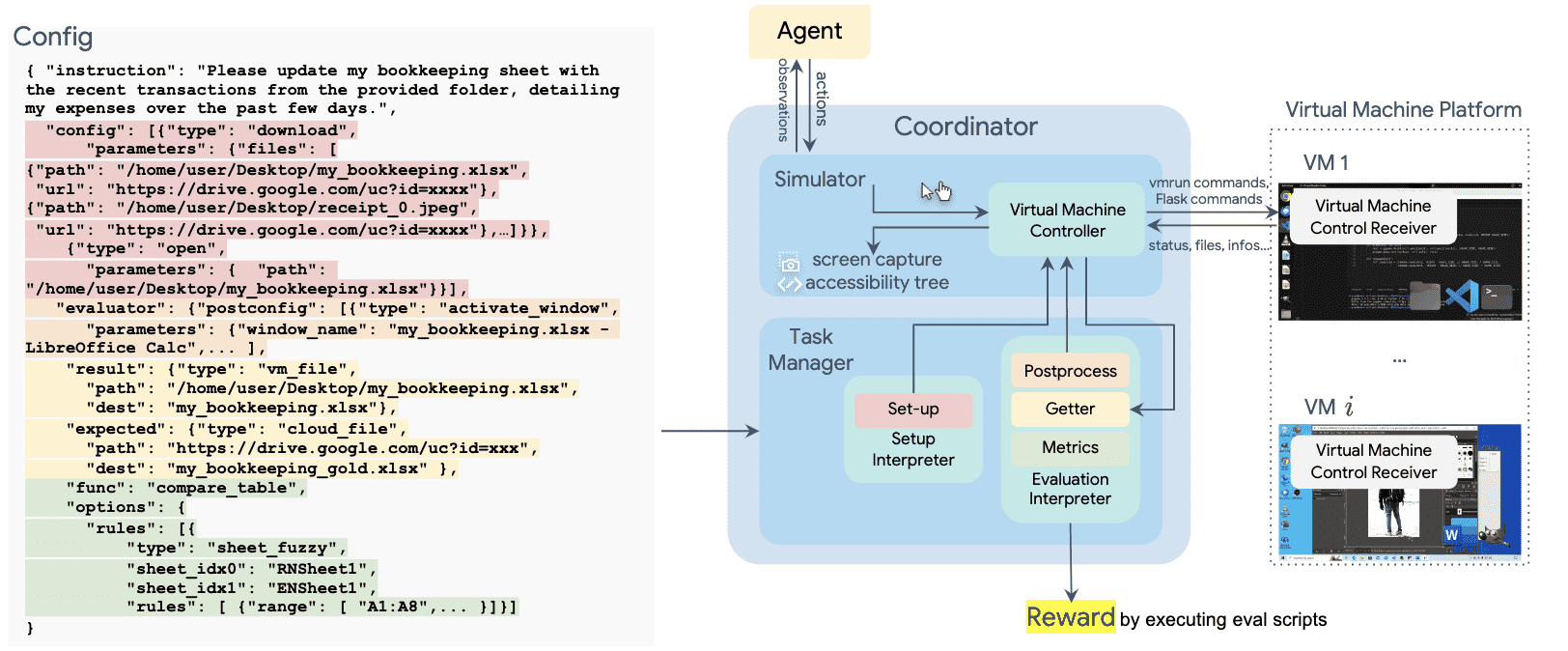
Figure 2: Overview of the OSWORLD environment infrastructure. The environment uses a configuration file for initializing tasks (highlighted in red), agent interaction, post-processing upon agent completion (highlighted in orange), retrieving files and information (highlighted in yellow), and executing the evaluation function (highlighted in green). Environments can run in parallel on a single host machine for learning or evaluation purposes. Headless operation is supported.¶
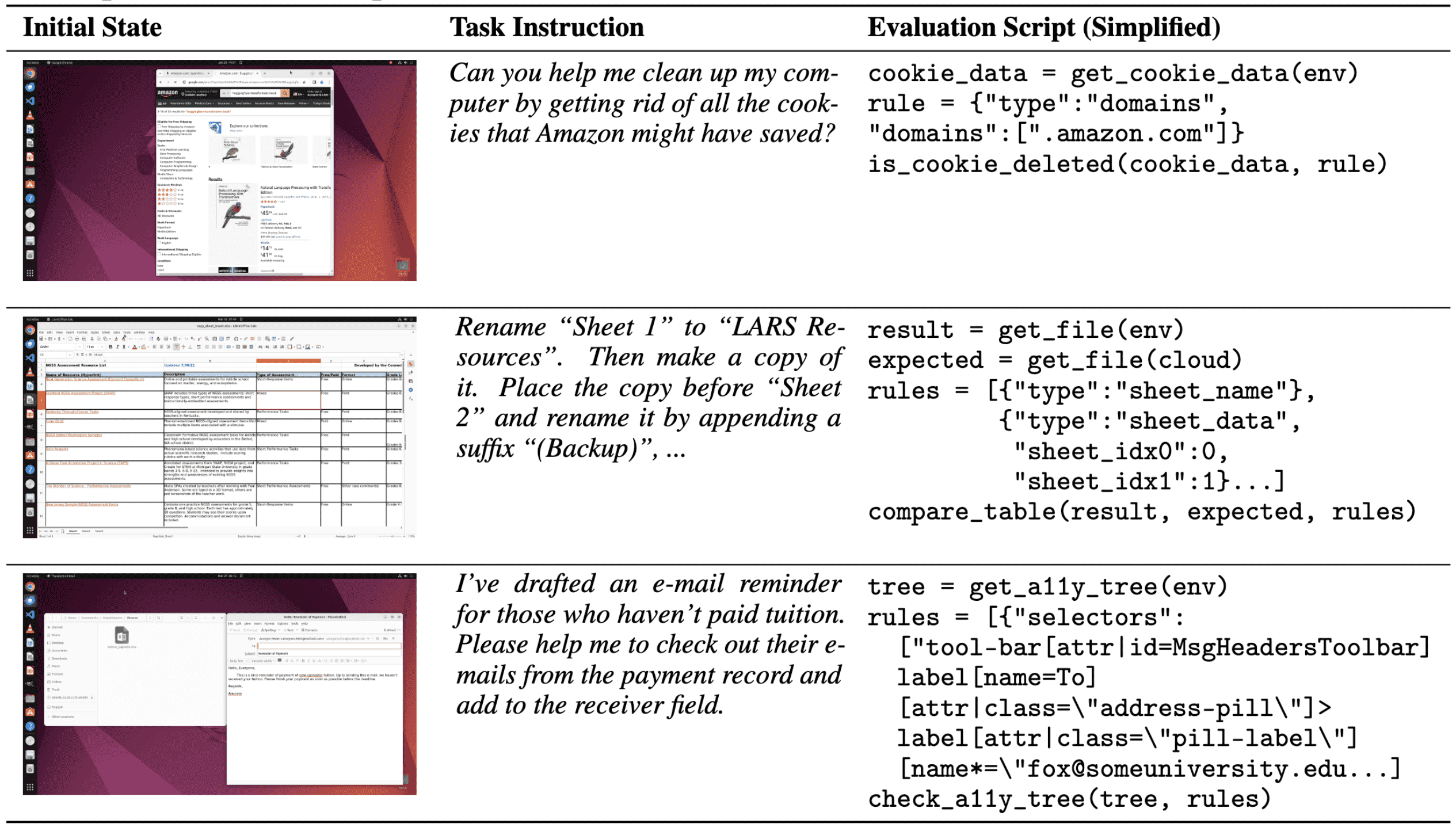
Table 1: Examples of our annotated evaluation scripts, which involve retrieving data from configuration files, the environment, and the cloud, and executing functions to assess functional correctness andobtain results. The example-wise evaluation facilitates the diversity of tasks and reliable evaluationof complex, real-world, open-ended tasks.¶
2.3 Observation Space¶
- 代理在 OSWORLD 中可以获取的信息包括:
屏幕截图(包括鼠标位置、应用窗口、文件夹)
辅助功能(a11y)树(类似网页 DOM 结构,提供软件界面结构信息)
自定义数据流(如终端输出)
- 这些信息允许代理与多个应用进行复杂交互,但也带来了挑战,例如:
高分辨率屏幕截图(如 4K)增加计算成本
结构化文本(如辅助功能树)导致决策路径变长
2.4 Action Space¶
- OSWORLD 的动作空间包括:
鼠标操作(移动、单击、右击、拖动)
键盘操作(按键、快捷键)
等待 (WAIT)、任务完成 (DONE)、任务失败 (FAIL)
代理需要生成符合 PyAutoGUI 语法的 Python 代码,例如:
.click(300, 540, button='right') # 右键点击坐标 (300, 540) .hotkey('ctrl', 'alt', 't') # 按下 Ctrl + Alt + T 组合键
此外,OSWORLD 允许在程序结构中嵌入动作(如 for 循环),增强表达能力。
- 相比 Web 端代理(如 MiniWoB++、CC-Net、WebArena),OSWORLD 的动作空间更完整,支持所有计算机操作,包括:
右键点击
按住 Ctrl 选择多个项目
