2407.10759_Qwen2-Audio Technical Report¶
组织: 阿里千问
Abstract¶
Qwen2-Audio 是一个新一代的大型音频语言模型,能处理各种音频输入,并根据语音指令进行分析或直接回应。
它通过自然语言提示来训练,而不是复杂的标签体系,同时扩大了训练数据量。
模型支持两种模式:
语音聊天模式:用户可以纯语音与模型对话,无需输入文字。
音频分析模式:用户可以提供音频和文字指令,模型会进行分析。
无需特定提示词切换模式,模型能自动理解音频内容并正确回应,即使音频中混有多种声音或多说话人。
此外,通过 DPO 技术优化后,模型在事实性和行为控制方面表现更好,在 AIR-Bench 测试中超过了以往的领先模型如 Gemini-1.5-pro。
1. Introduction¶
音频是人与人、人与生物之间重要的交流媒介,包含丰富信息。要实现通用人工智能(AGI),理解各种音频信号是关键。
最近,大音频语言模型(LALM)有了重大进展,能理解各种语音、分析信号并进行复杂推理。
本报告提出了 Qwen2-Audio,一个能处理音频和文本输入、输出文本的大音频语言模型。
它比以往的模型使用了更多数据,并简化了预训练流程,直接用自然语言提示进行训练。
之后,通过指令微调和偏好优化,使模型输出更符合人类偏好。
Qwen2-Audio 有两个模式:
音频分析模式:可分析语音、声音、音乐等各种音频,用户用语音或文字指令都可以,模型能自动识别其中的命令部分。
