2506.07982_𝜏²-Bench: Evaluating Conversational Agents in a Dual-Control Environment¶
引用: 0(2025-07-21)
组织: Sierra, University of Toronto & Vector Institute
总结¶
简介
核心创新: 双控环境(Dual-Control Environment)
核心思想: 通过 Dec-POMDP 模型,模拟代理与用户之间的多轮交互
LLM 总结¶
这篇文章提出一个名为 𝜏²-Bench 的评估框架,用于在“双控制环境(Dual-Control Environment)”下评估对话代理(Conversational Agents)的性能。这种环境模拟的是用户与系统之间存在双重控制的交互场景,例如自动驾驶系统中用户和AI系统共同操控车辆,或者在医疗咨询中用户和AI共同做出决策。
文章的主要内容包括:
背景与动机:现有的对话系统评估方法多集中于单向或单控制交互(例如问答、闲聊),而缺乏对多控制、协作性、安全性和责任分配等复杂交互场景的评估。因此,作者提出需要一个更贴合多主体协作场景的评估体系。
𝜏²-Bench 框架设计:
双控制环境建模:设计一个用户与AI系统在决策上相互协作的交互模型,模拟现实世界中多主体交互的复杂性。
任务设置:包含多个任务类型,如决策协调、意图识别、责任划分等,强调对话过程中双方的协作与冲突处理。
评估指标:设计了多维度的评价指标,包括任务完成度、交互质量、协作一致性、安全性等。
实验与分析:
在多个对话系统上进行测试,包括当前主流的对话模型如 GPT-4 和 LLaMA。
实验结果表明,不同模型在双控制场景下的表现差异显著,强调了此类评估框架对模型能力的区分度和指导作用。
同时揭示了模型在责任分配、冲突处理方面的不足,为未来对话系统的改进提供了方向。
贡献与意义:
提出了首个针对“双控制”交互环境的评估框架。
为研究对话代理在协作性、安全性和责任意识等方面的性能提供了基准。
推动对话系统从单一任务响应向更复杂的协作式交互发展。
综上,这篇文章通过构建 𝜏²-Bench,填补了对话系统在多控制交互评估方面的空白,为未来研究和应用提供了新的视角和评估工具。
Abstract¶
本章节介绍了一个名为 τ²-bench 的新基准测试框架,旨在解决现有对话式AI代理基准测试中缺乏“双控环境”(dual-control environment)的问题。现有基准主要模拟单控环境,即只有AI代理可以使用工具与环境交互,用户仅作为被动的信息提供者。而现实场景(如技术支持)中,用户需要主动参与环境状态的改变。为弥补这一差距,τ²-bench 提出了四个主要贡献:
构建了一个新的电信双控领域模型,采用 Dec-POMDP(部分可观测马尔可夫决策过程的去中心化版本)框架,模拟AI代理和用户共同使用工具在共享动态环境中进行协作与沟通;
提出了一个组合任务生成器,可以编程生成多样化且可验证的任务,由基本组件组成,确保领域覆盖全面且复杂度可控;
开发了一个高保真用户模拟器,其行为受到工具和可观测状态的约束,提升了模拟的真实度;
对代理性能进行了细粒度分析,通过多种消融实验区分推理错误和沟通/协调错误的来源。
实验结果表明,当代理从“无用户”环境切换到“双控”环境时,性能显著下降,突显了引导用户行为的挑战性。总体而言,τ²-bench 提供了一个控制良好的测试平台,用于评估AI代理在需要有效推理和用户引导能力的场景中的表现。代码和数据可在提供的GitHub链接中获取。
1 Introduction¶
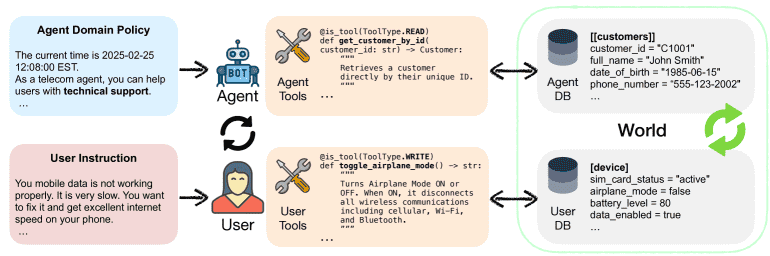
Figure 1:Supporting dual-control environment in \(τ^2\)-bench. The agent have access to a set of tools that interact with a database, and is tasked with resolving the user’s request via Tool-Agent-User (TAU) interactions while adhering to the domain policy. To test real-world scenarios, the user is simulated by another AI agent given a scenario-based instruction and a set of tools that interact with its own database. The simulated user can be regarded as handling an easier version of the TAU interaction in a dual format (Tool-User-Agent), where it only need to follow instructions but does not need to reason about solutions for the task.