复杂的鼠标键盘组合

Table 2: Some examples of the mouse and keyboard actions A in OSWORLD. See App. A.3 for the completelist.¶
总结¶
- OSWORLD 是一个用于训练和评估 AI 代理的计算机操作环境,核心特点包括:
基于 POMDP 任务建模,支持部分可观察的环境。
虚拟机执行任务,确保安全,并能随时恢复快照。
支持复杂的观察空间,包括屏幕截图、辅助功能树等。
完整的动作空间,涵盖所有可能的计算机交互方式。
自定义任务评估方法,使用文件解析、逆向工程、实时爬取等方式评估任务成功与否。
这个环境适用于训练 AI 代理来操作真实计算机任务,并且比基于 Web 的 AI 代理平台更接近实际计算机操作逻辑。
3. OSWORLD Benchmark¶
OSWORLD 基准测试包括 369 个基于 Ubuntu 的真实计算任务,并提供 43 个 Windows 任务,用于测试 AI 代理在操作系统上的任务执行能力。
这些任务涵盖了各种应用程序的使用,包括 Chrome、VLC、Thunderbird、VS Code、LibreOffice、GIMP 以及基本的系统应用(终端、文件管理器、PDF 查看器等)。
OSWORLD 是一个针对 真实计算机环境 的 AI 任务基准,覆盖 单应用、跨应用和系统操作任务,并提供 详细的评估机制,相比于以往的基准(如 WebArena)更接近实际用户需求,且任务难度更高。
3.1 Operating System and Software Environments¶
支持真实操作系统(Windows、macOS 和 Ubuntu),使得 AI 代理可以在真实计算环境中执行任务,而不是在模拟环境中。
- 任务种类丰富:
单一应用任务(如编辑 Excel 表格、编写 Python 代码)。
跨应用任务(如在 Chrome 里查找信息并复制到 LibreOffice)。
系统操作任务(如管理文件、调整设置)。
- 任务设计方式:
任务来源广泛,包括 论坛、教程、Q&A 论坛(如 Reddit、StackOverflow)、在线课程(如 Coursera、Udemy),甚至 TikTok、YouTube 教程。
部分任务涉及 不可能完成的任务(如因为软件更新导致的功能失效),共 30 个,以测试 AI 对“无法完成”的识别能力。
任务的多样性使 OSWORLD 在复杂性和评估能力上超过许多现有基准(如 WebArena)。
- 八个代表性应用程序以及系统提供的基本应用程序:
用于网页浏览的 Chrome、
用于媒体播放的 VLC、
用于电子邮件管理的 Thunderbird、
作为编码 IDE 的 VS Code
分别用于处理电子表格、文档和演示文稿的 LibreOffice(Calc、Writer 和 Impress)、
用于图像编辑的 GIMP
其他基本操作系统应用程序,如终端、文件管理器、图像查看器和 PDF 查看器。
3.2 Tasks¶
- 任务的执行环境
任务在 虚拟机(VM) 中进行,确保每次任务都有一致的初始状态。
通过 API 控制应用程序(例如用 pyautogui 控制 GUI 交互),模拟真实用户操作。
- 任务评估方式
任务完成后,会自动运行 评估脚本 来检测是否成功完成。
评估方式基于 执行结果,例如检测最终生成的文件是否符合预期,而不是简单的预测 AI 的下一步操作。
