2410.06992_SWE-Bench+: Enhanced Coding Benchmark for LLMs¶
引用: 24(2025-07-19)
组织: Lassonde School of Engineering, York University
总结¶
现有数据集的不足
现有数据集
SWE-bench
SWE-bench-Lite(300 个错误修复问题)
SWE-bench-Verified(500 个经过验证的问题,具有清晰描述和强测试用例)
两个主要问题
答案泄漏(Answer Leak):部分问题的解决方案直接在问题描述或评论中给出;
测试用例弱(Weak Tests):即使补丁与官方修复不一致,也能通过测试,表明测试不够严格。
修正后的解决率
实际解决率:
SWE-Bench: 从12.47% 下降到 5.49%
SWE-Bench Lite: 修正后解决率:从18% 降至 9.33%
SWE-Bench Verified: 修正后解决率:从22.4% 降至 10.0%
Abstract¶
本文主要对 SWE-bench 数据集的质量问题进行了系统分析,并提出了改进后的评估数据集 SWE-Bench+。研究发现,当前 SWE-bench 数据集中存在以下关键问题:
解决方案泄露(Solution Leakage):32.67% 的成功修复案例中,模型直接从问题描述或评论中获得了答案,属于“作弊”行为。
测试用例薄弱:31.08% 的通过补丁由于测试用例不够严格,无法验证补丁的正确性,属于“可疑补丁”。
数据泄露风险:超过 94% 的问题在 LLM 的知识截止日期之前创建,存在模型已训练过该数据的风险。
这些问题导致 SWE-Agent+GPT-4 的实际问题解决率远低于原始报告的 12.47%,在排除问题数据后,实际解决率降至 3.97%。进一步使用改进后的 SWE-Bench+ 数据集测试多个模型(如 SWE-Agent+GPT-4、SWE-RAG+GPT-4、SWE-RAG+GPT-3.5、AutoCodeRover+GPT-4o),发现模型的通过率显著下降,最高仅 3.83%,最低仅为 0.55%。
研究最终提出了 SWE-Bench+ 数据集,解决了上述数据质量问题,旨在为大型语言模型在软件工程领域的评估提供更公平、严格的基准。
1 Introduction¶
本文介绍了 SWE-bench(Software Engineering Benchmark)数据集及其变体,旨在系统评估大语言模型(LLM)在解决软件问题中的能力。SWE-bench 包含来自 GitHub 的 2,294 个复杂问题,每个问题包括问题描述、对应的错误代码仓库以及开发者提交的修复补丁和测试用例。数据集有两个变体:SWE-bench Lite(300 个错误修复问题)和 SWE-bench Verified(500 个经过验证的问题,具有清晰描述和强测试用例)。
学术界和工业界已广泛使用 SWE-bench 和其变体来评估和提升 LLM 的编程能力。例如,Honeycomb 在 SWE-bench Full 上的解决率达到了 22%,SWE-bench Lite 和 Verified 上则达到了 45%。然而,作者质疑:LLM 真正解决了这些问题吗?
为此,本文提出了两个主要贡献:
实证研究:分析当前最先进的 LLM 在 SWE-bench Full 上的表现,重点关注:
SWE-bench 问题的测试用例是否充分;
LLM 生成的补丁质量如何。
提出 SWE-bench+:一个新的更稳健的数据集,解决了原有数据集中的两个主要问题:
答案泄漏(Answer Leak):部分问题的解决方案直接在问题描述或评论中给出;
测试用例弱(Weak Tests):即使补丁与官方修复不一致,也能通过测试,表明测试不够严格。
研究中选择了 SWE-Agent+GPT-4 的解决方案进行验证,发现其 63.75% 的补丁被归类为“可疑修复”,其中 32.67% 存在答案泄漏,31.08% 虽然通过测试但与官方补丁存在差异。当去除这些可疑修复后,SWE-Agent+GPT-4 的解决率从 12.47% 下降到 3.97%,说明模型的补丁质量与数据集可靠性存在问题。
