2505.17589_CosyVoice3: Towards In-the-wild Speech Generation via Scaling-up and Post-training¶
引用:
组织:
Speech Team, Tongyi Lab, Alibaba Group
其他
CosyVoice3 Demo: https://funaudiollm.github.io/cosyvoice3
数据集: CV3-Eval
From LLM¶
CosyVoice 默认中文语速约 4–6 字 / 秒,英文约 3–5 词 / 秒。
CosyVoice 默认语音 token 表征速率为 25 token / 秒,云端 RTF 低至 0.05,首包延迟 150ms 起,完全满足实时对话需求;端侧经基础优化也能达到 RTF<0.6 的实时标准。
行业标准:RTF = 合成耗时 / 音频时长
Abstract¶
他们之前做了一个语音合成系统 CosyVoice 2,结合了大语言模型和流匹配模型,能做到双向流式合成,效果接近人类语音,但在语言覆盖、数据量等方面还有不足。
现在,他们推出了升级版 CosyVoice 3,支持多语言、零样本语音合成,在内容一致性、声音相似度和语调自然性上都有提升。
主要改进包括:
新语音分词器:通过多任务训练(识别语音、情感、语言、事件和说话人)来提高语调自然度。
新奖励模型:可用于后训练优化,不仅适用于 CosyVoice 3,也能用于其他基于 LLM 的语音合成模型。
数据扩展:训练数据从1万小时扩展到100万小时,覆盖9种语言和18种中文方言。
模型扩展:模型规模从5亿参数提升到15亿,性能明显提升。
关键词
LID: Language Identification(语种识别)
SER: Speech Emotion Recognition(语音情感识别, audio)
AED: Audio Event Detection(音频事件检测, audio)
SA: Speaker Analysis(说话人分析)
SS: Speaker Similarity(说话人相似度, 评估)
CER: Character Error Rate(字符错误率, 评估, WER)
SIM: Style Similarity(风格相似度, 评估)
1.Introduction¶
一、背景和现状¶
随着生成式神经网络的发展,语音合成(TTS)技术已经大幅超越传统方法,声音更加自然。
尤其是 零样本 TTS(Zero-shot TTS) 技术,可以不用提前训练某个说话人的声音,也能很好地模仿其语音风格和情感。
