2412.15115_Qwen2.5¶
Abstract¶
Qwen2.5 是一系列全新的大语言模型(LLM),在训练前和训练后都做了大幅改进:
预训练阶段:使用了 18 万亿高质量 tokens(之前是 7 万亿),提升了常识、专业知识和推理能力。
后训练阶段:用了超百万条数据做精细微调,还结合了多阶段强化学习(如 DPO 和 GRPO),显著提高了人类偏好适应能力、长文本生成、结构化数据分析和指令跟随能力。
Qwen2.5 提供多种模型配置,参数量从 0.5B 到 72B,支持基础版和指令微调版,还有量化版本,可在 Hugging Face 等平台获取。专有版本如 Qwen2.5-Turbo 和 Qwen2.5-Plus 可通过阿里云使用。
在多个基准测试中,Qwen2.5 表现优异,72B 指令版甚至能媲美 5 倍大小的 LLaMA-3-405B。Turbo 和 Plus 版本也分别接近 GPT-4o-mini 和 GPT-4o 的性能,性价比高。此外,它还被用于训练数学、编程和多模态专用模型。
1. Introduction¶
背景与趋势¶
人工通用智能(AGI)的曙光正在显现,得益于大型语言模型(LLM)的快速发展。
当前技术路径是:大规模预训练 → 精细监督调优(SFT)→ 人类反馈强化学习(RLHF)。
最近在推理能力方面取得突破,如 OpenAI 的 o1 模型,能更好地进行逐步推理和反思。
同时,开源 LLM 的爆发(如 LLaMA、Mistral、Qwen)让更多人能参与研究和应用开发。
Qwen2.5 的发布亮点¶
模型种类更多、更灵活
开源模型涵盖 0.5B 到 72B 共七种规模。
提供原始精度(bfloat16)和多种量化版本。
MoE 模型(Qwen2.5-Turbo、Qwen2.5-Plus)与 GPT-4o-mini 和 GPT-4o 性能接近。
训练数据大幅升级
预训练数据从 7 万亿 tokens 提升至 18 万亿,重点涵盖知识、编程和数学。
微调阶段使用了约 100 万条高质量数据,包括 SFT、DPO 和 GRPO 三种方法。
使用体验大幅提升
生成长度从 2K 提升至 8K tokens。
更好地支持结构化输入/输出(如表格、JSON)。
Qwen2.5-Turbo 支持 最长 100 万 tokens 的上下文。
2. Architecture and Tokenizer¶
Qwen2.5 系列包括两类模型:
开源的稠密模型:如 Qwen2.5-0.5B 到 72B
面向 API 服务的 MoE(专家混合)模型:如 Qwen2.5-Turbo 和 Qwen2.5-Plus
稠密模型结构:¶
基于 Transformer 解码器,关键组件包括:
GQA:提高 KV cache 效率
SwiGLU:非线性激活
RoPE:位置编码
QKV bias 和 RMSNorm:优化注意力机制和训练稳定性
MoE 模型结构:¶
在稠密模型基础上,用多个 FFN 专家和路由机制替代普通 FFN,实现更强性能。
分词器:¶
使用 Qwen 的 BBPE 分词器,词表大小为 151,643。新增了多个控制 token(从 3 个扩展到 22 个),增强了功能一致性和兼容性。

Table 1: Model architecture and license of Qwen2.5 open-weight models.