共开发了 134 种独立的评估函数,比以往的基准更丰富。
- 质量控制
每个任务由 两位未参与标注的作者进行测试,确保任务说明清晰、可执行,并修复可能存在的问题。
在实验过程中,四轮测试共投入 400 小时 进一步修正任务,减少误判和错误。
3.3 Data Statistics¶
任务总数:369(Ubuntu)+ 43(Windows)。
- 任务类型:
单一应用任务:268(72.6%)。
跨应用任务(涉及多个软件协作):101(27.4%)。
不可能完成的任务:30(8.1%)。
来自其他数据集的任务(如 NL2Bash、Mind2Web):84(22.8%)。
初始状态种类:302 种。
评估脚本种类:134 种。
- OSWORLD 相比于其他基准(如 WebArena、NL2Bash)有以下优势:
使用真实鼠标键盘操作,而不是 API 调用或网页模拟,适用于更广泛的软件环境。
支持多模态交互,不仅限于文本,还包括 GUI 操作(鼠标点击、窗口拖拽)。
提供完整的可执行环境,允许 AI 代理在实际操作系统上进行任务,而非仅提供静态数据。
涵盖跨应用任务,比如从浏览器复制内容到 Excel,而不仅仅是单一应用操作。
提供更丰富的评估方法,拥有 134 种基于执行结果的自动评估函数。
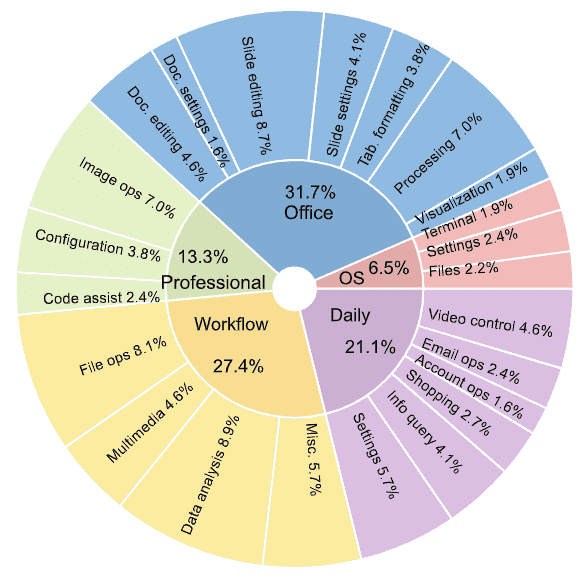
Figure 3: Distribution of task instructions in OSWORLD based on the app domains and operation types to showcase the content intuitively.¶
3.4 Human Performance¶

Table 4: Comparison of different environments for benchmarking digital agents.¶
- The columns indicate:
the number of task instances and templates (if applicable) where the task instantiated from templates through configurations (# Instances (# Templates)),
whether they provide a controllable executable environment (Control. Exec. Env.),
the ease of adding new tasks involving arbitrary applications in open domains (Environment Scalability),
support for multimodal agent evaluation (Multimodal Support),
support for and inclusion of cross-app tasks (Cross-App),
capability to start tasks from an intermediate initial state (Intermediate Init. State),
the number of execution-based evaluation functions (# Exec.-based Eval. Func.).
