2003.08934_NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis¶
组织: 1UC Berkeley 2Google Research 3UC San Diego
Keywords: scene representation, view synthesis, image-based rendering, volume rendering, 3D deep learning
Abstract¶
我们提出了一种新方法,只需少量照片,就能生成复杂场景的新视角图像,效果达到当前最先进水平。
方法用一个全连接神经网络来表示场景,输入是一个连续的5维坐标(3D位置 + 观察方向),输出是该位置的密度和视角相关的颜色。
我们通过沿相机射线查询这些坐标,并用体积渲染(volume rendering)技术把结果合成图像。
由于体积渲染(volume rendering)是可微的,只需输入带有相机位姿的图像,就能训练这个模型。
我们展示了这种神经辐射场优化方法在生成真实感图像上的强大能力,效果优于已有方法。
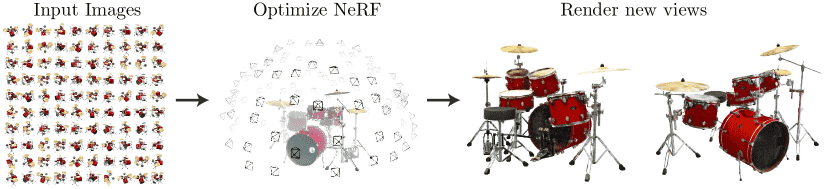
Figure 1:We present a method that optimizes a continuous 5D neural radiance field representation (volume density and view-dependent color at any continuous location) of a scene from a set of input images. We use techniques from volume rendering to accumulate samples of this scene representation along rays to render the scene from any viewpoint. Here, we visualize the set of 100 input views of the synthetic Drums scene randomly captured on a surrounding hemisphere, and we show two novel views rendered from our optimized NeRF representation.
1. Introduction¶
🌟核心思想:¶
NeRF 用一个全连接神经网络(MLP)来表示一个连续的5D场景,这个5D指的是空间位置 (x, y, z) 加上观察方向 (θ, ϕ)。
网络输出的是:
每个点的密度(表示该点是否有物体)
该点从特定方向看到的颜色(RGB)
📸怎么生成新视角图片(即渲染过程):¶
从相机发出一条射线,穿过场景,采样一系列3D点。
把这些点的位置和方向输入神经网络,得到颜色和密度。
用体渲染(volume rendering)技术,把这些颜色和密度“累加”,得到图像上的一个像素。
🎯怎么训练这个模型:¶
利用已有的一组照片(真实拍摄的多个角度图像),优化神经网络的参数,使生成的图像尽可能接近真实图像。
这个过程可用梯度下降法自动完成,因为整个渲染流程是可微分的。
🧠技术亮点:¶
使用 MLP 表示 5D 场景,代替传统的体素(节省大量存储空间)。
位置编码(Positional Encoding):提高 MLP 表达高频细节(比如边缘、纹理)的能力。
分层采样策略:重点采样有物体的区域,减少计算量、提高效率。
✅优点:¶
能生成高质量、逼真的新视角图像。
优于传统的三维建模或图像合成方法。
是首个实现高分辨率、真实感图像合成的连续神经表示方法。
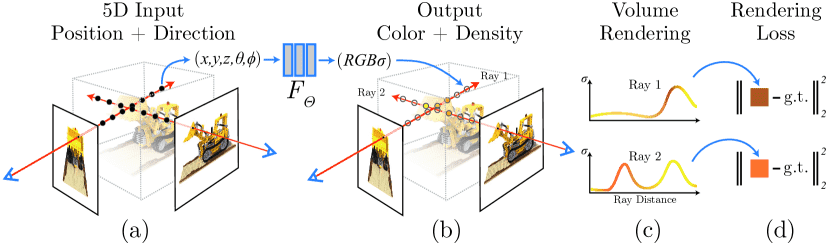
Figure 2: An overview of our neural radiance field scene representation and differentiable rendering procedure.