3. Pre-training¶
1. 预训练数据¶
Qwen2.5 在数据质量上比 Qwen2 提升明显,主要体现在:
更好的数据筛选:用已有模型对训练数据进行评分和多维评估,剔除低质量样本,保留高质量内容。
更强的数学和代码数据:引入专门的数学和编程数据集,让模型在这些任务上表现更好。
更优的合成数据:使用强大的大模型生成高质量的合成数据,并通过奖励模型严格筛选。
更合理的数据配比:减少低质量、重复性强的内容(如电商、娱乐),增加高价值领域(如科技、学术)内容。
数据规模从 Qwen2 的 7 万亿 tokens 增加到 Qwen2.5 的 18 万亿 tokens。
2. 超参数优化(Scaling Laws)¶
建立了一套用于不同模型规模的 超参数缩放规律。
系统研究了模型大小、数据量与学习率、批大小等关键参数的关系。
适用于多种模型结构,包括稠密模型(dense)和专家模型(MoE)。
通过这些规律可以更精确地调参,甚至让小的 MoE 模型达到大模型的性能水平。
3. 长上下文预训练¶
除Qwen2.5-Turbo外,分两阶段训练:先用 4K tokens 的上下文长度,再扩展到 32K tokens(或更长)。
Qwen2.5-Turbo 特别采用了 逐步扩展上下文长度 的训练方式,
分4阶段训练:32,768 tokens, 65,536 tokens, 131,072 tokens, and ultimately 262,144 tokens
使用了两个关键技术来提升长文本能力:
YARN:优化注意力机制。
DCA(双块注意力):提高处理长序列的效率和质量。
效果:最多能处理 100 万 tokens 的输入,同时保持短文本任务的性能不下降。
4. Post-training¶
两大核心改进:¶
更广的监督微调数据覆盖(Expanded Supervised Fine-tuning Data Coverage): 微调数据大大增加,专注补足模型在以下方面的短板:
长文本生成
数学解题
编程能力
指令理解与执行
结构化数据处理
逻辑推理
跨语言能力
系统提示的鲁棒性
双阶段强化学习(RL):
离线RL:解决奖励模型难评估的能力(如推理、事实准确性、指令执行),使用人工+自动筛选高质量数据做正负样本进行DPO训练。
在线RL:强化模型输出质量,确保内容真实、有帮助、简洁、相关、安全、无偏见。使用GRPO算法,优先训练不确定性高的样本。
4.1 Supervised Fine-tuning¶
长文本生成:最长支持8K token,构建专门数据集并用回译(back-translation)、过滤低质数据等手段提升质量。
数学能力:引入多来源链式思维数据,通过奖励模型筛选步骤清晰的推理过程。
编程能力:采集多语言代码任务,自动测试代码正确性。
