2505.09388_Qwen3¶
Abstract¶
Qwen3 是 Qwen 系列最新的大语言模型,涵盖从 0.6B 到 235B 参数规模,包含稠密模型和 MoE 架构。
它的主要创新是将“思考模式”(用于复杂推理)和“非思考模式”(用于快速响应)整合到一个模型中,无需切换不同模型,还能根据任务复杂度动态分配算力资源(即“思考预算”机制),在性能和延迟间取得平衡。
它还通过大模型带小模型的方式,降低了小模型训练成本但保持了高性能。
Qwen3 在多项评测中达到最先进水平,并将多语言支持从 29 种扩展到 119 种,跨语言能力大幅提升。
1. Introduction¶
🌐 背景与动机:¶
人类一直追求通用人工智能(AGI)或超级人工智能(ASI)。
最近的 GPT-4o、Claude 3.7、Gemini 2.5、DeepSeek-V3、Llama-4、Qwen2.5 等大模型已经在这一目标上取得显著进展。
尽管多数顶尖模型是闭源的,但开源社区正在快速缩小差距。
🧠 Qwen3 简介:¶
Qwen3 是一组开源大语言模型(LLM),支持从 0.6B 到 235B 参数的不同规模版本。
核心旗舰型号是 Qwen3-235B-A22B,采用 MoE 架构,每次推理仅激活 22B 参数,兼顾性能与效率。
🔧 核心创新:¶
双模式集成:一个模型同时支持“思考模式”和“非思考模式”,可灵活切换(switch from Qwen2.5 to QwQ)。
思考预算:用户可以精细控制模型的“推理强度”,以节省计算资源。
多语言训练:使用 36 万亿 Token,涵盖 119 种语言或方言,具备强大的多语言能力。
🏗️ 训练流程:¶
三阶段预训练:
通用知识(30T tokens)
知识密集领域(包括: science, technology, engineering, and mathematics (STEM) and coding)
长上下文训练(from 4,096 to 32,768 tokens)
多模态数据采集:调优专门的模型(如: Qwen2.5-VL, Qwen2.5-Math, Qwen2.5-Coder)来提取训练数据,包括数学、代码、PDF 文本等。
四阶段微调:
developing strong reasoning abilities through long chain-of-thought (CoT) cold-start finetuning
reinforcement learning focusing on mathematics and coding tasks
