2312.14132_DUSt3R: Geometric 3D Vision Made Easy¶
GitHub: https://github.com/naver/dust3r
组织: Aalto University, Naver Labs Europe
关键词¶
MVS: Multi-view stereo reconstruction
PnP: Perspective-n-Point
相关概念¶
📷 一、内参(Intrinsic Parameters)¶
内参描述的是摄像头自身的成像特性,即如何从摄像头坐标系中的三维点映射到二维图像平面上。常见的内参包括:
参数 |
含义 |
|---|---|
\( f_x, f_y \) |
焦距在图像x轴和y轴的像素单位值(通常是焦距乘以像素密度) |
\( c_x, c_y \) |
主点(principal point)的坐标,通常是图像中心 |
\( s \) |
偏轴系数(skew),描述x、y轴不垂直时的情况,通常为0 |
内参矩阵(相机矩阵)K 通常表示为:
此外,有时还包括畸变参数(distortion coefficients):
径向畸变:\( k_1, k_2, k_3 \)
切向畸变:\( p_1, p_2 \)
🌍 二、外参(Extrinsic Parameters)¶
外参描述的是摄像头相对于世界坐标系的位置和朝向,即世界坐标如何变换到摄像头坐标。包含:
参数 |
含义 |
|---|---|
\( R \) |
旋转矩阵,表示世界坐标系到摄像头坐标系的旋转 |
\( t \) |
平移向量,表示世界坐标系原点在摄像头坐标系下的位置 |
可以组成一个变换矩阵:
🧮 三、三维点到图像点的映射公式¶
给定一个世界坐标系中的三维点 \( X_{world} \),它投影到图像坐标系的公式如下:
其中:
\( X_{world} \) 是齐次坐标表示的三维点:$\( [X, Y, Z, 1]^T \)$
\( [R|t] \) 是 3x4 的外参矩阵
\( K \) 是 3x3 的内参矩阵
\( x_{image} \) 是图像中的点,通常需要再归一化处理(除以z)
🎯 应用场景¶
相机标定(Camera Calibration):获取内外参
三维重建 / SLAM:利用外参追踪摄像头位置
AR 增强现实:实现虚实对齐,必须准确知道内外参
Abstract¶
原文:
Multi-view stereo reconstruction (MVS) in the wild requires to first estimate the camera parameters e.g. intrinsic and extrinsic parameters. These are usually tedious and cumbersome to obtain, yet they are mandatory to triangulate corresponding pixels in 3D space, which is the core of all best performing MVS algorithms.
中文解释:
在自然环境下进行多视图立体重建(MVS)时,首先需要估计相机的参数,例如内参(intrinsic)和外参(extrinsic)。但这些参数通常很难获取且过程繁琐。然而,它们是必须的,因为只有通过这些参数,才能将不同图像中对应像素点三角测量还原为3D空间中的点,这是目前表现最好的MVS算法的核心。
原文:
In this work, we take an opposite stance and introduce DUSt3R, a radically novel paradigm for Dense and Unconstrained Stereo 3D Reconstruction of arbitrary image collections, i.e. operating without prior information about camera calibration nor viewpoint poses.
中文解释:
本研究提出了一种完全不同的做法,名为 DUSt3R,它是一种密集且无约束的立体三维重建新范式。它能处理任意图像集合,不需要任何相机标定信息或相机位姿先验,彻底摆脱了传统MVS的限制。
原文:
We cast the pairwise reconstruction problem as a regression of pointmaps, relaxing the hard constraints of usual projective camera models. We show that this formulation smoothly unifies the monocular and binocular reconstruction cases.
中文解释:
我们将两张图像之间的重建问题转化为“点图(pointmaps)”的回归任务,从而放松了传统投影相机模型的严格约束。我们证明,这种表述方式能够自然地统一单目和双目重建任务。
原文:
In the case where more than two images are provided, we further propose a simple yet effective global alignment strategy that expresses all pairwise pointmaps in a common reference frame.
中文解释:
当输入的图像超过两张时,我们进一步提出了一种简单而有效的全局对齐策略,可以将所有两两图像之间的点图统一到一个公共参考坐标系中。
原文:
We base our network architecture on standard Transformer encoders and decoders, allowing us to leverage powerful pretrained models.
中文解释:
我们采用标准的 Transformer 编码器和解码器作为网络架构,可以充分利用已有的强大预训练模型。
原文:
Our formulation directly provides a 3D model of the scene as well as depth information, but interestingly, we can seamlessly recover from it, pixel matches, relative and absolute cameras.
中文解释:
我们的方法不仅能直接输出场景的3D模型和深度图信息,而且有趣的是,还能从中自然恢复像素匹配关系、相对和绝对的相机参数。
原文:
Exhaustive experiments on all these tasks showcase that the proposed DUSt3R can unify various 3D vision tasks and set new SoTAs on monocular/multi-view depth estimation as well as relative pose estimation.
中文解释:
大量实验表明,DUSt3R 能统一多种3D视觉任务,并在单目/多视图深度估计、相对位姿估计等任务上设立了新的SOTA(最佳结果)。
原文:
In summary, DUSt3R makes many geometric 3D vision tasks easy.
中文解释:
总之,DUSt3R 让很多几何类3D视觉任务变得更简单了。
总结要点:
关键点 |
内容 |
|---|---|
传统MVS问题 |
依赖繁琐的相机内外参估计 |
DUSt3R创新点 |
不依赖相机参数,直接从图像构建3D模型 |
技术方法 |
点图回归 + Transformer架构 |
适用范围 |
单目、双目、多视图都适用 |
能力输出 |
可获取3D模型、深度图、像素匹配、相机姿态 |
成果表现 |
多个任务上刷新SOTA表现 |
1. Introduction¶
DUSt3R:一种用于从多视图图像中进行稠密三维重建(Dense 3D Reconstruction)的新方法。

Figure 1: Overview: Given an unconstrained image collection, i.e. a set of photographs with unknown camera poses and intrinsics, our proposed method DUSt3R outputs a set of corresponding pointmaps, from which we can straightforwardly recover a variety of geometric quantities normally difficult to estimate all at once, such as the camera parameters, pixel correspondences, depthmaps, and fully-consistent 3D reconstruction. Note that DUSt3R also works for a single input image (e.g. achieving in this case monocular reconstruction). We also show qualitative examples on the DTU, Tanks and Temples and ETH-3D datasets [108, 51, 1] obtained without known camera parameters. For each sample, from left to right: input image, colored point cloud, and rendered with shading for a better view of the underlying geometry.
