8.5. 通用¶
Glarity-用 AI 总结视频及翻译网页: https://glarity.app/
DataRobot-自动化机器学习平台: https://www.datarobot.com/
Democratizing Generative AI: https://h2o.ai/
https://www.ciciai.com/: 一家位于美国的 AI 初创公司,成立于 2022 年。该公司致力于为个人和企业提供人工智能驱动的聊天机器人服务:
一些常见功能: 问答:Cici AI 的聊天机器人可以回答用户提出的任何问题。 任务完成:Cici AI 的聊天机器人可以帮助用户完成各种任务,例如预约、订购和支付。 个性化推荐:Cici AI 的聊天机器人可以根据用户的兴趣和需求提供个性化的推荐。
https://www.coze.com/ 位于美国的 AI 初创公司,成立于 2022 年。该公司致力于为个人和企业提供人工智能驱动的聊天机器人服务。:
注: 中国不可用
8.5.1. 生成训练数据¶
Snorkel AI 是一家专注于企业级数据驱动人工智能解决方案的公司。其核心产品 Snorkel Flow 是一个基于数据的人工智能平台,旨在帮助企业构建高质量、可信赖的 AI 系统,同时降低训练和运营成本。
Snorkel 是一个用于快速构建和部署大规模监督学习模型的开源工具包。它允许开发者利用弱监督信号来生成训练数据,从而避免了传统手动标注大量数据的繁琐过程。Snorkel 的核心理念是利用大量未标记的数据以及专家知识来生成训练集,从而加速模型训练和部署的过程。该工具包提供了一系列的工具和库,帮助用户快速构建复杂的监督学习模型,并应用于各种领域,如自然语言处理、计算机视觉等。Snorkel 的目标是使开发者能够更轻松地应对大规模数据的挑战,降低模型构建的门槛,从而推动机器学习技术的进步和应用。
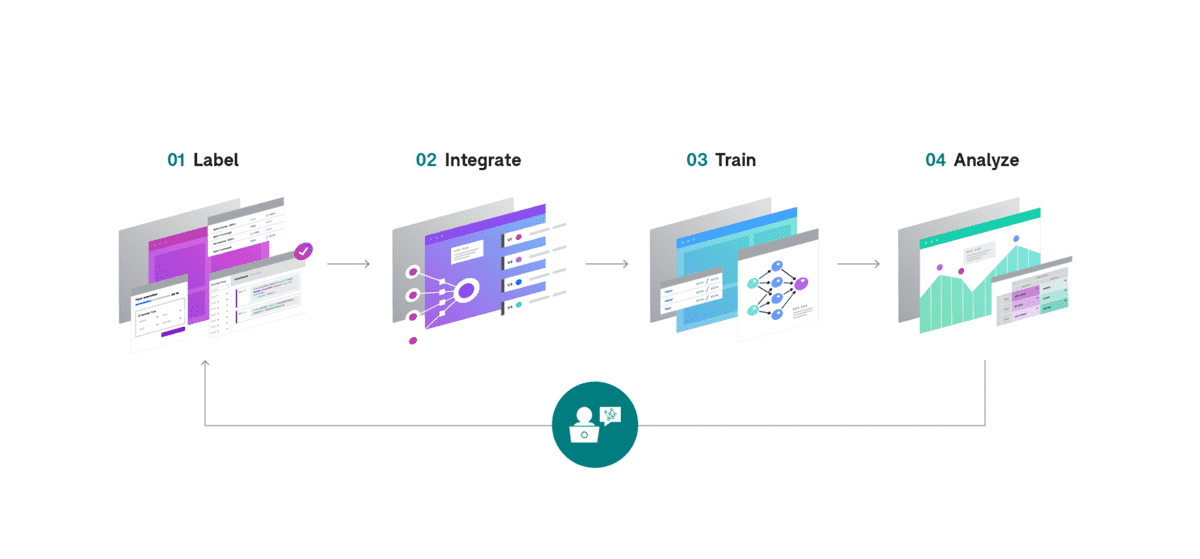
Snorkel 方法由四个主要步骤组成,用户可以迭代这些步骤来系统地提高 ML 模型的质量,直到准备好部署¶

标签函数(LF)可以来自多种来源,包括编写新的启发式(规则、模式等)或包装现有的知识资源(例如模型、众包标签、本体等)。以下是一些简单的伪代码示例,适用于您可以为电子邮件垃圾邮件检测器编写的 LF 类型。¶
常见类型的标注函数:
硬编码的推导:通常使用正则表达式
语义结构:例如,使用 spacy 得到的依存关系结构
远程监督:例如使用外部的知识库
有噪声人工标注:例如众包标注
外部模型:其他可以给出有用标注信号的模型
编写出的所有标注函数实际上就是一个个弱分类器,这些弱分类器有着一定的准确率和召回率,标注模型实际上是通过概率图模型的方式把这些弱分类器结合起来了,从而达到比单个弱分类器更好的效果。
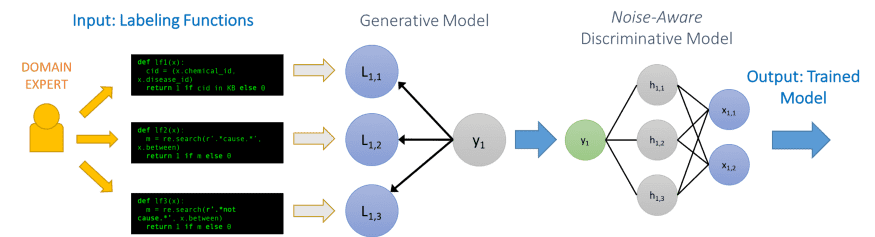
Snorkel 将利用这些不同的标注函数之间的冲突训练一个标注模型(Label Model)来估算不同标注函数的标注准确度。通过观察标注函数之间的彼此一致性,标注模型能够学习到每个监督源的准确度。
例如,如果一个标注函数的标注结果总是得到其他标注函数的认可,那么这个标注函数将有一个高准确率,而如果一个标注函数总是与其他标注函数的结果不一致,那么这个标注函数将得到一个较低的准确率。通过整合所有的标注函数的投票结果(以其估算准确度作为权重),我们就可以为每个数据样本分配一个包含噪声的标注(0~1 之间),而不是一个硬标注(要么 0,要么 1)。
接下来,当标注一个新的数据点时,每一个标注函数都会对分类进行投票:正、负或弃权。基于这些投票以及标注函数的估算精度,标注模型能够程序化到为上百万的数据点给出概率性标注。最终的目标是训练出一个可以超越标注函数的泛化能力的分类器。
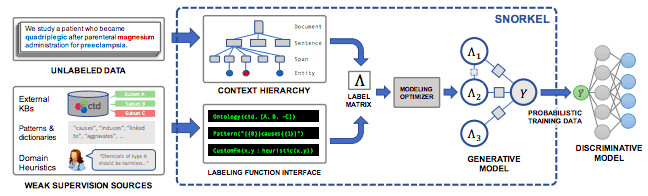
斯坦福的 Infolab 实现的 Snorkel 框架: https://github.com/HazyResearch/metal
参考¶
8.5.2. 工具类网站¶
https://www.crewai.com/: CrewAI 是一家位于美国的 AI 初创公司,成立于 2021 年。该公司致力于为企业提供多智能体代理系统平台,帮助企业自动化复杂任务。CrewAI 平台的核心是其多智能体代理系统。该系统由多个智能体代理组成,每个代理都专门执行特定任务。这些代理可以协同工作,完成复杂的任务。(https://github.com/joaomdmoura/crewAI)