3.2.2. DeepSeek-R1-推理模型¶
热点词¶
Test/Inference-Time scaling law,通过增加推理阶段的算力提升模型的推理能力
Post Training,通过后训练提升模型的推理能力
PRM/ORM:基于过程/结果的奖励模型
CoT:思维链
强化学习、self-play(自我博弈)与MCTS(使用蒙特卡洛搜索树寻找最佳答案)
其他关键词¶
pretrain-time scaling law
post-training¶
“Post-training”这个术语通常出现在机器学习和人工智能领域,特别是在深度学习模型的训练过程中。它指的是在初始训练完成之后进行的一系列操作或步骤,目的是为了进一步改进模型的性能、适应新的数据或者任务,而不需要从头开始完整的训练过程。
- 这些操作可能包括但不限于:
微调(Fine-tuning):使用新的数据集对已训练模型进行额外的训练,以便让模型能够更好地适应特定的任务或数据分布。这通常涉及到较低的学习率,以避免大幅度改变已经训练好的模型权重。
量化(Quantization):将模型中的参数从浮点数转换为低精度的整数表示形式,以此来减少模型的大小并加速推理过程,同时尽量保持模型的准确度。
剪枝(Pruning):去除模型中不重要的权重或神经元,以减少计算复杂度和模型大小,使模型更高效。
知识蒸馏(Knowledge Distillation):通过训练一个较小的“学生”网络来模仿一个较大的“教师”网络的行为,从而获得更小、更快但依然保持较高准确性的模型。
域适应(Domain Adaptation):调整模型,使其能够在一个与训练时不同的但相关的领域内工作得更好。
Test/Inference-time Scaling Law¶
有一个基础模型(我们称其为generator),但是这个模型的逻辑推理能力(比如解数学题的能力)较差时,我们该怎么改进它?再说的具体点,不考虑数据集相关的成本,假设我手头的gpu算力(FLOPs)是有限的,我该怎么利用它,能让我的模型最终能推理出更好的结果?
- 一个比较直接的想法是:把算力花在它的pretain阶段,给模型注入更多数理逻辑的预训练知识。
例如用更好、更多的代码数学等数据,或者扩展模型的参数规模。这个做法启发自大家都很熟悉的scaling law(更具体地说是pretrain-time scaling law)。
曾经,为了提升模型的逻辑推理能力,我们把算力都花在pretrain阶段,由此诞生了pretrain scaling law
现在,已经有现成的产品证明,算力如果花在post training和inference上,模型的推理能力将得到更大提升,也就是存在一个Test/Inferece scaling law
- openai o1 把这个算力更多地用在了2个地方:
用在了rlhf的训练上(post training)
用在了模型的推理阶段上(Test/Inferece)
- Test/Inferece scaling law
pretrain scaling law受到模型参数和训练数据的影响一样
Test/Inferece scaling law
- 把算力用在inference阶段,也就是说,在不变动pretrain阶段的情况下,只通过推理等层面的优化,来提升模型最后的生成效果。
- 这里又分成两种情况。
- 优化推理输入:prompt(CoT)
- 把算力花在推理阶段上可以提升模型效果
prompt给的越细节,你的多轮引导给的越多,模型或许就能产出更好的结果。
而更多的token意味着推理阶段需要花费更多的算力,这就是我们所说的【把算力花在推理阶段上可以提升模型效果】的具体内容之一
