p-tuning: GPT Understands, Too¶
组织: 清华大学 麻省理工学院
事实证明,使用自然语言模式提示预训练的语言模型对于自然语言理解 (NLU) 是有效的。然而,我们的初步研究表明,手动离散提示通常会导致性能不稳定——例如,更改提示中的单个单词可能会导致性能大幅下降。我们提出了一种新的方法 P-Tuning,该方法在与离散提示的串联中采用可训练的连续提示嵌入。从经验上讲,P-Tuning 不仅通过最小化各种离散提示之间的差距来稳定训练,而且还在包括 LAMA 和 SuperGLUE 在内的各种 NLU 任务上显著提高了性能。P-Tuning 通常对冻结和调整的语言模型都有效,在完全监督和少样本设置下都有效。
Prompting a pretrained language model with natural language patterns has been proved effective for natural language understanding (NLU). However, our preliminary study reveals that manual discrete prompts often lead to unstable performance – e.g., changing a single word in the prompt might result in substantial performance drop. We propose a novel method P-Tuning that employs trainable continuous prompt embeddings in concatenation with discrete prompts. Empirically, P-Tuning not only stabilizes training by minimizing the gap between various discrete prompts, but also improves performance by a sizeable margin on a wide range of NLU tasks including LAMA and SuperGLUE. P-Tuning is generally effective for both frozen and tuned language models, under both the fully-supervised and few-shot settings.
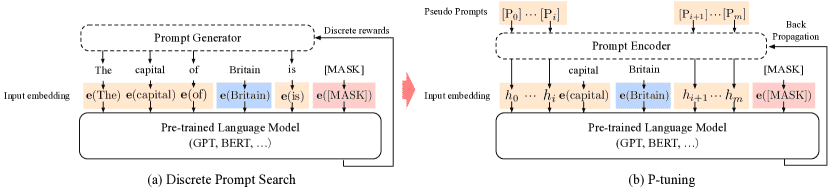
图 2:提示搜索 “The capital of Britain is [MASK]” 的示例。给定上下文(蓝色区域,“Britain”)和目标(红色区域,“[MASK]”),橙色区域是指提示。在 (a) 中,提示生成器只接收离散奖励;相反,在 (b) 中,连续提示嵌入和提示编码器可以以可微分的方式进行优化。Figure 2:An example of prompt search for “The capital of Britain is [MASK]”. Given the context (blue zone, “Britain”) and target (red zone, “[MASK]”), the orange zone refer to the prompt. In (a), the prompt generator only receives discrete rewards; on the contrary, in (b) the continuous prompt embeddings and prompt encoder can be optimized in a differentiable way.¶