0401.xxxxx_ROUGE: A Package for Automatic Evaluation of Summaries¶
PDF2: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/07/was2004.pdf
组织: Information Sciences Institute, University of Southern California
引用: 20772(2025-07-17)
总结¶
ROUGE-L(Longest Common Subsequence)
核心思想
评估自动生成摘要质量的指标之一
通过找出参考摘要与生成摘要之间的最长公共子序列(LCS)来度量它们的相似度。
Abstract¶
ROUGE 是一种用于评估摘要质量的指标,它通过将机器生成的摘要与人工写的理想摘要进行对比,来计算它们之间有多少重合的部分(比如 n-gram、词序列、词对等)。
本文介绍了四种 ROUGE 指标:ROUGE-N、ROUGE-L、ROUGE-W 和 ROUGE-S,其中三种被用于 2004 年 DUC(一个由 NIST 组织的大型摘要评估项目)中。
1.Introduction¶
传统上,摘要的质量是靠人工来评估的,比如看是否连贯、简洁、语法正确、易读、内容完整等。但人工评估很耗时,比如 DUC 比赛中,如果要大规模评估摘要,需要超过 3000 小时的人力,这不现实。
因此,研究者开始关注如何自动评估摘要。
早期的方法包括用余弦相似度、n-gram(如 unigram 或 bigram)重叠、最长公共子序列来比对摘要之间的相似度,但这些方法没验证是否和人工评估一致。
后来借鉴机器翻译中的 BLEU 方法(用 n-gram 统计评估翻译质量),Lin 和 Hovy 提出可以用类似的方式来评估摘要。
于是就有了这个叫 ROUGE 的自动评估工具,它的全称是: > Recall-Oriented Understudy for Gisting Evaluation
ROUGE 包含多种评估方法,用来衡量机器摘要与参考摘要的相似度。
2.ROUGE-N: N-gram Co-Occurrence Statistics¶
ROUGE-N 是一种用于评估自动摘要质量的指标,核心思想是看自动生成的摘要中,有多少 n-gram(连续的n个词) 能在人工参考摘要中找到。
它是一个召回率(Recall):即自动摘要中有多少参考摘要中出现过的 n-gram 被命中了。
公式含义:¶
分子:自动摘要中和参考摘要中共同出现的 n-gram 总数。
分母:参考摘要中所有 n-gram 的总数。
所以它衡量的是:参考摘要中的内容在自动摘要中覆盖了多少。
ROUGE vs BLEU¶
ROUGE-N 看的是“参考中出现的内容,自动摘要有没有提到”(召回)。
BLEU 是翻译评估指标,看的是“自动翻译中提到的内容,在参考翻译中是否也有”(精度)。
多个参考摘要时怎么处理¶
如果有多个参考摘要,会对自动摘要和每一个参考摘要计算 ROUGE-N。
然后取这些分数中的最大值作为最终得分(代表它最接近其中一个参考摘要)。
Jackknifing 技术:¶
假设有 M 个参考摘要:
每次拿 M-1 个当参考,1 个当作要评估的摘要,重复 M 次。
最后取这 M 次结果的平均值。
这样做可以估计人类之间的摘要一致性(即一个人写的摘要和其他人的一致程度)。
总结:¶
备注
ROUGE-N 衡量“自动摘要和人工摘要在词组级别的重合程度”,是召回率导向的;多个参考摘要时,取与任一最相似的那一个的得分,并可用 Jackknifing 估计人类表现。
3.ROUGE-L: Longest Common Subsequence¶
这段内容讲的是 ROUGE-L 指标,它是一种用来衡量两个文本(通常是摘要)相似度的算法,基于 最长公共子序列(LCS) 的概念。
🔹定义:ROUGE-L 是什么?
