2410.13848_Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation¶
引用: 152(2025-07-23)
组织:
1DeepSeek-AI
2The University of Hong Kong
3Peking University
总结¶
核心贡献
采用 双路径视觉编码器(dual-path visual encoder),将视觉信息解耦为两个部分
低级视觉特征(low-level features)
保留丰富的视觉细节,适用于需要精细理解的任务(如图像描述生成)
视觉生成:需要低维、细节层面的表示(如局部纹理、全局一致性)。
高级语义特征(high-level semantic features)
提取与语言任务更相关的抽象语义信息,适用于需要推理和理解的任务(如视觉问答)
视觉理解:需要高维、语义层面的表示(如对象类别、属性)
特点
通过将视觉编码解耦为独立路径,解决了因任务所需信息粒度不同而导致的性能问题
使用两个独立的视觉编码路径:一个用于理解,一个用于生成
两个路径共享统一的Transformer架构,实现跨任务的协调
统一的多模态理解和生成能力
不仅能够处理多模态理解任务(如视觉问答、图像分类)
还能处理生成任务(如图像描述生成、图像到文本的生成)
通过共享的语言模型(如 BERT 或 GPT)将视觉信息与语言信息融合
LLM总结¶
该论文《Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation》提出了一种名为 Janus 的统一多模态理解和生成模型。其核心思想是通过 解耦视觉编码(decoupling visual encoding) 来提升模型在处理视觉与语言任务时的灵活性和性能。
主要内容总结如下:
问题背景:
现有多模态模型通常将视觉特征直接与语言模型结合,缺乏对视觉信息的精细处理,限制了模型在多样化任务上的表现。
不同任务(如图像描述、问答、视觉推理)需要对视觉信息进行不同的处理方式,现有方法难以统一处理这些任务。
核心贡献 - Janus 模型结构:
提出 Janus 模型,采用 双路径视觉编码器(dual-path visual encoder),将视觉信息解耦为两个部分:
低级视觉特征(low-level features):保留丰富的视觉细节,适用于需要精细理解的任务(如图像描述生成)。
高级语义特征(high-level semantic features):提取与语言任务更相关的抽象语义信息,适用于需要推理和理解的任务(如视觉问答)。
通过这种解耦结构,Janus 能够根据任务需求选择性地使用视觉信息的不同层面,从而实现对多种多模态任务的统一建模。
统一的多模态理解和生成能力:
Janus 不仅能够处理多模态理解任务(如视觉问答、图像分类),还能处理生成任务(如图像描述生成、图像到文本的生成)。
