新溪-gordon
V2026.03
AI
1. 常用
1.1. 常用
1.2. AIGC
1.3. 机器学习machine learning
1.4. BI(Business Intelligence)
1.5. 深度学习
1.5.1. 常用
1.5.2. 历史
1.6. monitor
1.7. 相关算法
1.8. 工具
1.9. 常见问题
1.10. 机器人领域
2. 理论
2.1. 通用
2.1.1. 经典认知科学
2.2. 关键定义
2.2.1. 协同过滤(Collaborative Filtering, CF)
2.2.2. MF(Matrix Factorization,矩阵分解)
2.2.3. PMF(Probabilistic Matrix Factorization,概率矩阵分解)
2.2.4. Two-Tower Models(双塔模型)
2.2.5. 通用
2.2.6. Pipeline Parallelism
2.2.7. Tensor Parallesim
2.2.8. 激活函数-GELU
2.2.9. 激活函数-Leaky ReLU
2.2.10. 激活函数-ReLU
2.2.11. 激活函数-SiLU
2.2.12. 激活函数-Sigmoid
2.2.13. 激活函数-Tanh
2.2.14. 归一化-L1
2.2.15. 归一化-L2
2.2.16. 概率分布-Softmax
2.2.17. 概率分布-Sparsemax
2.2.18. 概率分布-logsoftmax
2.2.19. 损失函数-分类-cross-entropy(交叉熵)
2.2.20. 损失函数-分类-负对数似然损失NLL Loss
2.2.21. 损失函数-分类-对数损失(Log Loss)
2.2.22. 损失函数-分类-KL 散度(KL Loss)
2.2.23. 损失函数-回归-均方误差(MSE)
2.2.24. 损失函数-回归-平均绝对误差(MAE)
2.2.25. 损失函数-回归-Huber 损失
2.2.26. 损失函数-回归-对数余弦损失(Log-Cosh Loss)
2.2.27. 权重衰减(L2正则化)
2.2.28. GD(梯度下降)
2.2.29. SGD随机梯度下降
2.2.30. RMSprop
2.2.31. Adam
2.2.32. AdamW
2.2.33. Momentum
2.2.34. HMM-隐马尔可夫模型
2.2.35. WWM-Whole Word Masking
2.2.36. CRF-条件随机场
2.2.37. ANN(NN)
2.2.38. 深度神经网络(Deep Neural Network, DNN)
2.2.39. 卷积神经网络(Convolutional Neural Network, CNN)
2.2.40. RNN: 循环神经网(Recurrent Neural Network, RNN)
2.2.41. LSTM: 长短时记忆(Long Short Term Memory, LSTM)
2.2.42. 前向/反向传播
2.2.43. Linear Layer
2.2.44. Feedforward Network-前馈网络
2.2.45. LayerNorm(层归一化)
2.2.46. Weight Tying
2.2.47. Greedy Decoding
2.2.48. Image Grounding
2.2.49. Perplexity(PPL)困惑度
2.2.50. Manhattan World(曼哈顿世界)
2.2.51. Hough Transform(霍夫变换)
2.2.52. 极坐标表示法(Polar Coordinate System)
2.2.53. Gaussian Sphere(高斯球)
2.2.54. 边缘方向 Edge Direction
2.2.55. NormalVector法向量
2.2.56. AllReduce
2.2.57. BPE
2.2.58. Embedding 模型
2.2.59. K-Means聚类算法
2.2.60. LLM
2.2.61. 深度学习相关
2.2.62. 其他
2.2.63. 判别式模型vs生成式模型