💡 第一段:背景介绍¶
任务目标:
从多张图像中,估计一个场景的三维几何结构和相机参数——这是计算机视觉长期追求的终极目标之一。
备注
Unconstrained image-based dense 3D reconstruction from multiple views is one of a few long-researched end-goals of computer vision.
实际意义:
它有很多应用,如地图制作、导航、考古、文化遗产保护、机器人等。同时,它也涵盖了几乎所有几何相关的 3D 视觉任务。
技术演进:
传统 3D 重建方法是多个子领域长期技术积累的成果,比如
关键点检测(keypoint detection)
特征匹配(keypoint matching)
鲁棒估计(robust estimation)
Structure-from-Motion(SfM)、
Bundle Adjustment(BA)、
稠密多视图立体(dense Multi-View Stereo (MVS) )
🔧 第二段:传统方法的不足¶
传统 SfM + MVS 流程:
是一连串“最小子问题”(如特征匹配、三角化、相机估计、稀疏重建到稠密重建)组成的复杂流程。
问题在于:
这些子问题之间相互独立,彼此不协作,错误会级联传递,导致结果容易受到影响。此外,一些关键步骤(比如 SfM)在很多情况下不稳固,容易失败(比如图像数量太少、物体反光、相机运动太小等)。
核心问题:
如果相机参数估计不准,MVS 的结果质量也会跟着下降。
🚀 第三段:DUSt3R 的核心创新¶
目标:
提出一种新的、端到端的系统 DUSt3R,支持从 任意两张图像 中,重建三维结构,不需要任何相机参数(甚至连内参都不需要)。
关键点:
DUSt3R 输出的是一种新的结构叫 3D Pointmap,它具有以下能力:
表示场景几何;
关联图像像素和三维点;
表达两个视角之间的几何关系。
优势:
只通过一个网络,就能联合处理输入图像和生成的 3D Pointmap,把过去多个子问题合并为一个问题来学习和解决,从而提高整体协同与准确性。
📚 第四段:训练与建模思路¶
训练方式:
采用监督学习,使用合成数据、SfM 重建数据或真实传感器采集数据。
架构选择:
摒弃任务特定模块,使用通用 Transformer 架构,完全数据驱动,不强加几何先验。
网络学到的东西:
包括纹理、阴影、轮廓等形状先验,与传统 MVS 所依赖的几何 cue 类似,但是通过学习得到的。
🧩 第五段:多视图融合方式的新设计¶
传统 BA:
通过最小化重投影误差对相机和点进行优化。
DUSt3R 的做法:
引入一种新的全局对齐方法,不再使用重投影误差,而是直接在三维空间中对齐相机和几何信息,更快、更稳定。
效果:
在真实场景和未知相机条件下也能得到一致的重建效果。并且可以用于单目和多视图的场景。
📝 总结:论文贡献(四个方面)¶
首次实现:
一个统一、端到端的 3D 重建方法,不需要相机参数,支持单目和双目输入。Pointmap 表示:
提出 Pointmap 的方式保留了像素与场景之间的关系,规避了透视投影中的约束。多视图融合新策略:
通过 3D 对齐来融合多对图像的重建结果,不依赖 SfM/MVS 的中间步骤,但能导出它们常见的输出(相机位姿、稀疏点云等)。优异性能表现:
在单目/多视图深度估计、相机位姿估计任务中取得 SOTA(state-of-the-art)结果。
3. Method¶
概念定义¶
🟡 Pointmap(点图)¶
我们把一张图片上每一个像素点都对应一个三维空间的点,组织成一个二维的结构(宽 × 高 × 3),称为一个 pointmap(点图),记作:
这意味着:
图像有
W × H个像素点每个像素对应一个
3D坐标 (x, y, z)所以一张图像对应了一个
W × H × 3的三维张量
并且,这个 pointmap 和原始的 RGB 图像是 一一对应 的:
即每个像素 (i, j) 在图像中有颜色信息 I[i,j],同时也有一个 3D 点 X[i,j],表示这个像素点在现实三维空间中所对应的位置。
👉 可以理解为:点图是一个像素到三维世界坐标的映射。
📌 注意:这里假设每个像素射出去的光线只能打到一个唯一的三维点,即不考虑透明或半透明表面。
🟡 相机与场景建模(Cameras and Scene)¶
我们使用相机的内参矩阵 \(K ∈ ℝ^{(3×3)}\) 和一张对应的 深度图 \(D ∈ ℝ^{(W×H)}\) 来生成 pointmap X。
具体计算公式如下:
意思是:
D[i,j]是第(i, j)个像素点的深度值(相机到物体的距离)我们将像素坐标
(i, j)乘以深度,再加上深度值本身,组成一个[x, y, z]向量然后用相机内参矩阵的逆
K⁻¹反投影回相机坐标系,得到 3D 点X[i,j]
✅ 这一步是从“图像平面 + 深度” → “三维坐标”的标准反投影操作。
🟡 跨相机坐标转换(多视角点图的转换)¶
定义一个记号: \(X^{n,m}\) 表示第 n 个相机拍到的场景,通过转换,映射到第 m 个相机的坐标系中。
具体公式是:
解释如下:
\(X^n\):在相机
n的坐标系下的点图h(X):表示对X中的每个点做齐次变换(x,y,z) → (x,y,z,1),这是为了解决矩阵乘法需要齐次坐标P_n和P_m是两个相机的 世界到相机坐标的变换矩阵(pose), \(P ∈ ℝ^{(3×4)}\)P_n⁻¹:把相机n坐标系的点变换到世界坐标系P_m:再从世界坐标系变换到相机m的坐标系
✅ 所以这一公式完成了从相机
n拍到的点图,变换到相机m的坐标系下的点图。
✍️ 总结:¶
项目 |
含义 |
|---|---|
Pointmap (X) |
图像中每个像素点对应的 3D 点,维度为 |
I[i,j] ↔ X[i,j] |