模型通过共享的语言模型(如 BERT 或 GPT)将视觉信息与语言信息融合,实现端到端的训练和推理。
实验结果:
在多个视觉-语言任务上(如 VQA、Image Captioning、RefCOCO)进行了实验,结果显示 Janus 相比现有模型具有优越的性能。
该模型在不同任务之间展示了良好的泛化能力,验证了其解耦视觉编码设计的有效性。
意义与应用:
提出的解耦视觉编码方法为多模态模型的设计提供了新的思路,有助于实现更灵活、强大的视觉-语言统一建模。
Janus 模型可以应用于各种需要同时理解与生成的多模态任务,如智能助手、人机交互、内容生成等。
总结: Janus 通过引入双路径视觉编码器,将视觉信息解耦为低级和高级特征,实现了对多模态理解和生成任务的统一建模。该模型在多个视觉-语言任务中表现出色,展示了其在多模态学习领域的潜力和实用性。
Abstract¶
这篇文章介绍了Janus,一个统一多模态理解和生成的自回归框架。与以往依赖单一视觉编码器处理两种任务的方法(如Chameleon)不同,Janus通过将视觉编码解耦为独立路径,解决了因任务所需信息粒度不同而导致的性能问题。这种设计不仅减少了视觉编码器在理解和生成任务中的冲突,还增强了框架的灵活性,使两个任务组件可以独立选择最适合的编码方式。实验表明,Janus在性能上超越了先前的统一模型,并达到或超过了任务专用模型的水平。整体而言,Janus因其简洁、灵活和高效,成为下一代统一多模态模型的有力候选。
1 Introduction¶
本章是论文《Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation》的引言部分,主要介绍了多模态大模型在视觉理解和生成任务中的研究背景与挑战,并提出了本文的解决方案与创新点。内容总结如下:
研究背景¶
多模态大模型近年来在视觉理解和视觉生成领域取得了显著进展。
视觉理解方面,通常通过视觉编码器连接大语言模型(LLM),如LLaVA。
视觉生成方面,扩散模型和自回归方法都取得了不错的效果。
为了构建更强大、更通用的多模态模型,研究者尝试将理解与生成任务统一。
一些方法使用预训练的扩散模型处理生成任务(如Emu),但这类方法并非真正的统一模型,因为生成任务依赖外部模型。
另一些方法尝试用单个Transformer统一处理两个任务,如UniViT、InternVideo等,提高了指令跟随能力,但容易因任务间表示冲突而影响性能。
问题与挑战¶
理解和生成任务对视觉表示的需求存在显著差异:
视觉理解:需要高维、语义层面的表示(如对象类别、属性)。
视觉生成:需要低维、细节层面的表示(如局部纹理、全局一致性)。
这些差异会导致统一表示空间中的冲突和妥协,从而影响模型在两个任务上的表现。
本文贡献¶
提出了一个名为 Janus 的统一多模态框架,通过解耦视觉编码解决上述问题。
Janus 的核心设计是:
使用两个独立的视觉编码路径:一个用于理解,一个用于生成。
