2501.14249_HLE: Humanity’s Last Exam¶
作者: 1 Center for AI Safety, 2Scale AI
引用(81, 2025-06-26)
官网:
Abstract¶
现有的大语言模型(LLM)进步很快,已经能在很多主流测试(如 MMLU)中拿到超过 90% 的高分,导致这些测试已经不足以准确评估模型能力。
为此,研究者提出了一个新的测试集,叫做 Humanity’s Last Exam(HLE),这是一个多模态、覆盖广泛学科的高难度题库,目的是成为最后一个封闭式学术测试。
HLE 包含 2500 道选择题和简答题,涵盖数学、人文、自然科学等领域,由全球专家设计,题目标准明确,但不能通过简单搜索得出答案。
现有最先进的模型在这个测试中表现不佳,说明它们与专家水平还有较大差距。
1.Introduction¶
近年来,大语言模型(LLM)的能力大幅提升,在很多任务上超过了人类。但原有的评测题库(如 MMLU)已经“被做穿了”,准确率超过90%,不再能有效区分模型水平。
为此,研究者推出了一个新题库:“人类最后的考试(HLE)”,包含 2500 道超高难度的题目,覆盖多个学科。题目经过专家设计,不容易被网络搜索或简单查库解决,有些还是图文混合的。
每道题都要通过测试,确保最先进的模型答不出来,才会被收录。之后还要经过多轮专家评审,确保题目质量。
评测结果显示,当前的最强模型在 HLE 上准确率很低,还常常自信地给出错误答案,说明和人类专家之间仍有很大差距。
这个题库的目标,是为 AI 能力的进一步发展提供一个更严格、更有挑战性的评测标准。部分题库公开,供大家研究和比较模型性能。

Figure 2:Samples of the diverse and challenging questions submitted to Humanity’s Last Exam.

Figure 3:HLE consists of 2,500 exam questions in over a hundred subjects, grouped into high level categories here
3.Dataset¶
以下是这段内容的简洁版解释:
数据集简介¶
HLE(Humanity’s Last Exam) 是一个包含 2500 道高难度题目 的数据集,覆盖 100 多个学科,用于测试大语言模型(LLM)的极限。题目公开发布,但保留了一部分未公开题目用于检测模型是否过拟合。
题目来源¶
来自 全球 50 个国家、500 多个机构的 1000 名专家,大多是教授、研究人员或研究生学历者。
题目类型¶
包括两种格式:
精确匹配题:要求模型输出一个精确的答案。
多选题:模型从多个选项中选择一个答案。
14% 的题目包含图文内容。
24% 为多选题,剩下为精确匹配题。
每题都包含:题目正文、答案说明、解题思路、所属学科、作者姓名和机构。
提交要求¶
问题必须原创、明确、非搜索引擎可查,避免让模型靠记忆答题。
内容需专业、逻辑清晰,答案应唯一可验证。
禁止主观、开放式、涉及大规模杀伤性武器的问题。
每题都附详细解答说明。
回答错误但模型猜对的题目,需改进以防“误猜得分”。
奖励机制¶
总奖金 50 万美元:
前 50 道最佳题目各得 $5000。
接下来的 500 道题各得 $500。
所有被采纳题目的作者可成为论文合作者,吸引了高质量专家参与。
评审流程¶
初筛: 用多个顶级大模型测试题目,只有模型答错的才进入下一轮。
总共测试了 7 万次,最终约 1.3 万道题被送交人工审核。
人工评审:
所有评审人员都有硕士以上学历。
两轮评审流程,评估标准化,逐步精炼题目,最终筛选出优秀题目组成正式数据集。
4.Evaluation¶
📌 研究目的¶
作者评估了当前先进的大模型(LLMs)在 HLE 数据集(一个高难度的闭卷考试题库)上的表现,分析它们在不同问题类型和领域下的能力。
🧪 4.1 评估方法(Setup)¶
使用统一的提示词,要求模型先推理再作答。
用 o3-mini 模型作为“裁判”来判断答案是否正确。
接受格式上的合理差异(如小数 vs 分数)。
没有把“靠猜答对”的题目去掉,以保持数据的真实性。
📊 4.2 量化结果(Quantitative Results)¶
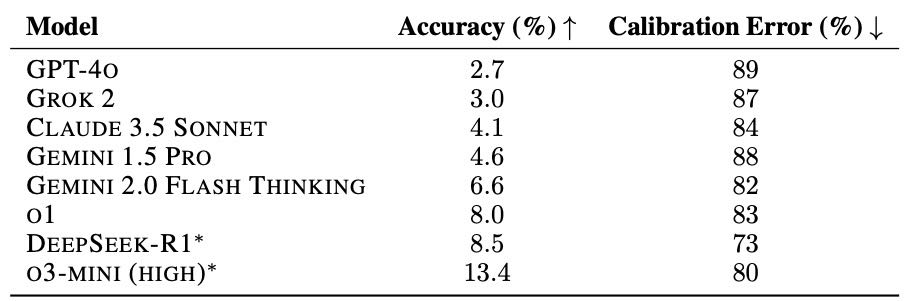
Table 1: Accuracy and RMS calibration error of different models on HLE, demonstrating low accuracy and high calibration error across all models, indicative of hallucination. ∗Model is not multi-modal, evaluated on text-only subset.
✅ 准确率(Accuracy)¶
所有模型在 HLE 上的得分都很低(最高约 13.4%),说明还有很大改进空间。
数据集有意筛除了容易题,所以模型表现差属正常,但猜对的成分也存在。
低分并不代表模型无能,但也不能说明它们有进步。
⚖️ 校准误差(Calibration Error)¶
模型常常在不确定时依然自信地给出错误答案,这叫“幻觉(hallucination)”。
所以还测了“信心匹配度”,即模型说自己 70% 有把握时,是否真的能有 70% 正确率。
所有模型在这项指标上表现也不好,说明它们不擅长自我判断。
🔢 Token 数量(Token Counts)¶
推理型模型生成的 token(字数)更多,计算成本更高。
尽管表现略好,但效率低下。
未来模型需要兼顾准确率与计算效率。
5.Discussion¶
模型未来表现:
虽然当前大模型在 HLE 测试上的准确率很低,但历史表明模型性能提升很快,因此到 2025 年底可能会超过 50%。
但即使模型在这种考试中表现很好,也不代表它具有自主研究能力或通用人工智能,因为 HLE 只测试封闭、可验证的学术问题,不涵盖开放性或创造性任务。
影响:
HLE 提供了一个统一的评估标准,有助于科学家和政策制定者理解 AI 发展水平,进而做出更好的决策和监管规划。