2412.09401_SLAM3R: Real-Time Dense Scene Reconstruction from Monocular RGB Videos¶
Google Scholar: (star 2, 2025-04-09)
组织: 北京大学、香港大学
术语¶
Image-to-Points (I2P)
Local-to-World (L2W)
稀疏 SLAM: 只跟踪少量关键特征点 → 地图是“稀疏点云”。主要区别在于对地图的表示密度和重建精度要求不同,适用于不同的应用场景。
类似“画草图” → 只记录重要的点(角点、边缘)
建出的地图像“星星点点的骨架”
稠密 SLAM: 尽量还原每个像素的深度 → 地图是“稠密模型或表面重建”
类似“画油画” → 每一块区域都尽量复原
建出的地图可以看到完整的墙面、物体曲面
Abstract¶
本章主要介绍了SLAM3R,一个新颖且高效的实时高质量密集三维重建系统。
SLAM3R的核心特点:
实时、高质量、密集的3D重建:
SLAM3R旨在从RGB视频中提取出密集的三维重建(即高精度的三维场景模型),且可以实时运行。
端到端的解决方案:
传统的SLAM方法通常需要分开处理局部三维重建(例如,局部帧的点云生成)和全局坐标对齐(即整体场景的合并)
SLAM3R则通过集成局部3D重建和全局坐标注册,提供一个统一的端到端解决方案
这个过程通过前馈神经网络(feed-forward neural networks)无缝连接
滑动窗口机制:
给定输入的视频,SLAM3R首先将视频分割成多个重叠的小片段(clip)
这些片段用于后续的三维点云回归。
直接回归三维点云:
与传统的基于位姿优化的方法不同,SLAM3R直接通过神经网络从每个视频片段的RGB图像中回归(即预测)三维点云
这里的“回归”是指神经网络直接输出三维坐标点,而不是通过多次优化或求解相机参数来间接推导三维信息
局部点云的对齐(aligns)与变形(deform):
SLAM3R会逐步对这些局部点云进行对齐和变形,最终生成一个全局一致的三维场景重建
对齐指的是将不同片段生成的局部三维点云合并成一个统一的整体;
变形指的是对点云的细微调整,使得整体重建更准确。
无需显式求解相机参数:
传统的SLAM方法需要估计相机的内参、外参等,以便进行三维重建和位姿优化,而SLAM3R不需要显式地求解这些相机参数。它通过神经网络直接从图像生成三维信息,简化了过程。
实验结果:
SLAM3R在多个数据集上的实验结果表明,它在重建精度和完整性方面达到了最先进的水平,并且在保证高质量的同时,保持了实时性能(>20 FPS)。
总结:
SLAM3R是一个创新的SLAM系统,它通过神经网络直接从RGB视频中回归三维点云,并通过对局部点云的对齐与变形,生成全局一致的三维重建。
与传统方法相比,SLAM3R的优势在于它避免了复杂的相机参数求解,提供了一个更加简洁且高效的解决方案,而且速度快、效果好。
它通过全新的方法打破了传统SLAM系统在处理时所需的优化过程,且能够实时生成高质量的三维重建,这在很多实际应用场景中是非常有意义的。
1. Introduction¶
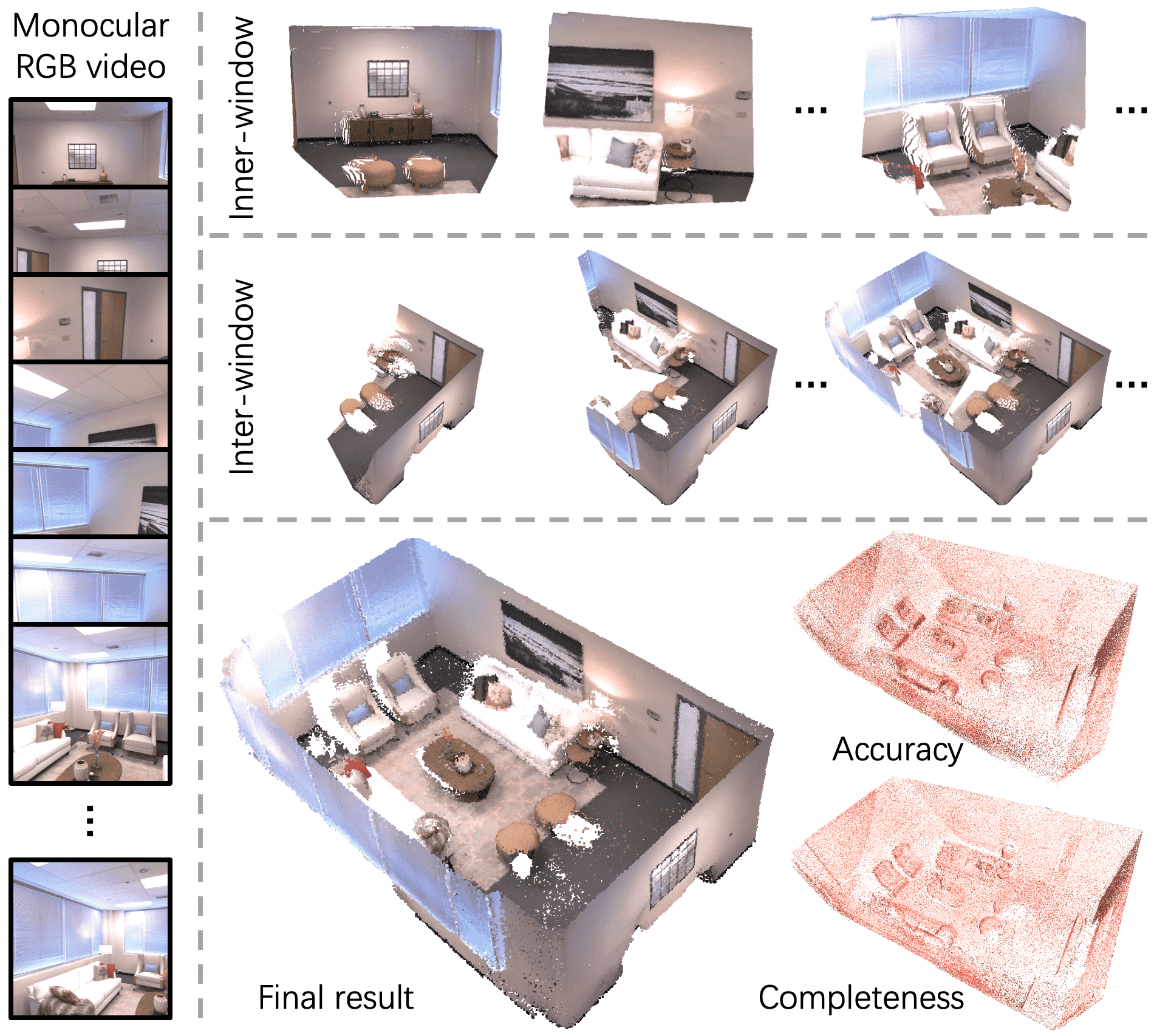
Figure 1: We introduce a novel dense reconstruction system - SLAM3R. It takes a monocular RGB video as input and reconstructs the scene as a dense pointcloud. The video is converted into short clips for local reconstruction (denoted as inner-window), which are then incrementally registered together (inter-window) to create a global scene model. This process runs in real-time, producing a reconstruction that is both accurate and complete.
这段内容主要介绍了SLAM3R系统的背景、方法以及其创新之处。让我们逐步拆解并理解这部分内容。
