Scaling of Search and Learning: A Roadmap to Reproduce o1 from Reinforcement Learning Perspective¶
- 本文旨在复现 OpenAI 的 O1 模型,并从强化学习的角度分析其实现路线图。研究重点聚焦于四个关键组成部分:策略初始化(Policy Initialization)、奖励设计(Reward Design)、搜索(Search)和学习(Learning)。
策略初始化:帮助模型发展出类似人类的推理能力,使其能够有效探索复杂问题的解空间。
奖励设计:通过奖励塑形(reward shaping)或奖励建模(reward modeling)提供密集且有效的反馈信号,为搜索和学习过程提供明确的指导。
搜索:在训练和测试阶段生成高质量的解决方案,计算资源的增加有助于获得更优的结果。
学习:基于搜索过程中生成的数据不断优化策略,更多的模型参数和搜索数据可以进一步提升模型性能。
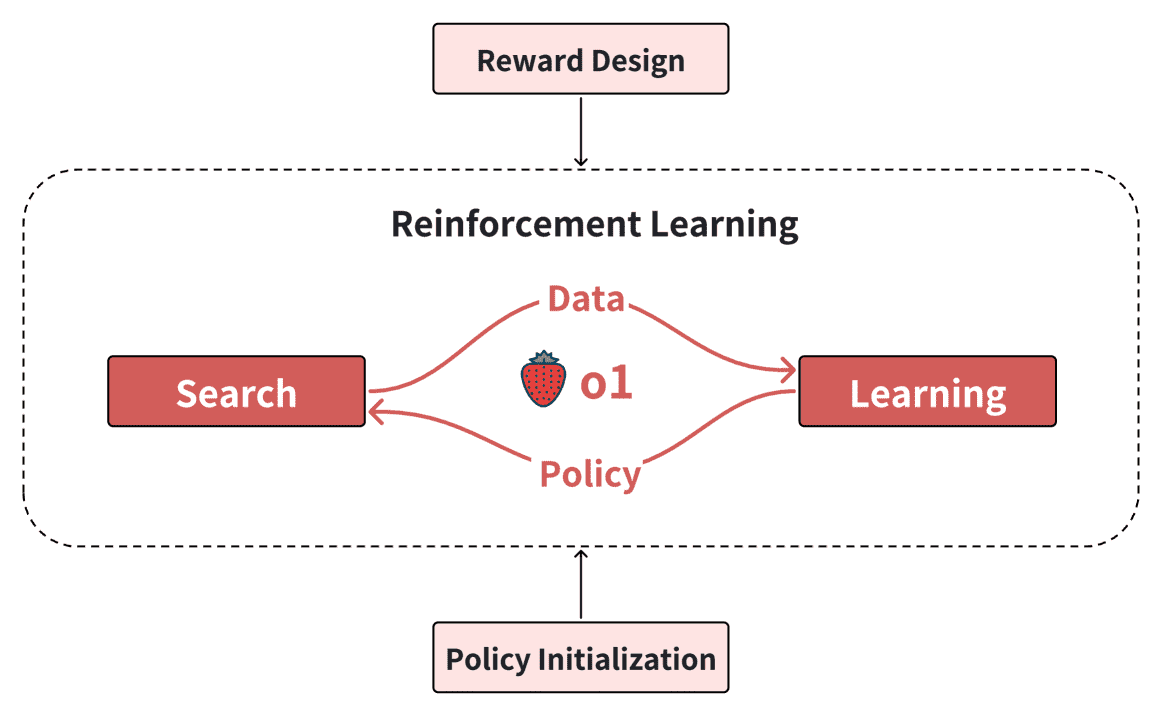
Figure 1:The overview of this roadmap including policy initialization, reward design, search and learning.¶
FromGPT¶
AI的范式转变¶
- o1的成功预示着AI领域可能会经历两次范式转变:
从“自监督学习”向“强化学习”的转变;
从单纯扩展训练计算能力,转向同时扩展训练和推理计算能力。
1. Introduction¶
Policy Initialization¶
在这个阶段,模型通过从大量互联网数据中进行预训练,获得了一个强大的初始策略,使其能够生成流畅的语言输出。
通过提示工程(Prompt Engineering)和监督微调,模型能够获得人类推理行为,比如任务组合、自我评估和自我修正。
由于LLMs的动作空间非常大,直接从零开始训练一个LLM是非常困难的。因此,可以通过预训练和提示工程来初始化一个强大的策略模型,使其具备类似人类的推理能力。
Reward Design¶
奖励信号是指导强化学习过程的重要部分。奖励设计的目标是为搜索和学习过程提供有效的信号。通过奖励塑形(Reward Shaping)和使用偏好数据(如用户反馈)来设计奖励模型,强化学习能够提高任务解决能力。
奖励信号可以是稀疏的,甚至在某些环境中不存在。为了将稀疏的结果奖励转化为密集的过程奖励,可以使用奖励塑形(reward shaping)方法。在没有奖励信号的环境中(如故事写作),可以从偏好数据或专家数据中学习奖励模型。
Both search and learning require guidance from reward signals to improve the policy.