每个像素和其三维点一一对应 |
X[i,j] 生成方式 |
利用深度图和相机内参进行反投影 |
X^{n,m} |
相机 |
变换公式 |
|
3.1 Overview¶
🧠 目标概述¶
训练一个网络来解决「广义立体视觉下的3D重建任务」,采用的方式是 直接回归(regression)。
输入:
两张 RGB 图像 \( I^1, I^2 \in \mathbb{R}^{W \times H \times 3} \)
输出:
两个与图像对应的 点图(pointmaps),分别是 \( X^{1,1}, X^{2,1} \in \mathbb{R}^{W \times H \times 3} \)(每个像素都有一个三维坐标)
以及各自的 置信图(confidence maps) \( C^{1,1}, C^{2,1} \in \mathbb{R}^{W \times H} \)
特别之处: 这两个点图都用第一个图像 \( I^1 \) 的坐标系来表达,这是一个非常规但很有优势的设计。
🏗️ 网络架构(Inspired by CroCo)¶
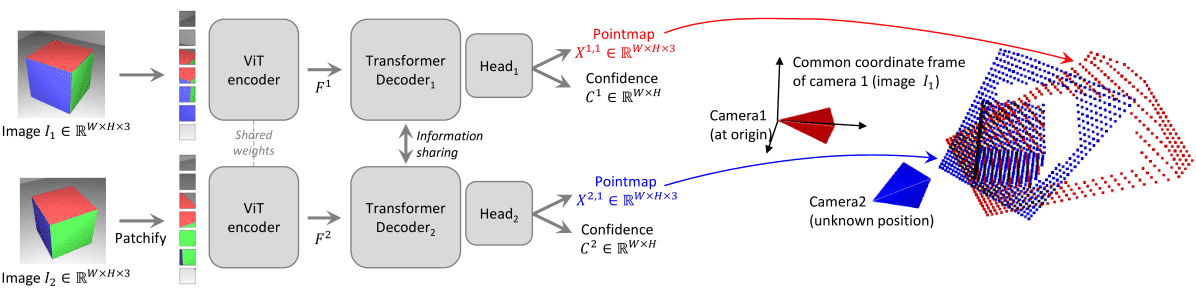
Figure 2: Architecture of the network \(\mathcal{F}\) . Two views of a scene \((I^{1},I^{2})\) are first encoded in a Siamese manner with a shared ViT encoder. The resulting token representations \(F^{1}\) and \(F^{2}\) are then passed to two transformer decoders that constantly exchange information via cross-attention. Finally, two regression heads output the two corresponding pointmaps and associated confidence maps. Importantly, the two pointmaps are expressed in the same coordinate frame of the first image \(I^{1}\). The network \(\mathcal{F}\) is trained using a simple regression loss
整体结构是一个 Siamese 双支路网络,即:
编码阶段(Encoder): 两个图像 \( I^1, I^2 \) 会被一个共享权重的 ViT(Vision Transformer)编码器编码为:
\( F^1 = \text{Encoder}(I^1) \)
\( F^2 = \text{Encoder}(I^2) \)
解码阶段(Decoder): 采用类似 CroCo 的 decoder,由多个 transformer block 组成,每个 block 有:
Self-Attention(自注意):在每个视角内进行
Cross-Attention(交叉注意):跨两个图像之间的信息交互(比如 \( G^1_i \) 需要看 \( G^2_{i-1} \) 的 token)
这个设计的关键点在于 每一层都在两个视角之间传递信息,确保生成的点图彼此对齐(aligned)。
初始化:
\( G_0^1 := F^1 \)
\( G_0^2 := F^2 \)
每一层的计算形如:
\[\begin{split} G_i^1 = \text{DecoderBlock}_i^1(G_{i-1}^1, G_{i-1}^2) \\ G_i^2 = \text{DecoderBlock}_i^2(G_{i-1}^2, G_{i-1}^1) \end{split}\]
回归头(Regression Heads): 将每个分支的 decoder token 送入各自的回归头,输出最终的:
点图(pointmap)
置信图(confidence map)
\[\begin{split} X^{1,1}, C^{1,1} = \text{Head}^1(G_0^1, ..., G_B^1) \\ X^{2,1}, C^{2,1} = \text{Head}^2(G_0^2, ..., G_B^2) \end{split}\]
💡 设计讨论(Discussion)¶
输出的点图只是「相对点云」,尺度是未知的(即 scale-ambiguous)。
网络本身不强制遵守几何约束,而是完全依赖数据中的几何一致性来「学出几何」。
虽然不是基于传统相机模型(如投影几何),但可以利用强大的预训练模型来获得更强泛化。
这让它相比于任务特定设计的网络,更通用、扩展性更强。
✅ 总结¶
DUSt3R 用一个 ViT 编码器 + 跨视角 transformer 解码器 + 回归头,直接从两张 RGB 图中输出两个对齐的 3D 点图(不依赖几何建模),通过训练数据自动学习几何。
3.2 Training Objective¶

Figure 3: shows the outcome of global alignment

Figure 3: Reconstruction examples on two scenes never seen during training. From left to right: RGB, depth map, confidence map, reconstruction. The left scene shows the raw result output from \(\mathcal{F}(I^{1},I^{2})\) .