OSWORLD 任务由 计算机专业的大学生 进行测试,记录任务完成时间和正确率。
- 平均完成时间:
OSWORLD 任务的中位数完成时间 111.94 秒。
对比 WebArena,WebArena 的任务仅 35.38 秒,表明 OSWORLD 任务更复杂。
甚至有部分任务需要 900 秒以上 完成。
- 任务完成正确率:
OSWORLD 任务的平均正确率 72.36%,远低于 WebArena 的 88%。
说明 OSWORLD 任务更具挑战性,对 AI 代理提出更高要求。
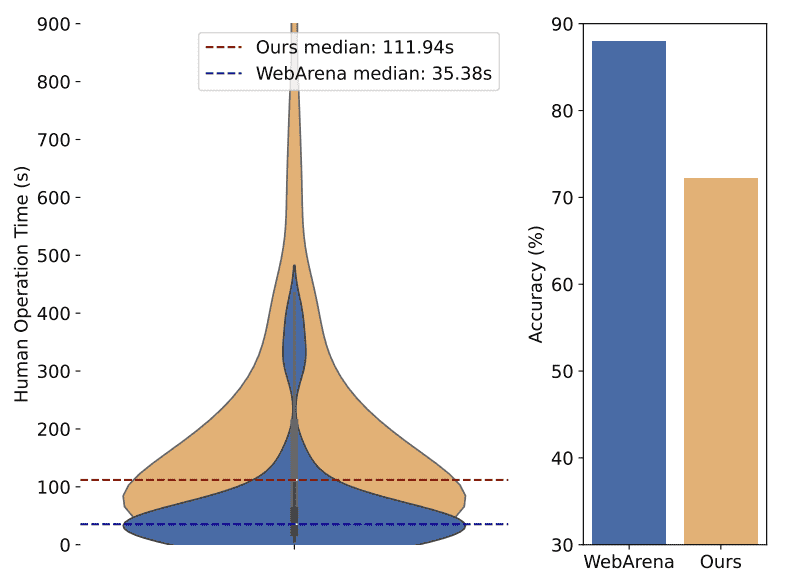
Figure 4: Human operation time and accuracy on OSWORLD and WebArena.¶
4. Benchmarking LLM and VLM Agent Baselines¶
本章主要是关于在 OSWORLD 基准测试 上评估 LLM(大语言模型)和 VLM(视觉语言模型)代理 的实验细节、输入方法以及性能分析。
这段内容分析了大语言模型(LLM)和视觉语言模型(VLM)在 OSWORLD 基准测试上的表现,发现它们在 GUI 任务上的表现仍然远远不如人类,尤其是复杂的多软件交互任务。尽管有些增强方法(如 SoM)被证明在传统任务中有效,但在高分辨率、坐标精确度要求高的任务中,它们的作用仍然有限。未来,纯视觉智能体可能是一个值得探索的方向,但当前 VLM 仍需大幅改进才能真正用于计算机操作任务。
4.1 LLM and VLM Agent Baselines¶
- 研究目标
测试 LLM 和 VLM 代理 在 OSWORLD 上的表现,评估其执行计算机任务(如 GUI 操作)的能力。
采用开源模型(如 Mixtral、CogAgent、Llama-3)以及闭源模型(如 GPT、Gemini、Claude、Qwen)。
引入 Set-of-Marks(SoM)方法 以提高 VLM 的视觉推理能力。
- 输入方式(实验设定) - 实验采用了 4 种不同的输入方式来测试 LLM 和 VLM 代理的能力:
- Accessibility tree(可访问性树)
以文本格式表示 GUI 界面的结构信息(如标签、文本、位置等)。
由于原始 XML 数据量过大(包含冗余信息),实验中进行了过滤,仅保留核心内容。
- Screenshot(截图)
直接将计算机屏幕截图输入到 VLM,让模型通过图像理解界面并执行操作。
分辨率设置:1920 × 1080,并进行不同分辨率的对比实验。
- Screenshot + Accessibility tree(截图+可访问性树)
结合可访问性树和截图,评估这种混合输入是否有助于提升 VLM 在 GUI 任务上的表现。
- Set-of-Marks(SoM)
在截图上标注 UI 元素(例如用编号框标记界面中的按钮、文本框等)。
代理通过识别编号来执行操作,而不是直接预测坐标。
4.2 Results¶
- 1)LLM 和 VLM 仍然远远落后于人类
- 模型成功率普遍较低:
仅使用截图(Screenshot-only)时,GPT-4V 和 Gemini-Pro-Vision 的成功率在 5.26% ~ 5.80% 之间。
仅使用可访问性树(a11y tree)时,最高成功率为 12.24%。
人类完成同样任务的成功率为 72.36%,远高于模型。
- 低成功率的原因:
LLM 缺乏历史上下文编码(prompt 方案调整后略有提升)。
LLM/VLM 在不同软件类型上的表现差异大(CLI 任务比 GUI 任务表现更好)。
多软件交互任务(如工作流)更难,成功率一般低于 5%。
- 2)任务类型影响模型表现
命令行(CLI)任务 相比 GUI 任务(如 Office 软件操作)更容易完成。
涉及多个软件的工作流任务(如从 Excel 复制数据到 Word)成功率极低(<5%)。
不同模型的偏差较大,成功率差距可达 20%。
- 3)A11y Tree 和 SoM 在不同模型上的效果不同
在 GPT-4V 和 Claude-3 上,a11y tree 信息的有效性仍然有限,模型难以准确理解和推理 GUI 元素。
- SoM 标注方法在 GPT-4V 上反而降低了性能,可能因为:
操作系统任务通常涉及高分辨率界面和大量 UI 元素,标注信息的噪声较大。
有些任务需要精确坐标操作,而 SoM 的边界框标注方式无法提供坐标级精度。
- 4)纯视觉输入(Screenshot-only)虽然表现最差,但可能是长期目标
当前成功率最低(5.26%),但在多软件交互任务上表现尚可。
- 优点:
不需要额外的 a11y tree 信息,输入方式更接近人类视觉感知。
未来如果能改进,纯视觉智能体可能具有更强的泛化能力,甚至可以适应物理世界任务(如机器人操作)。
- 关键结论
当前 LLM/VLM 代理远远无法取代人类操作计算机,尤其在 GUI 任务上表现较差。
命令行(CLI)任务比 GUI 任务更容易,工作流任务(跨软件操作)难度最高。
SoM 并不总是有效,在某些任务(如高分辨率操作系统任务)可能会引入噪声,影响准确性。
未来研究方向:优化纯视觉智能体(screenshot-only setting),以提升泛化能力。
5. Analysis¶
对视觉语言模型(VLM)在数字代理任务中的表现分析,主要涵盖了任务难度、输入模式、操作系统差异、常见错误以及与人类的比较等多个方面。
- 影响VLM代理任务表现的因素
任务属性:任务的难度、可行性、视觉需求、GUI 复杂度等都会影响模型表现。
输入方式:如截图分辨率、轨迹历史(文本 vs. 图像)、UI 布局的影响。
操作系统的影响:模型在不同 OS(如 Windows 和 Ubuntu)上的表现存在一定的相关性。
方法对比:比较了 GPT-4V 和 Claude-3 的表现,发现 GPT-4V 在执行层面比 Claude-3 更稳健。
5.1 Performance by Task Difficulty, Feasibility and App Involved¶
任务难度:任务完成时间越长,VLM 的成功率越低(人类的成功率下降较缓,而 VLM 下降幅度更大)。
可行性:模型在无法执行的任务上(如不存在的功能)表现略好于可执行任务,但总体成功率仍然较低。
- 涉及的应用数量:
单一应用内的任务成功率 13.74%。
跨应用任务的成功率仅 6.57%。
GUI 复杂度高的应用(如 LibreOffice Calc)表现最差。
5.2 Performance by Multimodal Observation Variances¶
截图分辨率:一般来说,分辨率越高,VLM 识别能力越强。
- 轨迹历史:
文本轨迹历史(如 a11y 树数据)可以提升性能,但需要较大的上下文窗口(6000 tokens)。