相关论文
Scaling laws for reward model overoptimization: https://proceedings.mlr.press/v202/gao23h.html
Training a helpful and harmless assistant with reinforcement learning from human feedback: https://arxiv.org/abs/2204.05862
Algorithms for inverse reinforcement learning:
Search¶
- 搜索过程在模型训练和推理/测试阶段都起着至关重要的作用。
训练阶段的搜索用于生成高质量的训练数据
推理/测试阶段的搜索则能够改进模型的 次优策略
比如,AlphaGo使用蒙特卡洛树搜索(MCTS)来提升其性能。
注意:扩展测试时的搜索可能会导致分布偏移问题。
次优策略(Suboptimal Policy)指的是尚未达到最优但已经具有一定效果的策略。它在性能上可能接近最优策略,但仍存在可以改进的空间。
- 更详细解释
搜索指的是在给定的环境或问题空间中寻找最优或次优解的过程。
- 训练阶段的搜索
通过搜索来生成更高质量的训练数据。
搜索的目的是通过探索更广泛的解决方案空间来发现可能的最佳解,从而生成有价值的数据用于后续的学习。
举个例子,AlphaGo在进行训练时,利用蒙特卡洛树搜索(MCTS)来探索围棋棋盘上的最佳走法,从而生成更多有用的训练数据,提高其性能。
- 推理阶段的搜索
模型已经学到了基本的规则和模式,但是它可能会遇到一些不确定或复杂的情况,这时就需要进行推理搜索来改进其决策。
搜索能够帮助模型在推理过程中找到更好的解决方案,而不仅仅是依赖已有的策略。
总的来说,搜索是通过探索和评估多个可能的解决方案,找到最适合的解决方式,无论是在训练还是推理过程中。
Learning¶
强化学习的优势在于它不需要昂贵的数据标注。
模型通过与环境的交互进行学习,而不是依赖人工标注的数据,从而降低了成本并且有可能实现超人类的表现。
策略梯度方法(policy gradient)和行为克隆(behavior cloning)是两种常用的学习方法。
2. Background¶
强化学习(RL)是一种通过与环境互动来学习的方式,而不是像传统的监督学习那样从静态的训练数据集中学习。在强化学习中,代理(Agent)通过在环境中探索和做决策来获得反馈。每次代理采取行动后,环境会返回一个奖励(Reward),并给出一个新的状态,代理利用这些反馈来调整其策略。
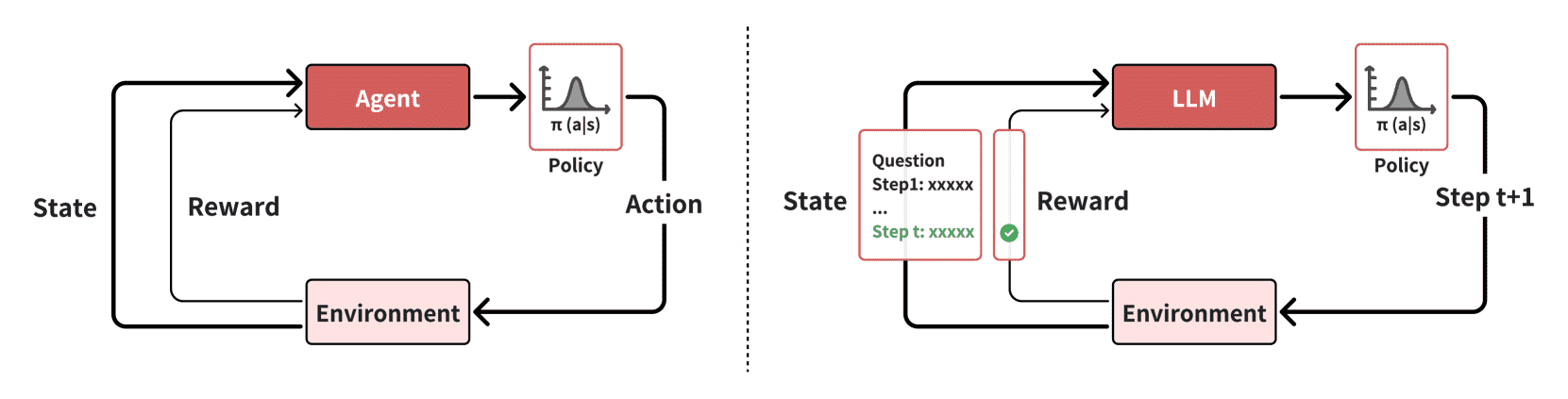
Figure 3:The visualization of the interaction between agent and einvironment in reinforcement learning for LLMs. Left: traditional reinforcement learning. Right: reinforcement learning for LLMs. The figure only visualizes the step-level action for simplicity. In fact, the action of LLM can be either token-, step-, or solution-level.¶
代理(Agent)¶
在强化学习中,代理是与环境互动并做出决策的实体。它根据 策略(Policy) 来决定自己的行动。
策略(Policy) 是一个从 状态(State)到行动(Action) 的映射,通常表示为在给定状态下采取某个行动的概率分布。代理会根据这个概率分布选择行动。
- 在LLM的背景下,代理指的就是LLM本身。LLM的策略决定了在给定当前状态时,它会选择哪个动作(例如生成一个新的token(token-level),完成一个推理步骤(step-level),或者给出一个解决方案(solution-level))。具体来说:
状态(State) 指的是在时间步t时,LLM的输入,包括用户输入和模型的前面输出。
动作(Action) 可以是生成一个单独的token、完成某个推理步骤,或者提供一个完整的解决方案。
环境(Environment)¶
环境是代理所做出决策的外部系统或世界。
- 环境会对代理的行动作出反馈,这些反馈包括:
新的状态(sₜ₊₁):表示在代理采取了某个动作后,环境的变化。
奖励(r(sₜ, aₜ)):表示代理所采取的行动的好坏,通常是一个数值,表示代理执行某个动作后的效果好坏。
- 环境的反馈有两种类型:
- 确定性反馈(Deterministic feedback)
在这种情况下,环境对每个行动的反馈是确定的,也就是说,给定相同的状态和行动,环境会产生相同的结果。
例如,当LLM解决一个数学问题时,当前的状态和行动组合后会产生一个确定的下一状态和奖励。
- 随机反馈(Stochastic feedback)
这种情况下,环境的反馈具有不确定性。
例如,在对话模型中,用户的回答是随机的,因此,用户的回答可能会有所不同。
这种不确定性通过 转移分布(Transition distribution) 来描述,它定义了在给定状态和行动的情况下,下一状态和奖励的概率分布。
通过不断与环境互动,LLM可以在动态的反馈环境中优化自己的策略,从而提升解决问题的能力。
3. Policy Initialization¶
- 策略(Policy)的定义与粒度
策略(Policy) 决定了代理(Agent)如何根据环境的状态来选择行动。
- LLM的策略有三个不同的粒度级别:
Solution-level actions:最粗粒度的动作,将整个解决方案视为一个动作。
Step-level actions:中等粒度的动作,每个步骤作为一个离散的动作。
Token-level actions:最细粒度的动作,每个token(词元)作为一个动作。
- LLM的策略初始化包括两个关键阶段:
预训练(Pre-training):模型通过自监督学习,在大量文本语料库中学习基本的语言理解和生成能力。
指令微调(Instruction Fine-Tuning):通过基于指令-回应对的训练,使模型从单纯的下一token预测转变为生成符合人类需求的回应。
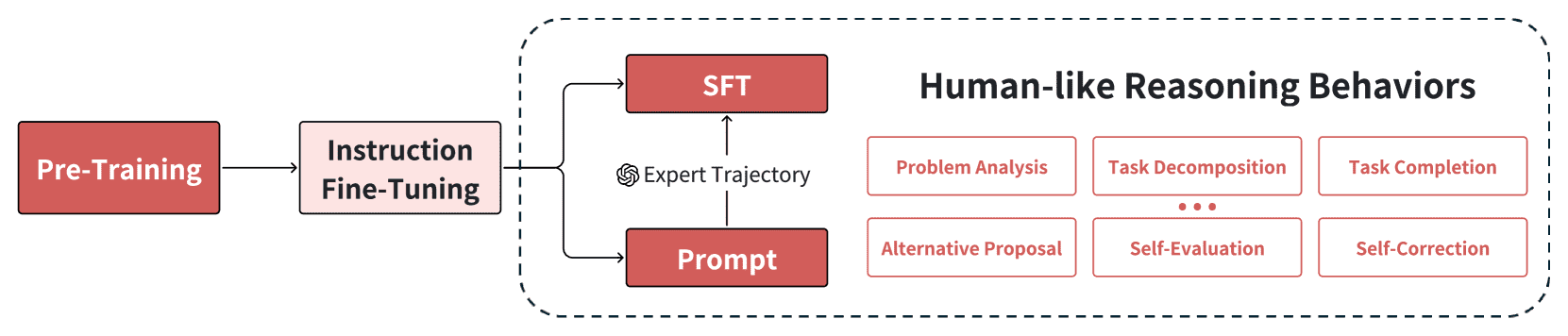
Figure 4:The process of policy initialization, including pre-training, instruction fine-tuning, and the injection of human-like reasoning behaviors. These behaviors can be learned through SFT or triggered by prompts.¶
3.1 Pre-Training¶
语言理解与生成: 模型通过暴露于大量自然语言数据中,学习语法结构、上下文理解、多语言能力等。
世界知识获取与存储: 通过海量的语料,模型学会了从事实到概念、程序到数学的广泛知识。
基础推理能力: 通过推理模式,模型能够逐步从简单的推理到复杂的推理,例如逻辑推理、代码分析等。
3.2 Instruction Fine-Tuning¶
- 指令微调的目的是使LLM能够从“纯粹的token预测”转向“目标明确的任务行为”。
数据多样性: 微调效果与训练数据集的多样性密切相关。例如,拥有多样任务的指令数据集能让模型更好地泛化到不同的任务上。
高质量的指令-响应对: 训练数据中指令与回应的质量决定了微调的效果。模型经过高质量的数据训练,可以更好地完成新任务。
这一阶段的目标是让模型具备任务导向的行为,使得模型能够根据给定的指令合理地生成回应。
3.3 Human-like Reasoning Behaviours¶

Table 1:Exemplars of Human-like Reasoning Behaviors from o1 blog (OpenAI, 2024a)¶
LLM不仅要在语法和知识上表现出色,还需要具备“人类般的推理能力”。
- 六种类似人类的推理行为
问题分析(Problem Analysis):模型在解题之前先分析和重述问题,确认理解是否正确。
任务分解(Task Decomposition):将复杂任务分解为多个子任务,从而更容易逐步解决问题。
任务完成(Task Completion):基于分析和分解的步骤,逐步完成任务,生成解决方案。
替代提案(Alternative Proposal):在遇到难题或瓶颈时,能够提出多个解决方案。
自我评估(Self-Evaluation):完成任务后,模型对自己生成的答案进行验证。
自我修正(Self-Correction):在出现错误时,能够发现问题并进行修正。