这篇文章主要介绍了 τ²-bench,一个新型的对话式AI代理评估基准,重点在于模拟真实世界中用户与AI代理之间的协作场景。以下是对该章节内容的总结:
1. 现有基准的局限性¶
现有的对话AI评估基准(如τ-bench、Tool Sandbox、FlowBench、APIGen)通常属于单控环境,即只有AI代理可以操作工具并完成任务,而用户仅提供目标或偏好信息。这种设计虽然便于任务定义,但缺乏对用户主动参与的模拟,无法反映真实场景中用户与代理之间的双向协作,比如在技术客服中用户需要执行具体操作(如重启手机)来解决问题。
2. τ²-bench的核心创新:双控环境¶
τ²-bench引入了双控环境(Dual-Control Environment),其中:
AI代理和用户(由另一个AI模拟)都可以使用工具,共同操作共享的动态环境。
用户的行为受到环境状态和可用工具的约束,减少对自然语言指令的依赖,提升用户模拟的可靠性和可控性。
通过设计用户工具的输出格式和使用方式,确保用户行为受限,从而保持AI代理在协作中的主导地位。
3. τ²-bench的四大贡献¶
电信领域的双控环境
引入了基于Dec-POMDP框架的电信领域双控环境,模拟真实协作场景,突显代理在协同与沟通方面的能力需求。实验表明,当前最先进的LLM(如GPT-4.1、Claude-3.7-Sonnet)在该环境中任务成功率显著下降(约34%-49%)。组合式任务生成器
通过程序化方法,从少量原子情景中自动生成大量可验证且多样化的任务,支持对任务正确性、复杂度的精确控制,提升评估的灵活性与覆盖度。可靠的用户模拟器
用户模拟器与环境紧密结合,其行为由环境状态和工具可用性决定,使得用户行为更加可预测和稳定。实验表明,用户模拟器的错误率显著降低(16% vs. 40%)。细粒度的代理失败诊断
通过两种模式(自主模式与双控模式)评估代理性能:自主模式下代理独立完成任务,测试其推理能力;
双控模式下代理需要引导用户操作,测试其通信与协调能力。
实验发现,代理在双控模式下任务成功率下降约20%,表明沟通与协作是当前代理能力的主要瓶颈。
总结¶
τ²-bench通过引入双控环境,更真实地模拟了人与AI代理之间的协作过程,揭示了当前对话式AI在通信、协调与引导用户方面的不足。该基准不仅提供了更全面的评估框架,还为未来代理系统的改进指明了方向。
3 \(\tau^{2}\)-bench: Evaluating Agents in a Dual-Control Environment¶
该章节介绍了 τ²-bench,这是一个用于评估对话式AI代理在双控环境(dual-control environment)中表现的平台。其核心思想是通过Decentralized Partially Observable Markov Decision Process (Dec-POMDP) 模型,模拟代理与用户之间的多轮交互。该模型能够捕捉代理与用户协作完成任务(如技术故障排查)的复杂性。
章节总结:¶
3.1 Dec-POMDP 模型描述¶
τ²-bench 使用 Dec-POMDP 框架,定义了两个参与者(代理和用户)之间的交互机制。
模型的核心要素包括:
消息空间(Message space):代理和用户之间交换的自然语言消息。
状态空间(State space):包含整体状态(数据库状态和交互历史),例如代理的CRM数据和用户手机状态。
动作空间(Action spaces):每个参与者可以执行工具调用或发送消息。
观察空间(Observation spaces):参与者接收到的工具输出或对方的消息。
转移函数(Transition function):描述状态随动作变化的方式。
奖励函数(Reward function):对任务是否完成进行全局奖励评估。
指令空间(Instruction space):定义用户模拟的场景与代理需遵守的政策。
模型优势包括:
支持复杂、协作式场景的建模(如技术支持)。
增强用户模拟的可靠性和可控制性。