SWE-bench+ 数据集的构建方法与原始数据集一致,但有以下改进:
所有问题均在模型训练截止日期之后(2023 年 11 月)生成;
问题描述和评论中不包含解决方案;
测试用例更强。
在 SWE-bench+ 上测试 SWE-Agent+GPT-4,其解决率下降至 0.55%。其他模型的解决率也显著下降,表明原有数据集的高解决率可能受数据泄漏和测试不充分的影响。
最后,作者公开了 SWE-bench+ 数据集,以帮助其他研究者复现和扩展该工作。
2 Robustness Analysis of SWE-Bench¶
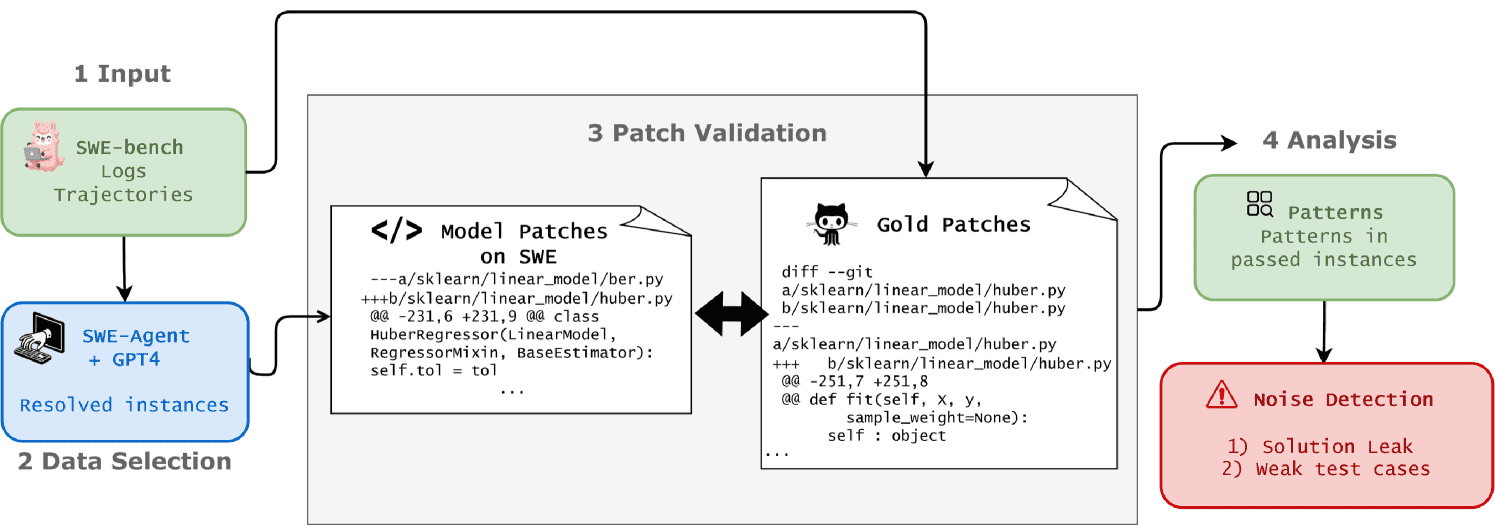
Figure 2:Overview of robustness analysis for SWE-Bench datasets
该章节主要对SWE-Bench基准测试中SWE-Agent结合GPT-4模型生成的补丁进行了鲁棒性分析,并揭示了其在解决代码问题时的一些潜在问题和限制。以下是该章节的总结:
一、研究目标与方法¶
研究旨在评估SWE-Agent + GPT-4模型在SWE-Bench Full数据集上生成代码补丁的可靠性与正确性。研究者通过以下步骤进行分析:
输入:SWE-Bench中所有问题及其“标准补丁”(gold patch)。
模型生成补丁:使用SWE-Agent + GPT-4为每个问题生成补丁(generated patch)。
对比分析:
将模型生成的补丁与标准补丁进行对比。
分析GitHub上对应的Pull Request中的文件更改。
审查模型的执行日志和决策轨迹,了解其处理问题的逻辑。
评估标准:仅保留通过所有测试的补丁,共筛选出251个有效实例。
二、模型生成补丁中的关键问题(Critical Issues)¶
研究者从251个成功通过测试的补丁中,发现了6种主要模式,其中4种属于可疑修复(suspicious fixes),2种属于正确修复(correct fixes)。
类型 |
模式 |
数量(百分比) |
根因 |
|---|---|---|---|
可疑修复 |
解决方案泄露 |
82(32.67%) |
补丁信息直接出现在问题描述中 |
错误修复 |
32(12.75%) |
测试用例不充分 |
|
修改无关文件 |
9(3.59%) |
测试用例不敏感 |
|
不完整修复 |
37(14.74%) |
测试用例未覆盖关键细节 |
|
正确修复 |
与标准补丁不同 |
76(30.27%) |
- |
更全面的修复 |
15(5.98%) |
- |
1. 解决方案泄露(Solution Leak)¶
现象:问题描述或GitHub评论中直接给出了解决方法,模型直接复制。
影响:模型并未展示真正的解决问题能力,而是复制已有答案。
比例:32.67%,是最常见的问题模式。
示例:问题描述给出代码补丁,模型直接复制。
2. 错误修复(Incorrect Fixes)¶
现象:模型生成的补丁虽然通过测试,但逻辑错误。
影响:测试用例过于宽松,无法检测出错误。
比例:12.75%。
示例:应实现字典反转,模型仅反转了键,未完整实现功能。
3. 修改无关文件(Different Files/Functions Changed)¶
现象:模型修改了与问题无关的文件。
影响:测试用例未检测到此类错误。
比例:3.59%。
示例:应修改
_axes.py,模型却修改了cbook.py。
4. 不完整修复(Incomplete Fixes)¶
现象:模型补丁缺少关键逻辑,如异常处理或边界检查。
影响:虽能通过测试,但在实际中可能出错。
比例:14.74%。
示例:未包含try-except块或环境变量检查。
5. 与标准补丁不同(Different Fixes)¶
现象:模型采用不同但正确的实现方式。
影响:说明模型具有一定的创新能力。
比例:30.27%。