ROUGE-L 用最长公共子序列(LCS)来衡量两个句子或摘要的相似度。
它关注的是:词语是否按照相同顺序出现,而不要求它们是连续的。
子序列:是从原句中按顺序抽取部分词的序列(中间可以跳过词)。
最长公共子序列(LCS):是两个句子中都出现的最长子序列。
例子:
X: police killed the gunman
Y: police kill the gunman
LCS: police the gunman(长度为3)
3.1 Sentence-Level LCS¶
先计算两个句子的 LCS 长度,然后根据以下公式计算:
Recall (R) = LCS / 参考句长度 Precision (P) = LCS / 候选句长度
F值 = \(\frac{(1+β²)R_{lcs} \cdot P_{lcs}} {R + β²P_{lcs}}\)
通常在 DUC 评测中,β 设为 ∞,表示只关注 Recall(召回率)。
🔹 ROUGE-L 的优点¶
比 n-gram 更灵活:不要求固定长度匹配。
比 unigram 更精细:保留了词语顺序的信息。
例子说明:
参考句 S1: police killed the gunman
候选句 S2: police kill the gunman → ROUGE-L 高(0.75)
LCS = len(police the guman) = 3
候选句长度 = len(police kill the guman) = 4
则: 3/4 = 0.75
候选句 S3: the gunman kill police → ROUGE-L 低(0.5)
LCS = len(the guman) = 2
候选句长度 = len(the gunman kill police) = 4
则: 2/4 = 0.5
虽然 S2 和 S3 的词一样多,但 S2 的顺序更接近参考句,所以分更高。
3.2 Summary-Level LCS¶
对摘要来说,不止一个句子。
所以对每个参考句 r,和所有候选句 c 计算 LCS,并取它们的 “联合” 匹配数(不是最大值)。
1. Recall (召回率):公式 (5)¶
\(r_i\):参考摘要的第 \(i\) 个句子
\(C\):候选摘要(包含多个句子)
\(LCS(r_i, C)\):将参考句 \(r_i\) 与候选摘要中所有句子的 LCS 取并集后得到的 LCS 长度
\(u\):参考摘要中句子的数量
\(m\):参考摘要中的总词数
➡️ 这个公式表示:对所有参考句子的 LCS 长度求和后除以总词数,得到的是 LCS 级别的召回率。
2. Precision (准确率):公式 (6)¶
\(n\):候选摘要(candidate summary)中所有词的总数
➡️ 和召回率类似,但分母换成了候选摘要词数,表示的是 LCS 匹配占候选词总数的比例。
3. F-measure (F分数):公式 (7)¶
\(\beta\):用于调整召回率与准确率权重的因子
实际应用中(如 DUC 评测),通常令 \(\beta \rightarrow \infty\),也就是只考虑召回率
🧪 举例解释¶
给定:
参考句 \(r_i = w_1, w_2, w_3, w_4, w_5\)
候选摘要包含两个句子:
\(c_1 = w_1, w_2, w_6, w_7, w_8\)
\(c_2 = w_1, w_3, w_9, w_5\)
最长公共子序列分别为:
\(r_i\) 和 \(c_1\) 的 LCS 是 \(w_1, w_2\)
\(r_i\) 和 \(c_2\) 的 LCS 是 \(w_1, w_3, w_5\)
联合 LCS 是:\(w_1, w_2, w_3, w_5\)
长度为 4
所以 \(LCS_{\cup}(r_i, C) = 4\)
✅ 总结要点¶
Summary-Level ROUGE-L 是通过联合 LCS 来度量参考摘要与候选摘要的整体相似性。
Recall(召回)更受重视,因为摘要任务倾向于覆盖更多重要信息。
本质上:参考摘要的每个句子与候选摘要中所有句子比对,取出最长公共子序列的并集,统计长度来算得分。
3.3 ROUGE-L vs. Normalized Pairwise LCS¶
计算公式如下:
假设 S1 有 \(m\) 个词,S2 有 \(n\) 个词,由于对称性,公式(8)可以简化为如下形式:
接下来我们定义 MEAD 中使用的 LCS 召回率(\(R_{LCS-MEAD}\))和 LCS 准确率(( P_{LCS-MEAD} \))如下:
我们可以用 \(R_{LCS-MEAD}\) 和 \(P_{LCS-MEAD}\) 将公式(9)重写为如下形式的 F-score,其中参数 \(\beta = 1\):
Sentence-level normalized pairwise LCS 和当 \(\beta = 1\) 时的 ROUGE-L 是相同的。
Summary-level normalized pairwise LCS 和 ROUGE-L 的差别在于:**
ROUGE-L:一个参考句子的 LCS 分数来自于其与候选摘要所有句子的LCS 并集。
归一化成对 LCS:取的是该参考句子在所有候选句中LCS 最大值的那一个。
所以,归一化成对 LCS 更像是“句子之间找最强匹配”,而 ROUGE-L 更像是“多个句子一起联合覆盖参考句”。
ROUGE-L 是 Normalized Pairwise LCS 的一种特殊归一化变体,两者均基于 LCS,但 ROUGE-L 更适合摘要任务中 “候选摘要对参考摘要的覆盖度” 评估,而 Normalized Pairwise LCS 更适合需要对称衡量两个序列相似度的场景(如句子相似度计算)。
4 ROUGE-W: Weighted Longest Common Subsequence¶
核心思想¶
连续匹配的词应该比零散匹配的词得分更高。
ROUGE-L 的问题¶
普通的 LCS(最长公共子序列, 如ROUGE-L)能找出候选句子和参考句子之间的匹配部分,但不区分连续匹配和分散匹配
比如两个句子LCS长度一样,但一个连续匹配、一个分散匹配,其质量应不同。
如:在下面两个候选句中,虽然 Y₁ 连续匹配了 ABCD,但 Y₂ 把它们拆散了,ROUGE-L 给的分数却一样,这不合理。
参考:A B C D E F G
Y₁ :A B C D I H K ← 连续匹配
Y₂ :A H B K C I D M ← 零散匹配
解决方法¶
引入了“加权的LCS”,简称 WLCS,对连续匹配的部分给予更高的权重。
具体方法是用一个二维动态规划表记录每一对词之间的“连续匹配长度”。
具体操作¶
使用一个权重函数
f(k)表示连续匹配长度为 k 的重要性。
权重函数的设计要求:¶
函数 \(f(k)\) 必须满足“连续性加分越来越多”: $\( f(x+y) > f(x) + f(y) \)$
这保证了连续匹配比零散匹配得更多分。
权重函数示例¶
\(f(k) = k^2\):平方函数,连续性加分很明显。
\(f(k) = \alpha k - \beta\):线性函数加惩罚项,模拟间隔造成的损失
\(\alpha k\):每多匹配一个词,增加 \(\alpha\) 分,这表示匹配的“好处”。
\(-\beta\):减去一个固定值,表示非连续匹配的惩罚项,因为你中间有断开(不连续)了,就扣点分
示例
情况1:匹配长度为 3,连续 → \(f(3) = 2×3 - 1 = 5\)
情况2:三个词分散匹配,不连续 → 每次都从 \(k=1\) 开始,三次总共得 \(3×f(1) = 3×(2×1 - 1) = 3\)
说明¶
用一个动态规划表 \(c(i,j)\) 记录得分,另一个表 \(w(i,j)\) 记录连续匹配长度。
每次匹配时,根据连续长度 \(k\) 来给分,使用一个函数 \(f(k)\) 来定义“连续性带来的额外奖励”。
比如连续匹配2个词,就得 \(f(2)-f(1)\) 分;连续3个词,就得 \(f(3)-f(2)\)。
得分计算¶
先求出WLCS得分 \(WLCS(X, Y) = c(m,n)\);
然后用函数的逆函数 \(f^{-1}\) 计算召回率 \(R\)、精确率 \(P\);
公式¶
函数的逆函数来计算召回率、精确率¶
因为 WLCS 的得分是加权的,不是简单地数词的个数了。为了计算“比例”(即召回率和精确率),我们必须把这个“加权得分”还原回词的数量,这样才好与句子长度做比较。
具体逻辑如下:
原来的召回率公式 是: $\( R = \frac{\text{匹配词数}}{\text{参考句子长度}} \)$
这要求分子和分母单位一致,都是“词数”。
但 WLCS 得到的是: $\( \text{加权后的得分} = f(k_1) + f(k_2) + \dots \)$ 这个得分是经过函数放大的,不是“原始词数”。
所以我们要反过来“解码”这个得分,用 \(f^{-1}(\text{得分})\) 来估计它相当于多少个词。
示例
假设:
我们用的是 \(f(k) = k^2\)
WLCS 得分是 25(可能是因为连续匹配了5个词)
那么我们要问:“这个得分等价于连续匹配了多少个词?”