1. SLAM3R的目标和背景:¶
SLAM3R是一个实时密集三维重建系统,输入为单目RGB视频,其目标是生成全局一致、准确且完整的三维点云重建。它的特点是能够在实时下完成重建,达到20帧每秒(FPS)的速度。
传统的密集三维重建方法通常需要依赖多阶段的流程,例如稀疏SLAM或结构从运动(SfM),这些方法通过估计相机参数(如位姿)来进行三维重建,之后再使用多视角立体视觉(MVS)来填充细节。这些方法虽然能够产生高质量的重建,但大多需要离线处理,因此在实际应用中不够高效。
密集SLAM方法有助于解决这一问题,但通常存在重建准确性或完整性不足,或者过度依赖深度传感器的问题。
单目SLAM方法近年来取得了一些进展,可以直接使用RGB视频进行密集重建。但这些方法往往牺牲了效率,例如NICER-SLAM的速度显著低于1 FPS。
2. SLAM3R的创新与方法:¶
为了克服现有方法的不足,SLAM3R提出了一种全新的方式,它的核心创新在于:
简化的架构:SLAM3R通过端到端的神经网络(Feed-forward Neural Networks)来完成三维重建,避免了传统方法中复杂的相机参数估计和全局优化过程。
两层次的框架:
**局部三维重建:**SLAM3R通过滑动窗口(Sliding Window)机制,将输入视频分成多个短片段进行局部重建。在每个窗口内,系统直接从RGB图像中回归三维点云。
**全局坐标系统的注册:这些局部三维点云被逐步注册和对齐,最终生成一个全局一致的三维场景模型。这个过程没有显式地估计相机参数,且通过Image-to-Points (I2P)和Local-to-World (L2W)**两个模块来实现。
I2P模块(图像到点云):I2P模块通过选择一个关键帧作为局部窗口的参考坐标系统,并利用该窗口内的其他图像来直接回归密集的三维点云。它的设计灵感来自DUSt3R,但将其扩展到多个视角的情况。
**L2W模块(局部到全局):**L2W模块将局部重建的三维点云逐步对齐到一个统一的全局坐标系统中,从而避免了显式的相机参数估计和复杂的全局优化。
3. SLAM3R的优势:¶
实时性能:SLAM3R能够在实时速度下运行,每秒超过20帧(FPS),这意味着它在处理密集的三维重建时,能够同时保证高质量和高效率。
**不依赖相机参数估计:**SLAM3R不需要显式地估计相机的内参和外参,这简化了整个重建过程。
高质量与完整性:SLAM3R能够在多个公共基准测试上达到最先进的重建质量,在准确性和完整性方面都表现优异。
4. 贡献总结:¶
提出了一种新颖的端到端实时三维重建系统,使用RGB视频输入,通过神经网络直接预测三维点云,并将这些点云对齐到一个统一的坐标系统。
设计了I2P模块,能有效处理多个图像,扩展了DUSt3R的多视角处理能力,并提高了预测的质量。
提出了L2W模块,能够直接将局部重建的三维点云对齐到全局坐标系统,避免了显式相机参数估计和全局优化的计算成本。
在多个公开基准测试中,SLAM3R达到了最先进的重建质量,同时保持了实时速度。
总结:¶
SLAM3R通过创新的神经网络架构,在实时性、重建质量和完整性之间找到了一个平衡点,解决了传统密集SLAM方法中的一些关键问题。它不依赖于复杂的相机参数估计,并且能够处理多个视角的输入,提供全局一致的三维场景重建。这使得它在各种实际应用中非常具有前景。
3. Method¶
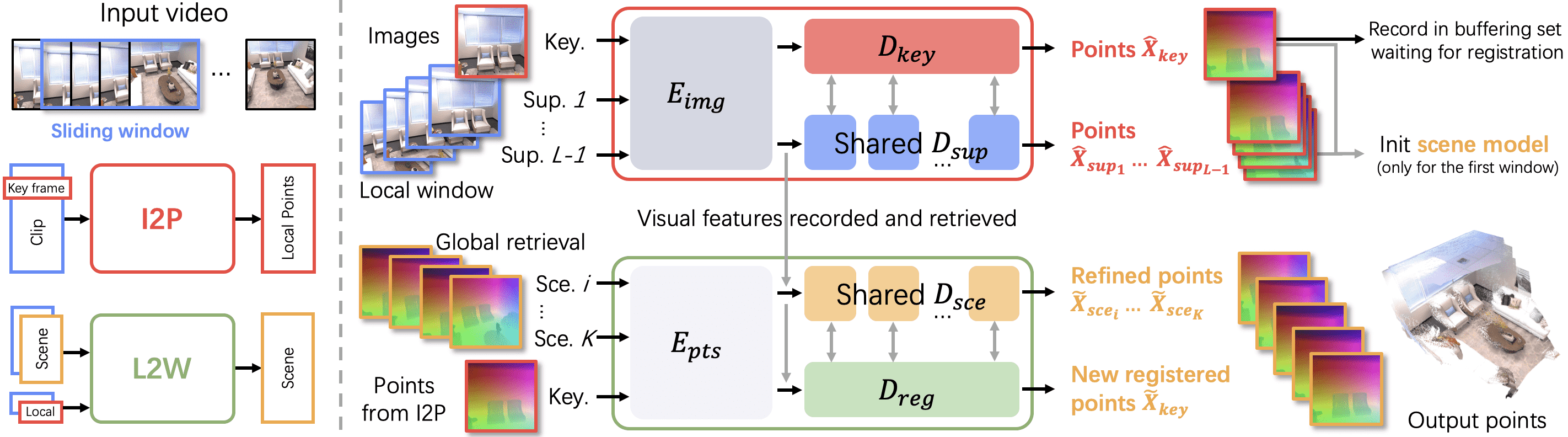
Figure 2: System overview. Given an input monocular RGB video, we apply a sliding window mechanism to convert it into overlapping clips (referred to as windows). Each window is fed into an Image-to-Points (I2P) network to recover 3D points in a local coordinate system. Next, the local points are incrementally fed into a Local-to-World (L2W) network to create a globally consistent