一、3D回归损失(3D Regression Loss)¶
这是网络的主要训练目标,核心思想是:
直接在三维空间上进行点的回归损失计算,即:预测的3D点图(pointmap)与真实的3D点图之间的误差(欧几里得距离)。
1.变量定义
\(\bar{X}^{1,1}, \bar{X}^{2,1}\):来自 ground-truth(真实点图)的两幅图像对应的 3D 点图。
\(X^{1,1}, X^{2,1}\):对应预测的 3D 点图。
\(\mathcal{D}^{1}, \mathcal{D}^{2}\):分别是有效像素(即有 ground-truth 的像素)的位置集合。
\(i \in \mathcal{D}^v\):视角 \(v\) 中的一个有效像素点索引。
\(X_i^{v,1}\):在视角 \(v\) 下,像素 \(i\) 对应的预测 3D 点。
\(\bar{X}_i^{v,1}\):对应的 ground-truth 3D 点。
2.损失函数定义 单个像素 \(i\) 的回归损失是预测点与真实点之间的 归一化欧几里得距离:
\[ \ell_{\text{regr}}(v,i) = \left\|\frac{1}{z}X^{v,1}_{i}-\frac{1}{\bar{z}}\bar{X}^{v,1}_{i}\right\| \]归一化的原因: 由于输入图像对的尺度/深度范围不确定,预测结果和 ground-truth 可能存在尺度差异。所以:
\(z\) 是对预测点图的整体尺度归一化因子
\(\bar{z}\) 是对真实点图的整体归一化因子
归一化方式为:
\[ \text{norm}(X^1, X^2) = \frac{1}{|\mathcal{D}^1| + |\mathcal{D}^2|} \sum_{v \in \{1, 2\}} \sum_{i \in \mathcal{D}^v} \|X^v_i\| \]意思是:所有有效像素的平均欧几里得距离(从原点出发)。
二、置信度感知损失(Confidence-aware Loss)¶
现实中图像存在很多“不确定区域”:
比如天空、透明物体、反射表面等,这些地方的 3D 重建不靠谱;
网络预测这些地方时信心也低。
引入置信度的原因: 让网络不仅预测 3D 点,还预测对每个像素的 置信度分数 \(C_i^{v,1}\),用来调节该像素对损失函数的影响。
置信度加权后的最终损失函数: $\( \mathcal{L}_{\text{conf}} = \sum_{v \in \{1,2\}} \sum_{i \in \mathcal{D}^v} C_i^{v,1} \cdot \ell_{\text{regr}}(v, i) - \alpha \log C_i^{v,1} \)$
含义如下:
第一项是置信度加权的 3D 回归损失;
第二项是正则项,鼓励置信度不要无限大(否则模型就可以总是给高置信度来压低损失);
\(\alpha\) 是权重超参数。
为保证 \(C_i > 0\),定义方式为: $\( C_i^{v,1} = 1 + \exp(\widetilde{C}_i^{v,1}) > 1 \)$
即:预测的是 \(\widetilde{C}\),然后通过
exp变换加1,保证最终置信度始终为正。
总结理解:¶
DUSt3R 网络训练目标设计非常简洁直观:
核心思想:直接对三维点云进行回归,而非像很多方法那样预测深度或视差图;
为了应对现实图像中存在的不确定区域,引入每像素置信度预测机制,并将其用于加权损失;
整体损失具有尺度不变性(通过点图归一化)和不确定性鲁棒性(通过置信度权重调节)。
3.3 Downstream Applications¶
✅ Point Matching(点匹配)¶
这部分讲的是如何在两张图片之间建立像素级别的匹配关系:
在两张图片的 pointmap(例如 \(X^{1,1}\) 和 \(X^{1,2}\))中,每个像素对应一个三维点(x, y, z)。所以可以直接在三维空间中使用最近邻(Nearest Neighbor, NN)搜索来做点匹配。
双向最近邻匹配:为了减少错误匹配,使用的是 互为最近邻 的点对:
\[ \mathcal{M}_{1,2} = \{(i, j)\ |\ i = \text{NN}_{1}^{1,2}(j)\ \text{and}\ j = \text{NN}_{1}^{2,1}(i)\} \]也就是说,从图像 1 的第 \( i \) 个像素出发,在图像 2 中找到最近的三维点是 \( j \),
同时,从图像 2 的 \( j \) 出发,最近的三维点回到了图像 1 的 \( i \),则认为这是一个匹配对。
最近邻的定义:
\[ \text{NN}_{k}^{n,m}(i) = \arg\min_{j \in \{0,\ldots,WH\}} \|X^{n,k}_j - X^{m,k}_i\| \]表示在图像 \( n \) 和 \( m \) 的第 \( k \) 层之间,对 \( i \) 点寻找最小欧氏距离的 \( j \) 点。
✅ Recovering Intrinsics(恢复相机内参)¶
Pointmap 是以图像坐标系表达的三维点,所以可以用这些点倒推出相机的内参,特别是焦距 \( f \)。
假设主点(principal point)在图像中心,像素是正方形,所以只需估计焦距 \( f_1^* \)。
优化目标是最小化 3D 点投影与实际像素位置之间的差异:
\[ f_1^* = \arg\min_{f_1} \sum_{i=0}^{W} \sum_{j=0}^{H} C^{1,1}_{i,j} \left\|(i',j') - f_1 \cdot \frac{(X^{1,1}_{i,j,0}, X^{1,1}_{i,j,1})}{X^{1,1}_{i,j,2}} \right\| \]其中:
\( (i', j') = (i - W/2, j - H/2) \),将像素中心化;
\( X^{1,1}_{i,j,*} \) 是三维点坐标;
\( C^{1,1}_{i,j} \) 是权重(例如可见性、置信度)。
可用 Weiszfeld 算法等快速迭代方法求解。
第二张图像的焦距 \( f_2^* \) 同理,只需换用 \( X^{2,2} \)。
✅ Relative Pose Estimation(相对姿态估计)¶
相机之间的相对位置和方向可以通过两种方式估计:
方法一:传统方式
用 pointmap 做点匹配;
恢复内参;
用匹配点对计算 基础矩阵或本质矩阵(Epipolar Matrix);
从中恢复旋转 \( R \) 和位移 \( t \)。
方法二:Procrustes 对齐(推荐)