图像轨迹历史 并不能提升性能,说明当前 VLM 在从图像中提取上下文信息方面能力较弱。
- UI 布局和噪声的影响:
窗口位置/大小变化、屏幕干扰(如打开无关软件)都会导致 VLM 任务成功率下降 60%~80%。
5.3 Performance across Different Operating Systems¶
在 Ubuntu 和 Windows 之间的任务表现具有 0.7 的相关性,说明相同的方法可以较好地迁移。
但 VLM 仍然受 OS 生态系统的影响,导致观察和操作空间的变化带来不确定性。
5.4 Qualitative Analysis¶
成功案例:VLM 能完成一些复杂任务,如用 VLC 提取字幕并用 ffmpeg 保存。
- 失败案例:
- 常见错误:
鼠标点击不准确(占 75% 失败案例)。
误点击导致重复操作或环境噪声(如弹窗未关闭、误点击广告)。
缺乏 GUI 逻辑理解,如不会调整文本居中、不知道 GIMP 的亮度调整在哪。
- 人类 vs. AI:
人类表现更好的任务:涉及文本编辑、设计、滚动操作(因为 VLM 缺乏 GUI 操作数据)。
AI 表现更好的任务:代码执行类任务(如监控 CPU、终止进程)。
AI 和人类都表现不佳的任务:重复性高的任务,如 Excel 批量处理(VLM 缺乏 API 训练)。
结论¶
- 当前 VLM 代理的主要瓶颈在于:
视觉信息处理不足(无法从图像轨迹中获取有效信息)。
执行能力弱(鼠标点击错误、无法适应 GUI 变化)。
跨 OS 的泛化能力有限(但仍有一定相关性)。
对 GUI 逻辑理解差(难以完成 GUI 操作任务,如对齐文本)。
Claude 虽然有更强的推理能力,但在细节执行上比 GPT-4V 更容易出现幻觉。
- 未来的改进方向包括:
优化 VLM 视觉信息利用能力(提升从截图提取上下文的能力)。
提升 GUI 交互策略(更准确的点击和窗口管理)。
加强跨 OS 适应能力(减少 OS 依赖的观察差异)。
改进模型执行策略(减少重复错误,提高 API 交互能力)。
7. Conclusion and Future Work¶
本章主要总结了OSWORLD的贡献,并提出未来研究的重点方向,主要包括提升视觉-语言模型(VLMs)的能力、改进智能体的探索与记忆机制、增强安全性、扩展数据集和环境。
- OSWORLD 的贡献
- OSWORLD 填补了现有交互式学习环境的关键空白:
提供一个更真实、更丰富的环境,涵盖多个操作系统、界面和应用程序。
让智能体可以执行更广泛的任务,并提升其在现实世界的应用潜力。
- 挑战仍然存在:
当前视觉-语言模型(VLMs)在 GUI 理解和操作知识方面仍有不足。
需要进一步研究,以提升智能体的交互能力。
- 未来研究方向
- 提升 VLMs 在 GUI 交互中的能力(Enhancing VLM capabilities for efficient and robust GUI interactions)
处理更长上下文信息:类似于机器人学(robotics)中的方法,提升计算效率,使智能体能处理更长的历史记录。
- 提升 GUI 理解能力:
使 VLMs 适应动态窗口变化,确保在不同应用界面下仍能正确操作。
提升基于指令生成精准操作的能力。
- 构建视觉记忆能力:
研究如何利用图像编码历史信息,帮助智能体记住和反思过去的交互。
可能涉及预训练(pre-training)、微调(fine-tuning)以及模型结构优化。
- 改进智能体的探索、记忆和反思能力(Advancing agent methodologies for exploration, memory, and reflection)
- 增强智能体自主探索和信息综合的能力:
目前,智能体难以处理长时间交互记录。
需要探索新的方法,让智能体能高效编码历史信息,从中提取关键知识。
- 整合记忆机制(memory mechanisms):
将知识锚定(knowledge grounding)引入(V)LLM 代理,提高长期记忆能力。
- 个性化与定制化:
个性化助手需要支持用户画像(user profiling)和长期记忆存储,以适应不同用户的使用习惯。
- 标准化交互协议:
需要制定适用于 GUI 和 CLI 界面的交互协议,提升智能体的通用性。
- 解决智能体在现实环境中的安全问题(Addressing the safety challenges of agents in realistic environments)
- 潜在风险:
强大的智能体可能被用于绕过 CAPTCHA 验证,或者滥用账户、利用漏洞创建病毒、发动攻击。
- 目前的安全措施:
研究人员采用虚拟机(VMs),防止智能体对主机系统造成不可逆损害。
- 当前评估方法的局限:
现有评估方法仅关注任务完成的正确性,而没有衡量潜在的破坏性行为。
由于计算机环境复杂,尚未找到高效的方法检测智能体的潜在副作用。
- 未来研究方向:
需要开发可靠的安全评估指标,确保智能体在开放环境中不会造成安全风险。
- 扩展和优化数据集与环境(Expanding and refining data and environments for agent development)
- 扩展到更多行业和应用场景:
包括医疗、教育、工业、交通等领域,满足更多真实世界的需求。
- 提升跨硬件、软件的适配能力:
让 OSWORLD 可以无缝部署到不同的计算机系统上。
- 改进 a11y(Accessibility)树的数据质量:
不同应用的 a11y 树质量参差不齐,部分开发者可能没有按照可访问性标准提供完整的 GUI 元素信息。
需要更智能的过滤和补全策略,以处理缺失的元素。
- 简化数据采集流程:
研究如何无痛(painless)收集计算机操作数据,并高效转化为智能体的能力。
- 总结
OSWORLD 在智能体交互研究中具有重要突破,但当前VLMs 仍面临 GUI 交互理解、记忆建模、安全性等问题。
- 未来研究的四大方向:
增强 VLMs 在 GUI 交互中的能力(更长上下文、窗口适应、视觉记忆)。
改进智能体的探索、记忆和反思能力(自主探索、知识锚定、个性化助手)。
解决安全性问题(潜在攻击风险、建立可靠的安全评估方法)。
扩展和优化数据集与环境(跨行业适配、a11y 数据改进、简化数据采集)。
A. Details of OSWORLD Environment¶
A.1 Environment Infrastructure¶
虚拟机(Virtual Machines, VMs)
A.2 Observation Space¶
观察空间是OSWORLD中用于感知环境的方式,主要分为三种类型:完整截图、无障碍树 和 终端输出。
- 将无障碍树转换为XML格式以便于消息传递
使用 pyatspi 获取Ubuntu上的无障碍树。
使用 pywinauto 获取Windows上的无障碍树。
A.3 Action Space¶
