11.3. 中文图片相关数据集¶
11.3.1. OCR¶
SCUT-EPT¶
手写体
SCUT-HCCDoc_Dataset_Release¶
GitHub: https://github.com/HCIILAB/SCUT-HCCDoc_Dataset_Release
通过网盘分享的文件:SCUT-HCCDoc_Dataset_Release_v2.zip 链接: https://pan.baidu.com/s/1EpCJlB5oTIYM-EsnRXP4rQ?pwd=mcw5 提取码: mcw5
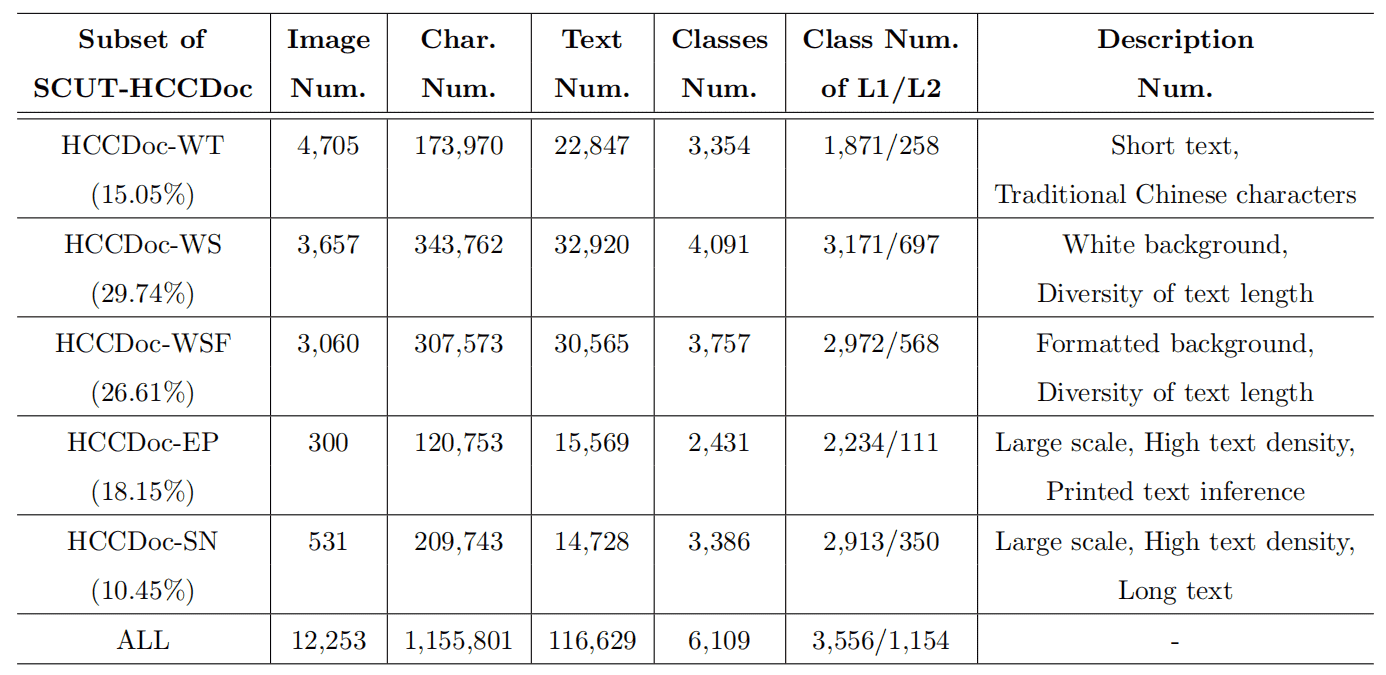
SCUT-HCCDoc can be roughly divided into five subsets:
手写体
HCCDoc-WT: images of traditional Chinese characters; HCCDoc-WS: images of simplified Chinese characters without a formatted background; HCCDoc-WSF: images of simplified Chinese characters with the formatted background; HCCDoc-SN: images of student notes; HCCDoc-EP: images of examination papers.
Chinese-Text-Recognition¶

The image demonstrates the four datasets used in our benchmark including Scene, Web, Document, and Handwriting datasets¶
- Scene Dataset
从五个公开的中文场景文本数据集中采集了图像样本(通过裁剪图像中的文本行),总共获取了 636,455 个文本样本。这些样本被随机打乱后按 8:1:1 的比例划分为训练集、验证集和测试集。
- 1.RCTW(Reading Chinese Text in the Wild)
来源:自然场景图像(街景、广告牌等)
原始数据量:12,263 张图像
- 使用方式:
从训练集中裁剪出 44,420 条文本行
未使用其官方测试集(因为不提供标签)
- 2.ReCTS(Recognizing Chinese Text in Street View)
来源:街景图像,主要是商铺招牌和路标
原始图像数:25,000 张
- 使用方式:
从训练集裁剪出 107,657 条文本样本
仅使用训练集,未用测试集
- 3.LSVT(Large-scale Street View Text)
来源:中英文混合的街景图像数据集
- 数据组成:
50,000 张图像提供完整标注(多边形框+文本内容)
400,000 张图像(一张图片仅标注一个文本实例)
- 使用方式:
只采用完整标注部分
裁剪出 243,063 条文本行图像
- 4.ArT(Arbitrary-Shaped Text Dataset)
来源:自然场景中的多形状文本图像
特点: * 包含弯曲文本、旋转文本等复杂布局
使用方式: * 从训练集中裁剪出 49,951 条文本图像
- 5.CTW(Chinese Text in the Wild)
来源:多样化的街景图像
特点: * 覆盖平面、凸起、低光照等复杂场景 * 提供字符级框、文本标签,以及额外属性(如背景复杂度、字符外观等)
使用方式: * 从训练集和测试集中裁剪出 191,364 条文本行图像
- Web Dataset
来源:MTWI 数据集(Multi-Type Web Images) * 包含来自淘宝网站的 20,000 张中英文网页文本图像 * 覆盖 17 个不同的商品类目 * 图像中的文本具有丰富的排版和设计风格
处理方式: * 从训练集中裁剪出 140,589 条文本图像 * 然后手动按 8:1:1 的比例划分训练集、测试集和验证集
- Document Dataset
- 来源:Text Render 公开合成引擎(用于合成文档风格的文本图像)
- 文本内容来源于多个真实语料库:
Wikipedia
电影字幕
Amazon 评论
百度百科(baike)
合成时随机设定文本长度(1~15个字符之间)
- 数据量:
总共合成了 500,000 张文档风格文本图像
然后手动按 8:1:1 的比例划分训练集、测试集和验证集
- Handwriting Dataset
- 来源:SCUT-HCCDoc(华南理工大学发布的中文手写文档数据集)
图像通过在自然环境下用相机采集
文本内容为真实中文手写体
- 处理方式:
- 原始提供:
训练集:93,254 条手写文本行
测试集:23,389 条文本行
- 为了更科学的验证效果,作者进一步将原始训练集手动划分为:
训练集:74,603
验证集:18,651
测试集仍沿用原始数据:23,389