we combine data with and without reasoning paths into a unified dataset for further fine-tuning, enabling the model to handle both types of input effectively,
we then apply generaldomain reinforcement learning to improve performance across a wide range of downstream tasks.
总结:包括链式思维(CoT)、强化学习、无推理数据整合、通用任务对齐。
小模型采用“大带小”的蒸馏策略以提升效果。
📊 性能表现:¶
在多项测试中,Qwen3 系列模型(特别是旗舰版)在数学、编程、Agent任务上表现优异。
例子:Qwen3-235B-A22B 在 AIME 数学测试、代码测试中取得领先成绩。
增加“思考预算”可明显提升模型在复杂任务中的表现。
📘 接下来的内容:¶
文章后续将介绍模型架构细节、训练方法、实验数据和未来方向。
2. Architecture¶
Qwen3 系列包括 6 个稠密模型(如 Qwen3-0.6B 到 Qwen3-32B)和 2 个稀疏 MoE 模型(Qwen3-30B-A3B 和旗舰模型 Qwen3-235B-A22B,其中只有 22B 参数在每次推理中被激活)。
稠密模型的架构与 Qwen2.5 类似,采用了:
GQA 注意力机制
SwiGLU 激活函数
RoPE 位置编码
RMSNorm 归一化
说明:做了一些改进,比如去掉了 QKV-bias,加入 QK-Norm 提升训练稳定性。
MoE 模型在稠密模型基础上引入专家机制,共有 128 个专家,每个 token 激活 8 个专家,取消了 Qwen2.5-MoE 中的共享专家,并使用负载均衡损失提升专家分工能力,从而提升性能。
此外,Qwen3 使用了自研 BBPE 分词器,词表大小为 151,669。
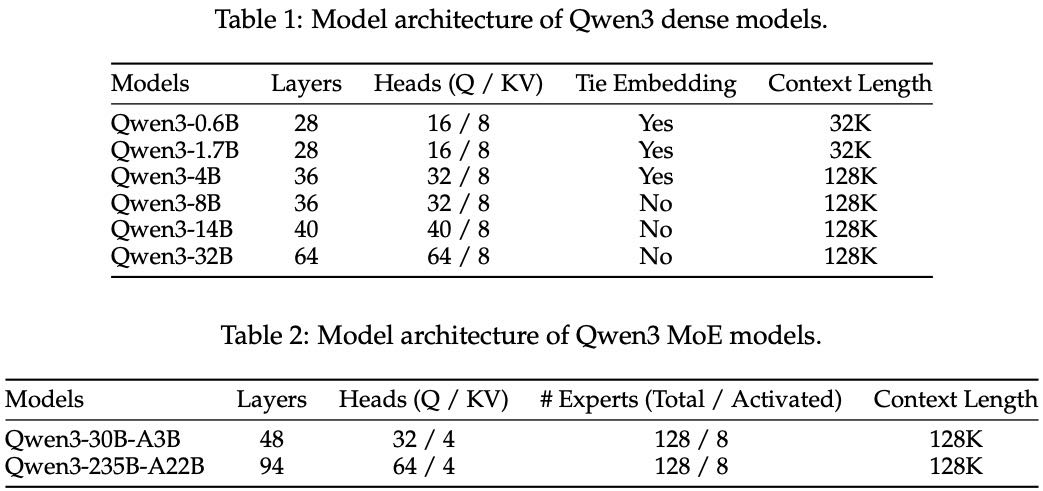
Table 1: Model architecture of Qwen3 dense models. Table 2: Model architecture of Qwen3 MoE models
3. Pre-training¶
3.1 Pre-training Data¶
相比 Qwen2.5,Qwen3 使用了更多、更广泛的训练数据:
总量达 36 万亿 tokens,是 Qwen2.5 的语言数的 2 倍。
涵盖 119 种语言和方言,from 29 to 119
数据包括:代码、STEM、推理任务、图书、多语言文本、合成数据等。
利用 Qwen2.5-VL 从 PDF 文档中提取文本,使用 Qwen2.5 进行质量提升。