动作空间定义了代理(agent)可以执行的操作类型。OSWORLD实现了两种动作空间:pyautogui 和 computer_13(基于 pyautogui 进行的封装)
C. Details of Baseline Methods¶
C.2 Prompt Details¶
C.2.1 Prompt for A11y Tree, Screenshot and their Combination Setting:
You are an agent which follow my instruction and perform desktop computer tasks as instructed.
You have good knowledge of computer and good internet connection and assume your code will run on a computer for controlling the mouse and keyboard.
For each step, you will get an observation of an image, which is the screenshot of the computer screen and you will predict the action of the computer based on the image.
You are required to use `pyautogui` to perform the action grounded to the observation, but DONOT use the `pyautogui.locateCenterOnScreen` function to locate the element you want to operate with since we have no image of the element you want to operate with. DONOT USE `pyautogui.screenshot()` to make screenshot.
Return one line or multiple lines of python code to perform the action each time, be time efficient. When predicting multiple lines of code, make some small sleep like `time.sleep(0.5);` interval so that the machine could take; Each time you need to predict a complete code, no variables or function can be shared from history、
You need to to specify the coordinates of by yourself based on your observation of current observation, but you should be careful to ensure that the coordinates are correct.
You ONLY need to return the code inside a code block, like this:
```python
# your code here
```
Specially, it is also allowed to return the following special code:
When you think you have to wait for some time, return ```WAIT```;
When you think the task can not be done, return ```FAIL```, don't easily say ```FAIL```, try your best to do the task;
When you think the task is done, return ```DONE```.
My computer's password is 'password', feel free to use it when you need sudo rights.
First give the current screenshot and previous things we did a short reflection, then RETURN ME THE CODE OR SPECIAL CODE I ASKED FOR. NEVER EVER RETURN ME ANYTHING ELSE.
C.2.2 Prompt for SoM Setting:
You are an agent which follow my instruction and perform desktop computer tasks as instructed.
You have good knowledge of computer and good internet connection and assume your code will run on a computer for controlling the mouse and keyboard.
For each step, you will get an observation of the desktop by 1) a screenshot with interact-able elements marked with numerical tags; and 2) accessibility tree, which is based on AT-SPI library. And you will predict the action of the computer based on the image and text information.
You are required to use `pyautogui` to perform the action grounded to the observation, but DONOT use the `pyautogui.locateCenterOnScreen` function to locate the element you want to operate with since we have no image of the element you want to operate with. DONOT USE `pyautogui.screenshot()` to make screenshot.