二、目前主流的零样本 TTS 技术有三类:¶
使用大语言模型(LLM),对离散的语音 token 进行建模;
使用扩散模型(Diffusion),自动学习语音与文本的对齐;
混合系统:用自回归 LLM 建模语义,再用非自回归模型生成细节语音,平衡质量、延迟与灵活性,是工业界主流。
三、CosyVoice 2 简介¶
作者之前开发了 CosyVoice 2,在中英文新闻播报类任务中效果很好。
它支持低延迟双向流式合成,音质接近人声。
但在 语言覆盖、场景多样性、数据量 和 文本格式适应性 等方面仍有限。
四、新模型 CosyVoice 3 的改进¶
为了解决上述问题,作者提出了 CosyVoice 3
改进包括:
新的语音分词器:能更好捕捉情感、发音风格等副语言信息。
提出后训练策略 DiffRO:一种新型可微分奖励优化方法,提升语音生成质量。
数据和模型规模扩展:
数据从 1 万小时扩到 100 万小时,涵盖 9 种语言、18 种方言、各种文本格式。
模型参数从 5 亿扩展到 15 亿,进一步提升语调自然性。
构建新评测基准 CV3-Eval:涵盖真实场景、多语言、多风格,评估模型在真实世界下的泛化能力。
五、结果¶
CosyVoice 3 在多个评测上表现优异,语义准确性、说话人相似度、语调自然性都超越 CosyVoice 2。
是向“真实世界语音合成”迈出的重要一步。
2.CosyVoice 3¶
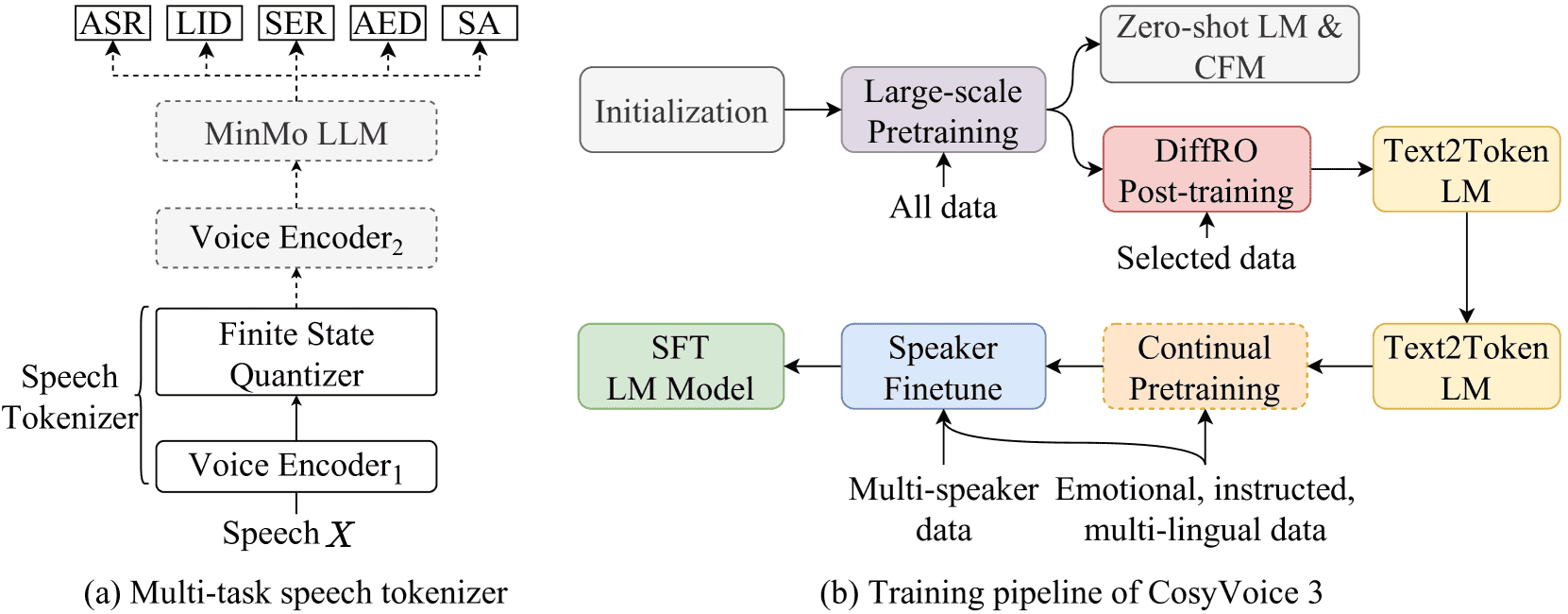
Figure 2:Illustrations of (a) Supervised multi-task trained speech tokenizer and (b) The training pipeline in CosyVoice 3. Modules with dashed boxes are only used in the training stage. The speech tokenizer is supervised trained on ASR, language identification (LID), speech emotion recognition (SER), audio event detection (AED), and speaker analysis (SA) tasks. CFM denotes the conditional flow matching model.