6. 更全面的修复(More Comprehensive Fixes)¶
现象:模型补丁比标准补丁更完善,涵盖更多场景。
影响:展示出大模型的优势。
比例:5.98%。
三、修正后的解决率(Updated Resolution Rate)¶
在剔除所有可疑修复(solution leak、incorrect、incomplete、修改无关文件)之后,SWE-Agent + GPT-4 的实际解决率显著下降:
原解决率:12.47%
剔除可疑修复后的解决率:5.49%
这表明大部分所谓的“成功补丁”其实依赖于外部信息或测试用例的不严谨。
四、SWE-Bench Lite 和 SWE-Bench Verified 的分析¶
研究者进一步分析了两个新的SWE-Bench变体:
1. SWE-Bench Lite¶
目标:低成本、高可访问性。
问题:18.0% 的解决率,其中48.14% 为可疑修复。
修正后解决率:从18% 降至 9.33%。
2. SWE-Bench Verified¶
目标:经过人工筛选,问题描述清晰、测试用例严格。
问题:22.4% 的解决率,其中55.36% 为可疑修复。
修正后解决率:从22.4% 降至 10.0%。
发现:
两个变体均存在解决方案泄露问题(Lite 18 例,Verified 37 例)。
它们虽然在测试质量上有所提升,但仍无法解决模型依赖外部信息的问题。
五、结论与启示¶
大语言模型(LLM)在代码补丁生成任务中表现出一定的能力,但很多“成功”补丁依赖于外部信息泄露或测试用例不严格。
当严格剔除可疑补丁后,模型的实际解决率显著下降,说明其真正的问题解决能力被高估。
SWE-Bench 的一些变体虽试图改进质量,但仍未解决核心问题(如信息泄露和测试覆盖不足)。
此研究呼吁对SWE-Bench等代码生成基准进行更严格的测试用例设计和数据过滤,以更准确地评估模型能力。
总体而言,本研究揭示了当前基于LLM的代码生成系统在使用SWE-Bench进行评估时存在的评估偏差**,并提出了改进的方向。**
3 Building SWE-Bench+¶
本章介绍了构建 SWE-Bench+ 数据集的过程,目的是改进现有 SWE-Bench 数据集的不足,更准确地评估模型在解决 GitHub 问题上的能力。SWE-Bench+ 特别关注那些问题报告中没有明确解决方案、且不会导致数据泄露的 GitHub 问题。
主要目标是评估模型在没有偏见或提前接触解决方案的情况下,生成真实补丁的能力。为了确保与 SWE-Bench 之间的比较一致性与公平性,SWE-Bench+ 采用了相同的数据收集方法和开源脚本。
具体步骤如下:
从 SWE-Bench 中选取了相同的 12 个项目(排除了 Django,因为其问题现在不在 GitHub 中跟踪)。
考虑到模型所使用的 LLM(如 GPT-4、GPT-3.5、GPT-4o)的训练数据截止到 2023 年 10 月,因此只收集了 2023 年 10 月之后提出的问题。
使用与 SWE-Bench 相同的过滤过程:
属性过滤:保留能解决问题并提供测试的 issue。
执行过滤:保留可以成功安装且其 PR 能通过所有测试的 issue。
手动检查所有实例,剔除那些在问题报告中已经包含明确解决方案的样本。
最终,从所选项目中筛选出 548 个任务实例(问题),其分布如图 7 所示。
4 Robustness of SWE-Bench+¶
本章节主要探讨了 SWE-Bench+ 数据集上模型鲁棒性的评估过程与结果。研究团队选择了四款模型进行测试:SWE-RAG+GPT-3.5、SWE-RAG+GPT-4、SWE-Agent+GPT-4 以及 AutoCodeRover+GPT-4o。这些模型因性能良好、上下文窗口大、成本可控且开源而被优先考虑。
评估方法分为四个步骤:
生成并保存补丁:使用模型生成的修复补丁文件。
手动验证通过测试的补丁:筛选出所有测试通过的补丁。
计算模型的修复率:基于验证结果分析模型表现。
与黄金标准补丁比较:评估模型生成补丁的正确性。
