3.2.7. BART¶
基本¶
BART 的全称是 Bidirectional and Auto-Regressive Transformers(双向自回归变压器)。它是由 Facebook AI 在 2019 年提出的一个新的预训练模型,结合了双向 Transformer 和自回归 Transformer,在文本生成相关任务中达到了 SOTA 的结果
BART 论文: https://arxiv.org/abs/1910.13461
其主要特征包括:
采用编码器 - 解码器 (Encoder-Decoder) 的 Transformer 网络结构。
编码器部分 Bidirectional, 可以捕捉语境信息。
解码器部分 Auto-regressive, 按时间序生成目标语言。
设计了新的预训练目标:文本堆积 (Text Infilling), 屏蔽文中部分文本,让模型预测被屏蔽的内容。
可以进行多种文本生成任务的微调,如摘要生成、问答、对话等。
在文档摘要、语言推断等任务上取得了 state-of-the-art 的结果。
预训练模型大小可变,包括 base 和 large 版本。
架构设计简洁优雅且高效可扩展。
总之,BART 融合了 BERT 的双向编码与 GPT 的自回归解码,是新一代文本生成模型的代表,取得了很好的生成任务效果,影响力与日俱增。
BART 原理与特点分析¶
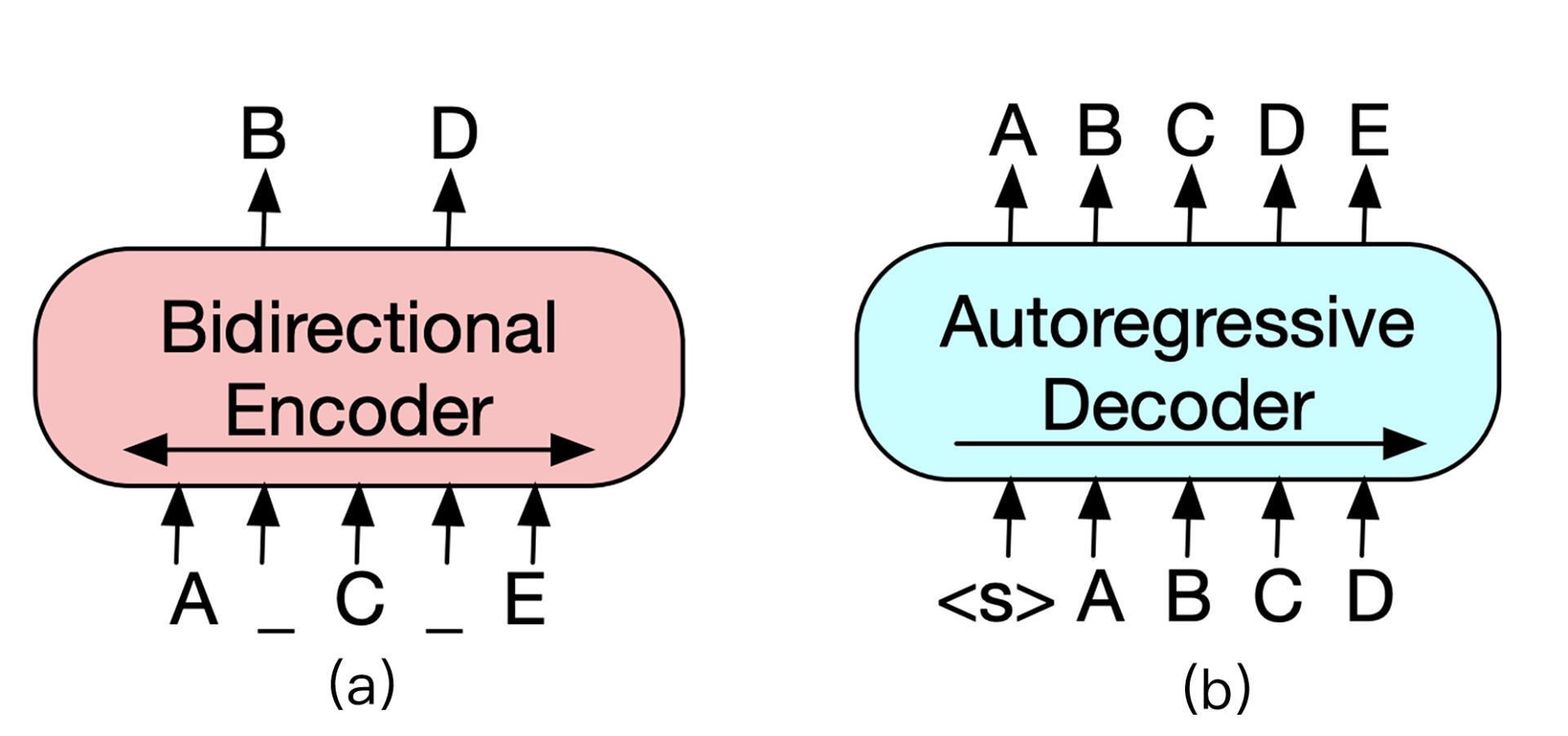
Transformer 左半边为 Encoder,右半边为 Decoder¶
Encoder 负责将原始文本进行 self-attention,并获得句子中每个词的词向量,最经典的 Encoder 架构就是上节课所学习的 BERT,但是单独 Encoder 结构不适用于文本生成任务。
Decoder 的输入与输出之间错开一个位置,这是为了模拟文本生成时,不能让模型看到未来的词,这种方式称为 Auto-Regressive(自回归)。例如 GPT 等基于 Decoder 结构的模型通常适用于做文本生成任务,但是无法学习双向的上下文语境信息。
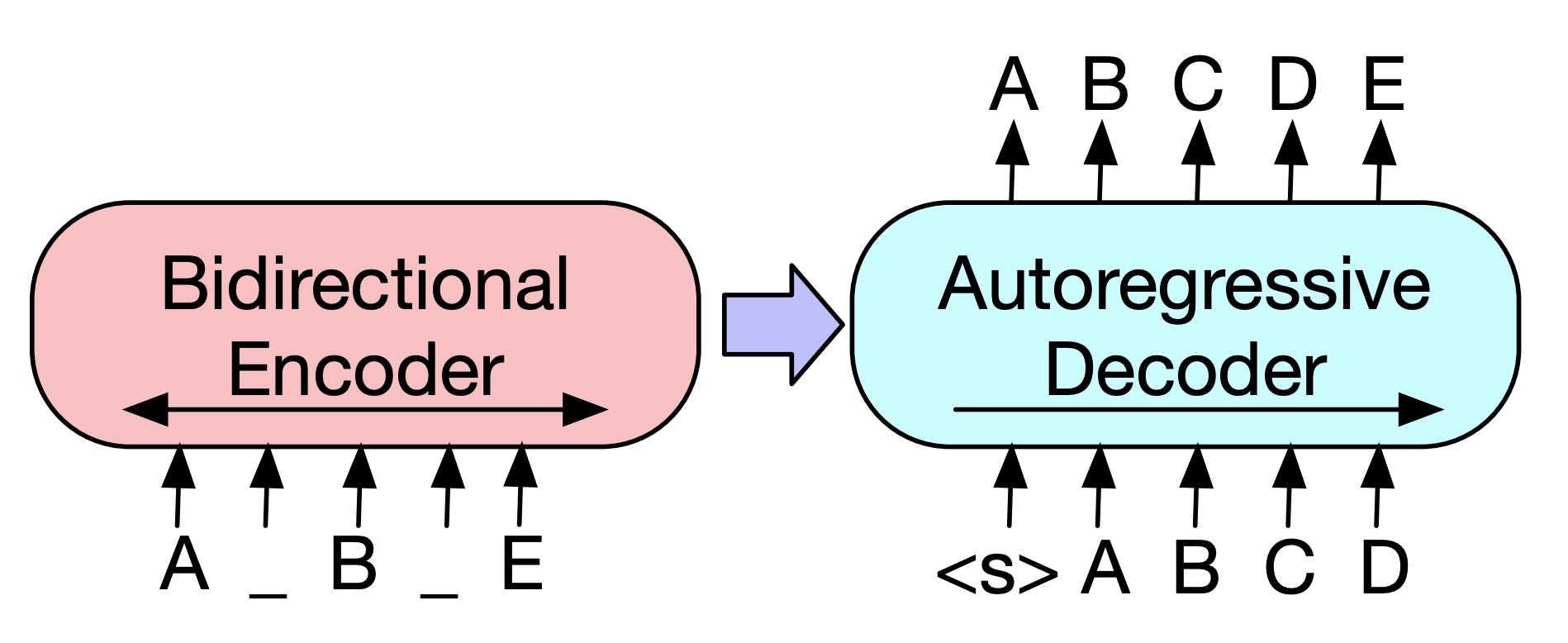
BART 模型就是将 Encoder 和 Decoder 结合在一起的一种 sequence-to-sequence 结构,它的主要结构如图所示。¶
BART 模型的结构看似与 Transformer 没什么不同,主要区别在于 BART 的预训练阶段。首先在 Encoder 端使用多种噪声对原始文本进行破坏,然后再使用 Decoder 重建原始文本。由于 BART 本身就是在 sequence-to-sequence 的基础上构建并且进行预训练,它天然就适合做序列生成的任务,例如:问答、文本摘要、机器翻译等。在生成任务上获得进步的同时,在一些文本理解类任务上它也可以取得很好的效果。