主要进展:相比 CosyVoice 2,新版本使用了更强大的语音理解模型 MinMo 来提取语音特征。
训练流程:包括大规模预训练、后训练(提高泛化能力)、持续预训练(迁移能力如多语种生成)、以及多说话人微调。
2.1 Speech Tokenizer via Supervised Multi-task Training¶
使用 MinMo 模型替代旧模型,并在其编码器中加入量化模块(FSQ)。
用 53 万小时数据进行多任务训练,任务包括语音识别、语言识别、情感识别等。
语音通过编码器提取特征 → 降维 → 量化 → 恢复维度 → 变成离散 token。
每秒输出 25 个语音 token。
2.2 Reinforcement Learning with Differentiable Reward Optimization¶
使用 ASR 模型预测文本,作为奖励信号来优化语音 token,而不是优化最终音频(节省资源)。
用 Gumbel-Softmax 模拟采样,结合 KL 散度控制模型偏移。
奖励函数支持多任务,如情感、语音质量评分(MOS)等。
2.3 Pronunciation Inpainting¶
引入“词+音素”的混合输入,增强对中文多音字、英文生僻词的控制。
构造辅助数据集,将文字替换为拼音或音素,提高发音准确性。
2.4 Self-training for Text Normalization¶
原本需要手写规则将文本标准化,现在使用大模型 Qwen-Max 自动学习转换规则。
生成的文本音频对加入训练集,提升模型对特殊字符和数字的处理能力。
2.5 Instructed Speech Generation¶
扩大了高质量“指令跟随”数据(从 1500 小时增至 5000 小时),覆盖情感、语速、口音等超 100 类控制类型。
可使用自然语言和标签精细控制,如 [笑声]、[呼吸] 等。
2.6 Capability Transfer in Speaker Fine-tuning¶
2.6.1 Turning a Monolingual Speaker into a Polyglot¶
构造包含多语言的单语语料,配合自然语言指令,实现说话人“跨语种说话”。
2.6.2 Transferring the Capability of Instructed Generation¶
微调过程中加入带说话人风格的指令语料,有些保留空白以增强泛化。
防止模型遗忘原始能力,保持多说话人的指令理解能力。
3.The Multilingual Data Pipeline¶
这段内容讲的是为了训练多语言TTS(语音合成)模型,如何从网络上收集并处理音频数据。
核心思想是通过一个六步的处理流程,把原始杂乱的多语种音频,变成高质量的训练数据。
语音检测和切分
利用说话人识别、语音活动检测等技术,把原始音频切成30秒以内的说话人片段。
降噪
用MossFormer2模型去噪,并去掉开头或结尾被截断的片段,只保留清晰完整的。
自动语音识别(ASR)转录
先识别语言,再用多个ASR模型(如Faster-Whisper等)转文字,取不同模型转录结果一致性高的(词错误率低于15%)文本。
标点修正
标点可能不准,通过对音频中停顿的时间分析(如停顿≥300ms加逗号,≤50ms删标点)来调整标点。
音量标准化
把所有音频音量统一到一个标准(最大值归一化后乘0.6)。
过滤异常数据
比较音频和文本的长度比例,去掉前1%和后5%异常比例的数据,防止音频和文本对不上。
4.Experimental Settings¶
4.1 Training Data for Speech Tokenizer¶
使用了 53 万小时的多任务监督数据,包括 ASR(语音识别)、LID(语言识别)、SER(情感识别)、AED(音频事件检测)和 SA(说话人分析)。
支持中、英、日、韩、俄、法、德等多语言。

Table 3: Details of the training data for speech tokenizer.