scene model. The proposed I2P and L2W networks elegantly share similar architectures. In the I2P step (Sec. 3.1), we select a keyframe as a reference to set up a local coordinate system and use the remaining frames in the window to estimate the 3D geometry captured within it. The points from the first window are used to establish the world coordinate system. We then incrementally fuse the following windows in the L2W step (Sec. 3.2). This process involves retrieving the most relevant already-registered keyframes as a reference, and integrating new keyframes. Through this iterative process, we eventually obtain the full scene reconstruction.
总结
这段内容描述了一个基于单目RGB视频进行密集场景重建的系统方法,主要包括三个关键步骤:I2P(图像到点的转换)网络、L2W(局部到全局坐标系的转换)网络,以及它们是如何互相协作实现3D重建的。
具体来说,系统的工作流程可以分为以下几个部分:
滑动窗口机制
系统首先通过滑动窗口机制将输入的单目RGB视频切分为重叠的视频片段(每个片段称为一个窗口)。
每个窗口作为一个输入送入I2P网络进行处理。
I2P网络(图像到点的转换)
在I2P阶段,系统选取窗口中的一个关键帧作为参考,构建局部坐标系,并利用窗口中的其他图像来估算3D几何数据。通过这一过程,系统能够恢复出局部的3D点云。
L2W网络(局部到全局坐标系的转换)
接着,I2P生成的局部点云会被送入L2W网络进行全局场景重建。在L2W阶段,系统会逐步将局部重建结果(即每个窗口生成的3D点云)注册到一个统一的全球坐标系中,最终生成一个完整的3D场景模型。
系统特点
该系统没有明确地解算相机参数,而是直接预测3D点云的统一坐标系。这种方式确保了较高的计算效率和实时性。
I2P网络的实现
I2P网络的设计灵感来自于DUSt3R(用于立体3D重建的网络),通过对其进行改进以支持多视角场景的处理。I2P网络使用多分支的视觉变换器(ViT)作为骨干网络,包含图像编码器、两个解码器(分别处理关键帧和支持帧),以及点回归头用于最终的3D点预测。
图像编码器
对每个视频片段的每一帧图像,图像编码器会将其编码成一个token表示。每一帧的token将被送入后续的解码器进行处理。
关键帧解码器
关键帧解码器通过多视角的交叉注意力机制(与传统的交叉注意力机制不同),结合来自多个支持帧的信息,来对关键帧进行解码。通过这种方式,系统可以更好地融合来自不同角度的信息,恢复出更完整的3D点云。
总结:
这个方法的目标是通过I2P和L2W两个步骤,实现对静态场景的密集3D重建,保证重建结果的完整性、每个点的准确性,并且保持实时性能。通过滑动窗口机制,逐帧恢复3D点云,并逐步将局部的3D点云注册到全局坐标系中,最终生成完整的3D场景。
🧠 方法核心思想(精简理解)
论文提出的系统由两个主要模块组成:
| 模块名 | 作用 | 概念类比
| I2P(Image-to-Points) | 从视频片段(窗口)中恢复局部 3D 点云 | 每段视频“局部建模”
| L2W(Local-to-World) | 把多个局部点云对齐,统一到一个全局坐标系 | “拼接全球地图”
重点特点:
全程不显式估计相机位姿
直接预测 3D 点图
通过滑动窗口机制推进时间轴(每帧都能当 keyframe)
支持实时重建
📹 输入输出与目标
输入:
假设静态场景,一个单目视频(monocular video)包括\(N\) 张 \(H \times W\) 的 RGB 图片:
一个RGB图片(RGB image frames)如下所示:
输出:
一组稠密的 3D 点: $\( \mathbf{P} \in \mathbb{R}^{M \times 3} \)$
表示最终场景中的 \(M\) 个三维点的坐标。
目标有三:
恢复尽可能多的 3D 点(完整性)
保证每个点的精度(准确性)
保持实时性(效率)
🧱 系统结构:滑动窗口 + 两阶段重建
论文图 2(system overview)描述了整个流程:
① 滑动窗口分片:
把整个视频切成长度为 \(L\) 的小片段: $\( \{ \mathcal{W}_i \in \mathbb{R}^{L \times H \times W \times 3} \} \)\( 每个 \)\mathcal{W}_i$ 就是一个“窗口”。
滑动步长默认是 1,意味着每帧都参与多次建模,每帧都能被选为 keyframe。
②I2P:局部点图预测(参考 Sec. 3.1)
对每个窗口 \(\mathcal{W}_i\),选一帧作为 keyframe(坐标系参考帧)
用该 keyframe 和其他帧估计出局部 3D 几何(点图)
相当于:一段视频 → 一片局部点云
③ L2W:局部点图对齐成全局地图(参考 Sec. 3.2)
第一个窗口预测出的点云定义全局世界坐标系
后续窗口的局部点图,逐个融合进这个全局场景
每次融合时会:
检索最相关的历史 keyframes(称为 scene frames)
用这些历史帧作为配准参考,把新帧对齐进来
系统维护一个小规模的“scene frame 缓存池”,防止内存/计算开销爆炸。
💡 特别之处:不预测相机位姿
传统 SLAM 方法通常:
估计每帧相机位姿(R, t)
再反推点的三维位置
而 SLAM3R 做的是:
直接预测点图
不需要知道相机在哪里
所有帧的点图都对齐在 keyframe / 世界坐标系下
这种设计的好处是:
不需要 Bundle Adjustment 或位姿优化
容易训练 / 推理端到端
适合部署在移动设备上(因为快)
✅ 总结为流程图:
视频帧序列(单目 RGB)
↓
滑动窗口(长度 L,步长 1)
↓
┌────────── I2P 模块 ──────────┐
│ 选定 keyframe(局部坐标系) │
│ → 恢复局部点图(3D 点) │
└─────────────────────────────┘
↓
第一窗口建立世界坐标系(初始化)
↓
┌────────── L2W 模块 ──────────┐
│ 检索最相关的 scene frames │
│ 将当前窗口的点图对齐融合进去 │
└─────────────────────────────┘
↓
最终输出:统一坐标系下的稠密点云场景
3.1 Inner-Window Local Reconstruction¶
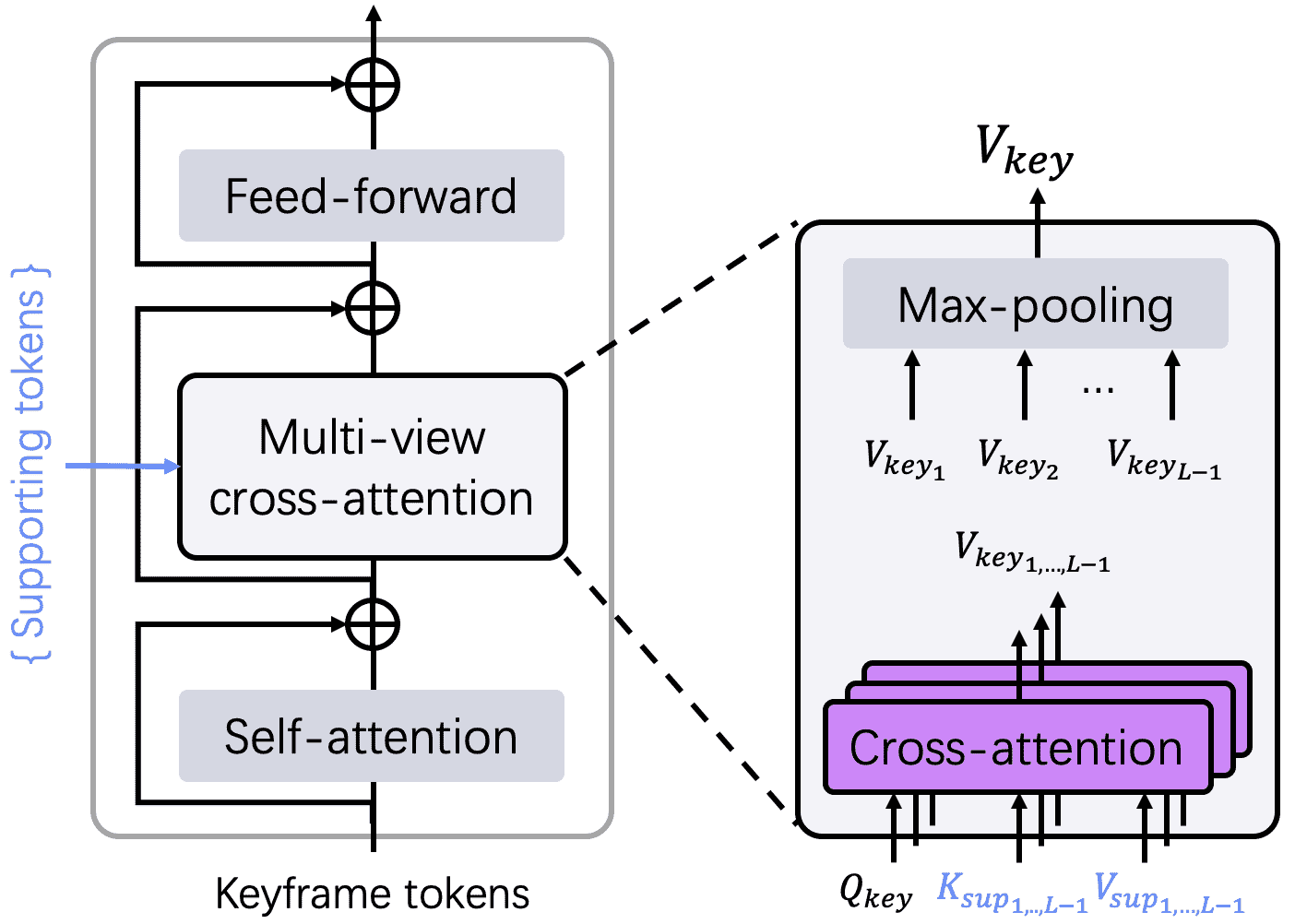
Illustration of a decoder block in the proposed keyframe decoder \(D_{key}\) . We present a minimalist modification to integrate information from different supporting images. Our approach traverses each of them, selects its token keys and values, and uses the keyframe queries to interact with them separately across the supporting images. This multi-view information is then aggregated through max-pooling. The registration decoder \(D_{reg}\) and scene decoder \(D_{sce}\) (described in Sec. [3.2] share the same architecture.
本节主要讲如何在一个小的视频窗口(window)内,将一组连续帧的信息结合起来,恢复出中间帧(keyframe)对应的密集三维点云(dense 3D pointmap)。
🌟总体目标