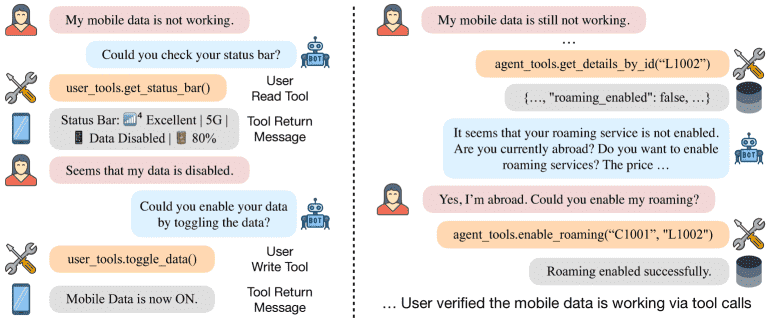
Figure 2:An example agent-user interaction trajectory ( \(𝒮_{history}\) ) of \(τ^2\)-bench in the telecom domain. By controlling the implementation of the user tools (the mocked phone), we can reliably simulate the user’s response to agent’s actionable instructions like “checking the status bar” and “toggling data” based on the underlying database state. On the right half, we show the possibility of modeling the impact of agent’s tool calls on the user’s database state, where the roaming service for the user is enabled on the agent’s end and therefore allows the user’s phone to roam.

Table 1: Key statistics for the \(τ^2\)-bench domains.
3.2 域与任务创建¶
通过多阶段流程构建领域特定材料,以电信领域为例,流程包括:
代理数据库与工具创建:使用大型语言模型(LLM)生成产品需求文档(PRD),并据此创建数据库、工具和单元测试。
用户数据库与工具创建:类似地,定义用户侧的数据库与工具(如模拟手机状态与功能)。
任务生成:通过组合原子子任务生成多样化的任务,每个任务由初始化、解决、断言函数定义。
代理政策生成:基于任务和解决方案,生成领域特定的代理操作政策。
人工优化:提升领域材料的质量。
任务复杂度由子任务数量决定。在电信领域,生成了2285个任务,从中采样114个用于测试。
引入**用户角色(Persona)**机制,支持对用户模拟的差异化设置(如新手或专家用户)。
3.3 任务评估¶
评估任务成功的方式包括多种标准:
数据库检查(DB check):验证数据库状态是否符合预期。
状态断言(Status assertion):通过预定义函数验证任务是否完成。
自然语言断言(Natural language assertion):检查交互历史中是否包含特定内容(如“诊断问题原因”)。
通信信息检查(Communication info check):验证消息是否符合预期。
动作匹配(Action matching):验证交互轨迹中是否执行了所有解决方案函数。
实际中,每个任务可选择适用的评估标准。在电信领域,仅使用状态断言进行评估。
总结¶
τ²-bench 通过构建基于 Dec-POMDP 的交互环境,系统性地评估对话式AI代理在双控场景下的表现。它支持多轮交互、工具调用与自然语言沟通,并通过结构化任务生成与多种评估标准,为代理模型的性能测试提供了灵活且可靠的平台。该平台已在多个领域(如电信、零售、航空)中部署,并支持用户模拟的个性化设置。
4 Experiments¶
本章总结如下:
4 实验¶
本章节详细描述了实验设置与结果,旨在评估对话代理在双控环境(Dual-Control Environment)中的性能。实验涉及四个大型语言模型(gpt-4.1-mini、gpt-4.1、o4-mini、claude-3.7-sonnet)在不同任务和用户模拟器交互中的表现。
4.1 代理设置¶
所有LLM API调用均通过 Litellm 包实现。
评估的模型包括:gpt-4.1-mini-2025-04-14、gpt-4.1-2025-04-14、o4-mini-2025-04-16 和 claude-3-7-sonnet-20250219。