4.2 Scaling up Dataset Size and Model Size for CosyVoice 3¶
数据扩展:
增加了电商、导航、金融、教育等多领域数据。
添加了对话、演讲、唱歌等多种风格。
使用文本正/反归一来增强对不同文本格式的适应能力。
加入了少数语言(如西班牙语、意大利语)和 19 种中文方言。
总训练时长达到 100 万小时。
模型扩展:
TTS语言模型从 5亿 参数扩展到 15亿。
使用了 DiT 架构的 CFM 模型,从 1亿 扩展到 3亿参数,并去掉了复杂的文本编码器和节奏模块。
4.3 Evaluation Settings for Zero-shot Capability¶
评估三方面能力:
内容一致性(ASR识别后计算 CER/WER)
说话人相似度(提取说话人向量计算余弦相似度)
音频质量(用 DNSMOS 网络评分)
使用了两个评估集:
常用 SEED-TTS-Eval(包含普通话、英文和难度较高的中文)
新构建的多语言评估集 CV3-Eval(详见下方)
4.4 CV3-Eval: a Multilingual Benchmark¶
为更全面评估模型,在现有评估不适用的情况下,构建了新的多语言测试集,
包含:
客观评估子集
多语言克隆:9种语言各500条,带背景噪声等真实场景挑战。
跨语言克隆:源音频和目标文本语言不同。
情感克隆:评估模型是否能复现快乐/悲伤/生气等情绪。
主观评估子集
表现力语音克隆:比如有强烈情绪、低语、喊叫等特殊语调。
表现力语音续写:用前3秒音频预测续写部分,与真实语音比较。
中文方言克隆:18种中文方言,由人工评估语音是否真实。
5.Experimental Results¶
5.1 Objective TTS Results on SEED-TTS-Eval¶
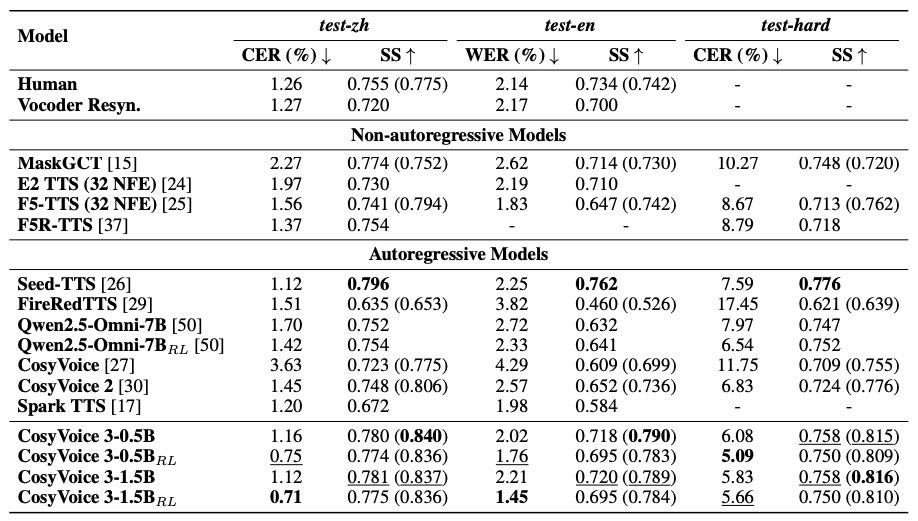
Table 4:Zero-shot TTS performance comparison between CosyVoice 3 and the baselines on the SEED test sets in terms of content consistency (WER/CER) and speaker similarity (SS). For speaker similarity, the results outside parentheses are measured by WavLM-based models while the results inside parentheses are measured by ERes2Net. While the boldface denotes the best result, the underline denotes the second best.
内容一致性(CER/WER 越低越好):CosyVoice 3 相比前一代(CosyVoice 2)提升明显,中文误差降低 44%,英文降低 51%,困难集降低 26%。
说话人相似度(SS 越高越好):CosyVoice 3 在多数情况下超过所有基线模型,仅略逊于 Seed-TTS。
RL 微调有帮助:加入 RL(强化学习)微调后,CosyVoice 3 内容一致性进一步提升 12%-35%,更适应多语言、复杂任务。
5.2 Objective Evaluation on Multilingual Benchmark CV3-Eval¶
5.2.1 多语言语音克隆结果¶
CosyVoice 3 支持 CV3-Eval 中所有语言(中文、日语、韩语、英语、德语、西语、法语、意大利语、俄语),其它模型只支持中英文。
在多数语言上,CosyVoice 3 的表现优于 F5-TTS、Spark-TTS 和 GPT-SoVits。
CosyVoice 3 加上 DiffRO 技术后,识别错误率(CER/WER)显著降低。
稀有词、绕口令、专业词依然是弱点,仍需改进。