You can replace x, y in the code with the tag of the element you want to operate with. such as:
```python
pyautogui.moveTo(tag_3)
pyautogui.click(tag_2)
pyautogui.dragTo(tag_1, button='left')
```
When you think you can directly output precise x and y coordinates or there is no tag on which you want to interact, you can also use them directly.
But you should be careful to ensure that the coordinates are correct.
Return one line or multiple lines of python code to perform the action each time, be time efficient. When predicting multiple lines of code, make some small sleep like `time.sleep(0.5);` interval so that the machine could take; Each time you need to predict a complete code, no variables or function can be shared from history
You need to to specify the coordinates of by yourself based on your observation of current observation, but you should be careful to ensure that the coordinates are correct.
You ONLY need to return the code inside a code block, like this:
```python
# your code here
```
Specially, it is also allowed to return the following special code:
When you think you have to wait for some time, return ```WAIT```;
When you think the task can not be done, return ```FAIL```, don't easily say ```FAIL```, try your best to do the task;
When you think the task is done, return ```DONE```.
My computer's password is 'password', feel free to use it when you need sudo rights.
First give the current screenshot and previous things we did a short reflection, then RETURN ME THE CODE OR SPECIAL CODE I ASKED FOR. NEVER
EVER RETURN ME ANYTHING ELSE.
D. Examples of Qualitative Analysis¶
D.1 Success and Failure Cases¶

Success Task¶

Failure Task¶
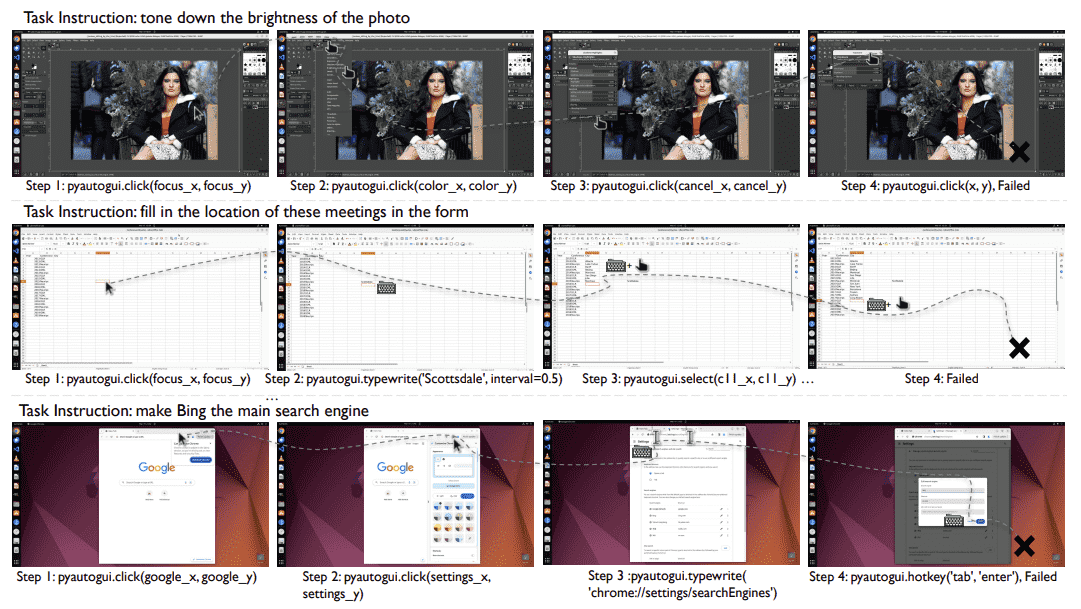
Figure 16: The figure shows examples of usage errors in three types of software. The first row is for GIMP, the second row is for LibreOffice Calc, and the third row is for Google Chrome. Detailed code execution processes are provided below.¶
GIMP Task: Could you tone down the brightness of my photo?:
# Action 1
import pyautogui
import time
# Coordinates for the image icon on the desktop
# Adding half of the width and height to get the center
image_icon_x, image_icon_y = 1793 + 60, 920 + 17
# Double-click on the image icon
pyautogui.doubleClick(image_icon_x, image_icon_y)
# Action 2
# Coordinates for the 'Colors' menu
# Adding half of the width and height to get the center
colors_menu_x, colors_menu_y = 344 + 28, 64 + 12
# Click on the 'Colors' menu
pyautogui.click(colors_menu_x, colors_menu_y)
# Action 3
# Coordinates for the 'Brightness-Contrast...' option in the 'Colors' dropdown
# Assuming each menu item is approximately 28 pixels apart
brightness_contrast_option_x, brightness_contrast_option_y
= 344 + 28, 64 + 12 + 28 * 6
# Click on the 'Brightness-Contrast...' option
pyautogui.click(brightness_contrast_option_x, brightness_contrast_option_y)
# Action 4
# Coordinates for the 'Cancel' button in the 'Shadows-Highlights' dialog
# Adding half the width and height to get the center
cancel_button_x, cancel_button_y = 375 + 42, 625 + 16
# Click the 'Cancel' button
pyautogui.click(cancel_button_x, cancel_button_y)
# Coordinates for the 'Brightness-Contrast...' option in the 'Colors' dropdown
# Adjusted index for Brightness-Contrast option
brightness_contrast_option_x, brightness_contrast_option_y
= 344 + 28, 64 + 12 + 28 * 5
pyautogui.click(brightness_contrast_option_x, brightness_contrast_option_y)
# Action 5
# Coordinates for the 'Cancel' button in the 'Exposure' dialog
# Adding half the width and height to get the center
cancel_button_x, cancel_button_y
= 375 + 42, 391 + 16
pyautogui.click(cancel_button_x, cancel_button_y)
# Coordinates for the 'Brightness-Contrast...' option in the 'Colors' dropdown
# Adjusted index for Brightness-Contrast option
brightness_contrast_option_x, brightness_contrast_option_y
= 344 + 28, 64 + 12 + 28 * 6
pyautogui.click(brightness_contrast_option_x, brightness_contrast_option_y)
# Action 6
# Coordinates for the 'Cancel' button in the 'Color Balance' dialog
# Adding half the width and height to get the center
cancel_button_x, cancel_button_y
= 375 + 42, 588 + 16
pyautogui.click(cancel_button_x, cancel_button_y)
# Since the 'Brightness-Contrast...' option was not correctly opened before,
we will use an estimated position based on the dropdown menu.