用户模拟器使用 gpt-4.1-2025-04-14 实现。
每个任务运行四次,LLM 温度设为 0 以确保输出确定性。
代理和用户模拟器均以 函数调用代理 的形式实现,工具以 OpenAI 工具格式 提供。
提示词包括通用指南和领域特定策略,具体内容见附录。
成本方面,gpt-4.1-2025-04-14 模型在代理和用户模拟器上的平均成本为每任务 \(0.086 和 \)0.059。运行所有领域(1次任务)的成本约为 $40。
4.2 实验结果¶
Pass^k 指标¶
在验证过的 τ²-bench 领域(零售、航空)和新增的 电信领域 中评估了模型表现。
电信领域表现出 更高的挑战性:gpt-4.1 在电信领域的 Pass^1 降至 34%,相比之下零售和航空分别为 74% 和 56%。
gpt-4.1-mini、o4-mini 和 claude-3.7-sonnet 在电信领域表现更好(Pass^1 约为 50%)。
claude-3.7-sonnet 在电信领域的 Pass^1 表现与航空领域相当,但随着 k 增加,其性能下降更快,说明其在电信任务中的 一致性较低。
消融分析¶
实验了三种配置:
Default:代理与用户协同控制。
No-User:代理完全控制问题解决过程。
Oracle Plan:代理仅需执行已知的工具调用序列。
结果显示:
在 Oracle Plan 模式下,性能优于 Default,说明推理负担是影响性能的关键因素。
从 No-User 切换到 Default 后,Pass^1 显著下降(gpt-4.1 降 18%,o4-mini 降 25%),表明用户参与的双控设置对代理是一个挑战。
No-User 模式下,代理表现更好,但随着任务复杂度增加,性能差距缩小。
政策文档对性能的影响¶
使用更详细的 工作流式政策文档 后:
在 Default 和 No-User 模式下,性能略有提升。
但在 Oracle Plan 模式中,性能反而下降,推测原因是 提供过多信息可能引起干扰。
动作数量和子任务的复杂性影响¶
任务动作越多,代理成功概率越低。
No-User 模式下的性能整体高于 Default 模式,但在动作数增加时差距减小。
gpt-4.1 在动作数较多(10 以上)的场景中表现优于 o4-mini。
子任务数量增加也会导致性能下降,验证了任务设计在复杂度扩展上的有效性。
问题类型的影响¶
电信领域定义了三种问题类型:
service_issue、mobile_data_issue、mms_issue。service_issue最简单,mobile_data_issue和mms_issue更复杂。
复杂问题类型对代理的 多步推理和条件逻辑能力 构成挑战。
不同模型在不同问题类型上的表现不同,例如 claude-3.7-sonnet 在
mobile_data_issue上优于 o4-mini,但在service_issue上表现较差。
用户角色(Persona)的影响¶
Easy 用户角色 下代理表现更好。
No Persona(无角色设定) 的任务表现与 Hard 角色 相当或更差,表明 明确的用户角色设定对代理性能至关重要。
4.3 双控机制对基准可靠性的影¶
双控环境中,用户模拟器质量 是影响基准可靠性的重要因素。
实验通过人工标注用户与代理的交互轨迹,评估用户模拟器行为是否符合任务要求。
错误分类:
关键错误:导致任务无法完成的错误。
非关键错误:不影响任务完成的错误。
用户模拟器质量评估¶
在电信领域中,用户模拟器的错误率显著低于航空和零售领域(电信领域错误率 16%,航空 47%,零售 40%)。
提升的原因包括:
电信领域的 结构化界面 和 明确的操作空间 限制了用户行为。
降低了对自然语言描述的依赖,从而提高了用户模拟器的 稳定性和可预测性。
总结¶