这些推理行为使得LLM能够更灵活、精确地处理复杂的任务,提升了模型的智能水平。
3.4 Speculation About the Policy Initialization of o1¶
Long-Text Generation Capabilities: LLMs需要生成大量令牌以涵盖复杂和多样化的推理行为,这需要复杂的长篇文化建模功能。
Shaping Human-like Reasoning Behaviors Logically: 以逻辑上连贯的方式来协调类似人类的推理行为的能力。这种编排需要复杂的决策;例如,当自我评估确定错误时,该模型必须战略性地确定是进行自我纠正还是探索替代解决方案。
Self-Reflection: 自我评估,自我纠正和替代建议等行为确定为模型自我反省能力的表现。自我反思解决了自回归模型的基本局限性:无法修改先前生成的内容
3.5 Challenges of Policy Initialization for Reproducing o1¶
采样效率与多样性的平衡:在初始化时,模型需要平衡有效的样本采样与足够的多样性。过于固定的策略会限制探索空间,影响模型的学习能力。
推理行为的领域泛化:当前研究通常集中在特定领域(如数学或编程)中实现人类推理行为。然而,推理行为应具备跨领域的泛化能力,以便能够在不同任务中发挥作用。因此,设计具有广泛适用性的推理行为成为一个挑战。
4. Reward Design¶
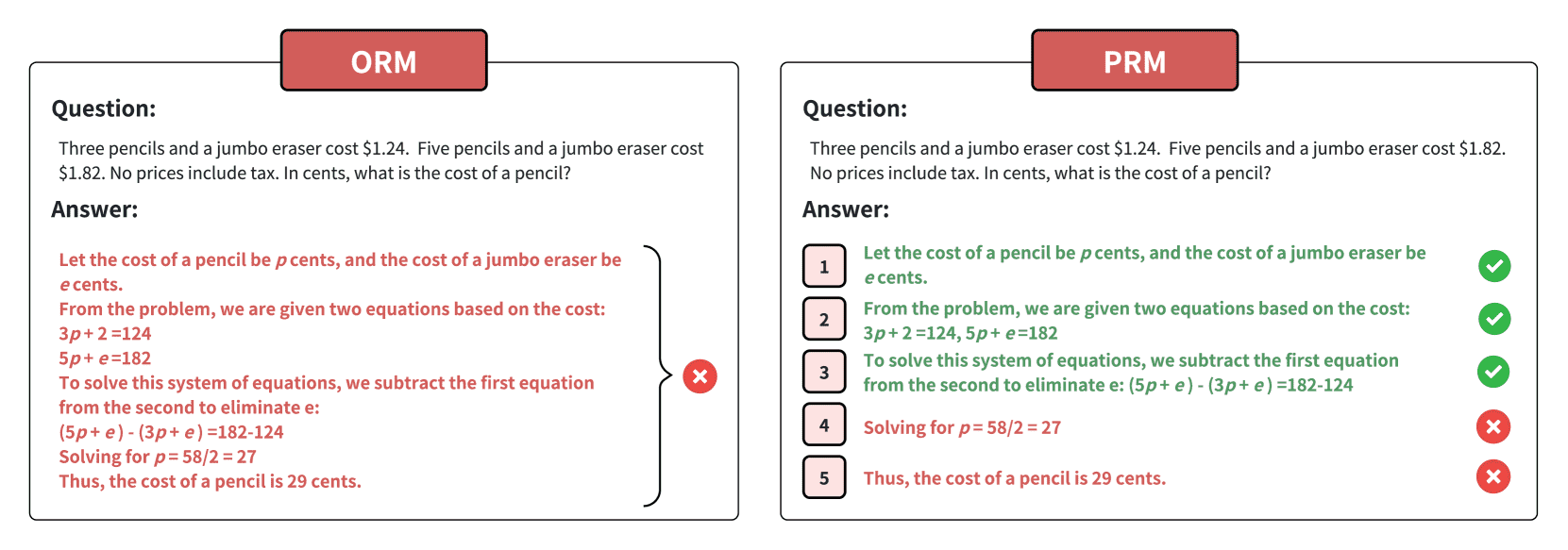
Figure 5:Outcome reward vs Process reward. The figure shows two different types of reward: outcome reward (left) and process reward (right). The entire solution is incorrect due to the penultimate line. Therefore, for outcome rewards, the whole solution is marked as incorrect, while for process reward, the previous three steps are marked as correct and the last two steps as incorrect.¶
强化学习中的代理通过奖励信号获取反馈,并试图通过改进策略来最大化长期奖励。
奖励函数 \(r(s_t, a_t)\) 表示在某个时刻,代理在状态 \(s_t\) 下采取动作 \(a_t\) 时所获得的奖励。
这些奖励信号在训练和推理过程中至关重要,因为它们定义了代理的期望行为,并通过数值评分来指导学习。
4.1 Outcome Reward vs Process Reward¶
Outcome Reward(结果奖励):这种奖励基于最终结果来评估模型的表现。例如,数学问题的解答是否正确。其优点是简单,但缺点是没有对中间步骤提供反馈,可能导致模型在生成过程中出现错误步骤。
Process Reward(过程奖励):与结果奖励不同,过程奖励不仅对最终结果进行评分,还对中间步骤给予奖励。这使得模型能够通过奖励中间步骤来改进自己的行为,通常用于长链推理的任务(例如数学或代码生成),能够帮助模型学习每一步的优化。
过程奖励的设计通常更复杂,尤其是在没有现成的奖励信号时。比如,有些任务可能没有标准的“正确答案”,而只能通过逐步的反馈(如人工标注)来给予奖励。
4.2 Reward Design Methods¶
4.2.1 Reward from Environment¶
从环境中获取奖励(Reward from Environment)
最直接的方法是从实际环境中获取奖励信号,或通过模拟器模拟奖励信号。
例如,编程任务可以通过编译器或测试用例来提供反馈。
From Realistic Environment
From Simulating Environment
From AI Judgment
4.2.2 Reward Modeling from Data¶
从数据中学习奖励(Reward Modeling from Data)
如果无法从环境中直接获取奖励,可以通过从专家数据或偏好数据中学习奖励模型。
例如,使用人类的偏好数据来对模型的输出进行评分,这种方法在强化学习中的人类反馈(RLHF)中得到广泛应用。