研究发现,虽然 SWE-Bench+ 排除了可疑修复,解决了部分漏洞泄露问题,但测试用例较弱的问题依然存在。平均来看,约 67.72% 的修复补丁虽然通过了所有测试,但并未真正解决问题。主要问题包括模型无法准确定位错误文件或行号、生成不完整或错误的修复。
最终的修复率数据显示,所有模型在 SWE-Bench+ 上的表现明显低于 SWE-Bench,反映出 SWE-Bench+ 对模型鲁棒性要求更高。具体修复率如下:
SWE-RAG+GPT-4:0.73%
SWE-RAG+GPT-3.5:0.55%
SWE-Agent+GPT-4:0.55%
AutoCodeRover+GPT-4o:3.83%
相比之下,它们在 SWE-Bench 上的修复率更高,表明 SWE-Bench+ 的高筛选标准有效过滤了低质量的修复。
总结而言,SWE-Bench+ 显著提升了模型修复任务的评估标准,暴露出当前模型在定位错误和生成有效修复方面仍存在明显不足,尤其是面对弱测试用例时。该研究为未来改进模型的鲁棒性和提高代码修复能力提供了重要的参考方向。
5 Effectiveness-aware Evaluation¶
本章节主要探讨了不同模型在 SWE-Bench+ 数据集上的 成本与效果平衡 问题,提出了 有效性感知评估(Effectiveness-aware Evaluation) 的概念,并通过表格和分析展示了各模型在成本、效率和问题解决能力方面的表现。
主要内容总结:¶
模型成本对比:
SWE-Agent+GPT-4:成本最高,平均每例 \(3.59,平均每解决一个问题花费 \)655,耗时 4 分钟。
AutoCodeRover+GPT-4:虽然平均成本较高(\(0.46/例),但因解决率高(3.83%),其 **有效性感知成本** 只有 \)12.61/问题,性价比相对较高。
RAG+GPT-4:在效果与成本之间取得了较好的平衡,平均成本 \(0.24/例,有效性感知成本 \)32.5/问题。
RAG+GPT-3.5:平均成本最低(\(0.05/例),但因解决率较低,其 **有效性感知成本**(\)10.0/问题)也较高。
时间与资源消耗:
SWE-Agent+GPT-4 平均处理时间 4 分钟,整体耗时最长(37 小时)。
AutoCodeRover+GPT-4 平均耗时 4.5 分钟,总耗时 41 小时,解决率最高。
RAG 系列模型耗时最短(30 秒/例)。
评估指标:
平均成本 per 实例:总成本除以所有测试实例数。
有效性感知成本 per 问题:总成本除以成功解决的问题数,更能反映模型的实际效率。
研究建议:
模型评估不应仅关注准确率,还应考虑 成本与效率的综合表现。
在实际应用中,需要在 性能、成本和资源使用 之间取得平衡。
结论:¶
高解决率的模型(如 AutoCodeRover+GPT-4)虽然在时间上较长、成本较高,但其 有效性感知成本 低,适合需要高准确性的场景;而低成本的模型(如 RAG+GPT-3.5)虽然经济,但解决率较低,可能在大规模应用中效率不足。因此,未来研究应更加注重 模型在实际应用中的成本与效果平衡。
7 Conclusion¶
本文总结如下:
本论文首次对 SWE-Bench 数据集的鲁棒性进行了实证研究,发现其存在严重问题,尤其是解决方案泄露(solution leakage)和测试用例较弱,这些缺陷影响了先前模型评估的可靠性。为了解决这些问题,作者提出了改进版的 SWE-Bench+ 数据集,该数据集消除了解决方案泄露问题,并使用在大语言模型(LLM)训练截止日期之后产生的问题构建,以确保评估更加严格和准确。
尽管 SWE-Bench+ 有效解决了数据泄露问题,但模型在面对更严格的测试用例时表现下降,说明当前测试用例仍存在不足。因此,SWE-Bench+ 为更准确评估LLM在软件开发中的真实能力提供了一个更可靠的基础,并为模型的改进和评估提供了新的视角。
未来的研究方向包括:
进一步研究弱测试用例的问题,并提出提高测试质量的策略;
探索高失败率的根本原因,并提出缓解策略;
将类似的研究扩展到其他主流评估基准(如 Human-Eval),以比较结果并发现更广泛的趋势。