本章通过系统实验验证了多个大型语言模型在双控环境下的表现。结果显示,电信任务更具挑战性,且用户参与显著影响代理性能。通过不同实验设置(如消融分析、用户角色设定、政策文档等)揭示了模型在多步推理、任务复杂性、用户协作等方面的优劣。此外,用户模拟器的质量对实验结果的可靠性也有显著影响,电信领域的结构化设计使其在用户模拟方面表现出更高的稳定性。
5 Conclusion¶
本章总结了τ²-bench的研究结论与未来工作方向。τ²-bench在τ-bench的基础上引入了双控制设置(dual-control setting),发现在需要协调与沟通的任务中,大语言模型(LLMs)性能显著下降,这表明协调与沟通能力是解决用户请求的关键瓶颈,而不仅仅是纯推理能力。
目前,用户模拟器仍有改进空间。虽然已有研究表明通过引入精心设计的工具可以避免关键性错误,但尚未探索这些方法在航空和零售等实际领域的应用。实现这一扩展将有助于构建更通用的高质量用户模拟器。
此外,目前扩展τ²-bench的领域覆盖仍严重依赖人类专家。若该基准方法要在工业界广泛应用并提供标准化评估,亟需研究如何自动化领域构建过程。
最后,τ²-bench的一个重要限制是未明确建模客户支持任务中普遍存在的专家与新手之间的认知差距。未来的研究可以聚焦于评估和提升AI代理在与非专业用户互动时的适应与解释能力,而τ²-bench为此类研究提供了坚实的基础。
Broader Impact¶
本章节探讨了为大型语言模型(LLMs)和人工智能代理(AI agents)建立标准化基准的重要性。标准化基准有助于确保技术发展的社会可控性,促进公平,并为研究者提供透明的评估框架,从而推动领域内的协作与进步。尽管该研究本身可能不会直接带来负面社会影响,但它对现实世界中AI代理的发展具有贡献,而这些代理将在经济和社会层面产生广泛影响。因此,确保AI代理能够安全、有效地与人类用户协作,是其负责任地应用于商业和日常生活中的关键前提。
Appendix¶
附录部分通常包含对正文内容的补充材料,如数据表格、计算公式、参考文献、代码示例或其他支持性内容。由于您提供的“## Appendix”部分没有具体内容,因此无法进行详细总结。
如您能提供附录中的具体文字或材料,我可以帮助您进一步整理和总结。
Appendix A Telecom Domain¶
用户画像(User Persona)¶
定义了两种用户类型,代表不同技术水平和应对问题的能力:
Persona 1(简单用户):
年龄41岁,办公室职员,熟悉常规手机功能。
有中等技术能力,需要清晰的步骤指导。
交互中友好、耐心,愿意确认理解并给予反馈。
Persona 2(困难用户):
年龄64岁,退休人员,仅使用基础功能(打电话、拍照)。
技术知识有限,对复杂术语不理解(如APN、VPN)。
容易焦虑,需要持续安抚,简单操作也可能引发担忧。
总结¶
该章节详细描述了电信领域中任务的构建方式,包括任务分类、动作复杂度、用户画像、示例任务及其解决路径。通过设定两种用户类型和两种交互模式(有用户/无用户),评估对话代理在不同控制环境下的表现,为后续评估模型能力提供了实验基础。
Appendix B Verifying Original \(\tau^{2}\)-bench¶
本章主要围绕验证原始τ²-bench基准的实现和任务设计,旨在确保其一致性、正确性和可验证性,具体总结如下:
B.1 验证实现¶
为减少实现错误,采取了以下措施:
统一工具形式:在所有领域中采用统一的工具形式,确保代理能力表示的一致性。
定义数据模型:每个领域环境都需明确数据模型,以增强结构和可理解性。
引入模拟领域:特设一个用于单元测试的“模拟领域”,用于隔离验证基准的核心功能,便于发现和修复问题。
B.2 验证任务¶
为确保任务的清晰性和正确性,采取了多项改进措施:
结构化任务数据:通过元数据增强任务描述,明确任务目的和所需能力。用户指令结构化为意图、具体指令、已知/未知信息,并引入初始化选项以灵活控制初始状态,同时支持基于共用数据基础的构建。
分类评估标准:将任务评估标准分为四类:
环境断言(检查数据库状态)
通信断言(验证代理传达的信息)