Learning Rewards from Preference Data
Learning Rewards from Expert Data
4.2.3 Reward Shaping¶
- 奖励塑形(Reward Shaping)
是一种优化奖励信号的技术,旨在提高学习效率和模型性能。
某些环境中的原始奖励信号可能不够有效,例如仅提供结果奖励(outcome-based rewards)而缺乏过程奖励(process-based rewards),这可能导致模型难以获得足够的反馈来指导学习。
在这种情况下,可以对奖励进行重塑,使其更加密集且富有信息,从而增强模型的学习能力。
在训练大型语言模型(LLM)时,使用强化学习(RL)进行自我纠正(self-correction),并发现适当的奖励塑形方法,能够有效防止模型学习过程中的崩溃。
需要注意的是,由于 价值函数(value function) 依赖于特定策略 π,针对某个策略估算的价值函数可能无法作为另一个策略的有效奖励信号。这意味着在不同策略之间迁移奖励信号时,需要特别关注其适用性。
4.3 Speculation About the Reward Design of o1¶
鉴于 O1 可以处理多任务推理,因此其奖励模型可能会结合多种奖励设计方法。
对于复杂的推理任务(例如数学和代码),响应通常涉及较长的推理链,仅仅依据最终结果给予奖励可能不足以有效地训练或评估系统(如o1)
对于这类任务,可能会更倾向于使用能够监督中间过程的奖励模型,即过程奖励模型,而不是单纯基于ORM
ORM, Outcome Reward Model(结果奖励模型)主要侧重于根据任务的结果来给予奖励。
诸如 奖励塑形 之类的技术可以帮助从结果奖励中获得过程奖励,从而更好地指导和优化整个推理过程。
4.4 Challenges of Reward Design for Reproducing o1¶
分布偏移(Distribution Shift): 奖励模型可能在训练过程中出现“分布偏移”,即当策略更新时,原有的奖励模型可能无法适应新策略。因此,奖励模型需要与策略更新同步。
复杂任务的奖励建模: 随着任务的复杂性增加,如何为语言模型选择合适的奖励信号变得更具挑战性。尤其是,当任务的目标不容易量化时(例如,生成的代码是否正确),如何判断和建模奖励信号成为了关键问题。
4.5 Generalization(泛化能力)¶
构建一个通用奖励信号,可以将其分为两个组成部分: 奖励组合(Reward Ensemble) 和 世界模型(World Model)
这一节关注如何为更通用的任务设计奖励模型,以支持智能体在现实世界环境中解决实际问题。
奖励组合(Reward Ensemble)¶
核心思想:在处理通用任务时,可以将多个特定领域的奖励信号进行组合,形成一个综合的奖励模型。这种方法类似于专家模型(Mixture of Experts, MoE),每个“专家”针对不同的任务训练,提供对应的奖励信号,最终将这些输出聚合在一起。
- 关键研究:
Quan (2024): 采用MoE方法训练奖励模型,每个专家负责不同任务,最后通过聚合输出形成综合奖励。
Nguyen et al. (2024): 将奖励模型选择问题视为 多臂赌博机(multi-armed bandit) 问题,旨在学习如何选择最合适的奖励模型。
核心问题:如何有效地组合不同的奖励信号? 这是奖励组合方法的关键挑战,涉及到如何权衡不同任务之间的奖励贡献。
世界模型(World Model)¶
核心思想:世界模型不仅能提供奖励信号,还可以预测环境的下一个状态。传统上,世界模型用于模拟环境,以帮助智能体在模拟中学习。
- 关键研究与方法:
视频生成器(Video Generator):一些研究认为视频生成器可以作为世界模型,因为它能预测未来时间步骤的图像(即未来状态)。
状态表示预测(Representation Prediction):认为世界模型不需要直接预测下一个状态本身,而是预测其表示(representation),这比直接预测图像更简单高效。
- 挑战与前景:
当前的研究大多关注预测下一个状态,但作者认为建模奖励信号本身同样重要且具有挑战性。
观点:对于智能体在真实环境中成功完成任务,除了预测状态,准确建模奖励信号也是至关重要的。
总结¶
奖励组合方法通过集成不同领域的奖励模型,增强了泛化能力,但面临如何有效组合的挑战。
世界模型不仅能预测环境变化,还能辅助奖励信号建模,且从直接预测状态到预测状态表示的发展提高了效率。