# Assuming 'Brightness-Contrast...' is the second option in the 'Colors' menu.
brightness_contrast_option_x, brightness_contrast_option_y
= colors_menu_x, colors_menu_y + 28 * 2
pyautogui.click(brightness_contrast_option_x, brightness_contrast_option_y)
# Action 7
# Coordinates for the 'Cancel' button in the 'Color Temperature' dialog
# Adding half the width and height to get the center
cancel_button_x, cancel_button_y = 375 + 42, 403 + 16
pyautogui.click(cancel_button_x, cancel_button_y)
# Since the 'Brightness-Contrast...' option was not correctly opened before,
we will use an estimated position based on the dropdown menu.
# Assuming 'Brightness-Contrast...' is the second option in the 'Colors' menu.
brightness_contrast_option_x, brightness_contrast_option_y
= colors_menu_x, colors_menu_y + 28 * 2
# Click on the 'Brightness-Contrast...' option
pyautogui.click(brightness_contrast_option_x, brightness_contrast_option_y)
# ... More Wrong Duplicate Actions; Can not find the right coordination.
# Failed
Libreoffice calc Task: I now want to count the meeting cities of the three machine learning conferences in the past ten years from 2013 to 2019(including 2013 and 2019). I have listed the names and years of the conferences in excel. Please fill in the vacant locations:
# Action 1
# Move to cell C2 which is the first empty cell under 'City' for ICLR 2013
pyautogui.click(319, 222)
# Coordinates of cell C2
time.sleep(0.5)
# Type the city name for ICLR 2013
pyautogui.write('Scottsdale')
# Press Enter to move to the next cell
pyautogui.press('enter')
# Action 2
# Move to cell C3 which is the city cell for ICML 2013
pyautogui.click(319, 268)
# Coordinates of cell C3
# Type the city name for ICML 2013
pyautogui.write('Atlanta')
# Press Enter to move to the next cell
pyautogui.press('enter')
# Action 3
# Move to cell C4 which is the city cell for NeurIPS 2013
pyautogui.click(319, 289)
# Coordinates of cell C4
# Type the city name for NeurIPS 2013
pyautogui.write('Lake Tahoe')
# Press Enter to move to the next cell
pyautogui.press('enter')"
... More copy-and-paste operations
# Action 15
# Move to cell C16 which is the city cell for NeurIPS 2017
pyautogui.click(319, 541)
# Coordinates of cell C16
# Type the city name for NeurIPS 2017
pyautogui.write('Long Beach')
# Press Enter to move to the next cell
pyautogui.press('enter')
Failed.
Chrome Task: Can you make Bing the main search thingy when I look stuff up on the internet?
# Action 1
pyautogui.click(x=1280, y=50)
# Approximate coordinates for the 'More' button
pyautogui.move(0, 150)
# Moving the cursor down to 'Settings' in the drop-down menu
pyautogui.click()
# Clicking on 'Settings'
# Action 2
pyautogui.click(tag_31)
# Click on the 'Finish update' button to
approximate the location of 'More' button
pyautogui.move(-50, 0)
# Move left from the 'Finish update' button to approximate the 'More' button
pyautogui.click()
# Click on the 'More' button
time.sleep(0.5)
pyautogui.move(0, 150)
# Move down to the 'Settings' option in the drop-down menu
pyautogui.click()
# Click on 'Settings'
# Action 3
# Click on the 'Customise Chrome' button which should be the 'More' button
time.sleep(1)
# Wait for the dropdown menu to appear
# The 'Settings' option is usually located towards the bottom of
the dropdown menu, so I'll move the cursor down to reach it
pyautogui.move(0, 200)
# Move down to the 'Settings' option in the drop-down menu
pyautogui.click()
# Click on 'Settings'
# Action 4
pyautogui.click(tag_47)
# Click on the 'Close' button to close the 'Customise Chrome' menu
pyautogui.click(tag_25)
# Click on the 'New Tab' button to open a new tab
time.sleep(1)
# Wait for the new tab to open
pyautogui.typewrite('chrome://settings/searchEngines')
# Type the direct URL to the search engine settings page
pyautogui.press('enter')
# Action 5
# Simulate pressing the 'Tab' key multiple times to navigate through the options
for _ in range(10):
# Assuming it might take around 10 tabs to reach the search engine list
pyautogui.press('tab')
time.sleep(0.5)
# Wait for the focus to move to the next element
# Simulate pressing the 'Enter' key to select an option,
which would be done once we reach the Bing option
pyautogui.press('enter')
# Action 6
pyautogui.click(tag_42)
# Click on the 'Cancel' button to exit the edit mode for the '360' search engine
Failed.