5.2.2 跨语言语音克隆结果¶
CosyVoice 3 相比 CosyVoice 2,在不同语言之间转换表现大幅提升。
特别地,CosyVoice 2 在日转中表现差(因中日有汉字重合干扰),CosyVoice 3 通过日文转平假名解决了这个问题。
更大的模型(1.5B)比小模型(0.5B)整体表现更好,且说话人相似度无明显下降。
CosyVoice 3 在英转中、中转英任务中优于其它模型,MOS 和 SS 评分也领先。
5.2.3 情感语音克隆结果¶
CosyVoice 3 在表达“高兴”、“悲伤”、“生气”情绪方面,在“文本相关”任务中效果最好。
所有模型在“文本无关”的情绪克隆任务上表现下降,说明目前的 TTS 系统主要靠文本情绪推断语气,缺乏独立情感控制能力。
加入 DiffRO-EMO 技术后,CosyVoice 3 的情绪准确率显著提高。
5.2.4 主观评估结果(MOS)¶
主观测试由 10 位母语者评分,结果显示:
中文上,各模型得分接近但略低于真人语音。
英文上,CosyVoice 3-0.5B 达到人类水平,CosyVoice 3-1.5B 超过人类水平。
综合来看:CosyVoice 3 模型比 CosyVoice 2 更自然,模型越大,语音质量越好。
5.3 Ablation of Speech Tokenizer¶
一、上游:语音识别任务(ASR)¶
对比了不同的 tokenizer(VQ、FSQ、MinMo)在多个语言(英语、中文等)下的识别准确率。
FSQ-MinMo(CosyVoice 3 用的 tokenizer)在中文 Fluers 测试集上比 MinMo 表现更好。
在另一个多任务识别测试集(AIR-Bench)上,FSQ-MinMo 虽然在性别和年龄分类任务上略逊色,但整体表现接近 MinMo。
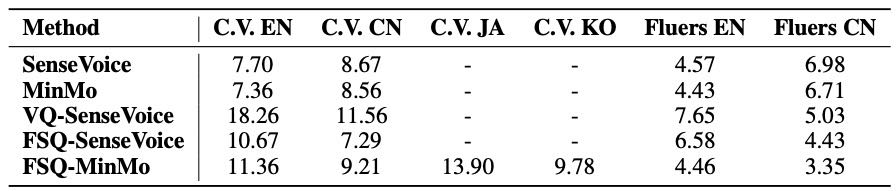
Table 10:Comparison between VQ and FSQ inside the Sensevoice-large and MinMo encoders in terms of ASR WERs and CERs (%) across language-specific subsets of the CommonVoice (C.V.) and the Fluers benchmarks. FSQ-MinMo is the tokenizer used in CosyVoice 3.
总结:FSQ-MinMo 在语音识别任务中表现稳定,尤其在中文上更好。
二、下游:语音合成任务(TTS)¶
评估了不同 tokenizer 对语音合成质量的影响,使用指标包括:
CER/WER:内容一致性(越低越好)
SS:说话人相似度(越高越好)
在 3,000 小时数据上,CosyVoice 3 的 tokenizer 比 HuBERT、W2v-BERT 2.0、SoundStream 更准确,说话人相似度也高。
在 17 万小时数据上,表现进一步提升,尤其是英文和难例子。
SoundStream 作为无监督声学 tokenizer,因缺少语义信息,在所有任务中表现最差。
👉总结:CosyVoice 3 的 supervised tokenizer 在语音合成中表现优越,训练数据越多,效果越好,但会逐渐趋于饱和。
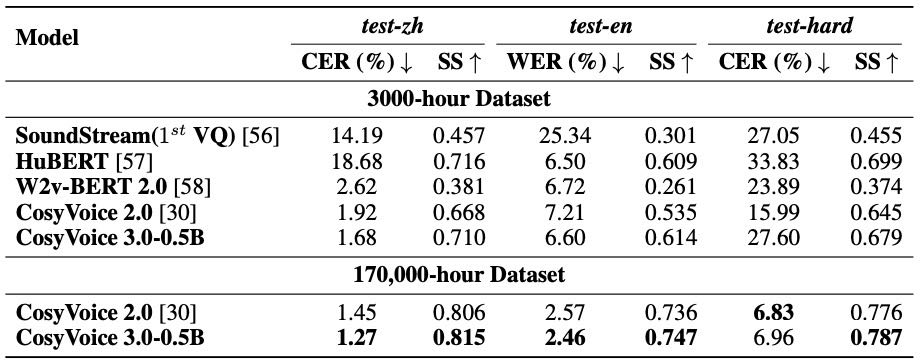
Table 12:Performance comparison of down-streaming zero-shot TTS modeling using different tokenizers on the SEED test sets in terms of content consistency (WER/CER) and speaker similarity (SS). While the boldface denotes the best result.