作者强调,未来在实现更强大的AGI时,奖励信号的建模将是不可忽视的重要方向。
5. Search¶
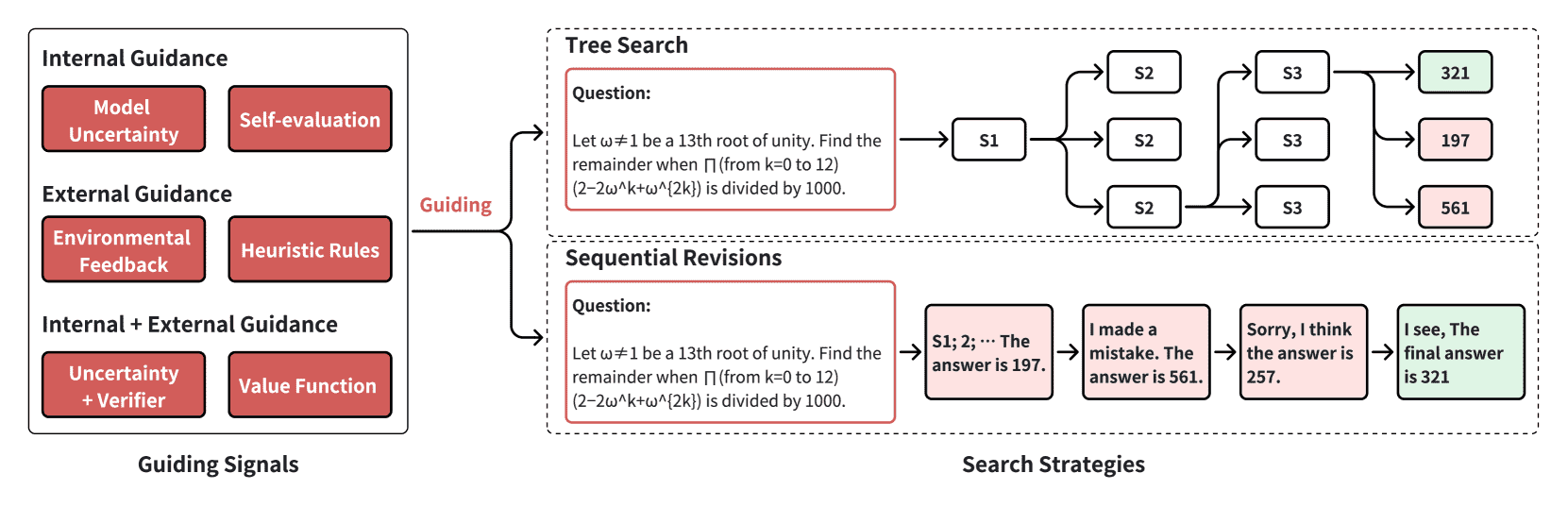
Figure 6:The two key aspects of search are the guiding signals for solutions selection and the search strategies to get candidate solutions. We divide the guidance used during the search process into two types: internal guidance and external guidance. We also divide search strategies into two types: tree search and sequential revisions. Search strategies are used to obtain candidate solutions or actions, while guiding signals are used to make selections on candidate solutions or actions. S1 means step 1.¶
- 随机采样与搜索的区别
随机采样(Random Sampling):大语言模型生成文本时常用的方法,比如核采样(Nucleus Sampling)。它通过随机选择概率较高的词,增强输出的多样性和质量。
- 搜索(Search):不仅仅是随机尝试,更像是一种有策略的探索。搜索方法基于一定的指导信号(guiding signals),通过多次尝试找到更优解。
常见的搜索方法包括:
Self-Consistency(自洽性):生成多个答案,选择最一致的结果。
Best-of-N(BoN):生成N个答案,选出最好的。
5.1 The role of Search in o1¶
- 搜索在 o1 模型中的作用分为两个阶段:
- 训练阶段的搜索(Training-Time Search)
类似于 强化学习(Reinforcement Learning) 的试错过程,模型在探索中学习高奖励的解决方案。
由于 o1 需要处理复杂推理任务,搜索空间非常大,简单的随机采样效率低,因此需要更高级的搜索策略来快速找到优质解答。
这些优质解答可以作为新的训练数据,帮助模型不断优化。
- 推理阶段的搜索(Test-Time Search)
在推理阶段,增加计算资源和推理时间可以提高模型性能。o1 在推理时会 “思考更久” ,这本质上是一种搜索行为,帮助模型找到更好的答案。
例如,模型可以生成多个候选答案,通过筛选机制选择最优答案。
- 搜索的核心要素
搜索由两个关键部分组成:
- 指导信号(Guiding Signals):帮助模型判断哪些答案更好,分为:
内部指导信号:模型自身的概率分布、损失函数等。
外部指导信号:外部的奖励信号或人类反馈等。
- 搜索策略(Search Strategies):具体如何探索解答空间,主要包括:
树搜索(Tree Search):像下棋一样,逐步扩展可能的解答路径。
序列修正(Sequential Revisions):生成初步答案后,进行多轮修改和优化。
注: 这两种分类方法是正交的,比如树搜索既可以依赖内部信号,也可以依赖外部信号。
- 总结
搜索比随机采样更有效,特别适合解决复杂推理任务。
在 o1 中,搜索不仅帮助模型更好地训练(获得高质量数据),也提高了推理阶段的输出质量。
搜索的效果依赖于好的指导信号和搜索策略,这两者相辅相成。
5.2 Search Guidance¶
搜索指导指的是在模型生成或推理过程中,提供信息来帮助模型找到更优解的信号。这些信号可以来自模型内部(比如模型不确定性)或外部(比如奖励信号)。
5.2.1 Internal Guidance¶
内部指导完全依赖模型自身的状态或能力,不需要外部环境或额外的模型反馈。
- 常见方法包括:
- ✅ 模型不确定性(Model Uncertainty)
概念:模型在某个输出上的不确定程度,通常用来帮助筛选出更可靠的答案。
- 应用示例:
自洽性(Self-Consistency):生成多个答案,通过多数投票或加权平均,选择不确定性最低的答案。