使用多个 Qwen2.5 模型生成教材、问答、代码等合成数据。
引入多语言标注系统,为 30 万亿 tokens 添加了细粒度标注(如教育性、安全性等),以更好地筛选和组合训练数据。
3.2 Pre-training Stage¶
预训练分为三个阶段:
通用阶段(S1):训练语言能力与常识知识,长度为 4096 的序列,共 30 万亿 tokens。
推理阶段(S2):提高逻辑推理能力,加入更多 STEM、推理、代码数据,额外训练 5 万亿高质量 tokens。
长文本阶段:扩展模型上下文能力,序列长度达 32768,引入 RoPE 基频扩展(ABF)、YARN 和双块注意力(DCA)等技术。
3.3 Pre-training Evaluation¶
在 15 个通用、数学、代码、多语言任务基准上评估 Qwen3 基座模型:
整体性能优于 Qwen2.5 和其他主流开源模型(如 LLaMA、DeepSeek、Gemma)。
MoE 架构优势明显:
激活参数仅为 dense 模型的 1/5,性能相当。
与 Qwen2.5-MoE 相比,激活参数减少一半以上,性能更好。
小模型表现突出:
Qwen3-8B/4B/1.7B 在多数基准上超过 Qwen2.5 更大模型(如 14B/7B/3B)。
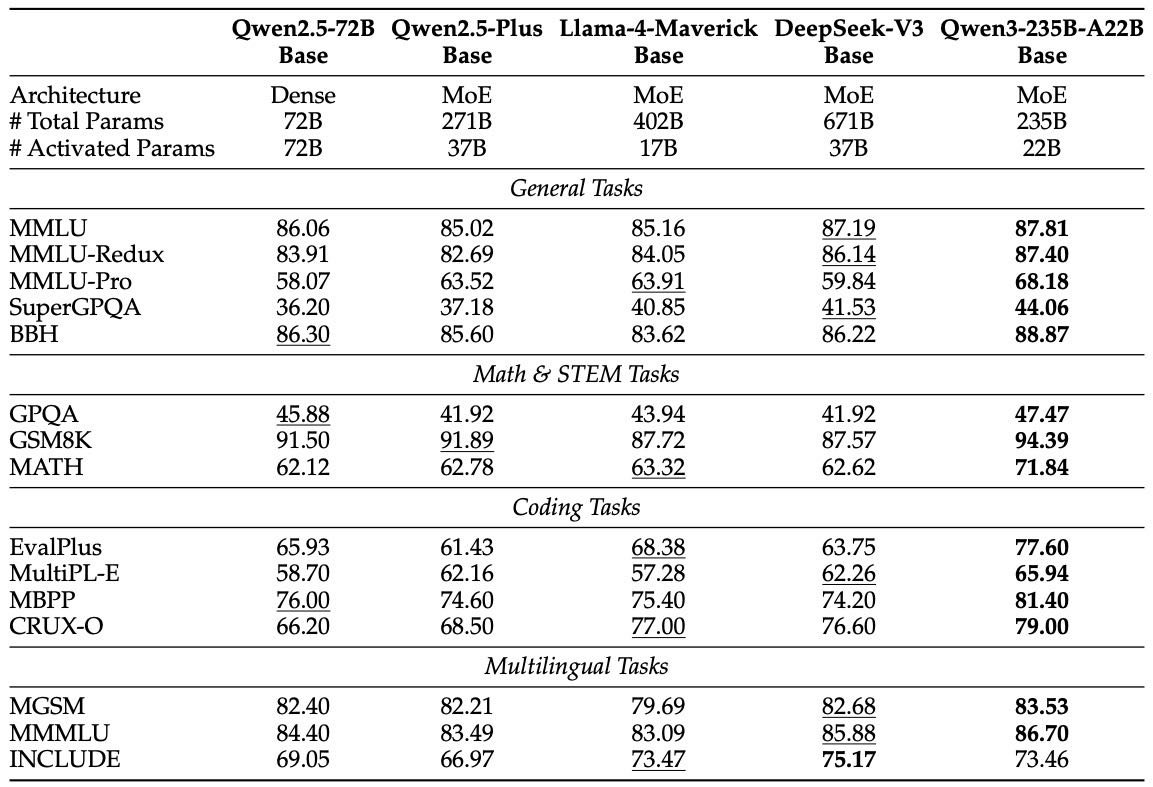
Table 3: Comparison among Qwen3-235B-A22B-Base and other representative strong open-source baselines. The highest, the second-best scores are shown in bold and underlined, respectively.
重点型号性能亮点
Qwen3-235B-A22B(MoE):
性能全面超越 LLaMA4、DeepSeek、Qwen2.5-72B,参数更少、成本更低。
Qwen3-32B(Dense):
超越同类模型(Gemma、Qwen2.5-32B),甚至超过 Qwen2.5-72B。
Qwen3-14B & 30B-A3B:
性能优于 Qwen2.5-14B,与更大模型 Qwen2.5-32B 接近或持平,但成本更低。
Qwen3-8B/4B/1.7B/0.6B:
在中小模型上表现出色,超过 Qwen2.5 更大模型,在边缘设备部署更具优势。
4. Post-training¶
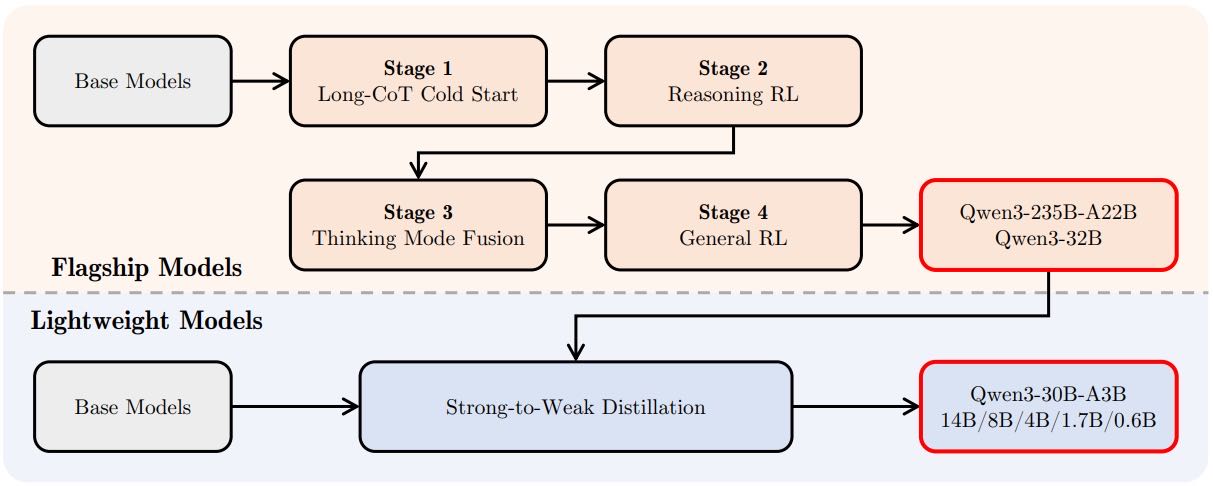
Figure 1: Post-training pipeline of the Qwen3 series models.