自然语言断言(支持自然语言的细粒度检查,便于调试)
操作断言(确认代理执行的必要动作)
迭代评审过程:基于模拟结果进行迭代评审。每个任务运行一次模拟,评审员可介入修复临时错误,确保模拟完整运行。模拟结果用于检查任务描述是否存在不足、过度或非唯一解等问题,并据此优化任务说明。
程序化任务生成:对于新引入的领域,采用程序化任务生成结合自动验证,从设计上保证任务的正确性。
总结:本章通过统一的实现框架、结构化任务设计、多维度评估标准、迭代评审和自动化生成,系统性地提高了τ²-bench基准的可靠性与可验证性,为后续研究与应用提供了坚实基础。
Appendix C Prompts¶
总结内容:¶
本章节提供了用于构建对话代理系统和用户模拟任务的提示模板。主要分为两部分内容:Agent系统提示和用户系统提示。
C.1 Agent系统提示¶
该部分定义了**客服代理(Agent)**的行为规则和操作方式。其核心内容包括:
功能定位:Agent是一个客户服务中心代表,根据提供的策略(policy)为用户提供帮助。
每轮操作限制:
每次只能执行一个操作:发送消息给用户 或 调用工具。
不允许同时进行消息发送和工具调用。
行为要求:
必须严格遵循策略。
生成的响应必须是合法的JSON格式。
要保持友好、有帮助的语气。
策略来源:具体的策略内容(如不同领域的处理规则)在附录D中定义。
C.2 用户系统提示¶
该部分定义了**用户模拟器(User Simulator)**的行为规则和任务流程。其核心内容包括:
任务目标:模拟用户与客服代理的真实、自然的对话,遵循给定的任务指令。
行为原则:
每次只能执行一个操作:发送消息或调用工具。
不能编造信息,只能依据任务指令提供的信息进行回复。
不能假设工具调用结果,必须基于实际调用结果生成回应。
避免重复指令,应使用自然语言进行表达。
逐步披露信息,在被代理询问后才提供相关信息。
一次只执行一项动作,如果代理要求执行多个动作,必须拒绝并要求分步进行。
工具调用的响应不会显示给代理,只有普通消息会被显示。
任务完成机制:
如果任务目标达成,生成**###STOP###**结束对话。
如果被转接至其他代理,生成**###TRANSFER###**。
如果无法继续对话(如指令信息不全),生成**###OUT-OF-SCOPE###**。
保持角色一致性,确保对话自然流畅。
附:示例任务指令¶
提供了三个不同领域的用户任务示例:
航空领域(airline):
用户想要预定与5月10日相同的航班(从ORD到PHL),并添加一名乘客。
提供了用户的基本信息(姓名、用户ID)和任务要求(座位、支付方式等)。
零售领域(retail):
用户想确认订单W4284542的配送状态,并根据情况取消部分或全部订单。
提供了用户信息(姓名、用户ID、地址),并详细描述了取消与退款流程。
电信领域(telecom):
用户报告移动数据异常,希望修复并获得良好网速。
提供了用户信息(姓名、电话、位置)和操作要求(不更换数据套餐、可接受数据补充)。
总结评价:¶
本章节详细定义了代理系统与用户模拟器的交互规则和行为规范,是构建和评估对话系统的关键指导模板。它强调了真实对话模拟的重要性,同时通过策略控制和任务指令为系统提供了清晰的操作边界与一致性标准。
Appendix D Domain Policies¶
论文章节内容总结¶
本附录讨论了三个主要行业中的代理政策:零售(Retail)、航空(Airline)和电信(Telecom)。这些政策规定了代理在与客户互动时的行为准则,包括允许的操作、所需验证步骤、响应要求以及如何处理特殊情况。
D.1 零售政策(Retail Policy)¶
职责范围:
代理可以帮助用户取消或修改待处理订单、退货或更换已交付订单、修改默认地址、以及提供基本信息(订单、产品、用户档案等)。
身份验证:
在与用户对话开始时,代理需通过电子邮件、姓名+邮编等方式验证用户身份,即使用户已提供用户ID,也必须完成这一步骤。
操作规则:
仅能处理一个用户请求。