更直接的方法是对两个 pointmap 直接对齐:
\[ R^*, t^* = \arg\min_{\sigma, R, t} \sum_i C^{1,1}_i C^{1,2}_i \left\| \sigma(R X^{1,1}_i + t) - X^{1,2}_i \right\|^2 \]这是经典的 带缩放的 Procrustes 对齐 问题;
目标是寻找最优的旋转 \( R \)、平移 \( t \) 和尺度因子 \( \sigma \),使两个点云对齐;
\( C^{1,1}_i \) 和 \( C^{1,2}_i \) 是每个点的权重或置信度。
总结¶
任务 |
做法 |
特点 |
|---|---|---|
点匹配 |
最近邻搜索 pointmap,双向过滤 |
快速、鲁棒 |
相机内参恢复 |
优化像素与 3D 投影的差异,求焦距 |
可直接从 pointmap 得到 |
相对姿态估计 |
可选:传统基础矩阵 or Procrustes 点云对齐 |
后者更直接、高效 |
这个方法的关键优势是:它将像素映射到三维点(pointmap)后,可以跳过中间很多传统步骤,直接用 3D 几何做视觉任务。
3.4 Global Alignment¶
核心思想是:通过构建一个图结构,将多个图像对中预测的点云进行全局对齐,从而将多个视角下的点图(pointmap)联合优化,统一到一个三维坐标系中。这种优化是 DUSt3R 这一类方法实现跨图像一致性的关键。我们可以从三个层面来理解它:
✦ 一、构建图结构: Pairwise Graph¶
给定一组图像 \(\{I^1, I^2, \ldots, I^N\}\),我们构造一个连接图 \(\mathcal{G}(\mathcal{V}, \mathcal{E})\):
节点 \(\mathcal{V}\): 每个图像为一个节点。
边 \(\mathcal{E}\): 图像对之间存在视觉重叠(通过图像检索或网络 \(\mathcal{F}\) 推理得到置信度高的图像对)才建立边。
这样一来,我们就得到了图像之间“可以相互配准”的关系图。
✦ 二、全局优化: Global optimization¶
目标是对每个图像 \(n\),估计其在世界坐标系下的点图 \(\chi^n \in \mathbb{R}^{W \times H \times 3}\),即将每幅图像的深度映射结果全局对齐。
步骤如下:
预测每对图像的点图和置信度:
对每条边 \(e = (n, m)\),通过网络 \(\mathcal{F}\) 预测出:
图像 \(n\) 和 \(m\) 的点图 \(X^{n,n}, X^{m,n}\)(统一在图像 \(n\) 的坐标系中)
对应的置信度图 \(C^{n,n}, C^{m,n}\)
为统一记号,定义: $\( X^{n,e} := X^{n,n},\quad X^{m,e} := X^{m,n} \)$
引入刚性变换(rigid transformation)和尺度:
每条图像对 \(e\) 关联一个刚性变换矩阵 \(P_e \in \mathbb{R}^{3 \times 4}\)(包含旋转和平移)和尺度 \(\sigma_e > 0\)
构建优化目标:
最终优化目标是最小化每个点图 \(\chi^n\) 与其预测的变换点图 \(\sigma_e P_e X^{n,e}\) 之间的加权 L2 距离,权重来自置信度图:
\[ \chi^* = \arg\min_{\chi, P, \sigma} \sum_{e \in \mathcal{E}} \sum_{v \in \{n, m\}} \sum_{i=1}^{HW} C^{v,e}_i \left\| \chi^v_i - \sigma_e P_e X^{v,e}_i \right\| \]直观理解就是:让每张图像的预测点图,在刚性变换与尺度下,尽可能接近它在世界坐标中的估计值。
防止退化(全零尺度):
为防止 \(\sigma_e = 0\) 导致的退化,增加约束: $\( \prod_e \sigma_e = 1 \)$
✦ 三、相机参数恢复:Camera Parameter Recovery¶
前面我们是直接优化每个图像的点图 \(\chi^n\),但实际上也可以从深度图 \(D^n\) 反推 \(\chi^n\):
使用标准针孔相机模型(Eq. 1): $\( \chi^n_{i,j} := P_n^{-1} \cdot h \left( K_n^{-1} \cdot \begin{bmatrix} i D^n_{i,j} \\ j D^n_{i,j} \\ D^n_{i,j} \end{bmatrix} \right) \)$
这样可以通过 \(\chi^n\) 反推出每个相机的位姿 \(P_n\) 和内参 \(K_n\)。
✅ 总结重点¶
模块 |
作用 |
|---|---|
\(\mathcal{F}\) 网络 |
对图像对进行点图预测 |
图结构 \(\mathcal{G}\) |
指示哪些图像需要对齐 |
\(P_e, \sigma_e\) |
对每对图像的刚体变换与尺度进行建模 |
优化目标 |
保证所有点图在统一世界坐标系中对齐,保持一致性 |
相机参数恢复 |
利用优化后的点图反推每个图像的位姿与内参 |
4. Experiments with DUSt3R¶
前言¶
🧠 1. 训练数据(Training data)¶
他们用了 8个数据集 来训练模型,涵盖各种场景:
室内/室外(例如 ScanNet++ 是室内,Waymo 是户外)
真实/合成(例如 Blended MVS 是合成数据)
面向物体/面向场景(例如 CO3D 是物体中心的)
有些数据集没有自带图像对(image pairs),采用了一种方法(参考文献[149])来自动构建图像对:
使用现成的图像检索 + 特征匹配方法,筛选和验证图像对。
最终一共收集了 850 万对图像(8.5M pairs) 作为训练数据。
🏗️ 2. 训练细节(Training details)¶
数据平衡:每轮训练中,会均匀采样每个数据集中的图像对,防止某些数据集占比过大。
图像分辨率策略:
初期训练用较小尺寸
224×224后期再用更高的
512px最大边尺寸图像训练(提高性能但成本更高)
图像形状处理:随机选择长宽比(如 16:9、4:3),裁剪后统一调整最大边到 512px,使模型对不同形状图像更鲁棒。
数据增强:使用常见的数据增强方法(没有具体列出,但可理解为旋转、缩放、颜色扰动等)。
网络结构:
Encoder:ViT-Large(大模型)
Decoder:ViT-Base(中模型)
Head:DPT Head(用于深度预测等任务)