Qwen3 后训练分为四个阶段 + 强-弱蒸馏,目标是构建具有可控推理能力、高性能、小模型友好的语言模型。
4.1 Long-CoT Cold Start(基础推理预训练)¶
目标:教授模型基础的链式思维(Chain-of-Thought, CoT)推理模式。
数据准备:
构建高质量数据集,涵盖数学、逻辑、编程等问题,每条数据都有验证过的正确答案或测试用例。
两轮筛选:
查询筛选:剔除不能验证的问题,或无需思维也能答对的问题。
响应筛选:去掉答案错误、重复、猜测、不连贯、风格混乱或与验证集重合的回答。
输出内容:
一个高质量、具有挑战性的推理训练数据集。
一个初步掌握推理结构、但尚未进行强化学习的模型。
能进行 CoT 推理的“思维雏形”。
4.2 Reasoning RL(Reasoning RL)¶
目标:通过强化学习提升模型推理能力,解决更难的问题。
方法:
挑选 3995 条冷启动阶段未用过的问题,确保覆盖广泛子领域且具挑战性。
使用 GRPO 算法进行强化训练,采用大 batch、多个 rollout 增强样本效率。
控制模型熵,稳定探索与收敛过程。
输出内容:
一个强化后的推理模型,推理成功率显著提升。
指标提升,如 AIME’24 成绩从 70.1 → 85.1。
模型具备稳定的“深度思考”能力。

Table 9: Examples of SFT data for thinking and non-thinking modes during the thinking mode fusion stage. For the thinking mode, the /think flag can be omitted since it represents the default behavior. This feature has been implemented in the chat template1 supported by the Hugging Face’s tokenizer, where the thinking mode can be disabled using an additional parameter enable thinking=False.
4.3 Thinking Mode Fusion¶
目标:将“非思维”能力融合进思维模型,使模型可在两种模式间自由切换。
操作方法:
继续监督微调(SFT),融合两个模式的数据。
“思维”数据:使用第二阶段模型生成。
“非思维”数据:任务广泛,覆盖编程、翻译、写作等。
引入 /think 和 /nothink 标记,支持用户指定模式。
默认使用思维模式,但可通过 flag 精确控制。
新增能力:
思维预算控制:当推理超出长度限制,模型可中断并输出当前结论。
格式统一响应结构:即使在非思维模式下也保留
<think></think>块,确保统一。
输出内容:
一个具备双模式能力的统一模型。
支持 token-budget 控制的思维过程。
动态切换响应策略的多功能语言模型。
4.4 General RL¶
目标:让模型在实际使用中更通用、更稳定。
