5.2.2. 关键词提取¶
关键词提取,主要分为有监督和无监督的方法,一般来说,我们采用无监督的方法较多一些,这是因为它不需要人工标注的语料,只需要对文本中的单词按照位置、频率、依存关系等信息进行判断,就可以实现关键词的识别和提取。
无监督方法一般有三种类型:
1. 基于统计特征的方法
2. 基于词图模型的方法
3. 基于主题模型的方法
基于统计特征的方法¶
备注
基于统计的方法的特点在于,对单词出现的次数以及分布进行数学上的统计,从而发现相应的规律和重要性(权重),并以此作为关键词提取的依据。
TF-IDF¶
term frequency–inverse document frequency,词频 - 逆向文件频率
最核心的思想非常简单:一个单词在文件中出现的次数越多,它的重要性越高;但它在语料库中出现的频率越高,它的重要性反而越小
在 TF-IDF 中,词频(TF)表示关键字在文本中出现的频率。而逆向文件频率 (IDF) 是由包含该词语的文件的数目除以总文件数目得到的
关键词的提取目前也有很多集成工具包,比如 NLTK(Natural Language Toolkit),它是一个非常著名的自然语言处理工具包,是 NLP 研究领域常用的 Python 库。我们仍旧可以使用 pip install nltk 命令来进行安装。

在 TF-IDF 中,词频(TF)表示关键字在文本中出现的频率。而逆向文件频率 (IDF) 是由包含该词语的文件的数目除以总文件数目得到的,一般情况下还会取对数对结果进行缩放。¶
示例:
from nltk import word_tokenize
from nltk import TextCollection
sents=['i like jike','i want to eat apple','i like lady gaga']
# 首先进行分词
sents=[word_tokenize(sent) for sent in sents]
# 构建语料库
corpus=TextCollection(sents)
# 计算 TF
tf=corpus.tf('one',corpus)
# 计算 IDF
idf=corpus.idf('one')
# 计算任意一个单词的 TF-IDF
tf_idf=corpus.tf_idf('one',corpus)
基于词图模型的关键词提取¶
首先要构建文本一个图结构,用来表示语言的词语网络。然后对语言进行网络图分析,在这个图上寻找具有重要作用的词或者短语,即关键词。
最经典的就是 TextRank 算法了,它脱胎于更为经典的网页排序算法 PageRank。
TextRank 算法¶
PageRank 算法的核心内容有两点:
如果一个网页被很多其他网页链接到的话,就说明这个网页比较重要,也就是 PageRank 值会相对较高