答案是: $\( f^{-1}(25) = \sqrt{25} = 5 \)$
所以我们认为这段匹配相当于5个词,再拿这个“5”去算召回率。
小结¶
Rouge-W 是对 Rouge-L 的改进,更看重连续匹配的质量,通过引入加权函数 \(f(k)\) 来实现。
5.ROUGE-S: Skip-Bigram Co-Occurrence Statistics¶
什么是 Skip-Bigram? 是指句子中任意两个按顺序出现的单词对,中间可以有空格(不一定是连续的)。例如句子 “police killed the gunman” 中就有这些 skip-bigrams:
("police killed", "police the", "police gunman", "killed the", "killed gunman", "the gunman")ROUGE-S 评分方法: 比较候选句和参考句中这些 skip-bigram 的重合程度。 它用 F1 分数来衡量,公式考虑了查全率(Recall)和查准率(Precision),可调节 β 来平衡二者。
优点:
比 BLEU 更灵活,不要求词连在一起;
又比 ROUGE-L 更细,因为它统计所有有序词对,不只是一条最长公共子序列。
可加限制: 为了避免“the the”这种无意义的配对,可以设置跳跃最大距离 d,比如 d=4 表示词对最多隔4个词。
ROUGE-SU:ROUGE-S 的扩展版¶
问题: 有些句子比如 “gunman the killed police” 虽然词顺不同,每个词都在原句中出现,但 skip-bigram 是 0,导致 ROUGE-S 得分为 0。
解决方案: 在 ROUGE-S 基础上加入 unigram(单词)匹配统计,这样即使没有词对匹配,也能通过单词匹配拿到一定分数。这个改进版叫 ROUGE-SU。
总结对比:¶
ROUGE-S 看的是跳跃式词对重合度;
ROUGE-SU = ROUGE-S + 单词重合;
优点: 更灵敏,更合理;
表格展示了各种 ROUGE 指标(R-1, R-2, R-SU 等)与人工评价的相关性。
6 Evaluations of ROUGE¶
目的¶
评估 ROUGE 自动摘要评分指标的有效性,看它是否和人类评分一致。
评估方法¶
数据来源:
使用 DUC(2001~2003)的多种摘要数据,包括单文档、非常短摘要(类似标题)、多文档摘要。
每个系统的摘要都由人类进行评分,作为“真实值”。
评分对比:
计算 ROUGE 得分(17种变体,如 ROUGE-1 到 ROUGE-9、ROUGE-L、ROUGE-S 等)和人类评分之间的相关性。
使用 3 种统计方法:Pearson、Spearman、Kendall 相关系数。
额外变量:
CASE(原始文本)、STEM(词干提取后)、STOP(去停用词)三种预处理方式。