两个路径共享统一的Transformer架构,实现跨任务的协调。
该设计带来两个主要优势:
避免任务间表示冲突,无需在任务中取舍。
灵活可扩展:每个任务可使用该领域最先进的编码方法,并支持未来扩展(如点云、脑电、音频等)。
实验与结果¶
Janus 在多个视觉理解和视觉生成基准测试中取得**SOTA(最先进)**表现。
例如:
在 MMBench、SEED-Bench 和 POPE 上,Janus(1.3B)超越了 7B 参数的 LLaVA 和 Qwen-VL-Chat。
在 MSCOCO-30K 和 GenEval 上,Janus 的 FID 得分和准确率优于 DALL-E 2 和 SDXL 等图像生成模型。
实验结果验证了解耦视觉编码的有效性,并展示了 Janus 在性能、灵活性和扩展性上的优势。
总结¶
Janus 通过解耦视觉编码,解决了多模态理解和生成任务之间表示冲突的问题,为下一代统一多模态模型提供了新的思路。本章为全文奠定了基础,明确了本文的研究动机、方法创新与实验成果。
3 Janus: A Simple, Unified and Flexible Multimodal Framework¶
本文介绍了 Janus,一个用于多模态理解和生成的统一、灵活且简洁的框架。其核心思想是通过解耦视觉理解和视觉生成的编码器,从而提升模型在不同任务上的表现和适应性。
3.1 架构设计¶
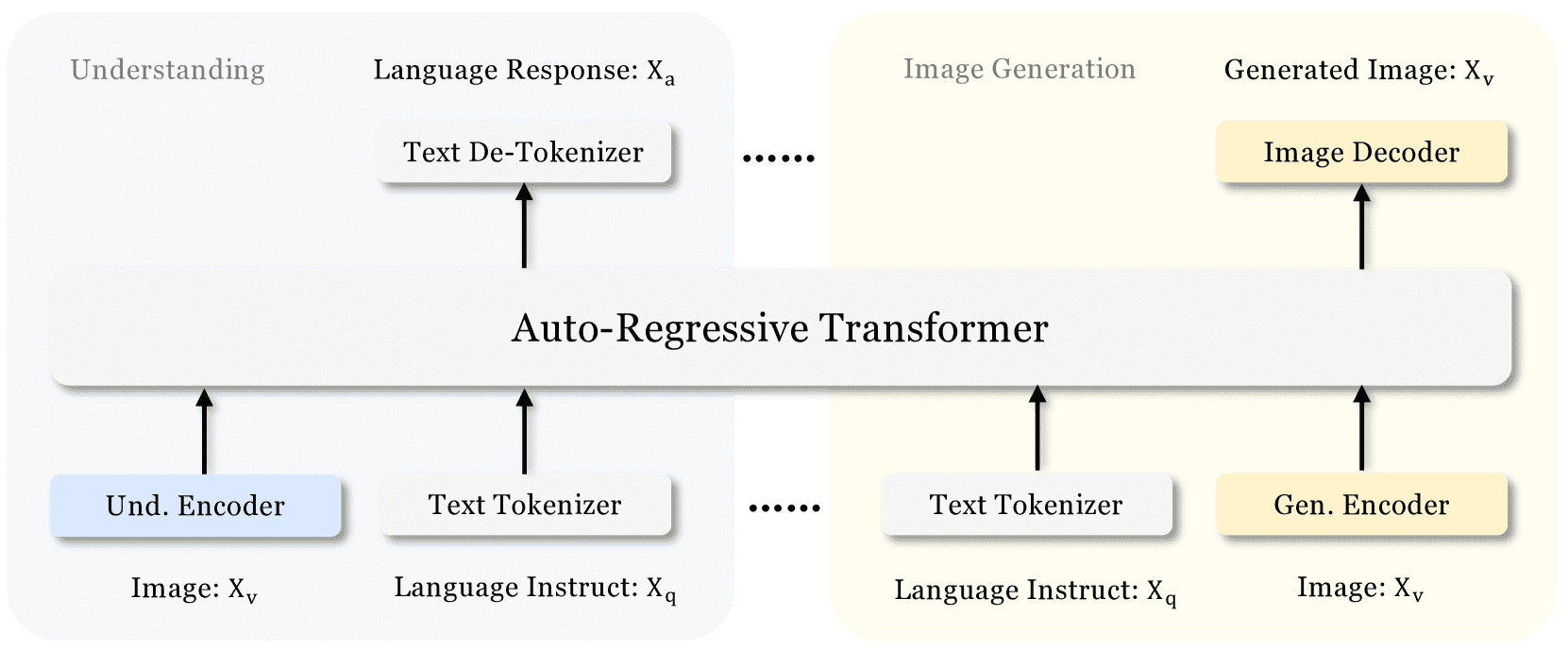
Figure 2: Architecture of our Janus.
图片说明
Und. Encoder: Understanding Encoder
Gen. Encoder: Generation Encoder
Janus 的架构如图 2 所示。模型针对纯文本、多模态文本图像理解和图像生成任务,采用不同的编码方式:
文本理解:使用大语言模型(LLM)的内置 tokenizer 将文本转换为 ID 序列。
多模态理解:使用 SigLIP 编码器提取图像的高维语义特征,并通过一个“理解适配器”映射到 LLM 的输入空间。
图像生成:使用 VQ tokenizer 将图像转换为离散 ID,再通过“生成适配器”映射到 LLM 的输入空间。
所有特征序列拼接后输入同一个 LLM,LLM 使用内置预测头处理文本预测,图像生成则使用随机初始化的预测头。
整个模型采用自回归结构,无需特殊设计的注意力掩码。
3.2 训练流程¶
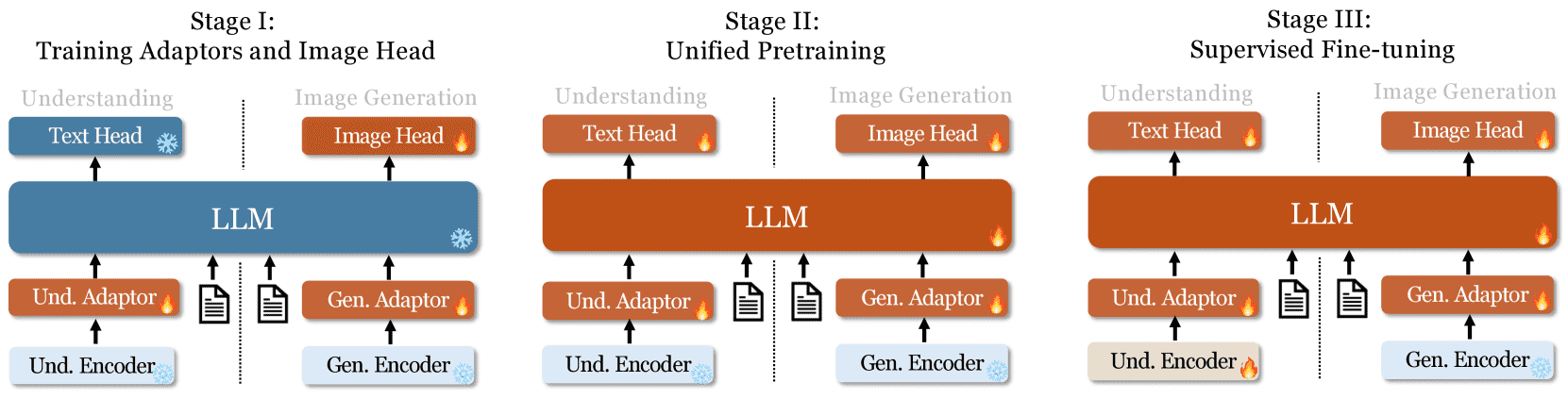
Figure 3: Our Janus adopts a three-stage training procedure. We use flame symbols/snowflake symbols in the diagram to indicate the module updates/does not update its parameters.