语义不确定性(Semantic Uncertainty):关注语义层面的差异而非句法差异。比如,使用自然语言推理(NLI)模型将具有双向蕴含关系的句子视为等价,再通过语义分布的熵来衡量不确定性。
幻觉检测(Hallucination Detection):利用语义熵来识别模型生成的幻觉内容。
优点:无需外部监督,易于获取。
缺点:依赖模型的校准程度(Calibration),如果模型校准不好,不确定性指标的可靠性会降低。
- ✅ 自我评估(Self-Evaluation)
概念:让模型对自己的输出进行评价,基于“评估比生成更简单”的假设(即生成器-判别器差距(DG-gap))。
- 关键应用:
基于人类反馈的强化学习(RLHF):通过人类偏好来指导模型学习,而不是直接标注正确答案。
LLM-as-a-Judge:大语言模型充当评判者,评估自己生成的内容,效果接近人类评估者。
LLM-as-a-Meta-Judge:更高级的自我评估方法,进一步提升评估能力。
挑战:模型可能无法在没有外部反馈的情况下准确评估自身输出。解决方案包括扩大模型规模、专门训练自我评估能力,或引入更详细的评估标准。
5.2.2 External Guidance¶
外部指导依赖于模型外部的环境反馈或任务相关信号
- 常见形式包括:
- 🌍 环境反馈(Environmental Feedback)
概念:使用来自任务环境的反馈信号,如奖励函数,来指导搜索。
- 应用示例:
奖励信号(Reward Signals):常用于强化学习,指导模型朝着更高奖励的方向调整输出。
多尺度奖励(Multi-Scale Rewards):不仅关注最终结果的奖励,还考虑中间步骤的奖励(如数学推理中的中间计算正确性)。
代理反馈(Proxy Feedback):如代码编译结果、单元测试结果,作为模型输出的质量指标。
- 挑战:
构建环境和设计奖励函数需要大量计算资源。
代理反馈可能存在分布偏移(Out-of-Distribution, OOD)问题,导致模型性能下降。
- 🌍 启发式规则(Heuristic Rules)
概念:基于任务特定的知识或经验制定的规则,帮助模型更高效地搜索解答空间。
- 应用示例:
贪婪搜索(Greedy Search)、A*搜索:常见的启发式搜索算法,依靠启发式函数指导决策。
任务特定启发式(Task-Specific Heuristics):增强模型推理能力,如在数学题推理中加入特定的逻辑规则。
优势:当环境反馈不可用或成本较高时,启发式规则是一种有效的替代方案。
5.2.3 Comparison of Internal and External Guidance¶
- Internal Guidance
依赖性: 依赖模型内部状态,无需外部环境或真实标签。
泛化能力: 高度可迁移,适用于各种任务,尤其在缺乏明确评估标准时。
计算成本: 成本较低,主要依赖模型自身推理。
推理阶段的适用性: 非常适合推理阶段,无需与外界频繁交互。
- External Guidance
依赖性: 依赖外部任务环境、奖励信号或真实标签。
泛化能力: 与具体任务强相关,效果更贴合模型性能,但泛化能力较弱。
计算成本: 成本较高,尤其是在需要与复杂环境交互或使用代理模型时。
推理阶段的适用性: 推理阶段成本较高,可能面临OOD问题。
5.2.4 Combination of Internal and External Guidance¶
- 结合内外部指导可以发挥各自优势,提升搜索效果。常见的结合方式包括:
模型不确定性 + 奖励模型反馈:同时考虑模型自身的不确定性和代理模型的反馈,选择质量更高的答案。
- 价值函数(Value Function):在强化学习中,价值函数(如V函数和Q函数)结合了环境奖励和模型内部状态,帮助模型选择能够最大化长期收益的行动。
DPO(Direct Preference Optimization):一种逆Q学习算法,DPO模型的logits可以看作Q函数,指导基于价值函数的搜索。
价值头(Value Head):将价值函数集成到策略模型中,共享大规模的模型骨干。
挑战:价值函数的准确性至关重要,特别是在奖励稀疏或输出维度高的任务中,估计误差会显著影响性能。
总结¶
内部指导依赖模型自身,适用于泛化性强、缺乏外部反馈的场景。
外部指导基于环境反馈或代理模型,能更好地对齐模型性能,但成本较高。
结合内外部指导可以提高搜索效率和输出质量,尤其在复杂推理任务中。
核心挑战包括模型校准、环境反馈的设计、以及价值函数的准确性。