语音对话模式:像和聊天机器人交流一样进行语音对话,也可以随时切换为文字输入。
比如用户上传一个音频,前半段是打字声,后半段说“这是什么声音?”,模型能正确回答“这是键盘的声音”。
在多个任务上评估结果显示,Qwen2-Audio 即使没有针对某个任务专门微调,也表现优于之前的模型,在一些基准测试上达到了最优水平。
2. Methodology¶
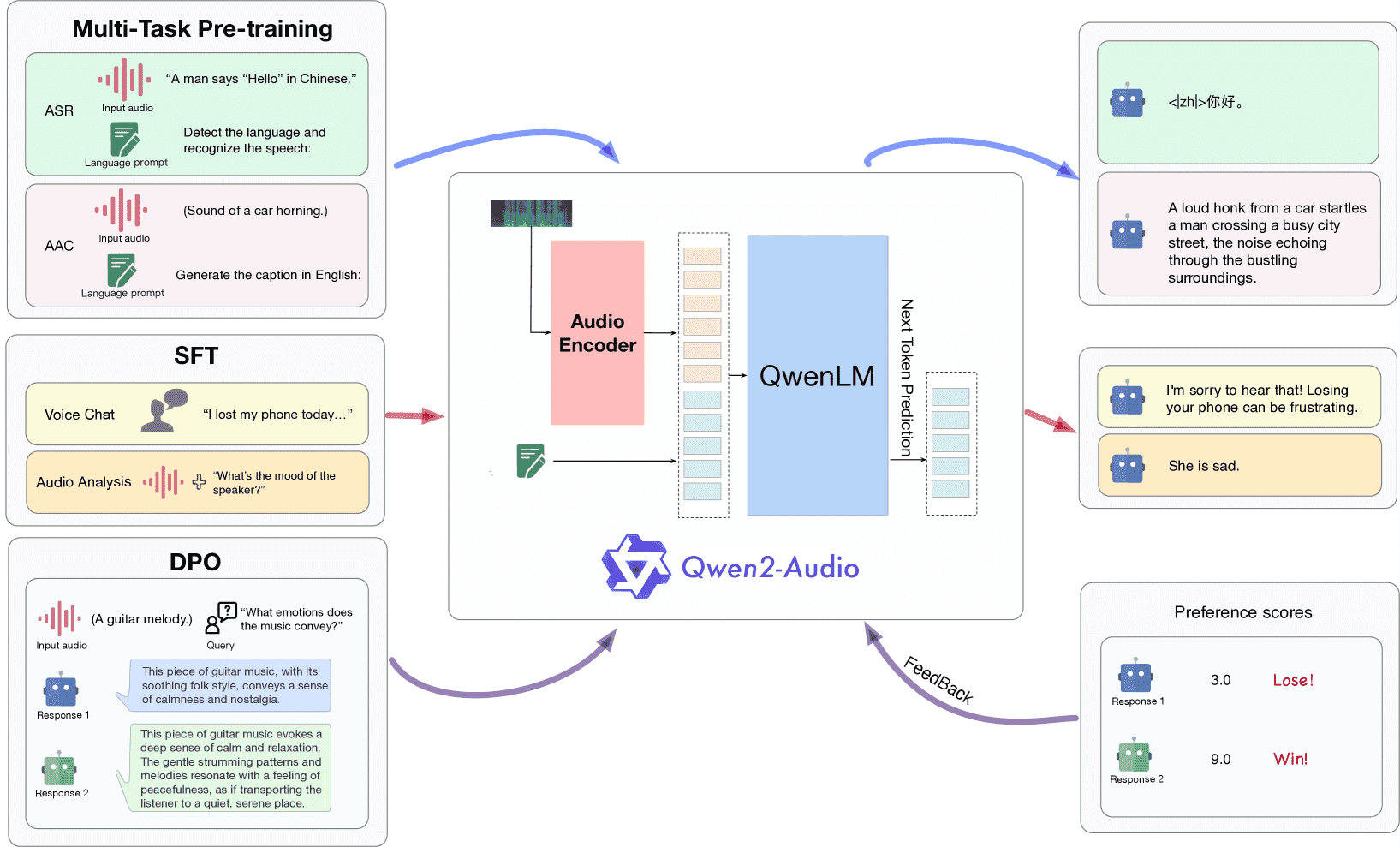
Figure 2:The overview of three-stage training process of Qwen2-Audio.
Model Architecture¶
Qwen2-Audio 包含一个音频编码器(基于 Whisper-large-v3)和一个大语言模型(Qwen-7B)。
训练目标是:根据音频内容和已有文本预测下一个文本 token。
音频处理流程是:
将音频重采样为 16kHz;
转换为 128 维 mel 频谱图(窗长 25ms,跳长 10ms);
加入池化层(stride=2)降低序列长度;
每帧表示约 40ms 音频。
Pre-training¶
使用**自然语言提示(prompts)**代替传统的结构化标签,提高泛化和指令理解能力。
3. 指令微调(SFT)¶
在大规模高质量指令数据上微调,强化模型理解人类意图的能力。
支持两种交互模式:
音频分析模式:支持用户上传音频,进行离线分析;
语音聊天模式:与用户进行语音对话,适用于实时互动。
这两种模式统一训练、无须手动切换。
4. DPO 优化¶
引入 Direct Preference Optimization(DPO) 方法,让模型更符合人类偏好:
输入:音频 + 好/坏两个回答;
优化:倾向选择人类标注的好回答。
3. Experiments¶
1. 评估方法:¶
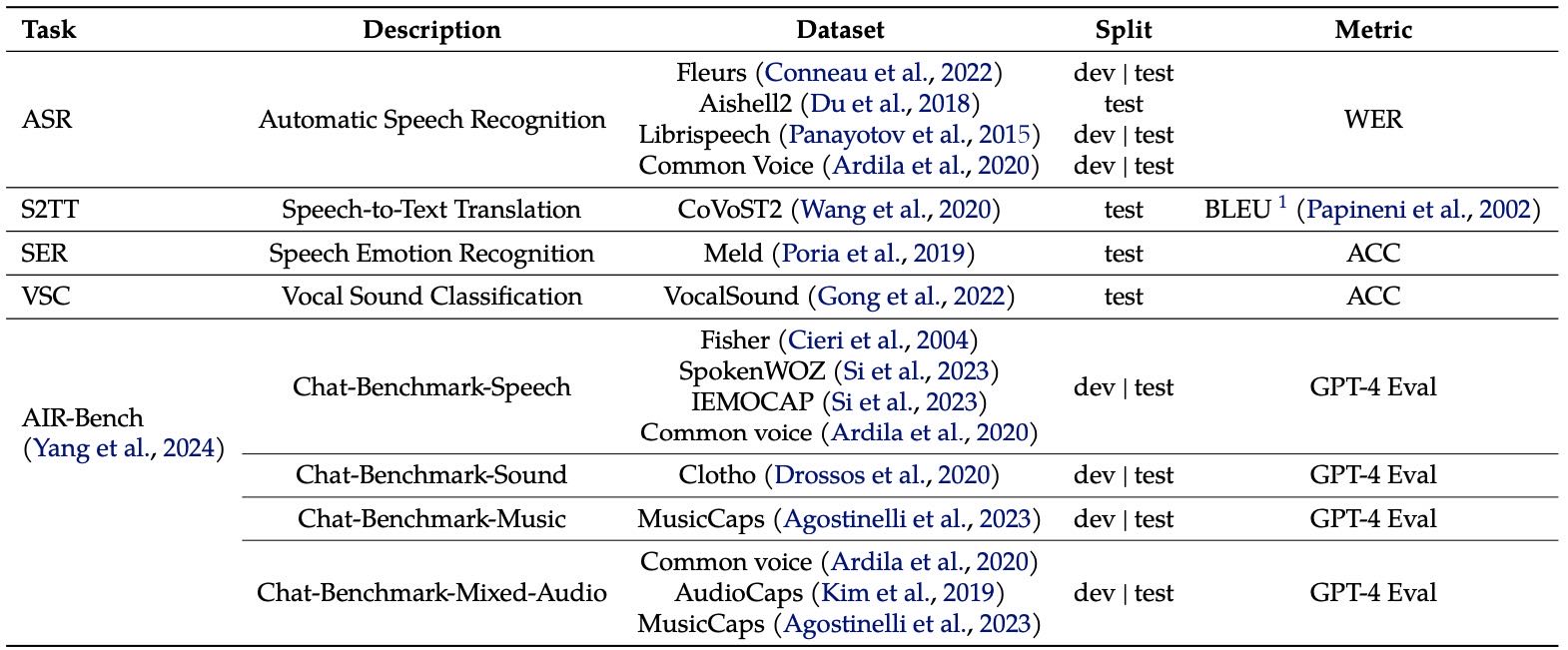
Table 1: Summary of Evaluation Benchmarks for Qwen2-Audio.
以往的测试数据集太简单,不能真实反映模型在实际场景的表现。
本文主要用 AIR-Bench 来评估,因为它更贴近用户真实体验。
同时也在13个数据集上评估了模型在多个任务上的表现,包括:
语音识别(ASR)
语音翻译(S2TT)
情感识别(SER)
声音分类(VSC)
所用评测数据都不包含在训练数据里,避免数据泄漏。
对比了多个开源模型和API模型(如 Gemini)。
2. 主要结果:¶
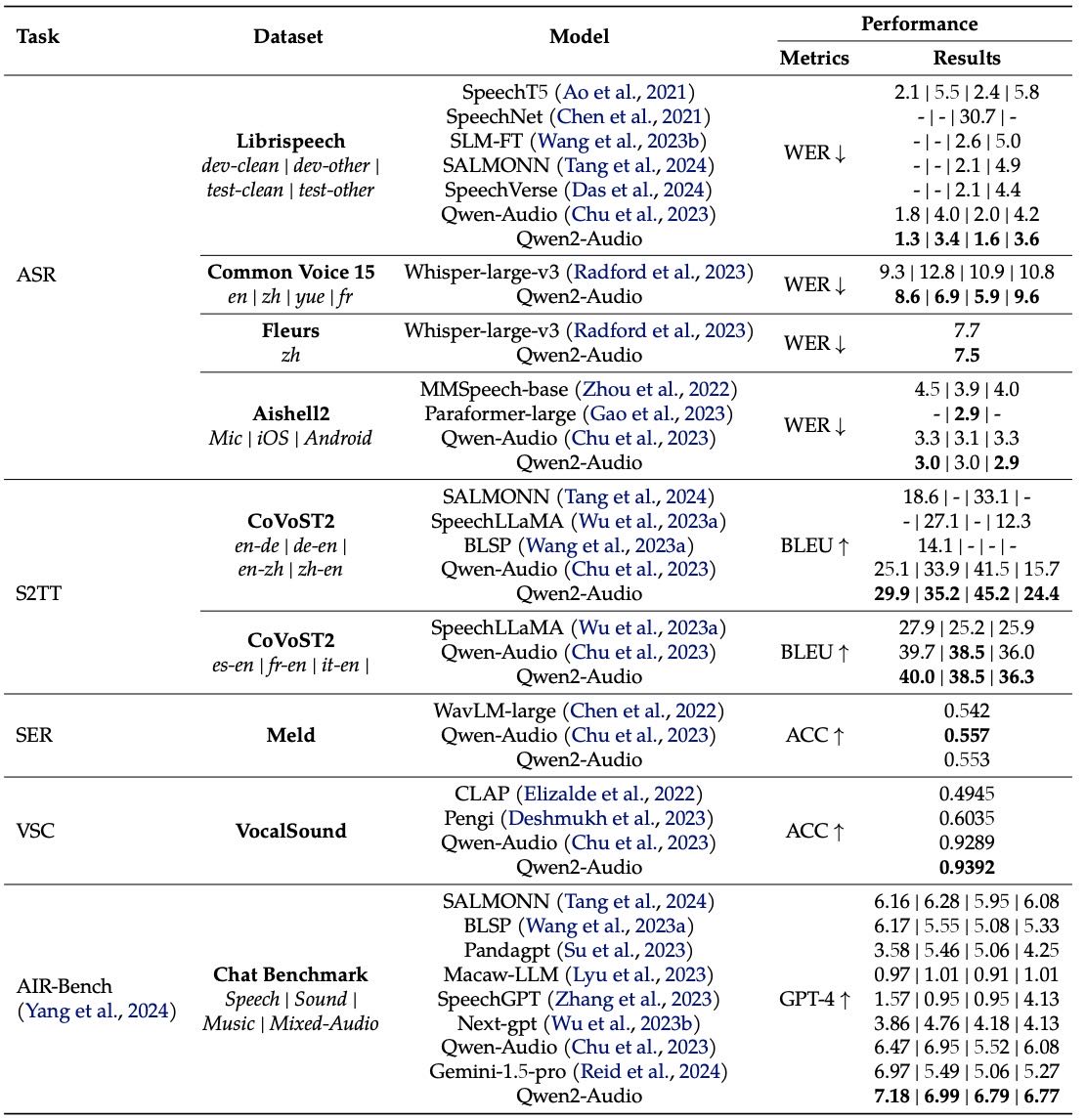
Table 2: The results of Automatic Speech Recognition (ASR), Speech-to-Text Translation (S2TT), Speech Emotion Recognition (SER), Vocal Sound Classification (VSC), and AIR-Bench chat benchmark. Note that for Qwen2-Audio, the results for Fleurs are zero-shot, whereas the results for Common Voice are not zero-shot.
语音识别方面,Qwen2-Audio 表现超过以前的多任务模型:
LibriSpeech 测试集上,识别错误率(WER)为 1.6% 和 3.6%。
中文识别方面,在 Fleurs 数据集上优于 Whisper-large-v3(两者都用零样本测试)。
语音翻译方面,在 CoVoST2 数据集中,在7个翻译方向上都明显领先其他模型。
声音分类任务方面(SER 和 VSC),Qwen2-Audio 也明显优于其他模型。
多模态聊天能力方面,在 AIR-Bench 的聊天子集上表现优异,超越 Qwen-Audio 和其他多模态大模型(LALM)。
5. Conclusion¶
我们提出了 Qwen2-Audio,它在原有 Qwen-Audio 的基础上增强了语音交互能力。
通过扩展预训练数据、优化对齐训练(SFT)和使用 DPO 技术,模型在语音理解和对话方面表现更好。
实验证明它在音频理解和语音对话上都很优秀,实际案例也展示了它流畅灵活的语音交互能力。