单一 vs 多个参考摘要。
主要发现:¶
单文档摘要(100词):
ROUGE-2、ROUGE-L、ROUGE-W 和 ROUGE-S 表现较好。
去除停用词、词干化对结果影响不大。
多参考摘要略有提升。
单文档极短摘要(10词):
ROUGE-1、ROUGE-L、ROUGE-W、ROUGE-SU 表现好。
ROUGE-N(N > 1)效果差。
去停用词有助于提升结果。
多文档摘要:
ROUGE-1、ROUGE-2、ROUGE-S4/SU4/S9/SU9 表现较好(尤其去停用词时相关性 > 0.70)
ROUGE-L 和 ROUGE-W 效果反而较差
摘要越长,ROUGE 得分与人类一致性越高(200词、400词相关性更高)
样本数量影响稳定性:
单文档样本数量多(>100),结果更稳定
多文档任务样本较少(~30),相关性波动大
结论:¶
ROUGE 各变体在不同摘要任务中的表现有差异。
整体来说:
ROUGE-1、ROUGE-2、ROUGE-L、ROUGE-SU4 是较稳妥的选择;
多个参考摘要、去除停用词可适度提升表现;
数据量充足时(样本多、摘要长)评估更可靠。
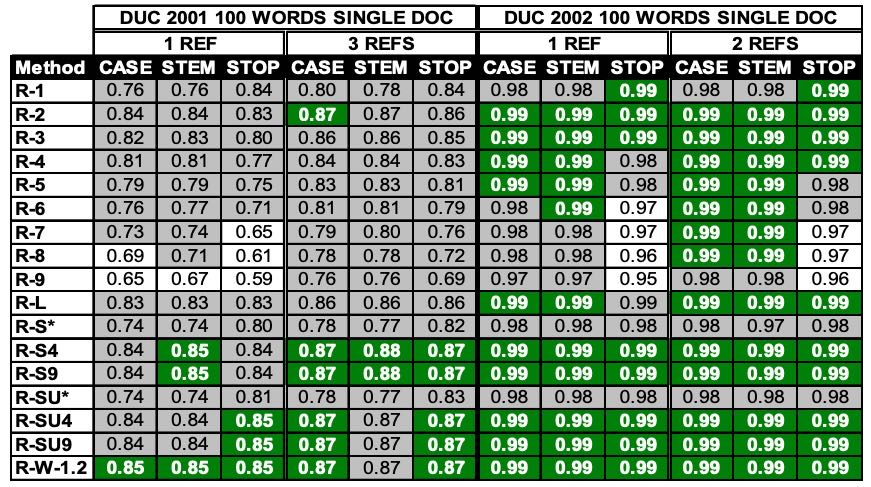
Table 1. Pearson’s correlations of 17 ROUGE measure scores vs. human judgments for the DUC 2001 and 2002 100 words single document summarization tasks.
图片解释
表 1 展示了 DUC 2001 和 DUC 2002 中 100 词单文档摘要数据集上,17 种 ROUGE 指标与人工评分之间的 Pearson 相关系数。每列中表现最好的数值用深色(绿色)标出,与最佳值在统计上相当的数值用灰色标出。
我们发现,在该数据集中,词干还原(stemming)或停用词去除对相关性影响不大;在 ROUGE-N 系列中,ROUGE-2 表现最佳;ROUGE-L、ROUGE-W 和 ROUGE-S 的表现也都较好;使用多个参考摘要虽然带来提升,但提升幅度不大。
在 DUC 2002 数据中,所有 ROUGE 指标与人工评分的相关性都非常高,这可能是由于该数据集中每个系统的样本数量是 DUC 2001 的两倍(DUC 2002 为 295,DUC 2001 为 149)。
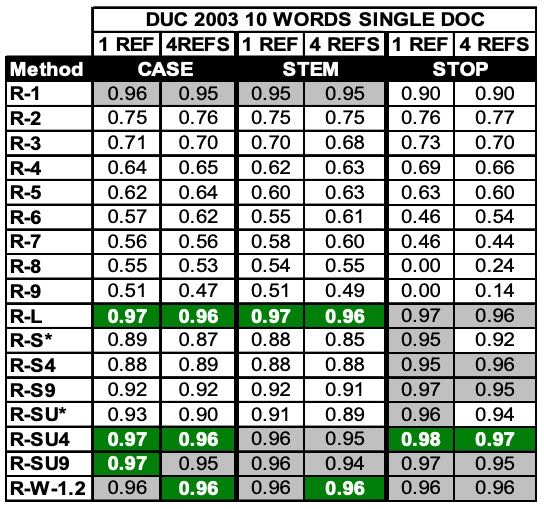
Table 2. Pearson’s correlations of 17 ROUGE measure scores vs. human judgments for the DUC 2003 very short summary task.