Janus 的训练分为三个阶段(见图 3):
适配器与图像头训练(Stage I):冻结视觉编码器和 LLM,仅训练适配器和图像预测头,以建立图像与语言表征的初步联系。
统一预训练(Stage II):解冻 LLM,使用纯文本、多模态和图像生成数据进行统一预训练。先使用 ImageNet 进行基础图像生成训练,再加入开放领域图文对数据。
监督微调(Stage III):使用指令数据微调模型,提高其对话和指令跟随能力。微调时不冻结生成编码器,但聚焦于答案生成,掩码掉用户和系统提示。
3.3 训练目标¶
Janus 是一个自回归模型,训练时使用交叉熵损失:
对于文本理解和多模态任务,损失计算在文本序列上;对于图像生成任务,损失计算在图像序列上。不同任务之间未分配不同的损失权重,设计简洁。
3.4 推理过程¶
文本和多模态任务:使用标准的 next-token 采样方法。
图像生成:使用无分类器引导(CFG)增强生成效果。生成时每个 token 的 logits 通过条件 logits 和无条件 logits 的加权组合计算。
3.5 潜在扩展¶
Janus 架构设计简洁且模块化,具有良好的扩展性:
多模态理解:可使用更强大的视觉编码器(如 EVA-CLIP、InternViT),并引入动态分辨率处理和 token 压缩技术,以适应高分辨率图像。
图像生成:可使用更细粒度的编码器(如 MoVQGan)和专用损失函数(如扩散损失),并结合自回归与并行注意力机制降低生成误差。
支持新模态:Janus 可轻松集成其他模态的编码器,如 3D 点云、触觉信号和脑电(EEG),从而发展为更通用的多模态模型。
总结¶
Janus 的创新点在于解耦视觉理解和生成的编码器,从而实现了统一的多模态建模与生成能力。通过三阶段训练流程和自回归结构设计,Janus 在保持模型简洁性的同时,具备良好的扩展性,为多模态任务提供了灵活高效的解决方案。
4 Experiments¶
本节内容对多模态理解和生成模型 Janus 的实验设计和结果进行了系统性的介绍和分析,主要包含以下几个方面:
一、实验设置(Implementation Details)¶
基础模型:
使用 DeepSeek-LLM (1.3B) 作为语言模型,最大序列长度为 4096。
在理解任务中使用 SigLIP-Large-Patch16-384 作为视觉编码器。
生成任务使用一个编码码本大小为 16,384 的编码器,图像下采样因子为 16。
适配器结构:
理解适配器和生成适配器均为两层 MLP。
图像预处理:
图像统一调整为 384×384 像素。
多模态理解任务中,长边拉伸,短边用 (127, 127, 127) 填充至 384。
生成任务中,短边拉伸为 384,长边裁剪至 384。
训练设置:
使用 HAI-LLM 框架,基于 PyTorch 构建,训练分布在 16 节点(每个节点 8 个 A100 GPU),总训练时间 7777 天。
使用序列打包(sequence packing)提高训练效率。
数据类型混合训练,比例由各阶段指定。
超参数设置:
包括学习率、优化器、学习率调度器、权重衰减、梯度裁剪等。
训练分为三阶段,每个阶段的超参数和数据配比不同。
二、数据集设置(Data Setup)¶
预训练阶段(Stage I):
多模态理解任务使用 125 万个图像-文本对(ShareGPT4444V)。
生成任务使用 120 万个 ImageNet-111k 样本。
监督微调阶段(Stage II):
包括纯文本数据、图像-文本交错数据、图像描述数据、图表数据、生成数据等。
图像描述数据使用开源模型重新生成,并格式化为问答对。
生成数据中,前 120K 步使用 ImageNet 图像,后 60K 步使用其他数据,以逐步提升模型复杂度。
指令微调阶段(Stage III):
使用多个指令调优数据集,用于文本理解、多模态理解与生成任务。
数据格式为用户-助手对话形式。
三、评估设置(Evaluation Setup)¶
多模态理解评估:
使用 VQAv2、GQA、POPE、MME、SEED、MMB、MM-Vet、MMMU 等主流视觉-语言基准测试。
Janus 在这些任务中表现优于许多现有模型,尤其在 1.3B 参数规模下性能接近甚至超越部分 7B 模型。
视觉生成评估:
使用 MSCOCO-30K、MJHQ-30K 和 GenEval 作为评估基准。
