LoRA: Low-Rank Adaptation of Large Language Models¶
组织: Microsoft
NLP 的一个重要范例(paradigm)包括对一般领域数据的大规模预训练和对特定任务或领域的适应。随着我们对较大的模型进行预训练,重新训练所有模型参数的完全微调变得不太可行。以 GPT-3 175B 为例——部署微调模型的独立实例,每个实例都有 175B 参数,成本高得令人望而却步。我们提出了 Low-Rank Adaptation,或 LoRA,它冻结了预训练的模型权重,并将可训练的等级分解矩阵注入到 Transformer 架构的每一层中,大大减少了下游任务的可训练参数的数量。与使用 Adam 微调的 GPT-3 175B 相比,LoRA 可以将可训练参数的数量减少 10,000 倍,将 GPU 内存需求减少 3 倍。LoRA 在 RoBERTa、DeBERTa、GPT-2 和 GPT-3 上的模型质量表现与微调相当或更好,尽管可训练参数较少,训练吞吐量更高,并且与适配器不同,没有额外的推理延迟。我们还对语言模型适应中的等级缺陷进行了实证调查,这阐明了 LoRA 的有效性。
An important paradigm of natural language processing consists of large-scale pre-training on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, full fine-tuning, which retrains all model parameters, becomes less feasible. Using GPT-3 175B as an example – deploying independent instances of fine-tuned models, each with 175B parameters, is prohibitively expensive. We propose Low-Rank Adaptation, or LoRA, which freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks. Compared to GPT-3 175B fine-tuned with Adam, LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times. LoRA performs on-par or better than fine-tuning in model quality on RoBERTa, DeBERTa, GPT-2, and GPT-3, despite having fewer trainable parameters, a higher training throughput, and, unlike adapters, no additional inference latency. We also provide an empirical investigation into rank-deficiency in language model adaptation, which sheds light on the efficacy of LoRA.
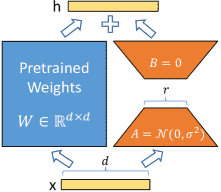
Figure 1:Our reparametrization. We only train A and B¶