图片解释
表 2 展示了 DUC 2003 单文档极短摘要任务的相关性分析结果。
我们发现,在这一任务中,ROUGE-1、ROUGE-L、ROUGE-SU4 和 9,以及 ROUGE-W 是表现非常好的指标;而 N>1 的 ROUGE-N 指标表现显著差于其他指标。
去除停用词总体上能提升性能,但 ROUGE-1 是一个例外。
由于该数据集的样本数量很大(624),使用多个参考摘要并未进一步提高相关性。
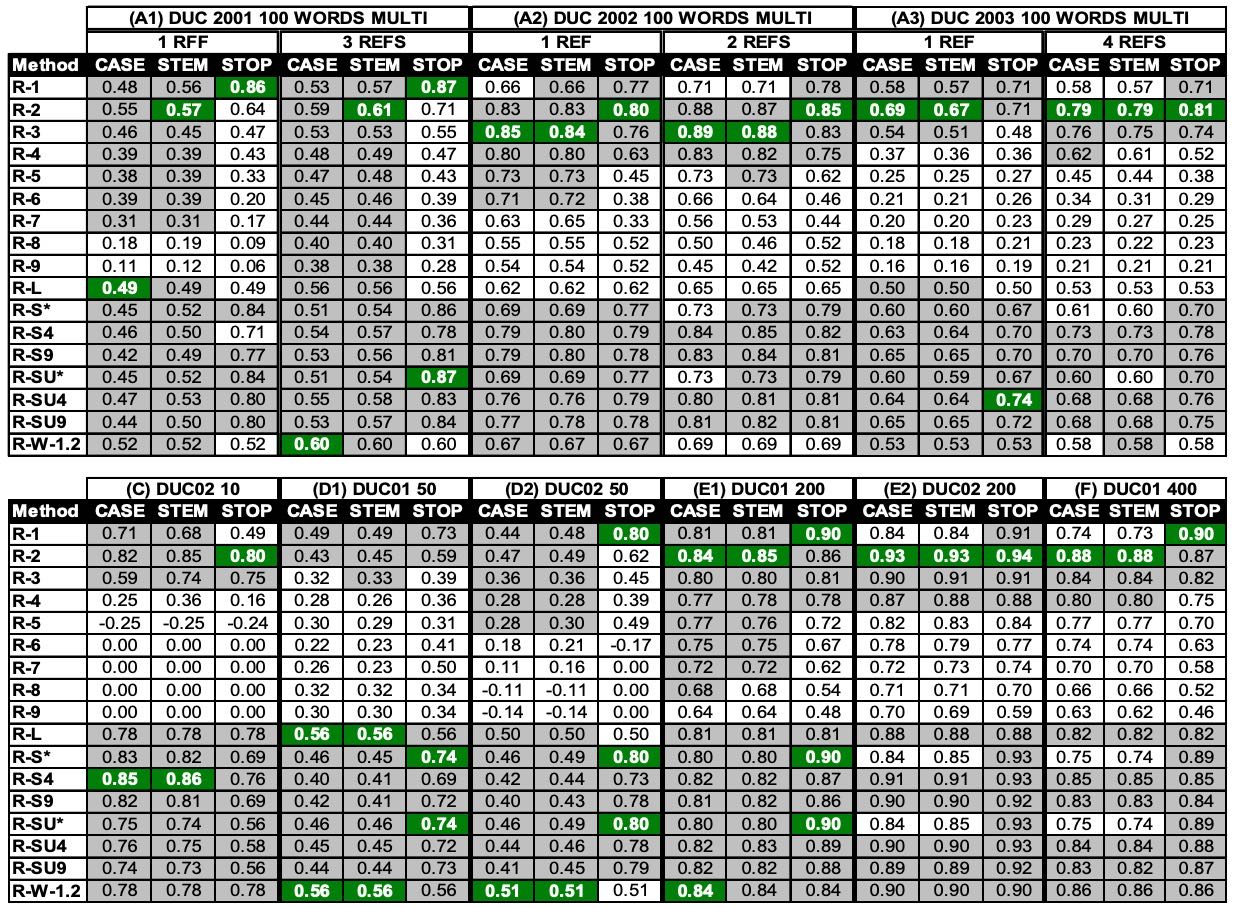
Table 3. Pearson’s correlations of 17 ROUGE measure scores vs. human judgments for the DUC 2001, 2002, and 2003 multi-document summarization tasks.