2.2.64. 欧几里得空间(Euclidean space)
2.2.65. 矢量化计算(Vectorize calculations)
2.3. 临时
2.3.1. ReAct框架
2.3.2. Reflection反思
2.3.3. 数学
2.3.4. bag-of-words
2.3.5. Word2Vec
2.3.6. Doc2Vec
2.3.7. FastText
2.3.8. LDA-Latent Dirichlet Allocation(潜在狄利克雷分配)
2.3.9. overfitting&underfitting
2.3.10. RAG
2.3.11. Agent
2.3.12. LLM
2.3.13. Prompt Engineering
2.3.14. LLM调优(finetune)
2.3.15. Workflow
2.3.16. 通用
3. 大模型
3.1. 常用
3.1.1. 常用
3.1.2. 依赖安装
3.1.3. 编码-解码器
3.1.4. 使用
3.1.5. 临时
3.2. 著名模型
3.2.1. Qwen3
3.2.2. DeepSeek-R1-推理模型
3.2.3. LLaMA
3.2.4. ChatGLM
3.2.5. BERT
3.2.6. OpenAI
3.2.7. BART
3.2.8. T5
3.2.9. ChatRWKV
3.2.10. Open-Assistant
3.2.11. OpenGVLab
3.3. 调优
3.4. 模型量化(Quantization)
3.4.1. 常用
3.4.2. GGUF 文件
3.5. 文件格式
3.5.1. 通用
3.5.2. GGML系列文件格式
3.5.3. ONNX
常用
ONNX
onnxruntime
skl2onnx
3.5.4. NCNN
3.6. 商业项目
3.6.1. 常用
3.6.2. OpenAI
3.7. Prompt 提示词
3.7.1. 中文
3.7.2. English
3.7.3. 示例
3.8. Android版LLM相关
3.8.1. 常用
3.8.2. Android版部署
3.8.3. GPU
4. RAG相关
5. NLP
5.1. 常用
5.2. 预处理
5.2.1. 常用
5.2.2. 关键词提取
5.2.3. 分词
5.2.4. 情感分析
5.2.5. 文本表示
5.2.6. 注意力机制
5.2.7. 语言模型
5.3. NER-命名实体识别
5.3.1. 常用
5.3.2. 序列标注
5.3.3. BiLSTM+CRF
5.3.4. 历史
5.4. 总结-摘要
5.4.1. 通用
6. 函数库
6.1. 常用
6.2. Image图像处理
6.3. Video视频
6.4. IPython
6.4.1. 常用
6.4.2. 魔法命令
6.4.3. display函数
6.5. Jupyter
6.6. NumPy
6.6.1. 通用
6.6.2. Ndarray 对象
6.6.3. 通用函数
6.7. Pandas
6.7.1. 常用
6.7.2. 实例-subset
6.7.3. 实例-统计分析
6.7.4. 利用pandas实现SQL操作
6.7.5. 实例-缺失值的处理
6.7.6. 多层索引的使用
6.7.7. 实践
实践-2012年奥巴马总统连任选举
6.7.8. API-输入输出
6.7.9. API-General functions
6.7.10. API-Series
6.7.11. API-DataFrame
6.7.12. API-index
6.8. Matplotlib
6.8.1. 基本
6.8.2. 安装
6.8.3. pyplot
6.8.4. matplotlib.patches
6.8.5. 实例
折线图plot
条形图bar
直方图hist
散点图scatter
面积图stackplot
饼图pie
箱型图box
多图合并multi
6.8.6. pylab子包
6.9. SciPy
6.9.1. 常用
6.10. sklearn
6.10.1. 常用
6.10.2. 监督学习
广义线性模型
6.10.3. 无监督学习
6.11. statsmodels
6.12. OpenCV