5.3 Search Strategies¶
两种主要的搜索策略:树搜索(Tree Search)和顺序修正(Sequential Revisions)
- 树搜索(Tree Search):
特点:同时生成多个候选答案,类似于全局搜索,适合探索广泛的解空间。
优点:能够覆盖更多解,促进探索,适合并行处理。
缺点:计算开销较大,可能存在效率问题。
- 顺序修正(Sequential Revisions):
特点:基于先前答案进行迭代改进,类似于局部搜索,关注精细化优化。
优点:在已有基础上逐步改进,可能更高效,适合复杂推理任务。
缺点:依赖于初始答案质量,计算成本随着修正次数增加。
5.3.1 Tree Search¶
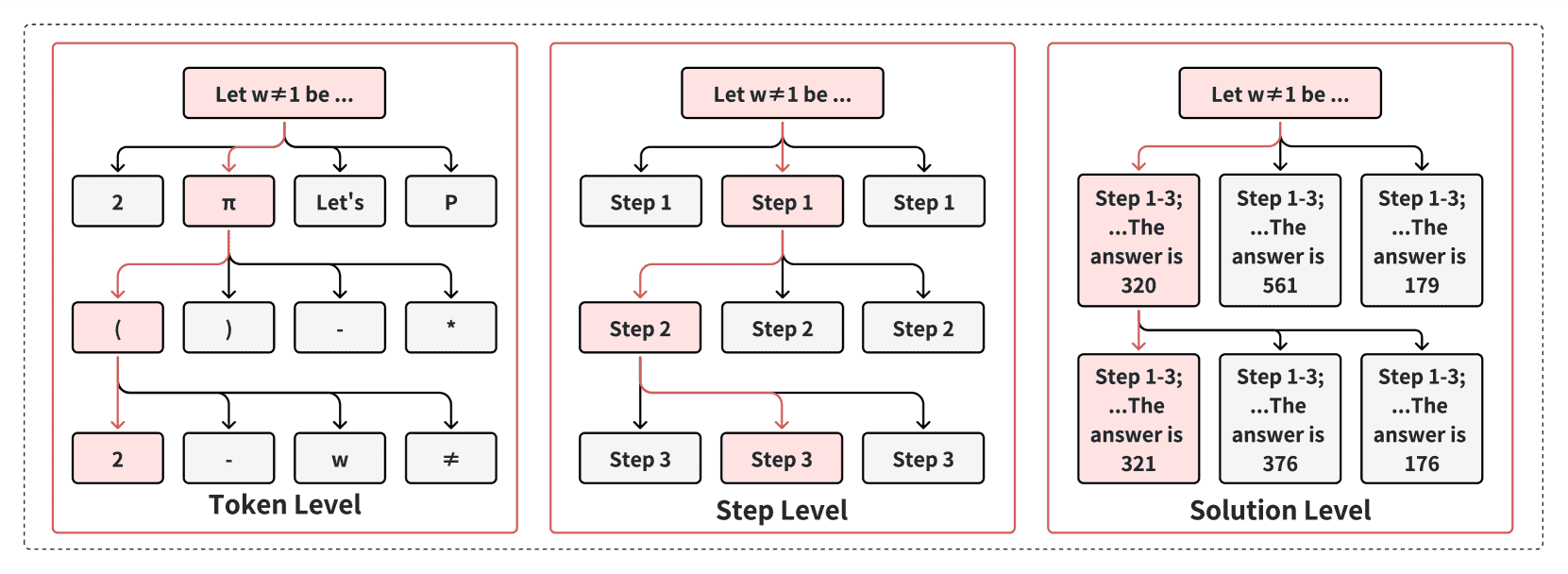
Figure 7:Definitions of search tree nodes at different granularities. The token level represents the finest granularity, while the solution level represents the coarsest granularity.¶
- 2.1 Best-of-N Sampling (BoN)
原理:生成 N 个独立候选答案,通过奖励模型选出最佳答案。
- 问题:
高计算成本:需要多次采样。
低效率:无法动态调整模型分布,容易过度采样高概率选项。
- 改进方法:
Speculative Rejection:提前丢弃低分答案,减少计算量。
BOND 和 vBoN:通过模型微调,模拟 BoN 的分布,减少采样次数。
- 2.2 Beam Search(束搜索)
原理:保留概率最高的若干条路径,逐步扩展并修剪低质量候选。
- 改进方法:
Reward-guided Beam Search:使用奖励信号替代简单的概率评分,提升与任务的匹配度。
TreeBoN、DPO 等方法:结合奖励模型、回溯机制等,平衡探索与利用。
- 2.3 Monte Carlo Tree Search (MCTS)
原理:基于蒙特卡罗模拟,使用多次随机模拟来评估各个候选路径的潜在价值。
- 四个核心步骤:
选择(Selection):基于价值选择路径,鼓励探索未充分访问的节点。
扩展(Expansion):在非终止节点展开新的子节点。
评估(Evaluation):使用滚动预测(rollout)或价值模型评估当前状态。
反向传播(Backpropagation):将评估结果反馈至路径上的所有节点,更新价值估计。
- 关键差异:
粒度(Granularity):可以在Token 级、Step 级或Solution 级操作。
Token 级:更精细,但树深度大,计算复杂。
Step 级:适用于推理任务,平衡树的宽度与深度。
Solution 级:每个节点代表完整解,适合自我改进场景。
5.3.2 Sequential Revisions¶
5.3.3 Comparison of Tree Search and Sequential Revisions¶
5.4 Speculation About the Search of o1¶
5.5 Scaling Law of Search¶
5.6 Challenges of Search for Reproducing o1¶
6. Learning¶
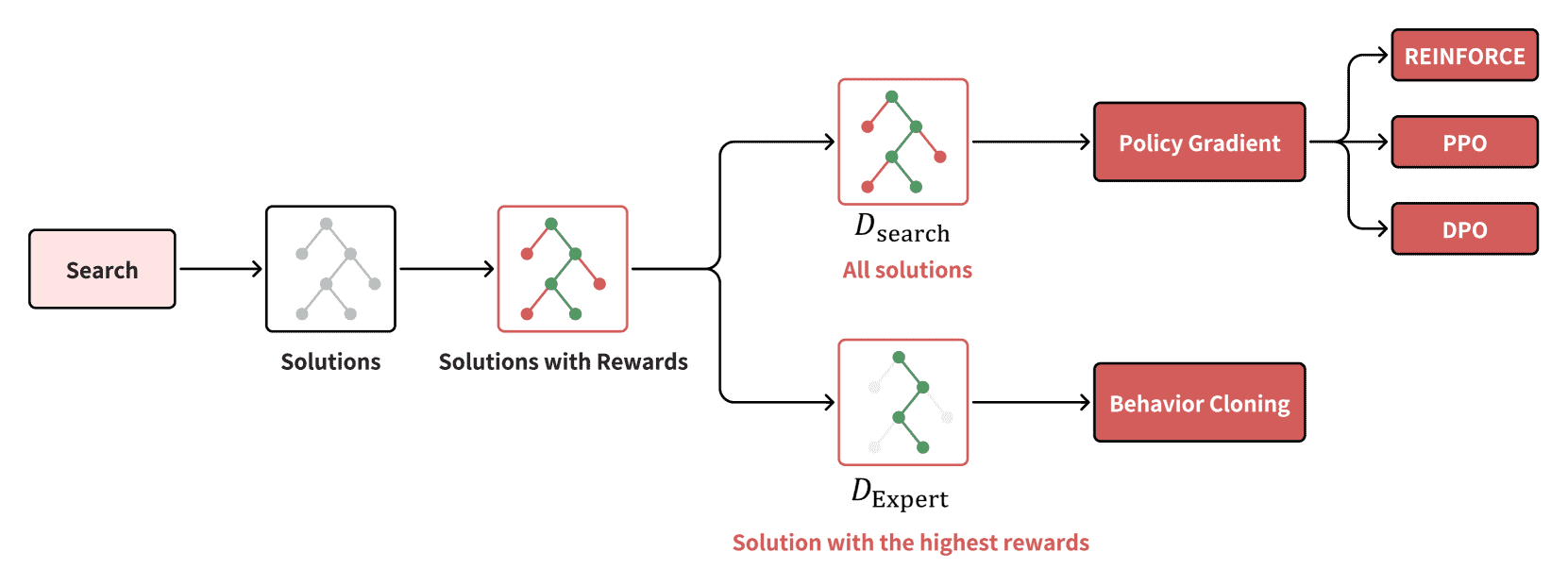
Figure 8:The difference of 4 learning methods, in terms of the data they use. Policy gradient use \(D_{search}\) which contains all searched solutions, while behavior cloning only utilizes \(D_{expert}\) , the solutions with the highest rewards. We distinguish the solution with the highest reward from the other solutions by using different colors: green for the highest reward and red for the others.¶