所有操作(取消、修改、退货、更换等)必须列出详细信息并获得用户确认。
不可提供未授权的信息或主观评论。
每次操作只允许调用一个工具。
产品与订单信息:
产品有50种类型,每种产品有多种变体。
每个订单有唯一ID、用户ID、地址、订单物品、状态等属性。
退款流程根据支付方式不同,处理时间也不同。
特殊情况处理:
如果请求无法通过代理操作完成,必须转接至人工代理。
D.2 航空政策(Airline Policy)¶
职责范围:
代理可帮助用户预订、修改、取消航班,以及处理退款和赔偿。
操作规则:
修改航班、舱位等操作需用户确认。
每次操作仅调用一个工具,且操作和响应不可同时进行。
必须验证航班状态(如是否已起飞、是否延迟)和用户身份。
退款与赔偿:
退款需返回原始支付方式,具体时间根据支付方式而定。
赔偿仅在用户投诉航班取消、延误等情况时提供,并需确认事实。
不同会员等级和保险情况影响赔偿金额。
行李与保险:
不同会员等级的用户可享受不同的免费行李额度。
旅行保险由用户自主选择,提供全额退款保障。
D.3 电信政策(Telecom Policy)¶
职责范围:
代理可帮助用户处理技术支持、逾期账单支付、线路停用、套餐选项等问题。
操作规则:
每次只执行一个工具调用,不可同时进行操作和响应。
在转接至人工代理前,代理应尽力解决问题。
客户与账单信息:
每个客户有详细档案,包括账户状态、付款方式、线路信息和账单记录。
账单状态分为草稿、已开票、已支付、逾期、等待支付、争议等几种。
线路与套餐管理:
可修改线路状态(如停用或激活)。
每个套餐有数据上限和价格,用户可升级或变更套餐。
可通过“数据加油”功能增加数据使用额度。
技术支持:
需先验证客户身份,然后提供技术支持。
总结¶
本附录详细描述了零售、航空和电信行业中代理应遵循的政策与操作规范。这些政策强调了代理在客户互动中的职责边界、身份验证的重要性、操作的合规性以及特殊情况的处理流程。通过这些规定,确保了代理在提供服务时的行为一致性和客户体验的可靠性。
Appendix E User Simulator Quality¶
本附录总结了用于模拟用户行为的对话系统在不同场景(零售、航空、电信)中出现的主要错误类型和失败模式,以及一些典型案例分析。
E.1 零售领域常见错误类型与失败模式¶
对零售领域20个标注错误的分析发现,主要错误类型包括:
对话结构规则违反(11/20):违反轮流或对话流程,如在同一轮混合工具调用和自然语言。
提前终止(3/20):用户在确认后立即终止对话(###STOP###),导致代理无法完成交易。
无依据的引用(2/20):引用了未提及的上下文细节,如支付方式或订单状态。
缺少约束(4/20):遗漏了必要的指示,如在所需颜色不可用时未请求替代SKU。
其中,提前终止和缺少约束是任务关键错误,而对话结构错误和无依据引用通常对任务影响较小,代理可恢复处理。
E.2 航空领域常见错误类型与失败模式¶
航空领域47个标注错误的分析显示:
缺少约束(11/47)
对话结构规则违反(19/47)
无依据的引用(15/47)
提前终止(2/47)
同样,缺少约束是主要任务关键错误。
E.3 电信领域常见错误类型与失败模式¶
电信领域8个错误全部为提前终止(8/8),用户在代理调用转接工具前就发出###TRANSFER###,这只有在导致任务失败时才是关键错误。
E.4 代表性案例¶
零售任务关键错误(提前终止):用户在确认订单修改后立即终止对话,导致代理无法执行修改并生成收据。
航空任务关键错误(缺少约束):用户应要求转接人工客服,却继续进行预订,违反了任务目标。
电信任务关键错误(提前终止):用户在代理完成转接前就发出###TRANSFER###,可能影响问题解决流程。
总结¶
在不同领域中,用户模拟器的主要失败模式包括对话结构规则违反、提前终止、缺少约束和无依据引用。其中,缺少约束和提前终止是影响任务完成的关键问题。而结构错误和无依据引用通常可被代理恢复。这些发现有助于改进用户模拟器的设计,提高对话系统的鲁棒性与任务完成率。