- 优化推理输出:revise output distribution
- 让模型吃下一个问题后,自动化地去做CoT的过程
如:希望模型在吃下一个问题后,能自主产生以下输出:attempt1 -> attempt2 -> attempt3 -> …-> attempti -> answer
其中,每个attempt包含“多个中间步骤steps + 最终答案”,也就是它在模拟人类的思考过程:先做一次attempt,然后发现问题,在此基础上在做别的attempt,直到找到最终答案。
- 方案
一个直观的方法就是,如果我有: problem -> attempt1 -> … -> attempti -> answer 这种带标签的数据
解法1:我直接做sft,把最正确的attempt放在输入序列最后,当作label进行训练即可
解法2:我用类似rlhf的方法,先有一个奖励模型,它能对每一个思考步骤做评估,然后利用这个评估结果,指引模型步步搜索,每一步都找到最佳的思考步骤,最终能找到答案
仅从训练方法上来说,都可以算成是post-training
- 如何保证中间结果和答案一定是最好
一方面,我们可以考虑优化推理阶段,即使用一个能够评估中间步骤的verifier,在推理时指引模型搜索出最佳答案。例如,我们对一个问题采样多个attempts链,从中找最好的。或者在单个attempts中找到最好的attempt
另一方面,我们可以考虑在post-training阶段,使用这个verifier来指导模型自动化生产高质量的数据(这是个inference步骤),基于这些数据我们再做对齐。如果这个流程做得好,我们甚至可以直接信任post-training后模型的结果
所以,【优化推理输出】这一部分,你可以把算力全部花在post-training上,也可以花在post-training+inference上,从o1的技术报告上看,它应该选择了后者,同时post-training选择了某种基于强化学习的方法
- 具体参见相关论文
Let’s Verify Step by Step (openai)
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters(deepmind)
OpenAI¶
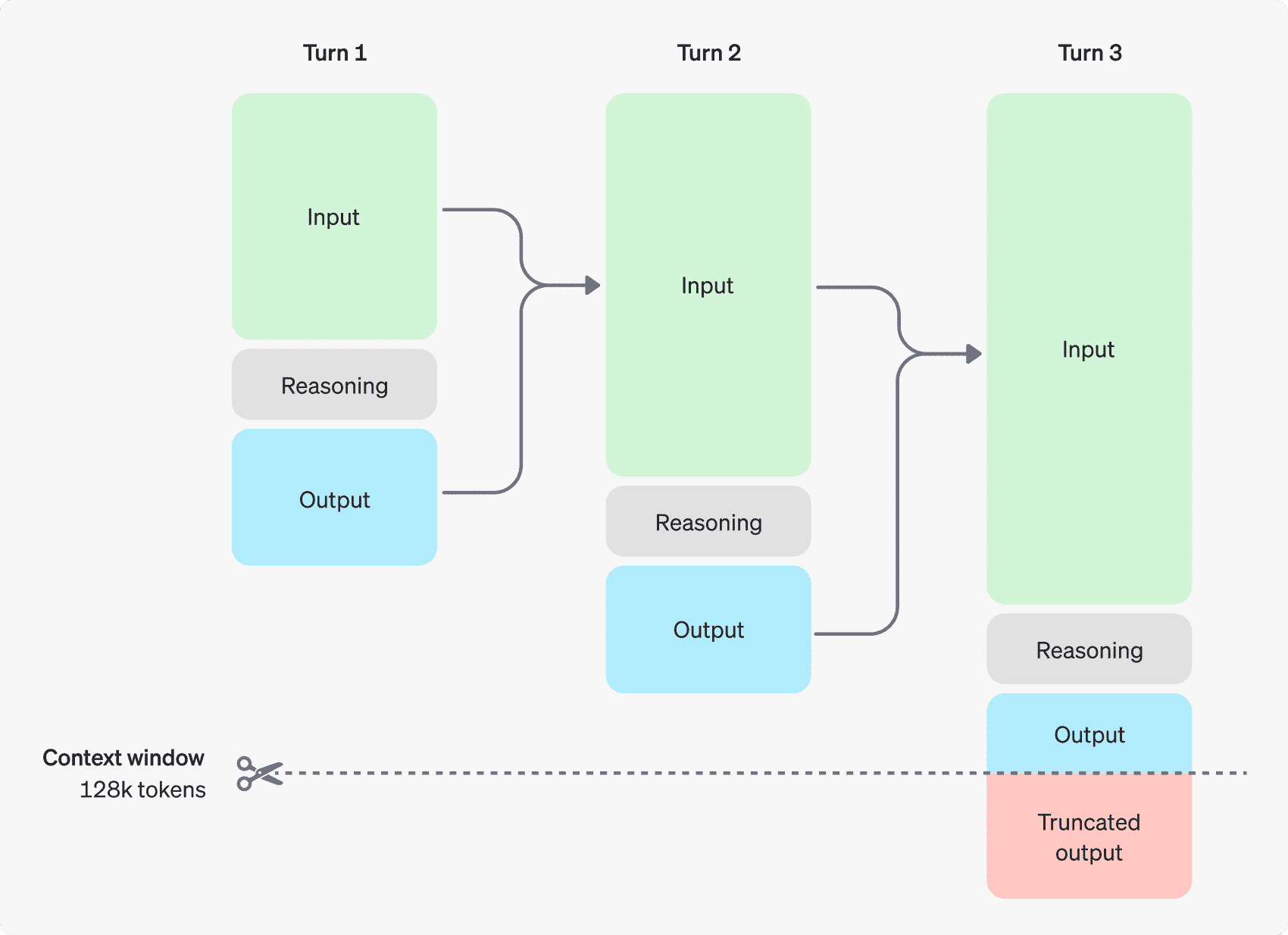
a multi-step conversation between a user and an assistant. Input and output tokens from each step are carried over, while reasoning tokens are discarded.¶
参考¶
收集了内外网可能和o1背后的算法有关的各种资料,包括相关论文、代码和twitter post等等: https://github.com/hijkzzz/Awesome-LLM-Strawberry
Let’s Verify Step by Step (openai): https://arxiv.org/abs/2305.20050
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters (google deepmind): https://arxiv.org/abs/2408.03314
A collection of LLM papers, blogs, and projects, with a focus on OpenAI o1 🍓 and reasoning techniques: https://github.com/hijkzzz/Awesome-LLM-Strawberry