如果一个 PageRank 值很高的网页,链接到一个其他的网页,那么被链接到的网页的 PageRank 值会相应地因此而提高
TextRank 跟 PageRank 的区别在于:
1. 用句子代替网页
2. 任意两个句子的相似性可以采用类似网页转换概率的概念计算
但是也稍有不同,TextRank 用归一化的句子相似度代替了 PageRank 中相等的转移概率
所以在 TextRank 中,所有节点的转移概率不会完全相等。
3. 利用矩阵存储相似性的得分,类似于 PageRank 的矩阵 M
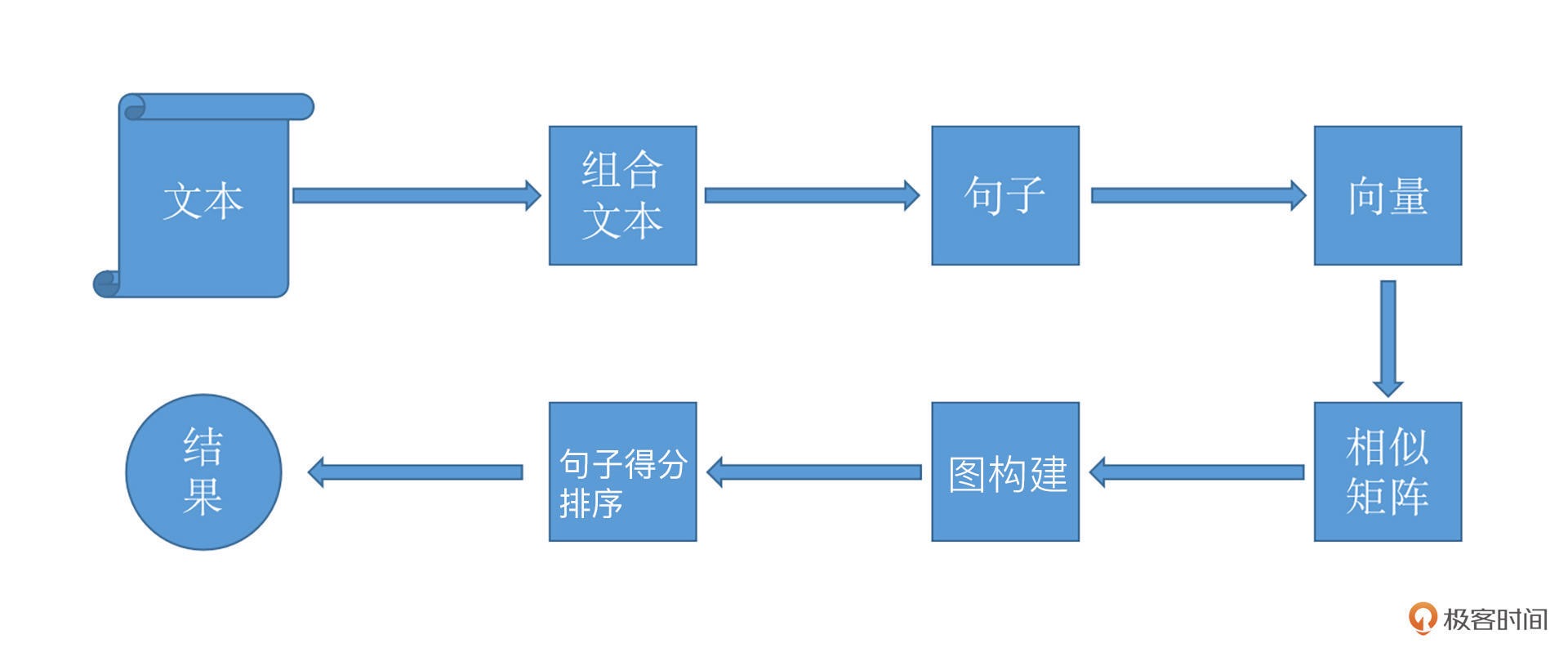
TextRank 的基本流程¶
示例-利用已经集成好的工具包 gensim 来实现使用这个模型:
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'), withFlag=False)
// 重要参数
sentence 是待处理的文本
topK 是选择最重要的 K 个关键词
基于主题模型的关键词提取¶
实际上它也是一种基于统计的模型,只不过它会 “发现” 文档集合中出现的抽象的 “主题”,并用于挖掘文本中隐藏的语义结构。
LDA¶
Latent Dirichlet Allocation(潜在狄利克雷分配)是最典型的基于主题模型的算法
示例:
from gensim import corpora, models
import jieba.posseg as jp
import jieba
texts = [line.strip() for line open ('input.txt', 'r')]
# 老规矩,先分词
words_list = []
for text in texts:
words = [w.word for w in jp.cut(text)]
words_list.append(words)
# 构建文本统计信息,遍历所有的文本,为每个不重复的单词分配序列 id,同时收集该单词出现的次数
dictionary = corpora.Dictionary(words_list)
# 构建语料,将 dictionary 转化为一个词袋。
# corpus 是一个向量的列表,向量的个数就是文档数。你可以输出看一下它内部的结构是怎样的。
corpus = [dictionary.doc2bow(words) for words in words_list]
# 开始训练 LDA 模型
lda_model = models.ldamodel.LdaModel(corpus=corpus, num_topics=8, id2word=dictionary, passes=10)
参数:
num_topics 代表生成的主题的个数
id2word 即为 dictionary,它把 id 都映射成为字符串
passes 相当于深度学习中的 epoch,表示模型遍历语料库的次数