6.12.1. 常用
6.12.2. 实例
6.12.3. 代码类结构
6.13. Seaborn
6.13.1. 常用
6.14. jieba中文分词
6.15. gensim: 文本主题建模和相似性分析
6.15.1. 常用
6.15.2. Core Tutorials
6.15.3. Tutorials: Learning Oriented Lessons
6.15.4. How-to Guides: Solve a Problem
6.16. LAC-百度词法分析工具
7. 学习框架
7.1. 常用
7.2. PyTorch
7.2.1. 常用
7.2.2. nn模块
7.2.3. PyTorch
7.2.4. ExecuTorch
7.2.5. torchrun (Elastic Launch)
7.3. huggingface
7.3.1. 常用
Hugging Face Hub
Hub Python Library
Datasets
TGI: Text Generation Inference
Evaluate
7.3.2. Transformers
Transformers
Transformers 4.45.2
7.3.3. Tokenizers
7.3.4. PEFT
PEFT
PEFT 0.13.0
7.3.5. Accelerate
7.3.6. TRL - Transformer Reinforcement Learning
7.3.7. 收集
resources
model
博文: decoding methods of LLM with transformers
7.4. vLLM
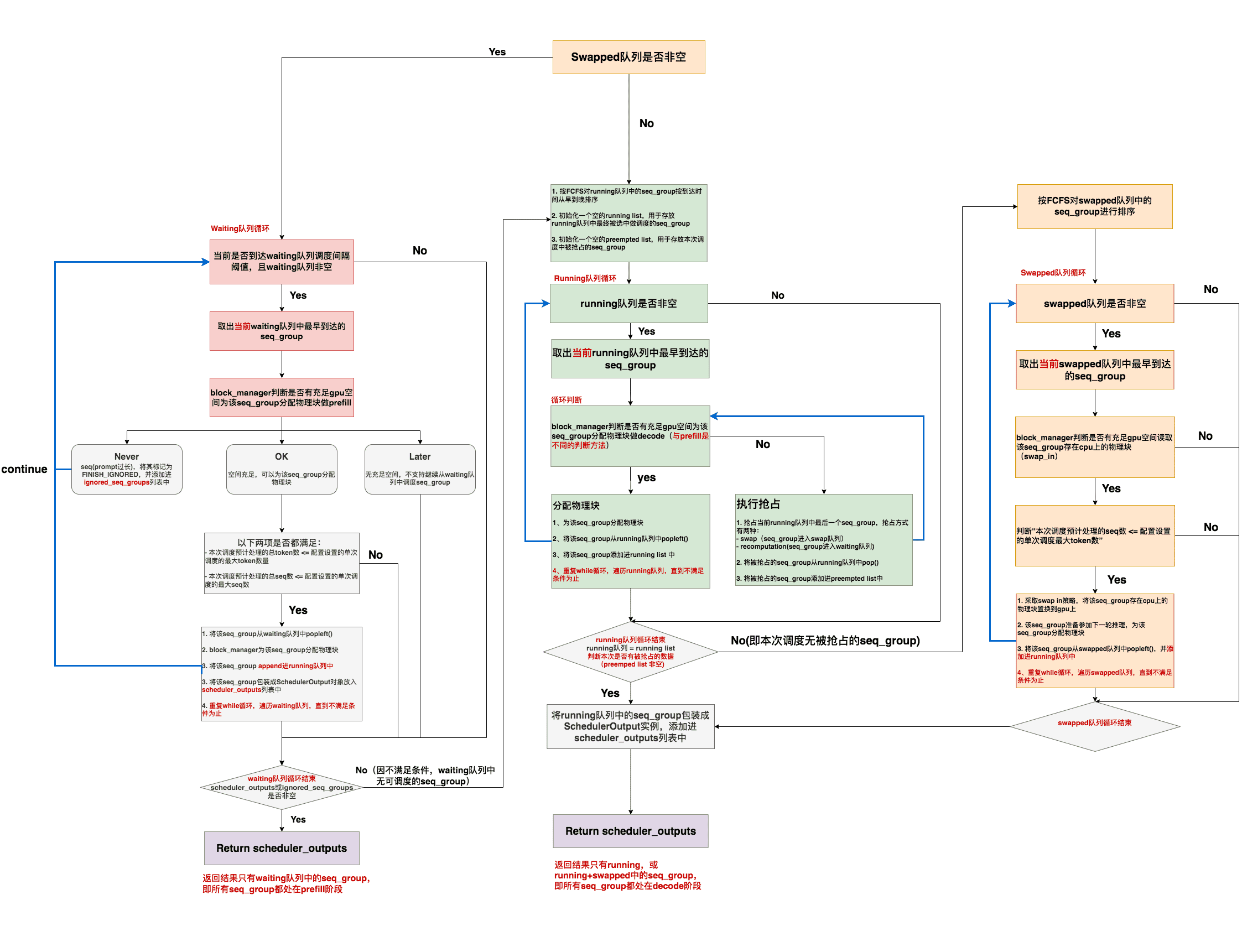
7.4.1. 常用
7.4.2. vLLM官方文档
7.5. llama.cpp框架
7.5.1. 常用
7.5.2. Python bindings for llama.cpp
7.6. DeepSpeed
7.6.1. huggingface
7.6.2. Zero Redundancy Optimizer (ZeRO)
7.6.3. DeepSpeed
7.7. mxnet库
7.7.1. nd模块
ndarray
ndarray.random
7.7.2. gluon模块
7.7.3. autograd模块
7.8. tensorflow
7.9. Keras
7.9.1. 常用
7.9.2. 实例
二分类问题
多分类问题
回归问题
7.10. 其他
8. 关键网站
8.1. Papers with Code
8.2. Kaggle
8.3. ArXiv 学术论文预印本平台
8.4. 视频相关
8.5. 通用
9. 实践
9.1. OCR
9.1.1. 常用
9.2. AIML
9.2.1. 常用
9.2.2. AIML 2.1 Documentation
10. 开源项目
10.1. Agent
10.2. RAG
10.3. 常用
10.4. UI界面
10.5. 调优
10.6. 搜索
10.7. LLM Inference Engines
10.8. 模型推理平台
10.9. LLM推理加速
10.10. LLM评估
10.11. AI平台
11. 数据集
11.1. 常用
11.2. 中文数据集
11.3. 中文图片相关数据集
11.4. dataset
11.5. 数据集相关网站
12. 常见模型
13. 图形&计算加速技术
13.1. 常用
13.2. cuda
14. Evaluate评测
14.1. 通用
14.2. TruLens
14.3. Ragas
14.4. DeepEval
14.5. UpTrain
14.6. evaluate
15. 传统AI
新溪-gordon
Docs
»
7.
学习框架
»
7.4.
vLLM
»
7.4.1.
常用
View page source
On This Page
7.4.1. 常用
关键文档
主页
索引
模块索引
搜索页面
7.4.1.
常用
¶
关键文档
¶
https://mp.weixin.qq.com/s/r_t6_zMvPT7za82MZX4oRA
主页
索引
模块索引
搜索页面