覆盖任务(共20+类):
遵循指令:内容、格式、长度。
格式一致性:比如正确响应 /think 标签。
用户偏好对齐:更自然、有趣、贴近人类。
工具调用能力(Agent):正确执行接口调用,长链任务中更稳定。
特定场景(如RAG):避免幻觉、增强事实准确性。
奖励方式:
规则奖励:准确检测格式/答案正确性。
参考答案评分:通过模型评估参考答案对齐度。
人类偏好模型评分:无需参考答案,通过人类偏好训练的 reward model 给分。
输出内容:
通用能力更强,适应性更高的模型。
在实际使用场景中表现更稳定、更符合用户预期。
4.5 Strong-to-Weak Distillation¶
目标:让小模型继承大模型的思维控制能力和性能。
适用模型:Qwen3 的多个小模型(0.6B、1.7B、4B、8B、14B)以及 MoE 模型 Qwen3-30B-A3B。
① Off-policy
使用大模型在 /think 和 /nothink 模式下生成的数据,训练小模型掌握双模式。
② On-policy
小模型自己生成响应,然后与大模型 logits 对齐(最小化 KL 散度)。
输出内容:
训练高效(无需完整四阶段),推理控制能力完整的小模型。
仅用 1/10 GPU 资源,即可获得媲美四阶段完整流程的性能。
4.6 Post-training Evaluation¶
🧪 一、评估方式¶
Qwen3 模型通过自动基准测试,在“思考模式”和“非思考模式”下分别评估,覆盖以下几个维度:
通用任务:使用 MMLU-Redux、GPQA-Diamond、C-Eval、LiveBench 等测试模型基础能力。
对齐任务:评估模型是否符合人类偏好,包括 IFEval、Arena-Hard、AlignBench、Creative Writing、WritingBench 等。
数学与文本推理:评估数学和逻辑推理能力,使用 MATH-500、AIME、ZebraLogic、AutoLogi 等。
Agent 与编程任务:用 BFCL、LiveCodeBench、Codeforces Elo 等测试模型编程能力和多轮交互能力。
多语言任务:测试模型在不同语言下的指令理解、知识、数学和逻辑推理能力。
评估时还设置不同的采样参数(如 temperature、top-p、output length 等)以区分思考/非思考模式。
📊 二、评估结果总结¶
旗舰模型 Qwen3-235B-A22B:
在思考和非思考模式下都领先于主流开源模型(如 DeepSeek-R1、DeepSeek-V3)。
接近甚至超越 GPT-4o、Gemini2.5-Pro 等闭源强模型。
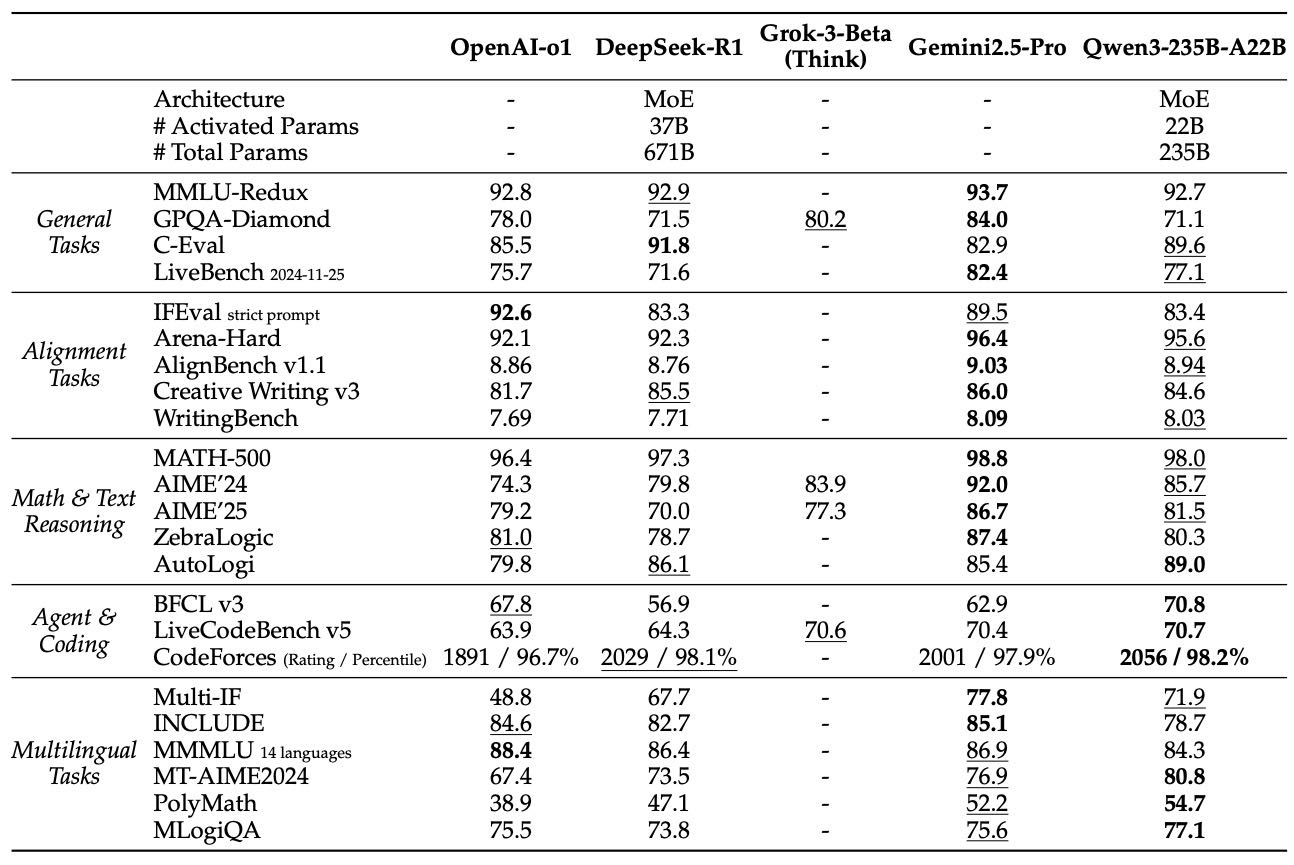
Table 11: Comparison among Qwen3-235B-A22B (Thinking) and other reasoning baselines. The highest and second-best scores are shown in bold and underlined, respectively.