指令跟随:LLM生成指令+验证代码+单元测试,确保能正确执行指令。
结构化数据理解:强化表格问答、错误纠正等任务,提升结构化信息推理能力。
逻辑推理:7万多样化问题,涵盖各种推理类型,逐步淘汰错误答案提升推理准确性。
跨语言迁移:用翻译模型扩展到低资源语言,保证语义一致。
系统提示鲁棒性:设计多样系统提示并验证模型性能稳定性。
响应过滤:结合打分模型与多Agent系统,严格筛选高质量输出。
4.2 Offline Reinforcement Learning¶
离线RL:专注客观题,如数学、编程等,构造15万对训练样本,使用DPO方法训练。
定义:与在线RL不同,离线RL可以提前准备好训练数据,适用于有“标准答案但难打分”的任务,比如数学、编程、逻辑推理等。
方法:先用已有模型生成多个答案,再通过自动/人工方式筛选出好的答案作为“正样本”,差的答案作为“负样本”,用于DPO(直接偏好优化)训练。
流程:这个过程用了以前的质量控制机制(比如执行反馈、答案匹配),共构建了约15万个训练对,然后用Online Merging Optimizer进行一次epoch的训练。
4.3 Online Reinforcement Learning¶
在线RL:构建奖励模型(根据真实性、有用性、简洁性等打分),再用GRPO优化主模型。训练时优先处理评分波动大的样本,提升学习效率。
目标:进一步提升模型质量,用强化学习优化模型输出,让其更加真实、有用、简洁、相关、安全、无偏。
打分标准:包括真实性、有用性、简洁性、相关性、无害性和去偏见。
数据来源:包括公开数据和复杂的内部查询集,使用不同方法(SFT、DPO、RL)微调后的模型生成回答,并采样不同温度值形成多样性。
训练方法:使用GRPO算法,优先训练那些模型回答差异大的问题(即打分方差高的问题),每个问题采样8个回答,训练批大小为2048。
4.4 Long Context Fine-tuning¶
阶段一:使用32K token以内短指令训练,奠定基础。
阶段二:结合32K短指令与最长262K长指令微调,提升长上下文指令跟随能力。
RL阶段仍只用短指令,因为:
长文本RL训练代价高;
缺乏适用于长文本的奖励模型。
5. Evaluation¶
评估方法¶
评估数据集:使用公开评测数据集(如 MMLU、GSM8K、HumanEval 等)和自建内部数据集,涵盖语言理解、数学、编程、多语言能力等多方面。
防止数据泄漏:通过 n-gram 和最长公共子序列(LCS)比对过滤训练集中的测试数据。
评估方式:主要自动评估,人工干预最少。
5.1 Base Models¶
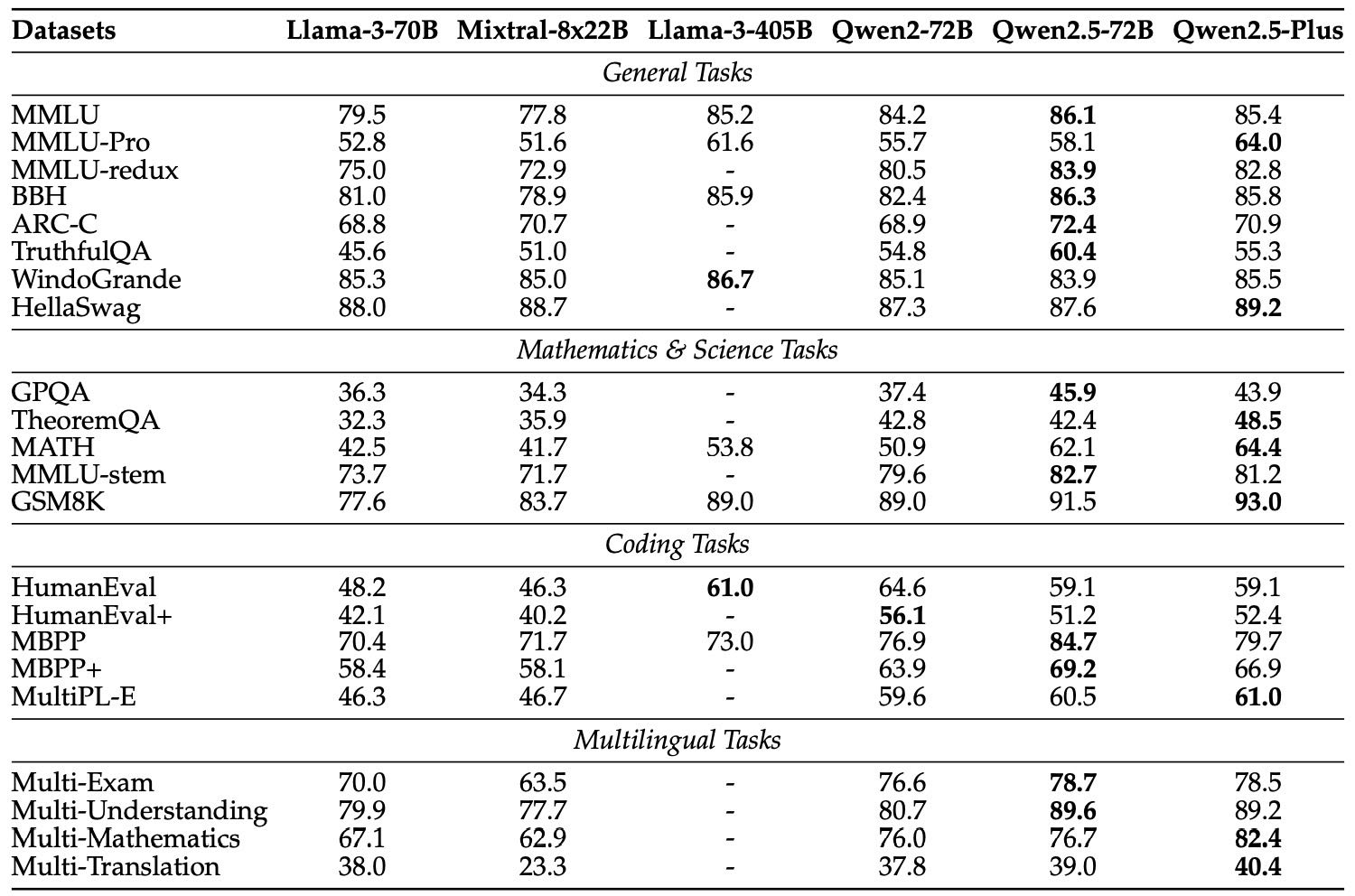
Table 2: Performance of the 70B+ base models and Qwen2.5-Plus.