图片解析
We synthesize images by sampling 5D coordinates (location and viewing direction) along camera rays (a),
feeding those locations into an MLP to produce a color and volume density (b),
and using volume rendering techniques to composite these values into an image (c).
This rendering function is differentiable, so we can optimize our scene representation by minimizing the residual between synthesized and ground truth observed images (d).
3. Neural Radiance Field Scene Representation¶
NeRF(神经辐射场)用一个连续的5D函数来表示三维场景,
输入是:
三维位置 (x, y, z)
视角方向 (θ, φ),通常转成三维单位向量 d
输出是:
颜色 (r, g, b)
密度 σ(表示这个点的“存在感”)
具体实现上,用一个MLP神经网络来学习这个函数,记为 FΘ(x, d) → (c, σ)。
为了保证从多个视角观察一致,设计上规定:
密度 σ 只由位置 x 决定
颜色 c 同时由位置 x 和视角 d 决定
网络结构大致是:
首先用8层全连接网络处理位置 x,输出 σ 和一个256维的特征向量
再把这个特征向量和视角 d 拼在一起,送入一层网络,输出颜色 c
这样做能表现出物体的视角相关效果(如高光),而只用位置 x 就做不到这些效果。
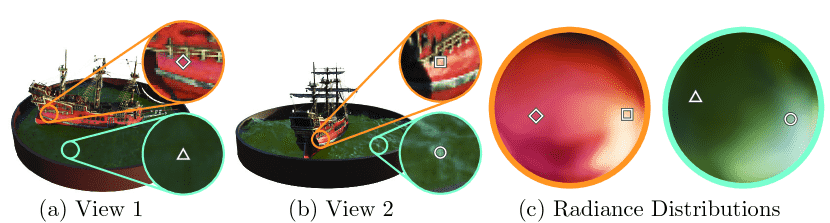
Figure 3:A visualization of view-dependent emitted radiance.
图片理解
Our neural radiance field representation outputs RGB color as a 5D function of both spatial position 𝐱 and viewing direction 𝐝.
Here, we visualize example directional color distributions for two spatial locations in our neural representation of the Ship scene.
In (a) and (b), we show the appearance of two fixed 3D points from two different camera positions:
one on the side of the ship (orange insets) and
one on the surface of the water (blue insets).
Our method predicts the changing specular appearance of these two 3D points,
and in (c) we show how this behavior generalizes continuously across the whole hemisphere of viewing directions.
4. Volume Rendering with Radiance Fields¶
🌟核心思想:¶
用一个神经网络来表示三维场景,它能输出 每个点的密度(σ)和颜色(c)。
为了渲染某个视角的图像,我们通过一条光线(ray)去采样空间中的点,累积颜色,形成图像。
📌详细解释:¶
体渲染原理:
每条相机光线
r(t) = o + t*d会穿过场景。我们计算这条光线的颜色
C(r),是通过积分获得的:\[ C(r) = \int_{t_n}^{t_f} T(t) \cdot \sigma(r(t)) \cdot c(r(t), d) dt \]其中:
σ(x)是密度,表示光线在点x被吸收的概率;T(t)是从起点到t不被吸收的概率;c(x, d)是点x在方向d上的颜色。
采样方法:
我们不能真的去积分,所以用 数值方法(quadrature) 来近似。
方法是将
t范围分成N个小段,每段中随机采一个点(叫 分层采样 stratified sampling)。
离散化后的计算公式:
最终颜色近似为: $\( \hat{C}(r) = \sum_{i=1}^N T_i \cdot (1 - \exp(-\sigma_i \delta_i)) \cdot c_i \)$
其中:
δ_i = t_{i+1} - t_i是相邻样本点间距;T_i是前i-1个点未被吸收的概率。