预训练初始化: 使用 CroCo 预训练模型权重作为初始化。CroCo 是一种 跨视图图像恢复任务的自监督预训练方法,非常适合 3D 视觉任务。
📊 3. 评估(Evaluation)¶
使用 同一个 DUSt3R 模型(DUSt3R 512) 来评估多个下游任务,从不对特定任务进行微调(zero-shot 评估风格)。
所有测试图像都会被等比例缩放到最大边 512px。
针对每个下游任务(如三维重建、配准、姿态估计等),采用不同输出方式,具体方法见第 3.3 和 3.4 节。
🎨 4. 定性结果(Qualitative results)¶
DUSt3R 即使在困难场景中也能生成高质量、稠密的 3D 重建结果。
附录中展示了很多 “非挑选”的可视化例子,包括图像对和多视图的重建效果。
✅ 总结一下关键点:¶
部分 |
内容 |
|---|---|
训练数据 |
多源数据集、850万图像对、多样性强 |
训练方法 |
小分辨率预热→大分辨率主训,数据增强,随机长宽比 |
模型结构 |
ViT-Large 编码器 + ViT-Base 解码器 + DPT Head |
预训练 |
使用 CroCo 初始化,适合 3D 任务 |
评估策略 |
单模型,多任务评估,无微调,输入统一为 512px |
结果展示 |
可视化效果好,不挑图,鲁棒性强 |
4.1 视觉定位(Visual Localization)¶
实验目标: 评估 DUSt3R 在绝对位姿估计任务(absolute pose estimation)中的表现,测试集为两个经典数据集:
7Scenes:7个室内场景,RGB-D 图像+6自由度相机位姿。
Cambridge Landmarks:6个室外场景,RGB 图像+SfM恢复的相机位姿。
评价指标:
中位数平移误差(translation error,单位 cm)
中位数旋转误差(rotation error,单位 °)
实验方法:
DUSt3R 作为一个 2D-2D像素匹配器(pixel matcher),用于计算查询图像与数据库图像之间的像素点对应。
数据库图像通过图像检索方法 AP-GeM 检索获得。
对于 Cambridge 使用 top 20 图像,7Scenes 使用 top 1。
没有使用任何后处理或精化(例如 bundle adjustment),也没有使用 GT 内参会有单独说明。
关键点:
仅使用 DUSt3R 输出的点云匹配(pointmap)来做位姿估计,完全 零训练用于视觉定位的监督。
DUSt3R 训练时也没有见过测试集中的图像。
与特征匹配类方法(如 HLoc)和端到端学习方法比较,表现相当甚至超越部分强基线(如 HLoc)。
4.2 多视角相对位姿估计(Multi-view Pose Estimation)¶
实验目标:
测试 DUSt3R 在多视角序列中的相对位姿估计效果。
数据集:
CO3Dv2:6M 帧,来自 37K 视频,51类对象(来自 MS-COCO),使用 COLMAP 计算真值位姿。
RealEstate10k:室内外场景,10M 帧,约 80K YouTube 视频片段,用 SLAM + BA 提取位姿。
实验设置:
对每段视频随机选 10 帧,构成 45 对图像输入 DUSt3R。
使用两种方式求解相对位姿:
PnP-RANSAC
全局对齐(global alignment)
评价指标:
RRA@15:相对旋转精度(角度误差 < 15° 的比例)
RTA@15:相对平移精度(角度误差 < 15° 的比例)
mAA@30:最小值 min(RRA@30, RTA@30) 下的平均准确率(AUC)
结果亮点:
DUSt3R 在两种数据集上都表现 优于目前最强的方法 PoseDiffusion。
即便只使用简单的 PnP 解法也超过现有学习与几何基线。
RealEstate10K 中 PoseDiffusion 使用 CO3Dv2 训练,但 DUSt3R 是纯零训练。
4.3 单目深度估计(Monocular Depth Estimation)¶
方法简述:
直接用图像
I输入 DUSt3R 自身作为查询图像和数据库图像,即ℱ(I, I)。输出点云中的 z 轴坐标即为预测深度。
数据集:
户外: KITTI, DDAD
室内: NYUv2, BONN, TUM
评价指标:
AbsRel:绝对相对误差 = |y - ŷ| / y
δ<1.25:预测深度和真实深度之比在 1.25 倍以内的像素比例
结果:
DUSt3R 属于 zero-shot 模型,没有针对深度估计训练。
表现优于自监督方法,甚至接近或超越很多监督方法。
可与 SlowTv(一个融合多源数据训练的大模型)媲美。
4.4 多视角深度估计(Multi-view Depth)¶
📌 方法概述:
DUSt3R 被用于多视图立体(Multi-view Stereo, MVS)深度估计任务,具体做法是:
利用它预测出的 点云图(pointmaps)中的 z 坐标作为深度图(depthmap)。
如果某张图像有多个角度的预测深度图,就会先统一缩放(rescale)到同一尺度,然后通过**置信度加权平均(weighted averaging by confidence)**的方法融合。
📊 评估方式:
使用了四个常见 MVS 数据集:DTU、ETH3D、Tanks and Temples、ScanNet。
指标包括:
Absolute Relative Error(绝对相对误差)
Inlier Ratio(内点比):阈值为 1.03
他们不使用 ground-truth 摄像机参数或深度范围,所以预测结果只有相对尺度。
为了做量化评估,会用 预测值和 GT 深度的中位数比值来做归一化(参考文献 [110] 的方法)。
🏆 实验结果:
DUSt3R 在 ETH3D 数据集上达到 SOTA 精度,在所有数据集上总体表现也超过了大部分使用 GT 摄像机位姿的 SOTA 方法。
速度方面也远超传统的 COLMAP 重建管线。
这说明该方法在多种场景(室内/室外,小尺度/大尺度)下都很适用,尤其在没见过的测试集上也能泛化(除了 ScanNet,因为它的训练集是 Habitat 数据集一部分)。
4.5 三维重建(3D Reconstruction)¶
📌 方法概述:
这部分评估的是整套流程(包括前面提到的 global alignment 对齐过程)之后得到的 3D 重建质量。
该方法特别之处在于:无监督、无先验(unconstrained MVS) —— 也就是说,完全不依赖于摄像头的内/外参信息。
评估时将预测结果对齐到 ground-truth 坐标系(用 Eq.5 的参数作为常数)。
📊 数据集与评估指标:
使用 DTU 数据集,零样本测试(zero-shot):不在 DTU 上微调,直接用原始模型。
指标包括:
Accuracy(精度):预测点到 GT 点云的最小距离
Completeness(完整性):GT 点到预测点云的最小距离
Overall:两者的平均
⚖️ 实验结果分析:
精度上略低于 SOTA 方法。原因:
其他方法用了 GT 摄像机位姿并在 DTU 上训练过。
最好的重建方法依赖亚像素级三角测量(sub-pixel triangulation),这需要明确的相机参数。
而 DUSt3R 使用的是回归方式(regression),精度本身就会受限。
尽管如此,在无任何相机信息前提下,仍达到 2.7mm 的平均精度,0.8mm 的完整性,总体误差 1.7mm,对于实用场景已经相当不错,尤其考虑到它是一个 plug-and-play 的方法。
4.6 消融实验(Ablations)¶
📌 消融点:
分析了两个因素对模型性能的影响:
CroCo 的预训练效果
图像分辨率的影响
📊 实验方式:
对比了前面任务(视觉定位、多视角位姿估计、多视角深度估计)在不同设置下的表现(见表 1、2、3)。
🧠 结论:
高分辨率和良好的预训练策略对最终表现有显著帮助。
和其他研究(如 [149] 和 [78])的结论一致:现代数据驱动方法高度依赖预训练和输入质量。
🧩 总结一句话:¶
DUSt3R 是一个无需摄像机参数、可 plug-and-play 的端到端 3D 重建系统,在多种任务上取得了令人瞩目的性能,虽然在极限精度上不及传统方法,但大大简化了流程,并保持了良好的泛化能力。
5. Conclusion¶
🔚 总结内容解析¶
原文摘要:
“我们提出了一种新范式,能够在没有任何关于场景或相机的先验信息的情况下完成3D重建,并且适用于各种3D视觉任务。”
✅ 关键词解释:¶
新范式(novel paradigm):DUSt3R 引入的是一种新的思路,不像传统方法那样依赖相机参数或结构先验,而是通过训练好的模型从图像中直接恢复3D信息。
in-the-wild:这意味着方法能在真实环境中工作,不局限于实验室或合成数据。
无需先验信息:DUSt3R 不需要已知的相机内参(intrinsics)、外参(extrinsics),或场景的深度范围等信息。
多种任务:不只是 3D重建,DUSt3R 还能处理视觉定位、多视图几何等任务。
📌 总结关键词提炼¶
关键词 |
含义 |
|---|---|
Raw output |
未后处理的网络原始输出(深度、置信图、点云) |
Viewpoint/Focal change |
摄像机角度或焦距变化(DUSt3R能处理) |
Pointmap recovery |
从图像恢复出3D点图+相机姿态 |
Unseen scenes |
测试图像没有出现在训练中,验证泛化能力 |
Plug-and-play |
开箱即用,不需要先验信息或复杂配置 |
Appendix A 附录概览¶
本附录提供了关于 DUSt3R 的补充信息与定性结果,具体内容如下:
B节 展示了该架构在具有挑战性的真实世界数据集上的成对预测的定性结果,同时还描述了与本文配套的视频资料。
C节 扩展了相关工作的讨论,涵盖了更广泛的方法类别及几何视觉任务。
D节 提供了多视图姿态估计任务的辅助消融实验结果,这部分由于篇幅限制未能包含在主文中。
E节 报告了一个实验性的视觉定位任务的结果,在该任务中,相机内参是未知的。
F节 详细介绍了训练流程与所采用的数据增强策略。
Appendix B. Qualitative results¶
相关视频: 视频链接

Figure 4:Example of 3D reconstruction of an unseen MegaDepth scene from two images (top-left). Note this is the raw output of the network, i.e. we show the output depthmaps (top-center, see Eq. 8) and confidence maps (top-right), as well as two different viewpoints on the colored pointcloud (middle and bottom). Camera parameters are recovered from the raw pointmaps, see Sec. 3.3 in the main paper. DUSt3R handles strong viewpoint and focal changes without apparent problems

Figure 5:Example of 3D reconstruction of an unseen MegaDepth [56] scene from two images only. Note this is the raw output of the network, i.e. we show the output depthmaps (top-center) and confidence maps (top-right), as well as different viewpoints on the colored pointcloud (middle and bottom). Camera parameters are recovered from the raw pointmaps, see Sec. 3.3 in the main paper. DUSt3R handles strong viewpoint and focal changes without apparent problems

Figure 6:Example of 3D reconstruction from two images only of unseen scenes, namely KingsCollege(Top-Left), OldHospital (Top-Middle), StMarysChurch(Top-Right), ShopFacade(Bottom-Left), GreatCourt(Bottom-Right). Note this is the raw output of the network, i.e. we show new viewpoints on the colored pointclouds. Camera parameters are recovered from the raw pointmaps, see Sec. 3.3 in the main paper.