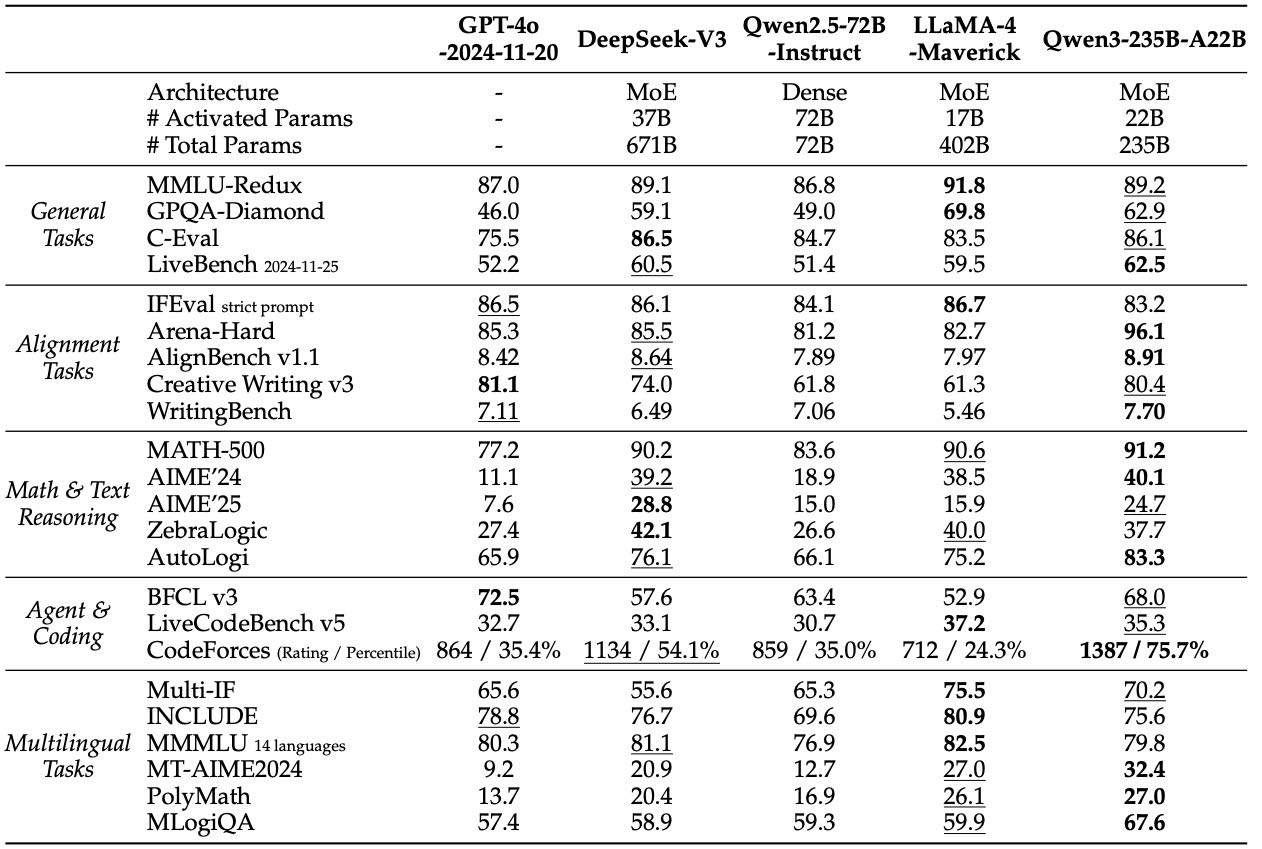
Table 12: Comparison among Qwen3-235B-A22B (Non-thinking) and other non-reasoning baselines. The highest and second-best scores are shown in bold and underlined, respectively
密集模型 Qwen3-32B:
推理能力超过之前的 QwQ-32B,逼近 OpenAI-o3-mini。
非思考模式下也优于 Qwen2.5-72B-Instruct,在多语言、对齐任务等方面表现出色。
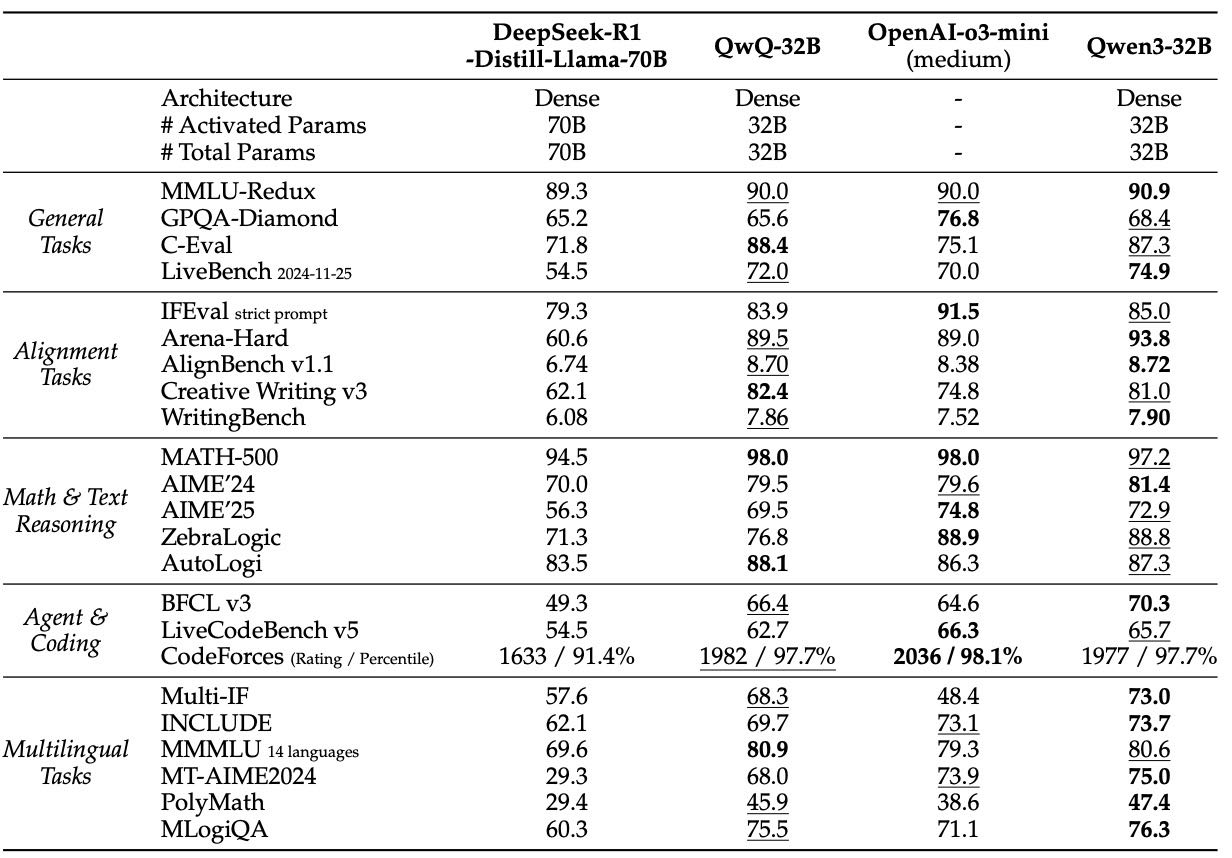