好处:
虽然我们用离散点计算,但因为采样是连续位置的,所以模型依然可以表示连续的三维场景;
公式是可导的,因此可以用于训练神经网络;
这公式本质上是一个改进版的 alpha blending(透明度合成)。
5. Optimizing a Neural Radiance Field¶
1. 为什么要优化?¶
基础的NeRF方法效果不够好,需要两个关键改进来提升渲染质量,特别是在处理高分辨率和复杂场景时 s
2. 改进一:位置编码(Positional Encoding)¶
问题:MLP难以学习颜色和几何中的高频细节。
解决方案:把输入坐标(位置和视角)映射成高维空间,通过高频的 sin/cos 函数处理,让 MLP 更容易学习高频变化。
作用:可以更好地还原精细纹理和结构。
类似技术:和 Transformer 的位置编码类似,但用于处理连续空间坐标而非离散序列位置。
3. 改进二:分层体积采样(Hierarchical Sampling)¶
问题:均匀采样效率低,浪费在空白或遮挡区域。
解决方案:
先用“粗网络”对每条射线进行粗采样;
根据粗网络的结果,重点在有用区域再做一次“细采样”;
最终的颜色由粗+细采样的结果计算。
作用:节省计算量,提升渲染效果,就像“重要性采样”。
4. 训练细节¶
输入:真实场景的RGB图像、相机位姿、内参和场景范围;
每步训练:
从图像中随机选出若干像素射线;
对每条射线进行粗采样64点、细采样128点;
通过渲染预测颜色,并与真实颜色做平方误差计算;
使用Adam优化器训练;
收敛时间:约10-30万步(1-2天,使用V100 GPU)。
6. Result¶
效果优越
作者的方法在合成图像和真实照片场景中都表现优于现有方法(从表格和图像中可看出),同时提供了很多消融实验来验证设计选择。
数据集
合成数据:使用两个数据集,包含简单和复杂几何结构的物体,分辨率高达 800×800。
真实数据:使用手机拍摄的 8 个复杂真实场景图像(来自 LLFF 论文和自己采集),图像大小为 1008×756。
对比方法
NV(Neural Volumes):用体素网格建模,效果还可以但细节不足,网格大小限制性能。
SRN(Scene Representation Networks):只能输出单一深度和彩色点,渲染结果过于平滑,细节弱。
LLFF:速度快,但图像一致性差,无法处理视角差异过大的情况,而且存储需求极大(一个场景可达 15GB)。
我们的方法的优点
渲染效果在**定量(表格)和定性(图像、视频)**上都更好;
训练虽然也慢(每场景约 12 小时),但模型只需 5MB 存储,比 LLFF 的 15GB 小很多;
即使只用 25 张图训练,也能超过其他方法用 100 张图的效果。
消融实验结论
去掉位置编码、视角相关性建模、层次采样都会明显降低效果;
输入图数量减少会降低效果,但仍优于其他方法;
位置编码频率适度即可,太高不会带来额外提升。

Figure 5:Comparisons on test-set views for scenes from our new synthetic dataset generated with a physically-based renderer. Our method is able to recover fine details in both geometry and appearance, such as Ship’s rigging, Lego’s gear and treads, Microphone’s shiny stand and mesh grille, and Material’s non-Lambertian reflectance. LLFF exhibits banding artifacts on the Microphone stand and Material’s object edges and ghosting artifacts in Ship’s mast and inside the Lego object. SRN produces blurry and distorted renderings in every case. Neural Volumes cannot capture the details on the Microphone’s grille or Lego’s gears, and it completely fails to recover the geometry of Ship’s rigging.
7. Conclusion¶
我们改进了以前用多层感知机(MLP)来表示物体和场景的做法,提出用5D神经辐射场(NeRF)来表示场景,它能根据位置和视角输出密度和颜色,效果比传统的体素网格方法好得多。
我们还引入了分层采样策略来提高训练和测试时的采样效率。但NeRF在优化和渲染效率、可解释性等方面还有很多挑战,比如不像体素或网格那样容易判断渲染质量和失败原因。我们希望这项工作能推动用真实图像构建基于NeRF的图形系统。