Prefix-Tuning: Optimizing Continuous Prompts for Generation¶
组织: 斯坦福大学
微调是利用大型预训练语言模型执行下游任务的实际方式。但是,它会修改所有语言模型参数,因此需要为每个任务存储一个完整的副本。在本文中,我们提出了前缀调整,这是一种自然语言生成任务微调的轻量级替代方案,它保持语言模型参数冻结,但优化了一个小的连续任务特定向量(称为前缀)。前缀调整从 prompting 中汲取灵感,允许 subsequent tokens 像 “virtual tokens” 一样关注此 prefix。我们将前缀调整应用于 GPT-2 的 table-to-text 生成,并应用于 BART 以进行摘要。我们发现,通过仅学习 0.1% 的参数,前缀调整在完整数据设置中获得了相当的性能,在低数据设置下优于微调,并且可以更好地推断出训练过程中看不到的主题的示例。
Fine-tuning is the de facto way to leverage large pretrained language models to perform downstream tasks. However, it modifies all the language model parameters and therefore necessitates storing a full copy for each task. In this paper, we propose prefix-tuning, a lightweight alternative to fine-tuning for natural language generation tasks, which keeps language model parameters frozen, but optimizes a small continuous task-specific vector (called the prefix). Prefix-tuning draws inspiration from prompting, allowing subsequent tokens to attend to this prefix as if it were “virtual tokens”. We apply prefix-tuning to GPT-2 for table-to-text generation and to BART for summarization. We find that by learning only 0.1% of the parameters, prefix-tuning obtains comparable performance in the full data setting, outperforms fine-tuning in low-data settings, and extrapolates better to examples with topics unseen during training.
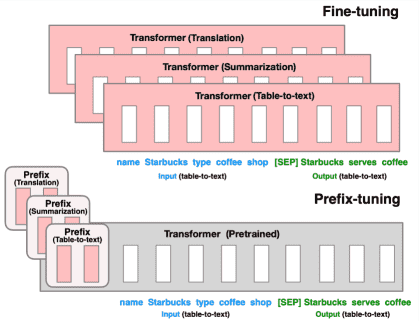
Figure 1: Fine-tuning (top) updates all Transformer parameters (the red Transformer box) and requires storing a full model copy for each task. We propose prefix-tuning (bottom), which freezes the Transformer parameters and only optimizes the prefix (the red prefix blocks). Consequently, we only need to store the prefix for each task, making prefix-tuning modular and space-efficient. Note that each vertical block denote transformer activations at one time step.微调(顶部)会更新所有 Transformer 参数(红色的 Transformer 框),并且需要为每个任务存储一个完整的模型副本。我们提出了前缀调整(底部),它冻结了 Transformer 参数,只优化前缀(红色前缀块)。因此,我们只需要为每个任务存储前缀,使前缀调整模块化且节省空间。请注意,每个垂直块表示一个时间步的变压器激活。¶