给定一个视频片段(一个滑动窗口内的图像序列),对中间帧进行三维重建,输出每个像素对应的 三维坐标(3D 点云),这种结构叫做 pointmap。
🧱 Image-to-Points (I2P)结构组成
输入:
一组连续视频帧:{I₁, I₂, …, I_L},总共 L 帧;
其中 中间帧
I_key是关键帧(keyframe),用于建立局部坐标系;其他帧称为 supporting frames(辅助帧),参与信息融合。
主干网络:
共享图像编码器
E_img:使用一个多分支的 Vision Transformer(ViT)结构,处理每帧图像,得到 token 表示;Keyframe 解码器
D_key:专门解码关键帧,做多视角交叉注意力;Supporting 解码器
D_sup:为辅助帧设置的解码器,只与关键帧做 cross-attention;点云回归头:从解码后的 token 中预测每个像素的三维点。
🧠 编码器 E_img
每一帧 Iᵢ(大小为 H × W × 3)先通过共享编码器
E_img,被编码成 T 个 token,每个维度为 d;表达为:
所有帧都是 并行 处理的,得到:
F_key:关键帧的 token;{F_supᵢ}:辅助帧的 token。
🧩 Keyframe 解码器 D_key
输入是关键帧的
F_key和 所有辅助帧的{F_supᵢ};使用了创新的 多视角交叉注意力(multi-view cross-attention):
每个辅助帧的 token 都和
F_key分别做一次 cross-attention;每次 cross-attention:query 是
F_key,key/value 是F_supᵢ;共有 L-1 个 cross-attention,彼此独立,可以并行;
最后用 max pooling 将这 L-1 个 cross-attention 输出融合为一个特征表示,称为
G_key。
这个设计的优点在于:
利用了多个视角的信息;
支持并行处理,速度快;
不同视角之间的信息不会相互干扰。
🧩 Supporting 解码器 D_sup
用来生成每个辅助帧的输出 token
G_supᵢ;输入是辅助帧的
F_supᵢ和关键帧的F_key;它 只和关键帧做 cross-attention,结构更简单;
所有辅助帧共享同一个
D_sup解码器。
表达为:
🧠 总结图(Figure 3)
展示了关键帧解码器
D_key的结构:每个辅助帧提供一组 key-value token;
关键帧的 token 拿来当 query;
最后所有 cross-attention 输出做 max pooling;
得到最终关键帧的三维信息表示。
🧩 技术要点总结
模块 |
功能 |
|---|---|
|
编码所有图像,提取 token 表示 |
|
解码关键帧,整合多个视角的 token,使用并行 cross-attention |
|
解码辅助帧,结合关键帧信息进行 cross-attention |
Point head |
根据解码后 token,预测每个像素的三维位置 |
如果你想我帮你画个结构图或者举个具体例子来说明,也可以告诉我~
3.2 Inter-Window Global Registration¶
这段内容主要描述了如何通过一种“跨窗口全局配准”(Inter-Window Global Registration)的方法将3D点云地图注册到全局坐标系中。具体而言,文章中介绍了如何利用I2P网络和局部到全球(L2W)模型进行逐步的3D点云配准,并结合了缓存策略和检索机制来提高效率和准确性。
场景初始化
首先,利用I2P网络生成的3D点云数据,将这些数据与多个关键帧一起用来初始化场景模型。
通过多次执行I2P网络,尝试不同的关键帧组合,选择出信心得分最高的结果来初始化场景模型。
场景模型的初始化过程生成了一个包含多个注册帧的场景点云,这些帧被视为“场景帧”。
缓存和检索
缓存集:为了处理长时间的视频数据,使用了reservoir sampling(水库采样)方法来控制缓存中存储的场景帧的数量。这是一种在固定大小的内存中存储来自大规模数据的无偏样本的方法。
每当有新的关键帧(keyframe)生成时,会从缓存集里检索出最相关的K个场景帧来作为全局注册的支持帧。
通过对场景帧和关键帧的特征进行比对,使用一个检索模块来衡量它们的相似性,帮助选择最合适的K个场景帧。