图片理解
表 3 的 A1、A2 和 A3 展示了在 DUC 2001、2002 和 2003 的 100 词多文档摘要任务上的相关性分析结果。
结果表明,使用多个参考摘要可以提高相关性,而去除停用词通常能提升性能。
ROUGE-1、2 和 3 的表现不错,但不够一致。
ROUGE-1、ROUGE-S4、ROUGE-SU4、ROUGE-S9 和 ROUGE-SU9 在去除停用词的条件下,其相关性都超过了 0.70。
而 ROUGE-L 和 ROUGE-W 在该组数据中表现不佳。
表 3 的 C、D1、D2、E1、E2 和 F 显示了在其余 DUC 数据上,使用多个参考摘要进行的相关性分析。
这些结果再次表明,去除停用词能获得更好的性能,尤其是在50词的多文档摘要任务中。
在长摘要任务中(即 200 和 400 词的摘要),观察到更好的相关性(大于 0.70)。
ROUGE 各评估指标的相对表现趋势,与100词多文档摘要任务中观察到的模式相同。
将表 3 的结果与表 1 和表 2 进行比较,我们发现:除了长摘要任务之外,多文档任务中的相关性值很少能达到 90% 以上。造成这种情况的一个可能原因是:我们在多文档任务中没有足够多的样本。在单文档摘要任务中,我们拥有超过 100 个样本;而在多文档任务中,我们仅有约 30 个样本。唯一拥有超过 30 个样本的任务是 DUC 2002,其在 100 词摘要任务中 ROUGE 指标与人工评估的相关性表现明显更好且更稳定,优于 DUC 2001 和 2003 中的类似任务。由于样本数量不足,系统性能的人工评估可能在统计上不够稳定,从而导致相关性分析的不稳定性。
7 Conclusions¶
本研究介绍了用于自动评估摘要质量的工具 ROUGE,并基于 DUC 三年的数据进行了全面评估。
主要结论如下:
ROUGE-2、ROUGE-L、ROUGE-W 和 ROUGE-S 在单文档摘要任务中效果很好。
ROUGE-1、ROUGE-L、ROUGE-W、ROUGE-SU4 和 ROUGE-SU9 适合评估简短摘要(如标题)。
多文档摘要中很难达到和人工评分高度一致(90%以上)的相关性,但在去除停用词后,ROUGE-1、ROUGE-2、ROUGE-S4、S9、SU4、SU9 表现还不错。
去掉停用词通常能提升评分结果与人工的一致性。
使用多个参考摘要有助于提高和人工评分的相关性。
此外,ROUGE 在机器翻译评估中也很有效,并且在不同数据量下表现稳定。但如何让 ROUGE 在多文档摘要中也能像单文档中那样与人工评分高度一致,仍是未解决的问题。