Figure 7:Example of 3D reconstruction from two images only of unseen scenes, namely Chess, Fire, Heads, Office (Top-Row), Pumpkin, Kitchen, Stairs (Bottom-Row). Note this is the raw output of the network, i.e. we show new viewpoints on the colored pointclouds. Camera parameters are recovered from the raw pointmaps, see Sec. 3.3 in the main paper.

Figure 8:Examples of 3D reconstructions from nearly opposite viewpoints. For each of the 4 cases (motorcycle, toaster, bench, stop sign), we show the two input images (top-left) and the raw output of the network: output depthmaps (top-center) and confidence maps (top-right), as well as two different views on the colored point-clouds (middle and bottom). Camera parameters are recovered from the raw pointmaps, see Sec. 3.3 in the main paper. DUSt3R handles drastic viewpoint changes without apparent issues, even when there is almost no overlapping visual content between images, e.g. for the stop sign and motorcycle. Note that these example cases are not cherry-picked; they are randomly chosen from the set of unseen CO3D_v2 sequences. Please refer to the video for animated visualizations.
Appendix D. 多视角姿态估计(Multi-view Pose Estimation)¶
🌟 核心结论:¶
DUSt3R 在 CO3Dv2 数据集上,即便只有 3 张输入图像,也大幅超过所有已有方法,包括当前最强的 PoseDiffusion。
[Fig. 9] 展示了 RealEstate10K 上的稠密点云恢复效果,即使首尾帧视角变化巨大。

Figure 9:Reconstruction example from 4 random frames of a RealEstate10K indoor sequence, after global alignment. On the left-hand side, we show the 4 input frames, and on the right-hand side the resulting point-cloud and the recovered camera intrinsics and poses.
Appendix E. 视觉定位(Visual Localization)¶
🌟 核心结论:¶
DUSt3R 在 7-Scenes 数据集(室内)上表现稳定,但在 Cambridge-Landmarks 数据集(室外)上效果较差,原因是后者点云稀疏,难以对重建结果做比例缩放。
🧪 实验设定:¶
摄像机焦距未知(Realistic setting)
方法:从 DUSt3R 输出的相对姿态(Rel-Pose)+ 使用数据库图像 GT 点云进行比例缩放
最终从缩放后的点云提取绝对姿态
📊 表格解读(Tab. 6):¶
数据集 |
方法 |
平移误差(cm) / 旋转误差(°) |
|---|---|---|
7Scenes(Chess) |
DUSt3R(scaled rel-pose) |
5 / 1.08 |
Cambridge(S. Facade) |
DUSt3R(scaled rel-pose) |
64 / 0.97 |
在 7Scenes 上几乎都是 2~6cm 级别的误差,旋转也在 1° 左右,表现很强。
在 Cambridge 上平移误差非常大(几十cm),关键原因是“数据库点云稀疏,比例缩放不可靠”。
📌 总结亮点:¶
模块 |
优势 |
挑战 |
|---|---|---|
Multi-view Pose Estimation |
极少视图(3帧)下表现优异,泛化强,无需目标数据集训练 |
- |
Visual Localization |
在密集 GT 点云下有较好定位精度 |
稀疏点云时比例缩放难以估计,影响定位 |
Appendix F. Training details¶
一、训练数据来源和处理¶
✅ 点云(pointmaps)的生成
对于图像 \( I^1 \) 和 \( I^2 \),DUSt3R 通过相机内参 \( K_1, K_2 \in \mathbb{R}^{3\times3} \)、相机姿态 \( P_1, P_2 \in \mathbb{R}^{3\times4} \) 和深度图 \( D_1, D_2 \in \mathbb{R}^{W\times H} \) 构建参考帧下的点云:
\( \bar{X}^{1,1} = K_1^{-1}([U; V; 1] \cdot D_1) \)
\( \bar{X}^{2,1} = P_1 P_2^{-1} h(K_2^{-1}([U; V; 1] \cdot D_2)) \)
其中 \( U, V \in \mathbb{R}^{W \times H} \) 是像素坐标网格,\( h(\cdot) \) 表示齐次坐标变换。
✅ 深度图的提取方式
每个像素点的深度值 \( D^1_{i,j} \) 可由点云的第三个坐标维度直接获得:
\( D^1_{i,j} = \bar{X}^{1,1}_{i,j,2} \)
因此,主文和附录中的所有深度图均可由点云输出的第 2 维直接提取(例如:\( X^{1,1}_{:,:,2} \))。
✅ 训练集混合
使用 8 个数据集混合训练,覆盖各种场景(室内、室外、真实、合成、物体中心等):
Habitat, ARKitScenes, MegaDepth, Static Scenes 3D, Blended MVS, ScanNet++, CO3Dv2, Waymo
总共提取了约 850 万对图像对。
二、数据增强策略¶
标准图像增强:随机颜色抖动 + 居中裁剪(焦距增强的一种形式)。
居中裁剪确保主点始终在中心,有助于生成更多变化的焦距组合。
训练时图像对双向输入:即同时训练 \( (I^1, I^2) \) 和 \( (I^2, I^1) \),增强泛化能力。
注意:两个方向的 token 不发生交互。
三、训练超参数(见表 7)¶
项目 |
低分辨率训练 |
高分辨率训练 |
DPT 训练 |
|---|---|---|---|
Prediction Head |
Linear |
Linear |
DPT |
Optimizer |
AdamW |
AdamW |
AdamW |
学习率 |
1e-4 |
1e-4 |
1e-4 |
Weight Decay |
0.05 |
0.05 |
0.05 |
Adam β 参数 |
(0.9, 0.95) |
(0.9, 0.95) |
(0.9, 0.95) |
每轮样本对数 |
70 万对 |
7 万对 |
7 万对 |
Batch Size |
128 |
64 |
64 |
训练轮数 |
50 |
100 |
90 |
Warmup |
10 轮 |
20 轮 |
15 轮 |
学习率调度器 |
Cosine Decay |
Cosine Decay |
Cosine Decay |
输入分辨率 |
224×224 |
多种组合,包括 512×384, 512×336, 512×288, 512×256, 512×160 等 |