点云嵌入
I2P模型生成的3D点云会被转化为L2W模型输入的形式,类似于图像处理中的“图像块化”(patchification)。通过处理关键帧和检索到的场景帧,使用嵌入方法将点云转换为可以输入到L2W模型的特征。
这些嵌入的特征与视觉特征一起被用于全局场景注册。
配准解码器和场景解码器
注册解码器(Registration Decoder): 其作用是将关键帧的局部重建转化到全局场景坐标系中。通过与其他场景帧的交互,逐步调整和优化关键帧的位置。
场景解码器(Scene Decoder): 该解码器用来进一步精细化场景的几何结构,而不改变坐标系。场景解码器通过与多个关键帧的互动优化场景。
点云重建与训练损失
最终,通过一个与I2P网络相同的头设计来预测在全局场景坐标系中的所有点云。
训练过程中,优化的目标是减少点云重建与真实场景之间的差异,从而不断改进模型的表现。
主要方法与技术
跨窗口配准(Inter-Window Registration): 通过L2W模型将不同窗口生成的点云逐步注册到全局坐标系中。
水库采样(Reservoir Sampling): 用于选择并存储最相关的场景帧,保持缓存集的有限大小。
特征检索: 通过比对场景帧和关键帧的特征,选出最相关的K个场景帧,作为全局注册的参考。
嵌入与融合: 将3D点云数据与视觉特征融合,通过嵌入方法进行表示。
解码与优化: 通过解码器来优化关键帧和场景帧的几何配准,最终实现全局场景的精确重建。
总结
这段内容描述了一个通过深度学习模型(尤其是I2P网络和L2W模型)进行跨窗口3D点云全局配准的过程。重点在于如何利用缓存策略、特征检索和多帧协作来提高注册过程的效率和准确性。
4. Experiments¶
这段内容来自于一篇关于SLAM3R(一个用于实时3D重建的视觉SLAM算法)的论文,其中包含了实验结果、方法比较、数据集和实现细节。下面我将帮助你理解其各部分内容:
实验结果
论文中列出了SLAM3R与其他方法在不同场景和数据集上的表现,并通过准确性(Acc.)和完整性(Comp.)进行比较。
重要方法包括:
DUSt3R:一种先前的方法,在多个场景中表现良好,但其帧率(FPS)很低,接近1以下。
MASt3R:另一种方法,虽然在某些场景中准确性较高,但帧率也较低。
Spann3R:该方法的表现显著优于其他方法,尤其是在某些场景中,表现了超过50 FPS的处理能力。
SLAM3R:文中的方法,显示出在多个场景中相对平衡的准确性和完整性,同时具有适当的FPS。
4.1 比较(Comparisons)¶

Figure 4: We visualize the reconstruction results on two scenes: Office-09 and Office 2 from the 7-Scenes and Replica datasets. Our method runs in real-time and achieves high-quality reconstruction comparable to the offline method DUSt3R.
评估指标:
重建精度和完整度:使用准确度(accuracy)和完整度(completeness)指标来量化重建的质量。
计算效率:使用每秒帧数(FPS)来衡量算法的计算性能,测试是在单一的NVIDIA 4090D GPU上进行的。
相机姿态估计:通过计算绝对轨迹误差(ATE-RMSE)来评估相机姿态。
重建算法对比:对比了SLAM3R与其他优化基的重建方法(如DUSt3R,MASt3R),以及增量重建方法Spann3R等,结果表明,SLAM3R在准确度和完整度上均优于这些方法,同时保持实时性能。
4.2 分析(Analyses)¶

Figure 5: Qualitative examples. We show our reconstruction results on Tanks and Temples [26], BlendedMVS [69], Map-free Reloc [2], LLFF [35], and ETH3D [50, 49] datasets, as well as in-the-wild captured videos, to demonstrate SLAM3R’s generalization ability.