评估指标包括 FID(图像生成质量)和 GenEval 的细粒度任务(如对象数量、位置、颜色等)。
Janus 在 1.3B 参数下取得了 0.61 的总体得分,优于多个生成专用模型(如 LlamaGen、SDv2、DALL-E 2 等)。
四、实验结果¶
多模态理解性能:
Janus 在多个基准测试中表现优异,如在 POPE 得到 87.0%,在 MMB 得到 69.4%,在 GQA 得到 59.1%。
在相同参数规模下,优于许多专门用于理解或生成的模型。
视觉生成性能:
在 GenEval 上,Janus 在对象识别、颜色、位置等任务上表现优异,尤其在位置属性(0.46)和颜色属性(0.42)上得分较高。
总体得分为 0.61,远高于 LlamaGen(0.32)和 DALL-E 2(0.52)等生成模型。
消融实验与定性结果:
进行了多组消融实验,验证了模型设计的有效性。
提供了部分生成结果的示例,说明 Janus 能生成高质量、符合语义的图像。
总结¶
本节全面评估了 Janus 模型在多模态理解与生成任务上的性能。通过多阶段训练策略、高质量数据集和合理的模型架构设计,Janus 在 1.3B 参数规模下实现了与大模型(如 7B、8B 模型)相当甚至更优的性能,展示了其在多模态任务中的高效性和通用性。
4.4 Comparison with State-of-the-arts¶
本章节主要对Janus模型在多模态理解和生成任务中的性能进行了全面评估与分析,包括与现有最先进方法的对比、消融研究,以及定性结果展示。
4.4 与最先进方法的对比¶
多模态理解性能¶
Janus在与类似规模的统一模型和仅理解模型的对比中表现出色,尤其是在MME和GQA数据集上,分别提升了约41%和30%。这归因于Janus对视觉编码的解耦设计,有效缓解了理解与生成任务间的冲突。即使是在更大规模模型(如LLaVA-1.5)面前,Janus在多个数据集(如POPE、MMbench、SEED Bench、MM-Vet)上依然具有竞争力。
视觉生成性能¶
Janus在GenEval、COCO-30K和MJHQ-30K等基准测试中表现优异。其在GenEval上的整体准确率达到61%,优于之前的统一模型Show-o(53%)及一些专用生成模型(如SDXL和DALL-E 2)。在COCO-30K和MJHQ-30K上的FID值分别为8.53和10.10,优于多个生成专用模型,表明其生成的图像质量上乘,具备良好的生成能力。
4.5 消融研究¶
本节通过多个实验验证Janus设计的合理性:
视觉编码解耦的重要性:实验表明,使用单一视觉编码器(如Exp-B)在理解任务上表现优于生成任务,但与专用于理解任务的模型(如Exp-C)相比仍存在差距。这说明解耦视觉编码有助于提升理解性能,而统一编码可能在任务间产生权衡。
统一训练 vs. 专用训练:统一训练(Exp-D)在理解与生成任务上的表现与专用训练(Exp-C和Exp-F)相当,说明Janus能够在不影响理解能力的前提下兼顾生成能力。
语义编码器的作用:通过引入基于SigLIP的语义编码器(Exp-B),在理解任务上显著提升,证实了语义信息提取对多模态理解的重要性。
4.6 定性结果¶
视觉生成对比¶
与SDXL和LlamaGen的对比图(图4)显示,Janus生成的图像在分辨率较低的情况下仍能较好地遵循用户提示,细节捕捉能力较强,表明其在视觉生成方面具备潜力。
多模态理解对比¶
在处理幽默表情包(MEME)任务中,Janus能够准确识别文本和图像情感,而Chameleon和Show-o在文本识别和对象识别方面表现较差。这进一步验证了Janus解耦视觉编码设计在细粒度多模态理解上的优势。
总结¶
Janus通过解耦视觉编码设计,在统一模型中实现了多模态理解和生成能力的双重提升。其在多个基准测试中优于现有模型,尤其在理解任务上表现突出。消融研究表明,解耦设计和语义编码器对性能提升具有关键作用。定性结果也验证了其在生成质量和理解能力方面的优势,展示了其在统一多模态模型中的应用潜力。
5 Conclusion¶
本文总结了Janus模型的核心思想、优势及其潜在应用。Janus是一个简单、统一且可扩展的多模态理解和生成模型,其关键在于将视觉编码模块解耦,分别用于多模态理解和生成任务,从而缓解因两种任务对视觉编码器不同需求而产生的冲突。大量实验表明,Janus在性能上表现出色,具有领先优势。此外,Janus具备高度灵活性和可扩展性,不仅在多模态理解和生成方面有较大提升空间,还能方便地扩展至更多输入模态。这些优势表明,Janus可能为下一代多模态通用模型的开发提供重要启示。