Table 13: Comparison among Qwen3-32B (Thinking) and other reasoning baselines. The highest and second-best scores are shown in bold and underlined, respectively
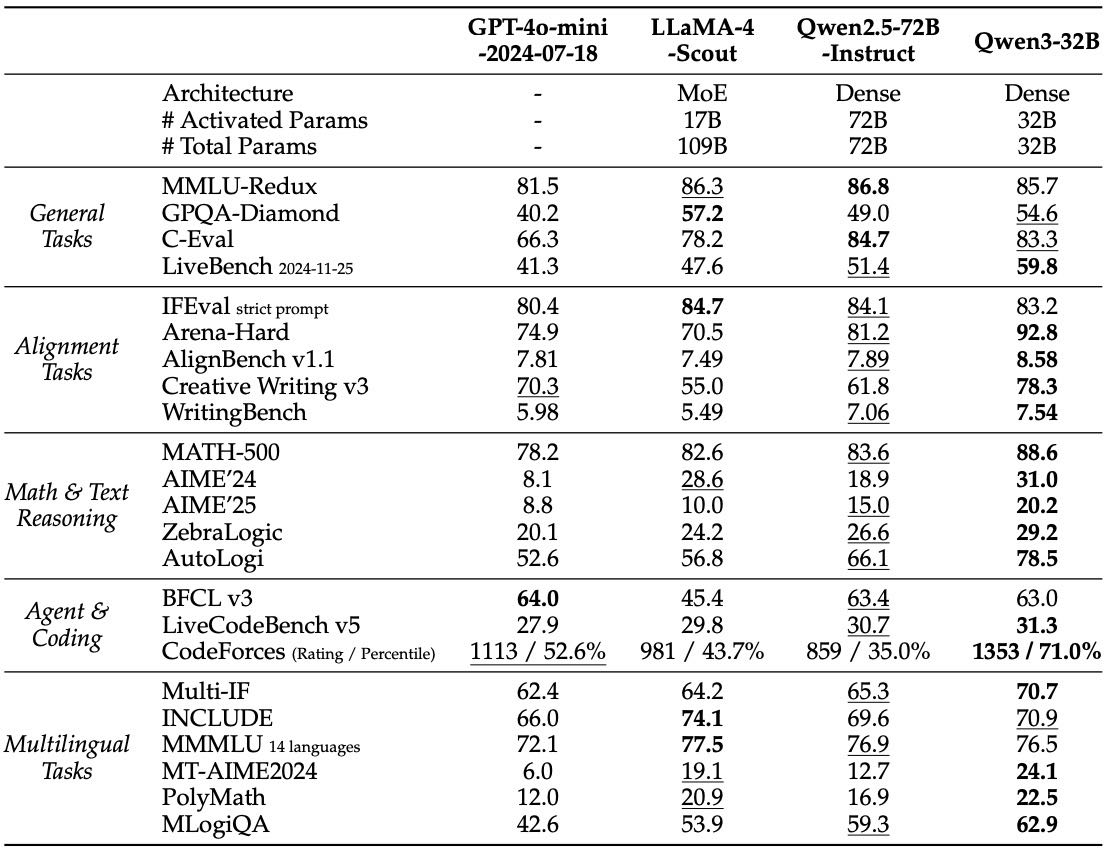
Table 14: Comparison among Qwen3-32B (Non-thinking) and other non-reasoning baselines. The highest and second-best scores are shown in bold and underlined, respectively.