I2P模型的有效性:
I2P模型:通过使用不同数量的支持视角,SLAM3R的重建质量不断提高。实验表明,SLAM3R的效率在窗口大小超过11时保持稳定,展示了并行设计的有效性。
L2W模型的优势:
L2W模型:通过在Replica数据集上进行消融实验,评估了不同点对齐方法(如DUSt3R的全局优化、传统的Umeyama和ICP方法、以及SLAM3R的L2W模型)。结果显示,SLAM3R的L2W模型在对齐精度和计算效率上都优于其他方法。
检索模块:
SLAM3R提出了一种轻量级的检索模块,用于从历史场景帧中选择最相关的帧以进行隐式重新定位。与传统的选择最近帧的方法相比,这种检索策略显著提高了性能。
总结:¶
这段内容主要说明了SLAM3R在多个数据集上的表现,特别是在重建精度、计算效率以及相机姿态估计方面的优势。它通过优化模型设计和检索模块,在没有复杂优化步骤的情况下,能够实现高效且高质量的三维重建。此外,SLAM3R的泛化能力也得到了验证,能够在各种实际场景中稳定工作。
5. Conclusion¶
这段内容主要总结了SLAM3R系统的关键贡献、局限性和未来的研究方向。下面是详细解读:
5. 结论¶
在本文中,作者介绍了SLAM3R,一个新颖且高效的系统,能够通过RGB视频进行实时的高质量、稠密的三维场景重建。其核心特点是使用了一个两级神经网络框架,能够通过简化的前馈过程进行端到端的三维重建,从而无需显式地求解相机参数。实验结果表明,SLAM3R在重建质量和实时效率上都表现出色,能够实现每秒20帧以上的性能(20+ FPS)。
局限性和未来工作¶
局限性:
相机参数预测的省略:由于系统省略了相机参数的预测,它无法执行全局束调整(global bundle adjustment)。束调整是优化相机参数和三维点位置的过程,通常用于提高视觉SLAM系统的精度。
相机定位精度:从场景点云预测得到的位姿精度,仍然不如专门用于相机定位的SLAM系统。
未来工作方向: 解决这些局限性将是作者未来工作的重点,尤其是提高相机定位精度并增强全局优化能力。
6. 致谢¶
资助来源:包括中国国家重点研发计划(2022ZD0160800)、香港大学的早期职业计划、Musketeers Foundation的捐赠等。
感谢:感谢评审的宝贵反馈,并特别感谢Zihan Zhu和Songyou Peng在实验中的帮助,同时也感谢香港大学计算与数据科学学院的支持。
Appendix¶
附录A:额外的实现细节和实验设置,这些内容因为篇幅限制未能在主文中展示。
附录B:实验设置的详细信息。
附录C:更多的比较和分析。
附录D:更多的重建结果的视觉展示。
Appendix A Implementation details¶
检索模块(Retrieval Module)¶
模块结构:
提出了一个轻量级的模块,用于高效地进行场景帧检索,支持关键帧注册。该模块重用了I2P模型的解码器块,并在此基础上增加了线性投影和平均池化层。
输入是一个关键帧和所有缓冲中的场景帧,通过预测关键帧与每个缓冲帧之间的相关性得分来进行检索。相关性得分不仅考虑视觉相似性,还为3D重建提供了合适的基准。
训练与损失函数:
该模块继承了I2P模型前两层解码器的权重,并使用L1损失来训练线性投影层。损失函数通过计算每个输入支持帧的相关性得分与I2P模型最终预测的均值置信度之间的差异来进行监督。
多关键帧联合配准(Multi-keyframe Co-registration)¶
架构改进:
在L2W模型中,场景解码器采用了与I2P模型中关键帧解码器相同的架构,允许同时输入和注册多个关键帧。这种方法减少了计算开销,因为可以通过一次解码过程注册多个关键帧。
通过这种方式,场景帧与关键帧之间可以双向交换信息,进一步提高了重建精度。
训练细节(Training Details)¶
数据集与训练数据:
使用了多个数据集进行训练,包括ScanNet++、ASE、CO3D-v2等。不同数据集采用了不同的采样策略,比如均匀采样和随机采样。
训练数据的图像首先被调整大小并居中裁剪到224×224像素。
模型训练过程:
I2P模型的训练使用了11帧的视频片段,其中中间帧作为关键帧,训练时使用L1损失进行监督。
L2W模型使用了长度为12的视频片段,其中前六帧为场景帧,后六帧为关键帧,经过200轮训练。
硬件配置:
训练使用了8台NVIDIA 4090D GPU,每个GPU拥有24GB内存,批处理大小为每个GPU 4个。
实验与结果¶
文中还展示了实验结果,包括SLAM3R方法在不同数据集上的重建效果以及与其他方法的比较,强调了SLAM3R在处理速度和准确性方面的优势。
总结来说,这部分内容详细描述了SLAM3R系统的核心模块和训练细节,展示了该系统如何通过多关键帧联合配准、轻量级检索模块以及高效的训练流程,实现在实时3D重建中的高效性和准确性。
Appendix B Details for experimental settings¶

Figure 6: The reconstruction results and the corresponding accuracy heatmaps of MASt3R [28] on Office 3 from Replica [54] dataset under different confidence thresholds. Lighter colors indicate higher accuracy.
这段内容主要介绍了论文中用于评估实验结果的几个重要指标及其计算方法,涉及重建质量、效率、相机姿态精度等方面的测量标准。具体来说:
1. 重建质量评估¶
重建质量通过准确性(Accuracy)和完整性(Completeness)两个指标来衡量。
准确性计算公式:对每个重建的点云中的点 \( x_i \),找到与之最接近的地面真值点 \( y_j \),然后计算该点之间的欧几里得距离 \( D(x_i, y_j) \),并取最小值,最后计算所有点的平均值。
完整性计算公式:对每个地面真值点 \( y_j \),找到与之最接近的重建点 \( x_i \),计算该点之间的欧几里得距离,最后计算所有点的平均值。