Qwen2.5-72B:比 LLaMA3-405B 小五倍的参数量,在多数任务上表现相当甚至更好。
Qwen2.5-Plus:成本更低,但在很多任务上甚至超过72B版本,尤其擅长数学、代码、多语言任务。
Qwen2.5-14B/32B/Turbo:在相似大小模型中表现优异,Turbo版本虽然成本低,但效果接近或优于14B。
Qwen2.5-7B:虽然参数较小,但超越多个主流7B模型,如 LLaMA3-8B 和 Gemma2-9B。
Qwen2.5-0.5B/1.5B/3B:体积小但性能强,尤其在边缘设备部署上具备优势,0.5B版本在数学和编程上超过了Gemma2-2.6B。
5.2 Instruction-tuned Model¶
5.2.1 Open Benchmark Evaluation¶
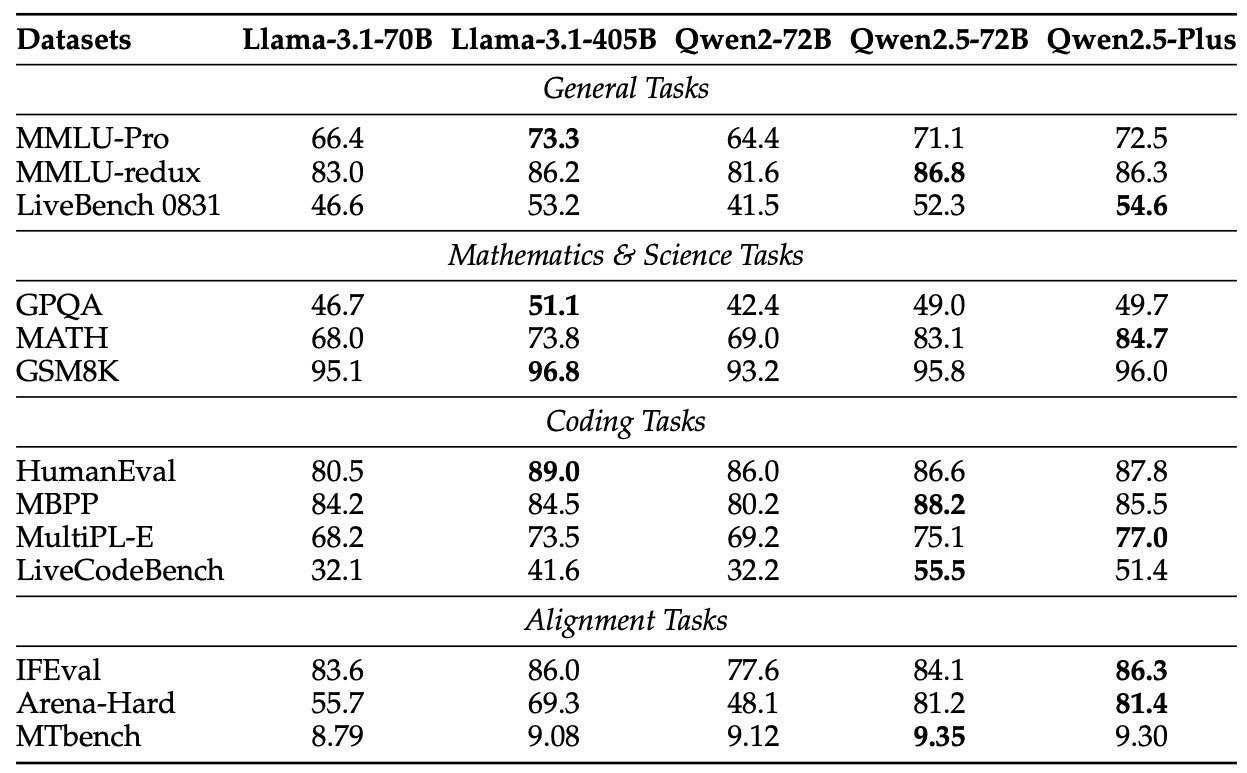
Table 6: Performance of the 70B+ Instruct models and Qwen2.5-Plus.