MBart¶
The following MBart models can be used for multilingual translation:
facebook/mbart-large-50-one-to-many-mmt (One-to-many multilingual machine translation, 50 languages)
facebook/mbart-large-50-many-to-many-mmt (Many-to-many multilingual machine translation, 50 languages)
facebook/mbart-large-50-many-to-one-mmt (Many-to-one multilingual machine translation, 50 languages)
facebook/mbart-large-50 (Multilingual translation, 50 languages)
facebook/mbart-large-cc25
facebook/mbart-large-50-many-to-many-mmt¶
facebook/mbart-large-50-many-to-many-mmt 是一个面向多语言的 Seq2Seq 模型,主要用于机器翻译任务。其主要特点包括:
基于 BART 模型架构,采用 Transformer Encoder-Decoder 结构。
预训练数据集包括 CC25 语料库中的 50 种语言,约为 25GB 数据。
支持直接多语言翻译,无需经过第三语言中继。
模型规模较大,约有 610M 参数。
在 WMT、Flores 等多语言翻译数据集上取得了 State-of-the-Art 的结果。
支持输入输出词典,可以自定义词汇。
模型已开源,可以免费使用。
可运行在 GPU 及 CPU 上,推理速度较快。
支持使用 PyTorch 及 Transformers 接口调用。
预训练模型可直接下载使用。
总体来说,该模型具有语言广泛、质量高且易用性强的特点,适合使用在需要高质量多语言翻译的场景中,是目前最强的开源多语言翻译模型之一。
示例:
fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
encoded_en = tokenizer(en_text, return_tensors="pt")
generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id("en_XX"))
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)