公式中的 \( P \) 和 \( Q \) 分别代表重建点云和真实点云中的点数,\( D(\cdot) \) 是欧几里得距离。
2. 效率评估¶
效率通过每秒处理帧数(FPS,frames per second)来衡量,计算方法为:
FPS = \( \frac{F}{\text{time}} \),其中 \( F \) 是视频中的帧数,time 是总的重建时间。
3. 相机姿态精度评估¶
使用绝对轨迹误差(ATE-RMSE)来衡量相机姿态精度。该指标计算预测轨迹与真实轨迹之间的欧几里得距离的均方根误差,公式为:
ATE-RMSE = \( \sqrt{\frac{1}{F}\sum_{i=1}^{F}D(T^{gt}_i, T^{perd}_i)^2} \),其中 \( T^{gt}_i \) 和 \( T^{perd}_i \) 分别代表真实和预测的相机位置。
4. 输入数据的不同设置¶
在不同的数据集上,作者采用了不同的输入帧采样方法:
在 Replica 数据集上,使用全视频帧作为输入,每20帧采样一次,并更新重建关键帧。
在 7 Scenes 数据集上,采用每20帧采样一次的方式,只重建采样帧的点云。
在 DUSt3R 和 MASt3R 数据集上,为了节省 GPU 内存,作者仅使用了 1/20 的图像进行全局重建质量评估。
5. 其他实验细节¶
DUSt3R 和 MASt3R 方法在使用高分辨率输入时,会遇到一些问题,尤其是在 MASt3R 中,偶尔会生成一些具有高置信度的浮动点,这些点难以通过置信度阈值进行过滤,从而影响了重建的准确性。
本文提出的 SLAM3R 方法通过有效的置信度评分,成功地减少了错误点的影响,从而提高了重建质量。
总之,这段内容描述了如何通过不同的评估指标来衡量重建质量、计算效率和相机姿态的精度,并详细说明了在多个数据集上的实验设置和方法调整。
Appendix C Additional comparisons and analyses¶
这段内容来自SLAM3R(一个实时密集场景重建的单目RGB视频处理系统)论文的附录部分,主要对比了SLAM3R与其他方法(如DUSt3R、Spann3R等)在不同数据集上的性能,并进行了进一步的实验分析。以下是对内容的逐项解析:
1. 数值结果对比¶
论文报告了SLAM3R与其他系统(如DUSt3R、Spann3R)在多个数据集(ScanNet、Tanks and Temples、ETH3D)上的重建误差比较。表格列出了不同场景下的“精度”和“完整性”两个指标。SLAM3R在大多数情况下优于Spann3R,并且与DUSt3R相比较表现相当或更好。这些实验结果验证了SLAM3R方法的有效性。
2. 窗口长度的收益递减¶
图9展示了SLAM3R在不同窗口长度下的关键帧重建结果。实验发现,随着窗口长度增加,重建的准确性和完整性最初快速提高,但之后逐渐下降。这是因为更长的窗口导致重叠区域减少,同时推理时间显著增加。最终,作者选择将窗口大小设置为11,以平衡重建质量和运行效率。
3. 场景帧数对配准的影响¶
实验展示了选择的场景帧数对关键帧配准的影响。随着选取的场景帧数增加,重建精度首先提高,但在某个阈值之后精度开始下降。选择太少的帧会导致缺少合适的帧,可能导致局部最小值;而选择太多帧会引入噪声,影响配准精度。因此,作者建议在大多数实验中使用5到10个场景帧来进行配准,以获得稳定且可靠的表现。
4. 相机位姿估计¶
这部分对比了SLAM3R与其他方法在相机位姿估计方面的表现。SLAM3R通过多视角输入和全局检索的层次化设计,表现出了较强的性能,优于一些同类方法,如Spann3R。此外,虽然一些经典SLAM系统(如GO-SLAM、DROID-SLAM)的位姿误差较小,但它们的重建精度和完整性较差。这表明,即使相机位姿不是完全准确,仍然能够通过有效的3D重建方法得到良好的重建结果。
总结¶
这段内容主要展示了SLAM3R在多个数据集上的性能评估,并深入分析了不同参数(如窗口长度、场景帧数等)对重建质量和效率的影响。实验表明,SLAM3R在大多数情况下超越了其他方法,并且通过合理选择参数(如窗口大小和场景帧数),能够在重建质量和运行效率之间找到平衡。
D. More visual results¶
Visualization of incremental reconstruction.¶
Figure 7 visualizes the process of our incremental reconstruction on two scenes from Replica [54]. Our method achieves effective alignment at loops while experiencing minimal cumulative drift, without offline global optimization step.

Figure 7: Visualization of the incremental reconstruction process of our method on the Office 3 and Room 1 of Replica [54] dataset. Our method achieves low drift without any global-optimization stage.
Reconstruction on DTU dataset.¶
The results are shown in Figure 8. Note that our method does not require any camera parameters, and produces dense point cloud reconstructions end-to-end in real-time.
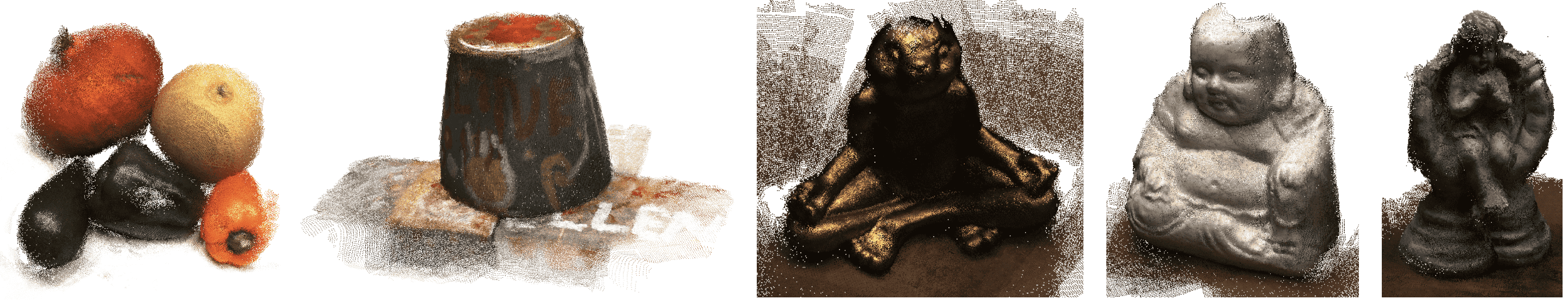
Figure 8: Reconstruction results on unorganized image collections from DTU [1] dataset.