Qwen2.5-72B-Instruct & Plus:在多个关键任务上超越LLaMA3.1-405B-Instruct;Plus版本在13个测试中有9个胜出。
Qwen2.5-14B/32B-Instruct & Turbo:32B表现优异,Turbo在成本更低的前提下超过14B-Instruct。
Qwen2.5-7B-Instruct:在数学、编程任务上领先Gemma2-9B-IT、LLaMA3.1-8B-Instruct。
Qwen2.5-3B/1.5B/0.5B-Instruct:尽管参数少,数学和编程表现优于Phi3.5-mini和MiniCPM3-4B等模型。
5.2.2 In-house Automatic Evaluation¶
为什么做内部评估:虽然已有一些公开基准,但不能全面评估大模型能力,因此团队开发了自己的评测数据,覆盖知识理解、文本生成、编程等能力,支持中英双语。
中英文表现对比:Qwen2.5 系列模型在中英文任务上整体表现优秀,尤其是在小模型上效率提升显著,如 Qwen2.5-0.5B 表现甚至优于 Qwen2-1.5B;Qwen2.5-72B 接近或超过 GPT-4、Claude3.5-sonnet,表现优于 LLaMA-3.1-405B(除了指令遵循)。
多语言评估:扩展了多个基准测试(如 IFEval、MMLU、MGSM8K),覆盖多种语言(如阿拉伯语、韩语、印尼语等),并用 BLEnD 测试文化细节理解。Qwen2.5 在多语言和数学推理任务上表现与同级别模型相当,文化理解相较上一代有所提升,但仍有进步空间。
5.2.3 奖励模型评估(Reward Model)¶
评估方式:使用多个基准(Reward Bench、RMB、PPE,以及内部中文偏好数据)评估 Qwen2.5 的奖励模型,比较对象包括 Nemotron、LLaMA、Athene 等。
结果总结:
Qwen2.5-RM 在 PPE 和中文人类偏好上表现最佳;
在 RMB 略逊于 Athene,在 Reward Bench 略低于 LLaMA。
重要发现:目前的评估标准(如 Reward Bench)未必能预测实际 RL 模型效果,高分不等于好结果。需要开发更能反映 RL 效果的奖励模型评估方法。
5.2.4 长上下文能力(Long Context Capabilities)¶
评估方法:使用 RULER、LV-Eval、Longbench-Chat 三个基准测试上下文处理能力。
结果:
Qwen2.5-72B-Instruct 长上下文处理能力领先,优于 GPT-4o-mini 和 GPT-4;
Qwen2.5-Turbo 在 100 万 token 的信息检索任务中达到 100% 准确率。
技术优化:通过稀疏注意力机制(基于 Minference)实现推理提速,在处理超长文本时推理效率提升 3.2–4.3 倍。
6. Conclusion¶
Qwen2.5 是一个先进的大语言模型,训练数据达到 18 万亿 tokens,经过精细的微调和多阶段强化学习,提升了模型对人类偏好的理解、长文本生成能力和结构化数据分析能力,非常适合用于执行指令类任务。
它有多个版本,既有开放参数版本(从 0.5B 到 72B),也有更高效的 MoE(专家混合)版本,比如 Qwen2.5-Turbo 和 Qwen2.5-Plus。
实验证明,Qwen2.5-72B-Instruct 的性能可媲美 LLaMA-3-405B-Instruct,尽管参数量小了 6 倍。它还能作为其他专业模型的基础,具有很强的扩展性,适用于科研和工业场景。
未来的计划包括三个方向:
不断优化模型质量,引入更多样、更高质量的数据。
继续研发多模态模型,实现文字、图像、语音的统一处理。
提升模型的推理能力,通过扩大推理计算资源来实现。