轻量模型(Qwen3-30B-A3B、14B、8B、4B 等):
使用“强监督弱模型蒸馏”策略,即使体积小、参数少,也优于相同或更大参数量的其他模型。
成本低、性能高,适合部署在边缘设备上。
4.7 Discussion¶
The Effectiveness of Thinking Budget(思考预算)
增加模型的“思考预算”(即输出 token 数量)能提升在数学、编程、STEM 领域的表现。
如果输出长度继续扩展到 32K 以上,预计表现还能进一步提升。
The Effectiveness and Efficiency of On-Policy Distillation
与直接使用强化学习相比,从同一个模型出发,通过蒸馏方式训练,性能更好,而且只用了约 1/10 的 GPU 计算资源。
特别是在数学任务中,蒸馏后的模型逻辑能力提升显著。
The Effects of Thinking Mode Fusion and General RL
第三阶段训练(Stage 3):加入了非思考模式后,模型初步具备了在对话中根据提示切换模式的能力,同时提升了指令跟随与创作长度控制能力。
第四阶段训练(Stage 4):进一步提升了模式切换的准确性(ThinkFollow 准确率达 98.9%),并增强了通用任务处理能力。
但在某些高难度任务(如 AIME 和 LiveCodeBench)上性能略有下降,原因可能是模型泛化范围变广,导致专精能力有所牺牲。
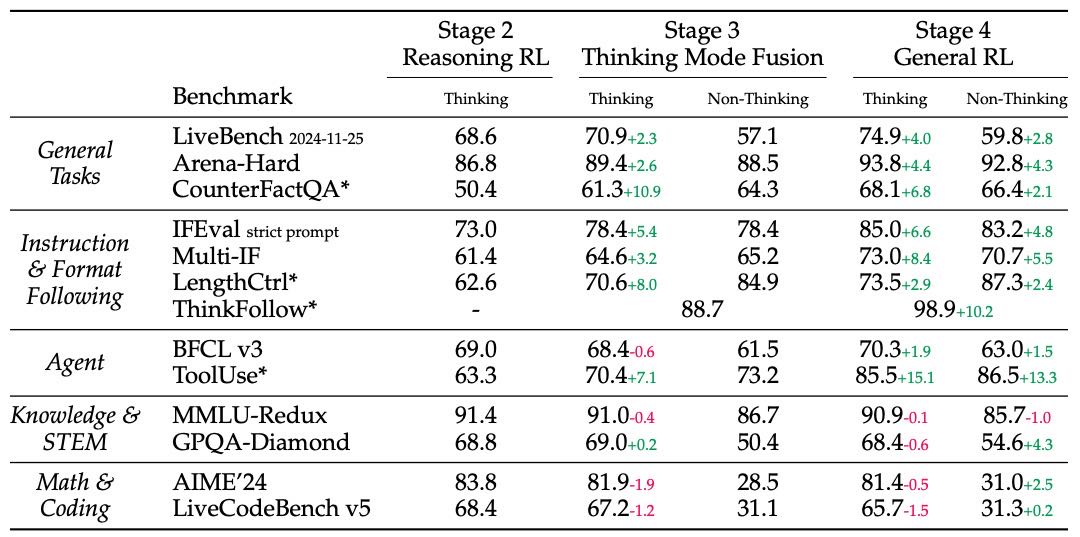
Table 22: Performance of Qwen3-32B after Reasoning RL (Stage 2), Thinking Mode Fusion (Stage 3), and General RL (Stage 4). Benchmarks with * are in-house datasets.
5. Conclusion¶
Qwen3 是 Qwen 系列的最新大模型,支持“思考模式”和“非思考模式”,可以灵活控制复杂任务所需的 token 数量。
它在 36 万亿 token 的大规模数据上预训练,支持 119 种语言,表现优异,尤其在代码生成、数学、推理和智能体任务上效果显著。
未来,团队将重点提升数据质量、优化模型结构与训练方法,实现更高效压缩和支持超长文本。同时,还将增强基于环境反馈的强化学习能力,构建能完成复杂任务的智能体。