5.4 Ablation of Reinforcement Learning¶
使用 DiffRO 强化学习技术显著提升了 TTS 系统(CosyVoice 2 和 3)的性能,在低资源语言和跨语言语音克隆中效果尤其明显。
相对 WER(词错误率)提升最高达 68.7%(例如韩语),且让小模型和大模型性能差距变小。
但强化学习略微降低了说话人相似度,可能是模型过于关注奖励(如情感)而忽略其他指标。
为增强情感表达,引入了情感识别(SER)作为奖励任务,确实提高了情感表达能力,但可能影响发音。
在难样本(如绕口令、重复词)中提升幅度不如整体测试集。
5.5 Pronunciation Inpainting¶
构建了用于测试中英文多音字/词发音修复能力的数据集。
最优方案(RepMono + MixPhn)在中英文上都达到 100% 修复率。
方法对比如下:
RepAll:考虑所有字符,覆盖广但易引入错误。
RepMono:只替换单音字,训练更准确。
CatPhn vs MixPhn:前者保留原字+拼音,语义更完整;后者只用拼音表示,更需模型理解发音。

Table 13:Corretion Rate of procunciation inpainting.
5.6 Instructed Generation¶
使用 Expresso 和内部数据集测试 CosyVoice 3 在指令式风格生成(如情绪、语速、方言等)上的表现。
相比 CosyVoice 2,CosyVoice 3 的风格相似度提升约 11%,但在 Expresso 集上 WER 略高(因 ASR 对情绪语音识别更难)。
CosyVoice 3 当前只支持情绪、风格等生成,未来将扩展到唱歌和音色编辑。
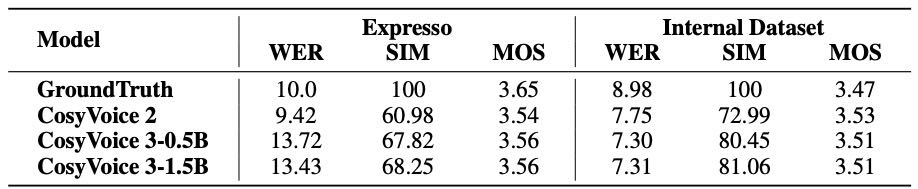
Table 14: Comparison of WER (%), Style Similarity (SIM), and MOS scores across different models for instructed TTS tasks.
5.7 Results on Speaker Fine-tuned Models¶
通过聚类方法找到每位说话人的音色中心,确保个性化微调后音色一致。
提升基础模型和训练数据质量能降低微调模型的错误率,尤其在英文和难样本集上效果明显。
5.8 Results on Turning a Monolingual Speaker into a Polyglot¶
CosyVoice 3 成功让单语说话人支持多语种语音合成,中、英、德、法、西、意、俄等语言的错误率都低于 4%。
日语效果较差(CER 9%),原因是日语文字多音、假名转换易出错;韩语为 6%,未来将补充数据。
6.Conclusion¶
CosyVoice 3 是一个先进的零样本语音合成模型,能在真实环境中表现出色。通过扩大数据和模型规模,它提高了语言覆盖度和合成质量,在内容一致性、说话人相似度和语调自然性方面都达到了很好的效果。模型还引入了新的语音分词器和后训练策略,能更好捕捉语音中的细微特征,并在多个基准测试中表现领先。
7.Limitations¶
但它也有不足,比如目前还不能通过文本控制音色,生成唱歌语音的效果也不够好,这些问题未来可以通过加入更多相关数据来改进。