Appendix¶
附录部分通常用于放置对正文内容进行补充说明的材料,如数据表、计算公式、参考文献、代码片段、调查问卷等。它的作用是为读者提供更详细或更专业的参考资料,以增强论文的完整性和可信度。附录内容虽不直接出现在正文讨论中,但对理解研究过程和结果具有重要辅助作用。
Appendix A Details of Semantic Tokenizer Mentioned in Ablation Study¶
本文附录 A 详细描述了在消融实验中使用的语义 Tokenizer 的架构、训练方法以及与大语言模型(LLM)的集成方式。总结如下:
一、语义 Tokenizer 架构(A.1)¶
架构基础:
语义 Tokenizer 基于已有架构改进,采用 16×16 的下采样率。
在原始的 CNN 像素解码器基础上,增加了一个“语义解码器”分支。
语义解码器是一个 12 层的 Vision Transformer(ViT),具有 12 个注意力头,隐藏维度为 768。
在与 LLM 集成时,使用因果注意力掩码(causal attention mask)来支持“下一个 token 预测”。
训练与测试使用方式:
在训练过程中,使用预训练的 SigLIP 模型监督语义信息的重建,同时使用原始图像监督 RGB 值的重建。
在测试阶段(与 LLM 集成时),语义解码器输出的特征经过适配器后输入 LLM。
需要注意的是,语义 Tokenizer 仅用于消融实验,而不是主实验中的标准模型。
二、训练过程(A.2)¶
训练阶段:
第一阶段:在 ImageNet-1k 数据集上预训练 40 个 epoch。
第二阶段:在 Janus 训练中使用的 5 亿张图像上微调 1 个 epoch。
使用恒定学习率(1e-4)和批量大小为 128。
训练损失函数:
RGB 重建损失:与原始工作一致,用于重建图像像素。
语义重建损失:使用 SigLIP-Large 作为教师模型,通过最大化语义解码器输出特征与 SigLIP 输出之间的余弦相似度来监督。
语义重建损失的权重为 0.25。
三、与 LLM 的集成(A.3)¶
处理流程:
输入图像首先通过 CNN 编码器、向量量化层和语义解码器,得到连续的语义特征。
这些特征通过适配器后输入 LLM,LLM 生成图像的 token ID 预测。
最后,像素解码器将这些 token ID 转换回 RGB 值,完成图像重建。
核心思想:
语义 Tokenizer 将视觉信息解耦为“语义”与“像素”两部分,分别由 LLM 和像素解码器处理,以支持多模态理解和生成。
总结¶
语义 Tokenizer 是一个专为消融实验设计的模块,具有 CNN 编码器和 ViT 语义解码器,能够分别重建图像的 RGB 信息与语义特征。其通过预训练与微调过程优化,并与 LLM 结合,用于探索视觉语义信息在多模态模型中的作用。该模块在主实验中未使用,仅用于验证语义信息处理的效果。
Appendix B Additional Qualitative Results¶
附录B 额外的定性结果总结:
本章节补充展示了 Janus 模型在文本到图像生成和多模态理解方面的更多定性结果:
更多文本到图像生成结果(图7)
展示了Janus在文本到图像生成任务中的高质量输出。所有图像被上采样至1024×1024,以提升可视化效果。结果表明,模型能够很好地遵循输入提示,生成与文本高度一致的图像。多语言文本到图像生成(图8)
Janus展示了其在多语言文本到图像生成方面的能力,支持英语、中文、法语、日语等语言。尽管训练数据仅使用英语文本到图像数据,模型仍能处理其他语言的输入。这一能力被归因于基础大语言模型(LLM)的特性,其将多种语言映射到统一的语义空间,使得Janus无需额外训练即可完成任务。更多多模态理解结果(图9)
Janus在处理多模态输入时表现出色,能够理解来自不同背景的输入,包括科学图表、艺术作品图像、LaTeX公式图像等,展示了其强大的多模态理解能力。
总结来看,Janus不仅在图像生成方面表现优异,还在多语言支持和多模态理解方面展现出广泛的适用性和强大的模型能力。